geektime专栏《Java并发编程实战》笔记【待完成】
本文是对geektime专栏Java并发编程实战的整理笔记。
一、并发编程的理论基础
1.出现可见性、原子性和有序性问题的原因?
CPU、内存、IO之间速度存在巨大差异。
为了平衡三者间的速度差异,OS、CPU、编译系统进行了优化。
- 1. CPU: 增加了缓存,以均衡与内存的速度差异;
- 2. OS:增加了进程、线程,以分时复用 CPU,进而均衡 CPU 与 I/O 设备的速度差异;
- 3. 编译程序:优化指令执行次序(指令重排序),使得缓存能够得到更加合理地利用。
引入上面的解决方案,同时也引来新的问题:
- 缓存导致可见性问题 (while(flag))
- 线程切换导致原子性问题 (i++)
- 重排序导致有序性问题(双检锁)
2.Java如何解决有序性和可见性问题?
导致可见性的原因是缓存,导致有序性的原因是编译重排序优化。那解决可见性、有序性最直接的办法就是禁用缓存和编译优化,但是这样问题虽然解决了,我们程序的性能可就堪忧了。合理的方案应该是按需禁用缓存以及编译优化。
Java内存模型规范了 JVM 如何提供按需禁用缓存和编译优化的方法。具体来说,这些方法包括 volatile、synchronized 和 final 三个关键字,以及六项 Happens-Before 规则。
- volatile、synchronized 、final
- Happens-Before 规则
Happen-before规则
Happens-Before 并不是说前面一个操作发生在后续操作的前面,它真正要表达的是:前面一个操作的结果对后续操作是可见的。也就是说Happens-Before 约束了编译器的优化行为,虽允许编译器优化,但是要求编译器优化后一定遵守 Happens-Before 规则。
①.程序的顺序性规则
这条规则是指在一个线程中,按照程序顺序,前面的操作 Happens-Before 于后续的任意操作。
class VolatileExample { int x = 0; volatile boolean v = false; public void writer() {//线程A执行writer操作 x = 42; v = true; } public void reader() {//线程B执行reader操作 if (v == true) { // 这里 x 会是多少呢? } } }
按照程序的顺序,代码“x = 42;” Happens-Before 于代码 “v = true;
也比较符合单线程思维(对于单个线程来说):程序前面对某个变量的修改一定是对后续操作可见的。
②.volatile变量规则
这条规则是指对一个 volatile 变量的写操作, Happens-Before 于后续对这个 volatile变量的读操作。
③.传递性
这条规则是指如果 A Happens-Before B,且 B Happens-Before C,那么 A Happens-Before C。
class VolatileExample { int x = 0; volatile boolean v = false; public void writer() {//线程A执行writer操作 x = 42; v = true; } public void reader() {//线程B执行reader操作 if (v == true) { // 这里 x 会是多少呢? } } }
④.管程中的锁的规则
这条规则是指对一个锁的解锁 Happens-Before 于后续对这个锁的加锁。也就是指前一个线程的解锁操作对后一个线程的加锁操作可见,综合 Happens-Before 的传递性原则,我们就能得出前一个线程在临界区修改的共享变量(该操作在解锁之前),对后续进入临界区(该操作在加锁之后)的线程是可见的。
synchronized (this) { // 此处自动加锁 // x 是共享变量, 初始值 =10 if (this.x < 12) { this.x = 12; } } // 此处自动解锁
对于上面的代码,可以这样理解:
假设 x 的初值是 10,线程 A 执行完代码块后 x 的值会变成 12(执行完自动释放锁)。
线程 B 进入代码块时,能够看到线程 A 对 x 的写操作,也就是线程 B 能够看到 x==12。
⑤.线程start规则
指主线程 A 启动子线程 B 后,子线程 B 能够看到主线程在启动子线程 B 前的操作。
Thread B = new Thread(()->{ // 【主线程调用 B.start() 之前,所有对共享变量的修改,此处皆可见】 // 此例中,var==77 }); var = 77;// 此处修改共享变量var的值 B.start();// 主线程启动子线程
⑥.线程join规则
指主线程A等待子线程B完成(主线程 A 通过调用子线程B 的 join() 方法实现)
Thread B = new Thread(()->{ // 此处对共享变量 var 修改 var = 66; }); // 例如此处对共享变量修改,则这个修改结果对线程 B 可见 B.start();// 主线程启动子线程 B.join() // 子线程所有对共享变量的修改,在主线程调用 B.join() 之后皆可见。此例中,var==66
final
volatile可以禁用缓存以及编译优化,而终极方法是使用final 关键字,它告诉编译器:这个变量生而不变,可以可劲儿优化。然而旧有的java内存模型却存在缺陷。
在旧有的java内存模型中,final可能给人一种错觉——final修饰的变量会发生变化。最典型的一个例子就是String的subString()。可参考:How can final fields appear to change their values?
/** * String由字符数组,起始偏移offset,长度length这三个属性组成。 * * substring()可以有这样的实现逻辑: * 创建一个新的String,这个String底层与原String共享同一个字符数组,只是起始偏移和长度不同,这样就可以避免额外的对象存储的空间开销和对象拷贝的时间开销。 * * 然而在旧有的java内存模型中,另一个线程可能会看到offset的值是默认值0而不是4,而之后又会看到offset的正确值4,这样就给人一种错觉——字符串从/usr变为了/tmp。 * 旧有的java内存模型允许这种情况存在,但在新的java内存模型中已经进行了修复,增强了final的语义。 */ String s1 = "/usr/tmp"; String s2 = s1.substring(4);
在 1.5 以后 Java 内存模型对 final 类型变量的重排进行了约束。现在只要我们提供正确构造函数没有“逸出”,就不会出问题了。
// 下面的构造函数发生了逸出,不要这么干 public FinalFieldExample() { // bad! x = 3; y = 4; // 这里就发生逸出。其它线程就可能通过global.obj访问到未构造完成的对象,从而可能看到属性的默认值,而非初始值。 global.obj = this; }
3.如何解决原子性问题?
互斥锁(synchronized)
等待通知(wait-notify)
4.如何用一把锁保护多个资源
当我们要保护多个资源时,首先要区分这些资源是否存在关联关系。如果资源之间没有关系,很好处理,每个资源一把锁就可以了。如果资源之间有关联关系,就要选择一个粒度更大的锁,这个锁应该能够覆盖所有相关的资源。
(1)保护没有关联关系的资源
如果资源之间没有关系,每个资源一把锁就可以了。
class Account { // 锁:保护账户余额 private final Object balLock = new Object(); // 账户余额 private Integer balance; // 锁:保护账户密码 private final Object pwLock = new Object(); // 账户密码 private String password; // 取款 void withdraw(Integer amt) { synchronized(balLock) { if (this.balance > amt){ this.balance -= amt; } } } // 查看余额 Integer getBalance() { synchronized(balLock) { return balance; } } // 更改密码 void updatePassword(String pw){ synchronized(pwLock) { this.password = pw; } } // 查看密码 String getPassword() { synchronized(pwLock) { return password; } } }
(2)保护有关联关系的资源
如果资源之间有关联关系,就要选择一个粒度更大的锁,这个锁应该能够覆盖所有相关的资源。
例如,银行业务里面的转账操作,账户 A 减少 100 元,账户 B 增加 100 元,这两个账户就是有关联关系的。对于像转账这种有关联关系的操作,我们应该怎么去解决呢?
我们很容易凭直觉想到这种解决方案:使用 synchronized 关键字修饰一下 transfer()。然而,这种方案只是看上去正确,实际上是错误的。
/** * (错误方式)并不能保护有关联关系的资源 */ class Account { private int balance;//余额 // 转账 synchronized void transfer(Account target, int amt){ if (this.balance > amt) { this.balance -= amt; target.balance += amt; } } }
在这段代码中,临界区内有两个资源:分别是转出账户的余额 this.balance 和转入账户的余额 target.balance,并且用的是一把锁 this。问题也出在 this 这把锁上,this 这把锁可以保护自己的余额 this.balance,却保护不了别人的余额 target.balance。
下面我们具体分析一下,假设有 A、B、C 三个账户,余额都是 200 元,我们用两个线程分别执行两个转账操作:账户 A 转给账户 B 100 元,账户 B 转给账户 C 100 元,最后我
们期望的结果应该是账户 A 的余额是 100 元,账户 B 的余额是 200 元, 账户 C 的余额是 300 元。
我们假设线程 1 执行账户 A 转账户 B 的操作,线程 2 执行账户 B 转账户 C 的操作,这两个线程分别在两颗 CPU 上同时执行,那它们是互斥的吗?我们期望是,但实际上并不是。
因为线程 1 锁定的是账户 A 的实例(A.this),而线程 2 锁定的是账户 B 的实例(B.this),所以这两个线程可以同时进入临界区 transfer()。
同时进入临界区的结果是什么呢?
线程 1 和线程 2 都会读到账户 B 的余额为 200,导致最终账户 B 的余额可能是300(线程 1 后于线程 2 写 B.balance,线程 2 写的 B.balance 值被线程 1 覆盖),可能是 100(线程 1 先于线程 2 写B.balance,线程 1 写的 B.balance 值被线程 2 覆盖),就是不可能是 200。
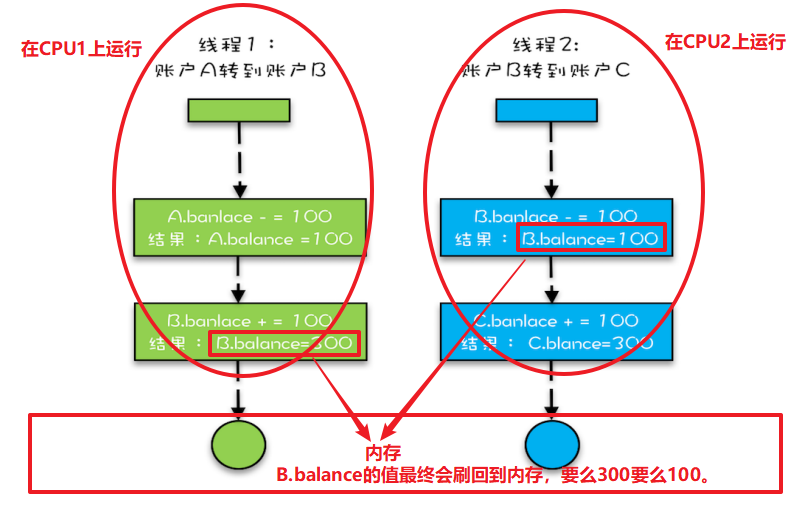
使用锁的正确方式
我们提到用同一把锁来保护多个资源,用个形象的词描述叫做“包场”,那么只要我们的锁能覆盖所有受保护资源就可以了。在上面的例子中,this 是对象级别的锁,所以 A 对象和 B 对象都有自己的锁,如何让A 对象和 B 对象共享一把锁呢?方式其实挺多的,比如:
①(不可取)可以让所有对象都持有一个唯一性的对象,这个对象在创建 Account 时传入。
但是在真实的项目场景中,创建Account对象的代码可能分散在多个工程中,传入共享的lock比较困难,缺乏可行性。
class Account { private Object lock; private int balance; private Account(); // 创建 Account 时传入同一个 lock 对象 public Account(Object lock) { this.lock = lock; } // 转账 void transfer(Account target, int amt){ // 此处检查所有对象共享的锁 synchronized(lock) { if (this.balance > amt) { this.balance -= amt; target.balance += amt; } } } }
②(可行,串行化,性能差)用Account.class作为共享的锁
class Account { private int balance; // 转账 void transfer(Account target, int amt){ synchronized(Account.class) { if (this.balance > amt) { this.balance -= amt; target.balance += amt; } } } }
③放弃只用一把锁,用多把锁(细粒度锁)
我们用 Account.class 作为互斥锁,虽然这个方案不存在并发问题,但是所有账户的转账操作都是串行的,性能太差。
我们可以使用细粒度锁来进行优化。
class Account { private int balance; // 转账 void transfer(Account target, int amt){ // 锁定转出账户 synchronized(this) { // 锁定转入账户 synchronized(target) { if (this.balance > amt) { this.balance -= amt; target.balance += amt; } } } } }
然而,使用细粒度锁是有代价的,这个代价就是可能会导致死锁。
5.死锁
对于上面的例子,假设线程t1执行A给B转账,同时线程t2执行B给A转账,则t1需要先锁定A账户再锁定B账户,t2需要先锁定B账户再锁定A账户。在这个过程中,可能会出现t1锁定A账户,准备锁定B账户,同时t2锁定了B账户,准备锁定A账户。两者呈现相互等待的局面,也就是发生了死锁。
只有以下这四个条件都发生时才会出现死锁:
1. 互斥,共享资源 X 和 Y 只能被一个线程占用;
2. 占有且等待,线程 T1 已经取得共享资源 X,在等待共享资源 Y 的时候,不释放共享资源 X;
3. 不可抢占,其他线程不能强行抢占线程 T1 占有的资源;
4. 循环等待,线程 T1 等待线程 T2 占有的资源,线程 T2 等待线程 T1 占有的资源,就是循环等待。
(死锁前预防)避免发生死锁:
只要破坏以上任何一条,就可以避免死锁
1.互斥没法破坏,因为用锁就是为了互斥
2.破坏占用且等待:一次性申请所有资源,就不存在等待了
/** * 要破坏这个条件,可以一次性申请所有资源。以转账操作为例,可以一次性申请所有资源:转出账户和转入账户 * * 具体实现:增加一个角色Allocator,负责全局的资源管理,必须是单例。它的具体作用是:同时申请资源 apply() 和同时释放资源 free()。 * 当账户 Account 在执行转账操作的时候,首先向 Allocator同时申请转出账户和转入账户这两个资源,成功后再锁定这两个资源; * 当转账操作执行完,释放锁之后,我们需通知 Allocator 同时释放转出账户和转入账户这两个资源。 */ class Allocator { private List<Object> als = new ArrayList<>(); // 一次性申请所有资源 synchronized boolean apply( Object from, Object to){ if(als.contains(from) || als.contains(to)){ return false; } else { als.add(from); als.add(to); } return true; } // 归还资源 synchronized void free( Object from, Object to){ als.remove(from); als.remove(to); } } class Account { // actr 应该为单例 private Allocator actr; private int balance; // 转账 void transfer(Account target, int amt){ // 一次性申请转出账户和转入账户,直到成功 while(!actr.apply(this, target)) ; try{ // 锁定转出账户 synchronized(this){ // 锁定转入账户 synchronized(target){ if (this.balance > amt){ this.balance -= amt; target.balance += amt; } } } } finally { actr.free(this, target) } } }
3.破坏不可抢占:占用资源的线程进一步申请其它资源时,如果申请不到,主动释放已占有的资源。这一点 synchronized是做不到的,因为线程获取不到资源会进入阻塞状态啥也干不了。但是SDK层面上提供的Lock可以实现。
4.破坏循环等待:可以按顺序申请,比如给资源编号,从小到大。
class Account { private int id; private int balance; // 转账 void transfer(Account target, int amt){ Account left = this ① Account right = target; ② if (this.id > target.id) { ③ left = target; ④ right = this; ⑤ } ⑥ // 锁定序号小的账户 synchronized(left){ // 锁定序号大的账户 synchronized(right){ if (this.balance > amt){ this.balance -= amt; target.balance += amt; } } } } }
(死锁后排查)分析dump转储文件 :
可以通过 jstack 命令或者Java VisualVM这个可视化工具将 JVM 所有的线程栈信息导出来,完整的线程栈信息不仅包括线程的当前状态、调用栈,还包括了锁的信息。
6.等待-通知机制
破坏占用且等待条件时,可以使用while死循环的方式来循环等待。
如果 apply() 操作耗时非常短,而且并发冲突量也不大时,这个方案还挺不错的,因为这种场景下,循环上几次或者几十次就能一次性获取转出账户和转入账户了。
// 一次性申请转出账户和转入账户,直到成功 while(!actr.apply(this, target)) ;
但是如果 apply() 操作耗时长,或者并发冲突量大的时候,循环等待这种方案就不适用了,因为在这种场景下,可能要循环上万次才能获取到锁太消耗CPU了。其实在这种场景下,最好的方案应该是:如果线程要求的条件(转出账本和转入账本同在文件架上)不满足,则线程阻塞自己,进入等待状态;当线程要求的条件(转出账本和转入账本同在文件架上)满足后,通知等待的线程重新执行。其中,使用线程阻塞的方式就能避免循环等待消耗CPU 的问题。
需要wait-notify/notifyAll需要注意的几点:
①被通知线程的执行时间点与通知时间点基本上不会重合,所以当线程执行时,很可能条件已经不满足了(有其它线程插队)。
所以通常会将wait()放在while循环中。利用这种范式可以解决上面提到的条件曾经满足过这个问题。范式,意味着是经典做法,所以没有特殊理由不要尝试换个写法。
while(条件不满足) { wait(); }
②被通知的线程要想重新执行,仍然需要获取到互斥锁(因为曾经获取的锁在调用wait()时已经释放了)
③wait()、notify()、notifyAll() 方法操作的等待队列是互斥锁的等待队列,所以如果 synchronized 锁定的是 this,那么对应的一定是 this.wait()、this.notify()、this.notifyAll();如果 synchronized 锁定的是 target,那么对应的一定是 target.wait()、target.notify()、target.notifyAll() 。
而且 wait()、notify()、notifyAll() 这三个方法能够被调用的前提是已经获取了相应的互斥锁,所以我们会发现 wait()、notify()、notifyAll() 都是在synchronized{}内部被调用的。如果在 synchronized{}外部调用,或者锁定的 this而用target.wait() 调用的话,JVM 会抛出一个运行时异常:java.lang.IllegalMonitorStateException。
④尽量使用notifyAll()
notify()是会随机地通知等待队列中的一个线程,而notifyAll()会通知等待队列中的所有线程。
7.安全性、活跃性以及性能问题
并发编程中我们需要注意的问题有很多,主要有三个方面,分别是:安全性问题、活跃性问题和性能问题。

8.管程
Java1.5 之前提供的唯一的并发原语就是管程,而且 1.5 之后提供的 SDK 并发包,也是以管程技术为基础的。
作者刚接触 Java 的时候,以为它会提供信号量这种编程原语。因为操作系统原理课程告诉我们,用信号量能解决所有并发问题,结果发现并非如此。后来才发现Java 采用的是管程技术,synchronized 关键字及 wait()、notify()、notifyAll() 这三个方法都是管程的组成部分。而管程和信号量是等价的,所谓等价指的是用管程能够实现信号量,也能用信号量实现管程。但是管程更容易使用,所以 Java 选择了管程。
管程,对应的英文是 Monitor,Java领域很多同学直译为监视器,操作系统领域一般都翻译成管程。
所谓管程,指的是管理共享变量以及对共享变量的操作过程,让他们支持并发。翻译为 Java 领域的语言,就是管理类的成员变量和成员方法,让这个类是线程安全的。那管程是怎么管的呢?
MESA 模型
管程发展史上出现的三种模型,Hasen模型、Hoare模型和MESA模型。现在广泛应用的是 MESA 模型,并且 Java 管程的实现参考的也是 MESA模型。
管程是如何解决互斥问题的?很简单,就是将共享变量及其对共享变量的操作统一封装起来。
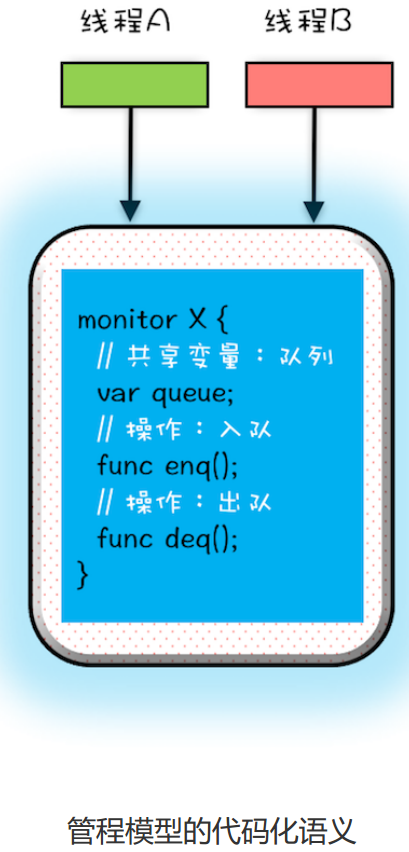
管程是如何解决同步问题的?
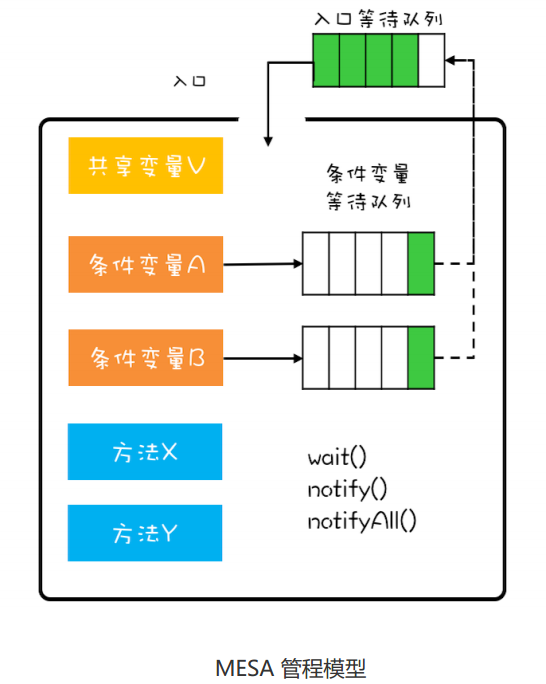
wait()的正确姿势
需要在while 循环里面调用 wait(),这个是 MESA 管程特有的。
while(条件不满足) { wait(); }
Hasen 模型、Hoare 模型和 MESA 模型的一个核心区别就是当条件满足后,如何通知相关线程。管程要求同一时刻只允许一个线程执行,那当线程 T2 的操作使线程 T1 等待的条件满足时,T1 和 T2 究竟谁可以执行呢?
1. Hasen 模型里面,要求 notify() 放在代码的最后,这样 T2 通知完 T1 后,T2 就结束了,然后 T1 再执行,这样就能保证同一时刻只有一个线程执行。
2. Hoare 模型里面,T2 通知完 T1 后,T2 阻塞,T1 马上执行;等 T1 执行完,再唤醒 T2,也能保证同一时刻只有一个线程执行。但是相比 Hasen 模型,T2 多了一次阻塞唤醒操作。
3. MESA 管程里面,T2 通知完 T1 后,T2 还是会接着执行,T1 并不立即执行,仅仅是从条件变量的等待队列进到入口等待队列里面。这样做的好处是 notify() 不用放到代码的最后,T2 也没有多余的阻塞唤醒操作。但是也有个副作用,就是当 T1 再次执行的时候,可能曾经满足的条件,现在已经不满足了,所以需要以循环方式检验条件变量。
何时可以使用notify()
使用notify需要满足以下三个条件:
- 1. 所有等待线程拥有相同的等待条件;
- 2. 所有等待线程被唤醒后,执行相同的操作;
- 3. 只需要唤醒一个线程。
9.线程的生命周期
通用的线程生命周期
通用的线程生命周期基本上可以用下图这个“五态模型”来描述。这五态分别是:初始状态、可运行状态、运行状态、休眠状态和终止状态。
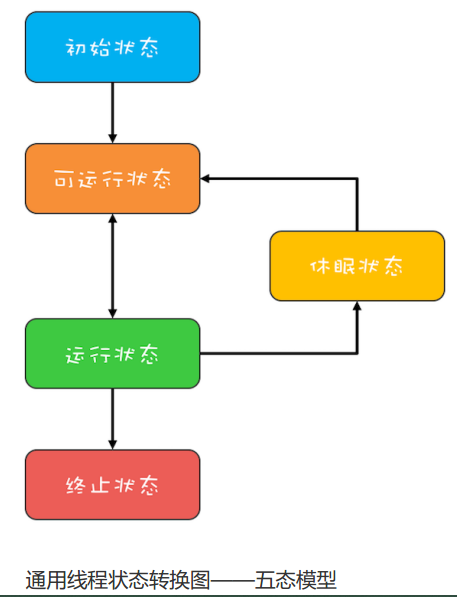
Java 语言里把可运行状态和运行状态合并了,这两个状态在操作系统调度层面有用,而 JVM 层面不关心这两个状态,因为 JVM 把线程调度交给操作系统处理了。除了状态合并,Java 语言细化了休眠状态。
Java 中线程的生命周期
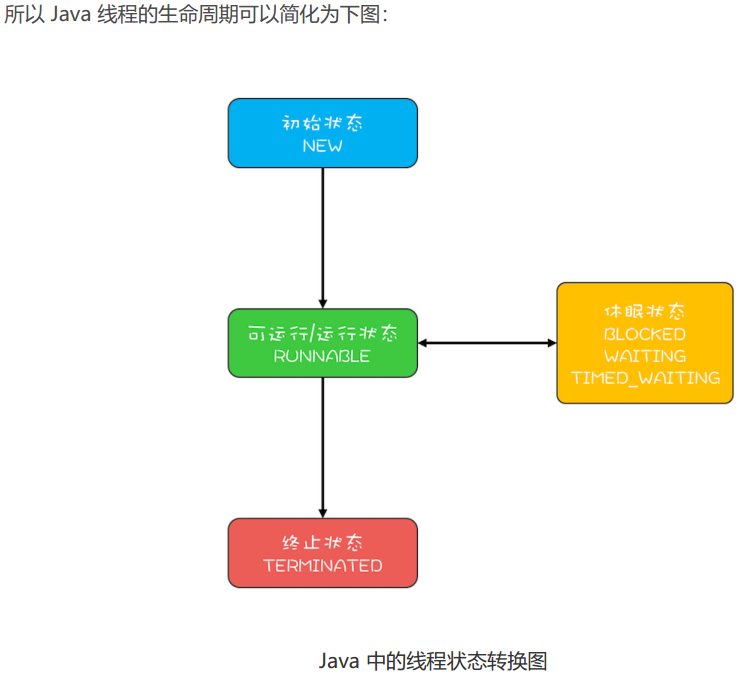
在操作系统层面,Java 线程中的 BLOCKED、WAITING、TIMED_WAITING 是一种状态,即前面我们提到的休眠状态。只要 Java线程处于这三种状态之一,那么这个线程就永远没有 CPU 的使用权。
多线程问题调试
理解 Java 线程的各种状态以及生命周期对于诊断多线程 Bug 非常有帮助,多线程程序很难调试,出了 Bug 基本上都是靠日志,靠线程 dump 来跟踪问题,分析线程 dump 的一个基本功就是分析线程状态,大部分的死锁、饥饿、活锁问题都需要跟踪分析线程的状态。
可以通过 jstack 命令或者Java VisualVM这个可视化工具将 JVM 所有的线程栈信息导出来,完整的线程栈信息不仅包括线程的当前状态、调用栈,还包括了锁的信息。
10.创建多少线程数最合适
- 对于 CPU 密集型的计算场景,理论上“线程的数量 =CPU 核数”就是最合适的。不过在工程上,线程的数量一般会设置为“CPU 核数 +1”,这样的话,当线程因为偶尔的内存页失效或其他原因导致阻塞时,这个额外的线程可以顶上,从而保证 CPU 的利用率。
- 对于 I/O 密集型计算场景,最佳的线程数是与程序中 CPU 计算和 I/O 操作的耗时比相关的,我们可以总结出这样一个公式:
单核 CPU:最佳线程数 =1 +(I/O 耗时 / CPU 耗时)
多核 CPU:最佳线程数 =CPU 核数 * [ 1 +(I/O 耗时 / CPU 耗时)]
对于 I/O 密集型计算场景,I/O 耗时和 CPU 耗时的比值是一个关键参数,不幸的是这个参数是未知的,而且是动态变化的,所以工程上,我们要估算这个参数,然后做各种不同场景下的压测来验证我们的估计。不过工程上,原则还是将硬件的性能发挥到极致,所以压测时,我们需要重点关注 CPU、I/O 设备的利用率和性能指标(响应时间、吞吐量)之间的关系。
11.局部变量是安全的
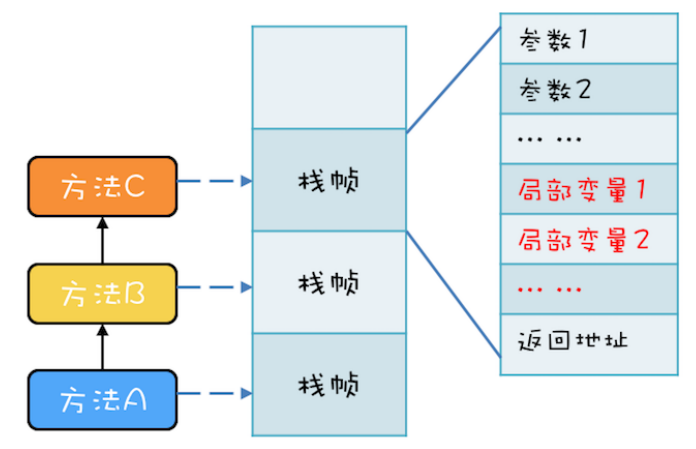
方法里的局部变量不会在线程间共享,所以没有并发问题,我们称之为线程封闭。
采用线程封闭技术的案例非常多,比如ThreadLocal,最经典的案例要属数据库连接池通过线程封闭技术,保证一个 Connection 一旦被一个线程获取之后,在这个线程关闭 Connection 之前的这段时间里,不会再分配给其他线程,从而保证了 Connection 不会有并发问题。
ThreadLocal<Connection>
12.如何用面向对象思想写好并发程序
在工作中,很多同学在设计之初都是直接按照单线程的思路来写程序的,而忽略了本应该重视的并发问题;等上线后的某天,突然发现诡异的 Bug,再历经千辛万苦终于定位到问题所在,却发现对于如何解决已经没有了思路。
正是基于以上原因,作者才展开了“如何用面向对象思想写好并发程序”这个话题。
面向对象思想与并发编程本来是没关系的,它们分属两个不同的领域。但是在 Java语言里,这两个领域融合在一起了,好在融合的效果还是不错的:在 Java 语言里,面向对象思想能够让并发编程变得更简单。
如何才能用面向对象思想写好并发程序呢,作者结合自己的工作经验,认为可以从封装共享变量、识别共享变量间的约束条件和制定并发访问策略这三个方面下手。
①.封装共享变量
面向对象思想里面有一个很重要的特性是封装,利用面向对象思想写并发程序的思路,其实很简单:将共享变量作为对象属性封装在内部,对所有公共方法制定并发访问策略。
例如下面实现的一个计数器。
public class Counter { private long value; synchronized long get(){ return value; } synchronized long addOne(){ return ++value; } }
另外,很多共享变量的值是不会变的,对于这些不会发生变化的共享变量,建议使用 final 关键字来修饰。这样既能避免并发问题,也能很明了地表明你的设计意图,让后面接手你程序的兄弟知道,你已经考虑过这些共享变量的并发安全问题了。
②.识别共享变量间的约束条件
识别共享变量间的约束条件非常重要。因为这些约束条件,决定了并发访问策略。
共享变量之间的约束条件反映在代码里,基本上都会有 if 语句,所以,一定要特别注意竞态条件。
/** * 例如:库存管理里面有个合理库存的概念,库存量不能太高,也不能太低,它有一个上限和一个下限。 * ①upper和lower这两个变量用了AtomicLong原子类,是线程安全的,所以这两个成员变量的set方法就不需要同步了。 * ②库存下限要小于库存上限:需要有if判断操作,存在竞态条件 */ public class SafeWM { // 库存上限 private final AtomicLong upper = new AtomicLong(0); // 库存下限 private final AtomicLong lower = new AtomicLong(0); // 设置库存上限 void setUpper(long v){ // 检查参数合法性 if (v < lower.get()) { throw new IllegalArgumentException(); } upper.set(v); } // 设置库存下限 void setLower(long v){ // 检查参数合法性 if (v > upper.get()) { throw new IllegalArgumentException(); } lower.set(v); } // 省略其他业务代码 }
③.制定并发访问策略
制定并发访问策略,是一个非常复杂的事情。不过从方案上来看,无外乎就是以下“三件事”。
- 1. 避免共享:避免共享的技术主要是利于线程本地存储以及为每个任务分配独立的线程。
- 2. 不变模式:这个在 Java 领域应用的很少,但在其他领域却有着广泛的应用,例如 Actor 模式、CSP 模式以及函数式编程的基础都是不变模式。
- 3. 管程及其他同步工具:Java 领域万能的解决方案是管程,但是对于很多特定场景,使用 Java并发包提供的读写锁、并发容器等同步工具会更好。
除了这些方案之外,还有一些宏观的原则,有助于我们写出“健壮”的并发程序。这些原则主要有以下三条。
- 1. 优先使用成熟的工具类:Java SDK 并发包里提供了丰富的工具类,基本上能满足你日常的需要,建议你熟悉它们,用好它们,而不是自己再“发明轮子”,毕竟并发工具类不是随随便便就能发明成功的。
- 2. 迫不得已时才使用低级的同步原语:低级的同步原语主要指的是 synchronized、Lock、Semaphore 等,这些虽然感觉简单,但实际上并没那么简单,一定要小心使用。
- 3. 避免过早优化:安全第一,并发程序首先要保证安全,出现性能瓶颈后再优化。在设计期和开发期,很多人经常会情不自禁地预估性能的瓶颈,并对此实施优化,但残酷的现实却是:性能瓶颈不是你想预估就能预估的。
13.热点问题答疑
1. 用锁的最佳实践
①可变的对象不适合用作锁。Integer 和 String ,Boolean类型的对象不适合做锁,普通类型变量也不适合做锁。
Integer 和 String 类型的对象在 JVM 里面会被重用。重用意味着锁可能被其他代码使用,锁一旦被其它程序占用而不释放,那你的程序就永远拿不到锁,这是隐藏的风险。
(Integer存在缓存机制)
class Account { // 账户余额 private Integer balance; // 账户密码 private String password; // 取款 void withdraw(Integer amt) { synchronized(balance) { if (this.balance > amt){ this.balance -= amt; } } } // 更改密码 void updatePassword(String pw){ synchronized(password) { this.password = pw; } } }
②锁应是私有的、不可变的、不可重用的。
//下面是使用锁的最佳实践:虽然写法其貌不惊人,却能避免各种意想不到的坑, // 普通对象锁 private final Object lock = new Object(); // 静态对象锁 private static final Object lock = new Object();
2. 锁的性能要看场景
对于破坏死锁的四个条件之一——破坏占用且等待条件,可以有下面两种处理方式,但两者性能存在差异。
//1.死循环方式 // 先一次性申请转出账户和转入账户,直到成功 while(!actr.apply(this, target)); // 再依次锁定转出账户和转入账户 synchronized(this){ synchronized(target){ } } //2.类锁方式 synchronized(Account.class)
如果操作(apply)非常费时,那么前者的性能优势就体现出来了,因为前者允许 A->B、C->D 这种转账业务的并行。
不同的并发场景用不同的方案,这是并发编程里面的一项基本原则。
3. 竞态条件需要格外关注
//contains() 和 add() 方法虽然都是线程安全的,但组合在一起不是线程安全的 void addIfNotExist(Vector v, Object o){ if(!v.contains(o)) {//静态条件 v.add(o); } }
4. 方法调用是先计算参数
有人认为set(get()+1);这条语句是进入 set() 方法之后才执行 get() 方法,其实并不是这样的。方法的调用,是先计算参数,然后将参数压入调用栈之后才会执行方法体。
/*********假设当前日志级别为INFO***********/ //会计算字符串的值 logger.debug("The var1:" + var1 + ", var2:" + var2); //【推荐】【占位符写法】,仅将参数压栈,不会计算字符串的值 logger.debug("The var1:{}, var2:{}", var1, var2);
5. InterruptedException 异常处理需小心
//以下代码目的是:借用sleep能捕获中断异常的特点来设置中断标识,从而使程序退出while循环。 //然而在触发 InterruptedException 异常的同时,JVM 会同时把线程的中断标志位清除 Thread th = Thread.currentThread(); while(true) { if(th.isInterrupted()) { break; } // 省略业务代码无数 try { Thread.sleep(100); }catch (InterruptedException e){ e.printStackTrace(); } }
正确的做法应该是捕获中断异常后,再恢复中断标识。【这点我也经常忘记】【这点我也经常忘记】【这点我也经常忘记】
catch (InterruptedException e){ // 重新设置中断标志位 th.interrupt(); e.printStackTrace(); }
6. 理论值 or 经验值
实际工作中,不同的 I/O 模型对最佳线程数的影响非常大,例如大名鼎鼎的 Nginx 用的是非阻塞 I/O,采用的是多进程单线程结构,Nginx 本来是一个 I/O 密集型系统,但是最佳进程数设置的却是 CPU 的核数,完全参考的是 CPU 密集型的算法。所以,理论我们还是要活学活用。
二、Java并发工具类
14.Lock&Condition(上):隐藏在并发包中的管程
并发编程领域,有两大核心问题:一个是互斥,即同一时刻只允许一个线程访问共享资源;另一个是同步,即线程之间如何通信、协作。这两大问题,管程都是能够解决的。
Java SDK 并发包通过 Lock 和 Condition 两个接口来实现管程,其中 Lock 用于解决互斥问题,Condition 用于解决同步问题。
再造管程的理由
Java 语言层面本身提供的 synchronized来实现了管程,那为什么还要在 SDK 层面再提供另外一种实现呢?
原因就是synchronized 申请资源失败,线程会一直进入阻塞状态。如果该线程在之前就成功申请了其它资源,则进入阻塞状态后其它资源也得不到释放。
如何设计一个互斥锁来解决synchronized的问题呢?
- 1. 能够响应中断。synchronized 的问题是,持有锁 A 后,如果尝试获取锁 B 失败,那么线程就进入阻塞状态,一旦发生死锁,就没有任何机会来唤醒阻塞的线程。但如果阻塞状态的线程能够响应中断信号,也就是说当我们给阻塞的线程发送中断信号的时候,能够唤醒它,那它就有机会释放曾经持有的锁 A。这样就破坏了不可抢占条件了。
- 2. 支持超时。如果线程在一段时间之内没有获取到锁,不是进入阻塞状态,而是返回一个错误,那这个线程也有机会释放曾经持有的锁。这样也能破坏不可抢占条件。
- 3. 非阻塞地获取锁。如果尝试获取锁失败,并不进入阻塞状态,而是直接返回,那这个线程也有机会释放曾经持有的锁。这样也能破坏不可抢占条件。
以上三种方案对应了Lock 接口中的三个API
// 支持中断的 API void lockInterruptibly() throws InterruptedException; // 支持超时的 API boolean tryLock(long time, TimeUnit unit) throws InterruptedException; // 支持非阻塞获取锁的 API boolean tryLock();
如何保证可见性
Java里多线程的可见性是通过 Happens-Before 规则保证的,而 synchronized 之所以能够保证可见性,也是因为有一条 synchronized 相关的规则:synchronized 的解锁 Happens-Before 于后续对这个锁的加锁。
而ReentrantLock(Lock接口的默认实现)的可见性则是利用了 volatile 相关的 Happens-Before规则。ReentrantLock底层是AQS实现的,AQS中有个state属性是volatile的。
可重入锁
可重入锁,指的是线程可以重复获取同一把锁。
可重入函数指的是多个线程可以同时调用该函数,每个线程都能得到正确结果;多线程可以同时执行,还支持线程切换意味着可重入函数是线程安全的。
公平锁与非公平锁
ReentrantLock构造函数可以传入fair参数,表示锁的公平策略,true 就表示需要构造一个公平锁,反之则表示要构造一个非公平锁。默认是非公平锁。
如果是公平锁,唤醒的策略就是谁等待的时间长就唤醒谁。
如果是非公平锁,则不保证公平,有可能等待时间短的线程先被唤醒。
用锁的最佳实践
锁最佳实践有很多,推荐并发大师 Doug Lea《Java 并发编程:设计原则与模式》一书中,推荐的三个用锁的最佳实践:
- 1. 永远只在更新对象的成员变量时加锁
- 2. 永远只在访问可变的成员变量时加锁
- 3. 永远不在调用其他对象的方法时加锁
第3条可能会过于严苛。但是建议还是要遵守,因为调用其他对象的方法,实在是太不安全了,也许“其他”方法里面有线程 sleep()的调用,也可能会有慢 I/O 操作,这些都会严重影响性能。更可怕的是,“其他”类的方法可能也会加锁,然后双重加锁就可能导致死锁。
思考题:
//下面代码虽然不会存在死锁,但是可能会存在活锁。 class Account { private int balance; private final Lock lock = new ReentrantLock(); // 转账 void transfer(Account tar, int amt){ while (true) { if(this.lock.tryLock()) { try { if (tar.lock.tryLock()) { try { this.balance -= amt; tar.balance += amt; } finally { tar.lock.unlock(); } }//if } finally { this.lock.unlock(); } }//if }//while }//transfer }
15.Lock和Condition(下):Dubbo如何用管程实现异步转同步?
前面介绍了Lock,这篇介绍了Condition。Condition 实现了管程模型里面的条件变量。
Java 语言内置的管程里只有一个条件变量,而 Lock&Condition 实现的管程是支持多个条件变量的,这是二者的一个重要区别。
在很多并发场景下,支持多个条件变量能够让我们的并发程序可读性更好,实现起来也更容易。比如一个典型的场景就是阻塞队列,就需要两个条件变量,一个notEmplty,一个notFull。
如何利用两个条件变量实现阻塞队列?
略
同步与异步
同步是Java 代码默认的处理方式。如果你想让你的程序支持异步,可以通过下面两种方式来实现:
- 1. 调用方创建一个子线程,在子线程中执行方法调用,这种调用我们称为异步调用;
- 2. 方法实现的时候,创建一个新的线程执行主要逻辑,主线程直接 return,这种方法我们一般称为异步方法。
Dubbo中的异常转同步
TCP 协议本身就是异步的,而我们工作中经常用到的 RPC 调用却大多数都是同步的,在 TCP 协议层面,发送完 RPC 请求后,线程是不会等待 RPC 的响应结果的。这是怎么回事呢?
那是因为有人帮你做了异步转同步的事情,Dubbo框架中就存在这样的转换。
//【异步转同步:当RPC返回结果之前,阻塞调用线程,让调用线程等待;当RPC返回结果后,唤醒调用线程,让调用线程重新执行。这不就是经典的等待 - 通知机制吗?】 // 创建锁与条件变量 private final Lock lock = new ReentrantLock(); private final Condition done = lock.newCondition(); // 调用方通过该方法等待结果 Object get(int timeout){ long start = System.nanoTime(); lock.lock(); try { while (!isDone()) {//通过经典的在循环中调用 await()方法来实现等待。 done.await(timeout); long cur=System.nanoTime(); if (isDone() || cur-start > timeout){ break; } } } finally { lock.unlock(); } if (!isDone()) { throw new TimeoutException(); } return returnFromResponse(); } // RPC 结果是否已经返回 boolean isDone() { return response != null; } // RPC 结果返回时调用该方法 private void doReceived(Response res) { lock.lock(); try { response = res; if (done != null) { done.signal();//通知调用线程,结果已经返回,不用继续等待了。 } } finally { lock.unlock(); } }
最近这几年,工作中需要异步处理的越来越多了,其中有一个主要原因就是有些 API 本身就是异步 API。例如websocket 也是一个异步的通信协议,如果基于这个协议实现一个简单的 RPC,你也会遇到异步转同步的问题。
现在很多公有云的 API 本身也是异步的,例如创建云主机,就是一个异步的API,调用虽然成功了,但是云主机并没有创建成功,你需要调用另外一个 API 去轮询云主机的状态。(itest项目中提交成绩和获取成绩结果就类似于这种情况:异步提交,然后需要通过轮训去获取结果)
如果你需要在项目内部封装创建云主机的 API,你也会面临异步转同步的问题,因为同步的 API 更易用。
16.Semaphore:如何快速实现一个限流器?
在管程被提出来之前,信号量一直都是并发编程领域的终结者。目前几乎所有支持并发编程的语言都支持信号量机制。
信号量模型
信号量模型还是很简单的,可以简单概括为:一个计数器,一个等待队列,三个方法init()、down() 和 up()。三个方法详细的语义如下:
- init():设置计数器的初始值。
- down():计数器的值减 1;如果此时计数器的值小于 0,则当前线程将被阻塞,否则当前线程可以继续执行。
- up():计数器的值加 1;如果此时计数器的值小于或者等于 0,则唤醒等待队列中的一个线程,并将其从等待队列中移除。

信号量模型里面,down()、up() 这两个操作历史上最早称为 P 操作和 V 操作,所以信号量模型也被称为 PV 原语。在 Java SDK 并发包里,down() 和 up() 对应的则是acquire() 和 release()。
如何使用信号量
只需要在进入临界区之前执行一下 down 操作,也就是Semaphore#acquire() ,退出临界区之前执行一下 up() 操作,也就是Semaphore#release()就可以了。
信号量是如何保证互斥的
假设两个线程 T1 和 T2 同时访问 addOne()方法,当它们同时调用 acquire() 的时候,由于 acquire() 是一个原子操作,所以只能有一个线程(假设 T1)把信号量里的计数器减为 0,另外一个线程(T2)则是将计数器减为 -1。对于线程 T1,信号量里面的计数器的值是 0,大于等于 0,所以线程 T1 会继续执行;对于线程 T2,信号量里面的计数器的值是 -1,小于 0,按照信号量模型里对 down() 操作的描述,线程 T2 将被阻塞。所以此时只有线程 T1 会进入临界区执行count+=1;。
当线程 T1 执行 release() 操作,也就是 up() 操作的时候,信号量里计数器的值是 -1,加 1 之后的值是 0,小于等于 0,按照信号量模型里对 up() 操作的描述,此时等待队列中的 T2 将会被唤醒。于是 T2 在 T1 执行完临界区代码之后才获得了进入临界区执行的机会,从而保证了互斥性。
有了lock为啥还要提供Semaphore
实现一个互斥锁仅仅是Semaphore 的部分功能,Semaphore 还有一个功能是 Lock 不容易实现的,那就是:Semaphore可以允许多个线程访问一个临界区。
现实中比较常见的需求就是我们工作中遇到的各种池化资源,例如连接池、对象池、线程池等等。例如我们熟悉的数据库连接池,在同一时刻,一定是允许多个线程同时使用连接池的,每个连接在被释放前,是不允许其他线程使用的。
信号量在 Java 语言里面名气并不算大,但是在其他语言里却是很有知名度的。Java 在并发编程领域走的很快,重点支持的还是管程模型。 管程模型理论上解决了信号量模型的一些不足,主要体现在易用性和工程化方面,例如用信号量解决我们曾经提到过的阻塞队列问题,就比管程模型麻烦很多。
快速实现一个限流器
需求:实现一个对象池。所谓对象池呢,指的是一次性创建出 N 个对象,之后所有的线程重复利用这 N 个对象。对象在被释放前也是不允许其他线程使用的。
思路:对象池可以用 List 保存实例对象。但关键是限流器的设计,这里的限流,指的是不允许多于 N 个线程同时进入临界区。那如何快速实现一个这样的限流器呢?这种场景,可以立刻想到信号量的解决方案。
public class ObjPool { final List<T> pool; // 用信号量实现限流器 final Semaphore sem; // 构造函数 ObjPool(int size, T t) { pool = new Vector<T>(); for (int i = 0; i < size; i++) { pool.add(t); } sem = new Semaphore(size); } // 利用对象池的对象,调用 func R exec(Function<T, R> func) { T t = null; sem.acquire(); try { t = pool.remove(0);//为每个线程分配了一个对象 t return func.apply(t); } finally { pool.add(t); sem.release(); } } } // 创建对象池 ObjPool<Long, String> pool = new ObjPool<Long, String>(10, 2); // 通过对象池获取 t,之后执行 pool.exec(t -> { System.out.println(t); return t.toString(); });
17.ReadWriteLock:如何快速实现一个完备的缓存?
Java中的管程和信号量理论上任何一个都可以解决所有的并发问题。但是Java SDK 并发包里为什么还有很多其他的工具类呢?原因很简单:分场景优化性能,提升易用性。
针对读多写少这种并发场景,Java SDK 并发包提供了读写锁——ReadWriteLock。读写锁都遵守以下三条基本原则:
- 1. 允许多个线程同时读共享变量;(读读不互斥)
- 2. 只允许一个线程写共享变量;(写写互斥)
- 3. 如果一个写线程正在执行写操作,此时禁止读线程读共享变量。(读写互斥)
读写锁的升级与降级
先获取读锁,然后再获取写锁,称为锁的升级。ReadWriteLock 并不支持锁的升级,获取读锁后,如果要再获得写锁,需要先释放读锁。
如果读锁还没有释放,此时获取写锁,可能会导致写锁永久等待,最终导致相关线程都被阻塞,永远也没有机会被唤醒。锁的升级是不允许的,这个一定要注意。
虽然锁的升级是不允许的,但是锁的降级却是允许的。
class CachedData { Object data; volatile boolean cacheValid; final ReadWriteLock rwl = new ReentrantReadWriteLock(); // 读锁 final Lock r = rwl.readLock(); // 写锁 final Lock w = rwl.writeLock(); void processCachedData() { // 获取读锁 r.lock(); if (!cacheValid) { // 释放读锁,因为不允许读锁的升级 r.unlock(); // 获取写锁 w.lock(); try { // 再次检查状态 if (!cacheValid) { data = ... cacheValid = true; } // 释放写锁前,降级为读锁。降级是可以的 r.lock(); ① } finally { // 释放写锁 w.unlock(); } } // 此处仍然持有读锁 try {use(data);} finally {r.unlock();} } }
18.StampedLock:比读写锁更快的锁
Java1.8里提供了一种叫 StampedLock 的锁,它的性能就比读写锁还要好,同样适用于读多写少的场景。
StampedLock 支持的三种锁模式
ReadWriteLock 支持两种模式:一种是读锁,一种是写锁。
StampedLock 支持三种模式,分别是:写锁、悲观读锁和乐观读。
写锁、悲观读锁的语义和 ReadWriteLock 的写锁、读锁的语义非常类似,允许多个线程同时获取悲观读锁,但是只允许一个线程获取写锁,写锁和悲观读锁是互斥的。不同的是:StampedLock 里的写锁和悲观读锁加锁成功之后,都会返回一个stamp;然后解锁的时候,需要传入这个 stamp
StampedLock性能更好的原因
StampedLock 的性能之所以比 ReadWriteLock 还要好,其关键是 StampedLock 支持乐观读的方式。ReadWriteLock 支持多个线程同时读,但是当多个线程同时读的时候,所有的写操作会被阻塞;而 StampedLock 提供的乐观读,是允许一个线程获取写锁的,也就是说不是所有的写操作都被阻塞。
StampedLock 使用注意事项
①对于读多写少的场景 StampedLock 性能很好,简单的应用场景基本上可以替代 ReadWriteLock,但是StampedLock 的功能仅仅是 ReadWriteLock 的子集
②StampedLock 不支持重入
③StampedLock 的悲观读锁、写锁都不支持条件变量
④如果线程阻塞在 StampedLock 的 readLock() 或者 writeLock()上时,此时调用该阻塞线程的 interrupt() 方法,会导致 CPU 飙升。
所以,使用 StampedLock 一定不要调用中断操作,如果需要支持中断功能,一定使用可中断的悲观读锁 readLockInterruptibly() 和写锁 writeLockInterruptibly()。这个规则一定要记清楚。
19.CountDownLatch和CyclicBarrier:如何让多线程步调一致
结合对账系统的业务进行性能优化,写的非常好。直接参考原文,不再赘述。
20.并发容器:都有哪些“坑”需要我们填?
如何将非线程安全的容器变成线程安全的容器?
只要把非线程安全的容器封装在对象内部,然后控制好访问路径就可以了。但尤其要注意组合操作,组合操作往往隐藏着竞态条件问题,即便每个操作都能保证原子性,也并不能保证
组合操作的原子性。
Java SDK中Collections 这个类中已经提供了一套完备的包装类,分别把 ArrayList、HashSet 和 HashMap 包装成了线程安全的 List、Set 和 Map。
List list = Collections.synchronizedList(new ArrayList()); Set set = Collections.synchronizedSet(new HashSet()); Map map = Collections.synchronizedMap(new HashMap());
在容器领域,用迭代器遍历容器容易入坑。
List list = Collections.synchronizedList(new ArrayList()); synchronized (list) { Iterator i = list.iterator(); while (i.hasNext())//组合操作,不具备原子性 foo(i.next()); }
应该改为下面的写法
//锁住 list 之后再执行遍历操作 List list = Collections.synchronizedList(new ArrayList()); synchronized (list) { Iterator i = list.iterator(); while (i.hasNext()) foo(i.next()); }
同步容器和并发容器
同步容器的所有方法都用 synchronized 来保证互斥,串行度高,性能太差。Java在1.5及之后的版本提供了性能更高的并发容器。
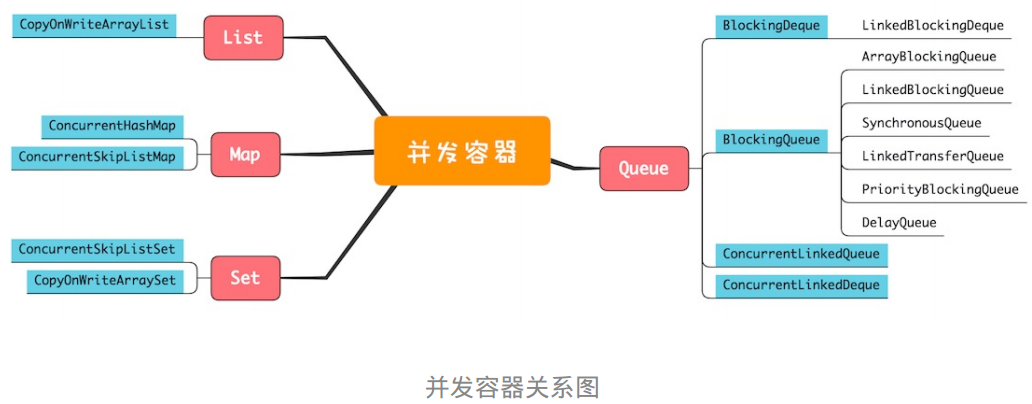
(List)
CopyOnWriteArrayList :仅适用于读多写少的场景
(Map)
ConcurrentHashMap的key是无序的,而ConcurrentSkipListMap的key是ConcurrentHashMap的key是无序的,而ConcurrentSkipListMap的key是有序的。所以如果需要保证 key 的顺序,就只能使用 ConcurrentSkipListMap。
ConcurrentHashMap:线程安全的Map
ConcurrentSkipListMap:跳表。跳表插入、删除、查询操作平均的时间复杂度是 O(log n)。在并发度非常高的情况下,若对 ConcurrentHashMap 的性能还不满意,可以使用ConcurrentSkipListMap。
(Set)
CopyOnWriteArraySet
ConcurrentSkipListSet
(Queue)
单端阻塞队列:
ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue、LinkedTransferQueue、PriorityBlockingQueue 和 DelayQueue
双端阻塞队列 :LinkedBlockingDeque
单端非阻塞队列:ConcurrentLinkedQueue
双端非阻塞队列:ConcurrentLinkedDeque
| 单端 | 双端 | |
| 阻塞 | ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue、LinkedTransferQueue、PriorityBlockingQueue 和 DelayQueue | LinkedBlockingDeque |
| 非阻塞 | ConcurrentLinkedQueue | ConcurrentLinkedDeque |
实际工作中,一般都不建议使用无界的队列,因为数据量大了之后很容易导致OOM。上面我们提到的这些 Queue 中,只有 ArrayBlockingQueue 和 LinkedBlockingQueue 是支持有界的。
21.原子类:无锁工具类的典范
无锁方案的实现原理
CPU 为了解决并发问题,提供了 CAS 指令,该指令是原子操作。
CAS 指令包含 3 个参数:共享变量的内存地址 A、用于比较的值 B 和共享变量的新值 C;并且只有当内存中地址 A 处的值等于 B时,才能将内存中地址 A 处的值更新为新值 C。
CAS通常会伴随自旋一起使用。
//CAS的经典用法 do { // 获取当前值 oldV = xxxx; // 根据当前值计算新值 newV = ...oldV... }while(!compareAndSet(oldV,newV);
ABA问题
可能大多数情况下我们并不关心 ABA 问题,例如数值的原子递增,但也不能所有情况下都不关
心,例如原子化的更新对象很可能就需要关心 ABA 问题,因为两个 A 虽然相等,但是第二个 A
的属性可能已经发生变化了。所以在使用 CAS 方案的时候,一定要先 check 一下。
原子类AtomicLong的getAndIncrement()方法内部就是基于CAS实现的,在Java 1.8中的实现如下。
final long getAndIncrement() { return unsafe.getAndAddLong(this, valueOffset, 1L); } public final long getAndAddLong(Object o, long offset, long delta){ long v; do { // 读取内存中的值 v = getLongVolatile(o, offset); } while (!compareAndSwapLong(o, offset, v, v + delta)); return v; } // 原子性地将变量更新为 x // 条件是内存中的值等于 expected // 更新成功则返回 true native boolean compareAndSwapLong(Object o, long offset, long expected, long x);
原子类概览
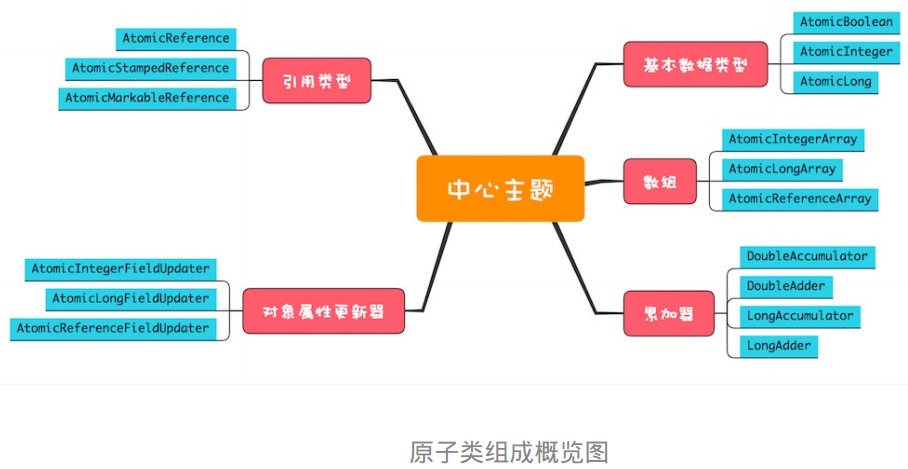
| 类型 | 相关原子类 | 备注 |
|
原子化的基本数据类型 |
AtomicBoolean、AtomicInteger、AtomicLong |
|
|
原子化的对象引用类型 |
AtomicReference、AtomicStampedReference 、AtomicMarkableReference |
利用它们可以实现对象引用的原子化更新。
AtomicReference 提供的方法和原子化的基本数据类型差不多。
不过对象引用的更新需要注意ABA 问题,AtomicStampedReference 和 AtomicMarkableReference 这两个原子类可以解决 ABA 问题。
AtomicStampedReference 实现的 CAS 方法就增加了版本号参数,AtomicMarkableReference 的实现机制则更简单,将版本号简化成了一个 Boolean 值
|
|
原子化数组 |
AtomicIntegerArray AtomicLongArray AtomicReferenceArray |
利用它们可以原子化地更新数组里面的每一个元素。 这些类提供的方法和原子化的基本数据类型的区别仅仅是:每个方法多了一个数组的索引参数,所以这里也不再赘述了。 |
|
原子化对象属性更新器 |
AtomicIntegerFieldUpdater AtomicLongFieldUpdater AtomicReferenceFieldUpdater |
利用它们可以原子化地更新对象的属性,这三个方法都是利用反射机制实现的 |
| 原子化的累加器 |
DoubleAccumulator DoubleAdder LongAccumulator LongAdder
|
这四个类仅仅用来执行累加操作,相比原子化的基本数据类型,速度更快,但是不支持 compareAndSet() 方法。 如果你仅仅需要累加操作,使用原子化的累加器性能会更好。 |
总结
①无锁方案相对于互斥锁方案,优点非常多,首先性能好,其次是基本不会出现死锁问题(但可能出现饥饿和活锁问题,因为自旋会反复重试)。
②Java 提供的原子类大部分都实现了compareAndSet() 方法,基于 compareAndSet() 方法可以构建自己的无锁数据结构,但是不建议这样做,这个工作最好还是让大师们去完成,原因是无锁算法没你想象的那么简单。
③所有原子类的方法都是针对一个共享变量的,如果需要解决多个变量的原子性问题,建议还是使用互斥锁方案。
22.Executor与线程池
一般意义上的池化资源,都是当你需要资源的时候就调用acquire()方法来申请资源,用完之后就调用release()释放资源。但线程池却一般的池化资源不同,线程池里面压根就没有申请线程和释放线程的方法。
线程池是一种生产者-消费者模式
线程池的使用方是生产者,线程池本身是消费者。
使用线程池
①强烈建议使用有界队列
Java并发包里提供了一个线程池的静态工厂类Executors,利用Executors你可以快速创建线程池。不过目前大厂的编码规范中基本上都不建议使用Executors。因为Executors提供的很多方法默认使用的都是无界的LinkedBlockingQueue,高负载情境下无界队列很容易导致OOM,而OOM会导致所有请求都无法处理,这是致命问题。所以强烈建议使用有界队列。
而使用有界队列,当任务过多时,线程池会触发执行拒绝策略。
②默认拒绝策略要慎重使用
线程池默认的拒绝策略会throw RejectedExecutionException,这是个运行时异常,对于运行时异常编译器并不强制catch它,所以开发人员很容易忽略。如果线程池处理的任务非常重要,建议自定义自己的拒绝策略;并且在实际工作中,自定义的拒绝策略往往和降级策略配合使用。
③注意异常处理的问题
例如通过ThreadPoolExecutor对象的execute()方法提交任务时,如果任务在执行的过程中出现运行时异常,会导致执行任务的线程终止;不过,最致命的是任务虽然异常了,但是你却获取不到任何通知,这会让你误以为任务都执行得很正常。虽然线程池提供了很多用于异常处理的方法,但是最稳妥和简单的方案还是捕获所有异常并按需处理,可以参考下面的代码。
try{ //业务逻辑 }catch(RuntimeException x){ //按需处理 }catch(Throwable x) { //按需处理 }
23.Future:如何用多线程实现最优的“烧水泡茶”程序?
//线程池提供了以下几种执行任务的方法 // 提交Runnable任务 public void execute(Runnable command) // 提交Runnable任务 public Future<?> submit(Runnable task) // 提交Callable任务 public <T> Future<T> submit(Callable<T> task) // 提交Runnable任务及结果引用 public <T> Future<T> submit(Runnable task, T result)
如果要获得执行结果,则需要提交Callable任务,通过Future的get()方法来获取结果。如果任务还没执行完,get会一直阻塞知道获取到结果。
Future只是一个接口,而FutureTask是一个实实在在的工具类,它同时实现了Runnable和Future接口。由于实现了Runnable接口,所以可以将FutureTask对象作为任务被Thread执行,或提交给ThreadPoolExecutor去执行;又因为实现了Future接口,所以也能用来获得任务的执行结果。
下面使用Future来实现实现最优的“烧水泡茶”程序
/** * 【FutureTask的使用】 * 线程T1和T2来完成烧水泡茶程序: * T1负责洗水壶、烧开水、泡茶这三道工序,T2负责洗茶壶、洗茶杯、拿茶叶三道工序, * 其中T1在执行泡茶这道工序时,需要等待T2完成拿茶叶的工序 * * 对于T1的这个等待动作,可以使用很多种方法来实现, * 例如Thread.join()、CountDownLatch,甚至阻塞队列。这里使用Future特性来实现。 */ public class FutureTaskDemo { public static void main(String[] args) throws ExecutionException, InterruptedException { FutureTask<String> task2 = new FutureTask<>(new T2Task()); //主工序 FutureTask<String> task1 = new FutureTask<>(new T1Task(task2)); Thread th1 = new Thread(task1); th1.start(); Thread th2 = new Thread(task2); th2.start(); //获取t1执行结果 System.out.println(task1.get()); } private static class T1Task implements Callable<String> { private FutureTask<String> task; public T1Task(FutureTask task) { this.task = task; } @Override public String call() throws Exception { System.out.println("洗水壶"); System.out.println("烧开水"); //获取t1线程的茶叶 String tea = task.get(); System.out.println("T1:拿到茶叶:" + tea); System.out.println("泡茶"); return "上茶:" + tea; } } private static class T2Task implements Callable { @Override public String call() throws Exception { System.out.println("洗茶壶"); System.out.println("洗茶杯"); System.out.println("拿茶叶"); return "龙井"; } } }
利用多线程可以快速将一些串行的任务并行化,从而提高性能;如果任务之间有依赖关系,比如当前任务依赖前一个任务的执行结果,这种问题基本上都可以用Future来解决。在分析这种问题的过程中,建议用有向图描述一下任务之间的依赖关系,同时将线程的分工也做好。对照图来写代码,好处是更形象,且不易出错。
24.CompletableFuture:异步编程没那么难
Java1.8提供了CompletableFuture来支持异步编程,比较复杂。
使用CompletableFuture重新实现前面的烧水泡茶程序
/** * CompletableFuture:java在1.8中提供的,用来支持异步编程。可能是最复杂的工具了。 * <p> * 我们分了3个任务: * 任务1负责洗水壶、烧开水 * 任务2负责洗茶壶、洗茶杯和拿茶叶 * 任务3负责泡茶,要等待任务1和任务2都完成后才能开始。 */ public class CompletableFutureDemo { public static void main(String[] args) { //任务1:洗水壶-->烧开水 CompletableFuture<Void> f1 = CompletableFuture.runAsync(() -> { System.out.println("T1:洗⽔壶..."); sleep(1, TimeUnit.SECONDS);//模拟耗时 System.out.println("T1:烧开⽔..."); sleep(2, TimeUnit.SECONDS);//模拟耗时 }); //任务2:洗茶壶->洗茶杯->拿茶叶 CompletableFuture<String> f2 = CompletableFuture.supplyAsync(() -> { System.out.println("T2:洗茶壶..."); sleep(1, TimeUnit.SECONDS); System.out.println("T2:洗茶杯..."); sleep(2, TimeUnit.SECONDS); System.out.println("T2:拿茶叶..."); sleep(1, TimeUnit.SECONDS); return "⻰井"; }); //任务3:任务1和任务2完成后执⾏:泡茶 CompletableFuture<String> f3 = f1.thenCombine(f2, (__, tf) -> { System.out.println("T1:拿到茶叶:" + tf); System.out.println("T1:泡茶..."); return "上茶:" + tf; }); //等待任务3执⾏结果 System.out.println(f3.join()); } private static void sleep(int time, TimeUnit unit) { try { unit.sleep(time); } catch (InterruptedException e) { } } } //⼀次执⾏结果: T1:洗⽔壶... T2:洗茶壶... T1:烧开⽔... T2:洗茶杯... T2:拿茶叶... T1:拿到茶叶:⻰井 T1:泡茶... 上茶:⻰井
CompletableFuture的使用
1.创建CompletableFuture对象
创建CompletableFuture对象主要靠下面的这4个静态方法
//使用默认线程池 static CompletableFuture<Void> runAsync(Runnable runnable) static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier) //手动指定线程池 static CompletableFuture<Void> runAsync(Runnable runnable, Executor executor) static <U> CompletableFuture<U> supplyAsync(Supplier<U> supplier, Executor executor)
默认情况下CompletableFuture会使用公共的ForkJoinPool线程池,这个线程池默认创建的线程数是CPU的核数(也可以通过JVM option:-Djava.util.concurrent.ForkJoinPool.common.parallelism来设置ForkJoinPool线程池的线程数)。如果所有CompletableFuture共享一个线程池,那么一旦有任务执行一些很慢的I/O操
作,就会导致线程池中所有线程都阻塞在I/O操作上,从而造成线程饥饿,进而影响整个系统的性能。所以,强烈建议根据不同的业务类型创建不同的线程池,以避免互相干扰。
创建完CompletableFuture对象之后,会自动地异步执行runnable.run()方法或者supplier.get()方法,对于一个异步操作,你需要关注两个问题:
①异步操作什么时候结束,
②如何获取异步操作的执行结果。
因为CompletableFuture类实现了Future接口,所以这两个问题可以通过Future接口来解决。另外,CompletableFuture类还实现了CompletionStage接口,这个接口内容实在是太丰富了,在1.8版本里有40个方法,这些方法我们该如何理解呢?
如何理解CompletionStage接口
可以站在分工的角度类比一下工作流。任务是有时序关系的,比如有串行关系、并行关系、汇聚关系等。比如前面烧水泡茶的例子,其中洗水壶和烧开水就是串行关系,洗水壶、烧开水和洗茶壶、洗茶杯这两组任务之间就是并行关系,而烧开水、拿茶叶和泡茶就是汇聚关系。
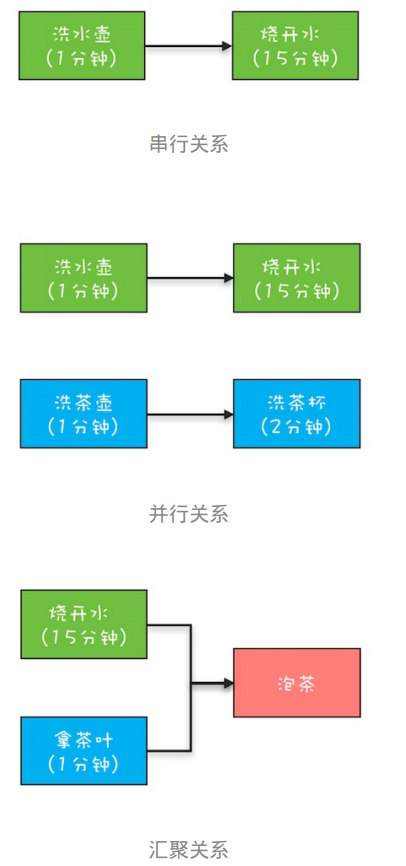
CompletionStage接口可以清晰地描述任务之间的这种时序关系,例如前面提到的 f3 = f1.thenCombine(f2, ()->{}) 描述的就是一种汇聚关系。
烧水泡茶程序中的汇聚关系是一种 AND 聚合关系,这里的AND指的是所有依赖的任务(烧开水和拿茶叶)都完成后才开始执行当前任务(泡茶)。既然有AND聚合关系,那就一定还有OR聚合关系,所谓OR指的是依赖的任务只要有一个完成就可以执行当前任务。
CompletionStage接口如何描述串行关系、AND聚合关系、OR聚合关系以及异常处理。
1. 描述串行关系
CompletionStage接口里面描述串行关系,主要是thenApply、thenAccept、thenRun和thenCompose这四个系列的接口。
CompletionStage<R> thenApply(fn); CompletionStage<R> thenApplyAsync(fn); CompletionStage<Void> thenAccept(consumer); CompletionStage<Void> thenAcceptAsync(consumer); CompletionStage<Void> thenRun(action); CompletionStage<Void> thenRunAsync(action); CompletionStage<R> thenCompose(fn); CompletionStage<R> thenComposeAsync(fn);
通过下面的示例代码,你可以看一下thenApply()方法是如何使用的。首先通过supplyAsync()启动一个异步流程,之后是两个串行操作,整体看起来还是挺简单的。不过,虽然这是一个异步流程,但任务①②③却是串行执行的,②依赖①的执行结果,③依赖②的执行结果。
CompletableFuture<String> f0 = CompletableFuture.supplyAsync( () -> "Hello World") //① .thenApply(s -> s + " QQ") //② .thenApply(String::toUpperCase);//③ System.out.println(f0.join()); // 输出结果:HELLO WORLD QQ
2. 描述AND汇聚关系
CompletionStage接口里面描述AND汇聚关系,主要是thenCombine、thenAcceptBoth和runAfterBoth系列的接口,这些接口的区别也是源自fn、consumer、action这三个核心参数不同
CompletionStage<R> thenCombine(other, fn); CompletionStage<R> thenCombineAsync(other, fn); CompletionStage<Void> thenAcceptBoth(other, consumer); CompletionStage<Void> thenAcceptBothAsync(other, consumer); CompletionStage<Void> runAfterBoth(other, action); CompletionStage<Void> runAfterBothAsync(other, action);
3. 描述OR汇聚关系
CompletionStage接口里面描述OR汇聚关系,主要是applyToEither、acceptEither和runAfterEither系列的接口,这些接口的区别也是源自fn、consumer、action这三个核心参数不同。
CompletionStage applyToEither(other, fn);
CompletionStage applyToEitherAsync(other, fn);
CompletionStage acceptEither(other, consumer);
CompletionStage acceptEitherAsync(other, consumer);
CompletionStage runAfterEither(other, action);
CompletionStage runAfterEitherAsync(other, action);
下面的示例代码展示了如何使用applyToEither()方法来描述一个OR汇聚关系。
CompletableFuture<String> f1 = CompletableFuture.supplyAsync(()->{ int t = getRandom(5, 10); sleep(t, TimeUnit.SECONDS); return String.valueOf(t); }); CompletableFuture<String> f2 = CompletableFuture.supplyAsync(()->{ int t = getRandom(5, 10); sleep(t, TimeUnit.SECONDS); return String.valueOf(t); }); CompletableFuture<String> f3 = f1.applyToEither(f2,s -> s); System.out.println(f3.join());
4. 异常处理
虽然上面我们提到的fn、consumer、action它们的核心方法都不允许抛出可检查异常,但是却无法限制它 不允许抛出可检查异常,但是却无法限制它们抛出运行时异常 们抛出运行时异常,例如下面的代码,执行 7/0 就会出现除零错误这个运行时异常。非异步编程里面,我们可以使用try{}catch{}来捕获并处理异常,那在异步编程里面,异常该如何处理呢?
CompletableFuture<Integer> f0 = CompletableFuture. .supplyAsync(()->(7/0)) .thenApply(r->r*10); System.out.println(f0.join());
CompletionStage接口给我们提供的方案非常简单,比try{}catch{}还要简单,下面是相关的方法,使用这些方法进行异常处理和串行操作是一样的,都支持链式编程方式。
CompletionStage exceptionally(fn); CompletionStage<R> whenComplete(consumer); CompletionStage<R> whenCompleteAsync(consumer); CompletionStage<R> handle(fn); CompletionStage<R> handleAsync(fn);
下面的示例代码展示了如何使用exceptionally()方法来处理异常,exceptionally()的使用非常类似于try{}catch{}中的catch{},但是由于支持链式编程方式,所以相对更简单。既然有try{}catch{},那就一定还有try{}finally{},whenComplete()和handle()系列方法就类似于try{}finally{}中的finally{},无论是否发生异常都会执行whenComplete()中的回调函数consumer和handle()中的回调函数fn。whenComplete()和handle()的区别在于whenComplete()不支持返回结果,而handle()是支持返回结果的。
CompletableFuture<Integer> f0 = CompletableFuture .supplyAsync(()->7/0)) .thenApply(r->r*10) .exceptionally(e->0); System.out.println(f0.join());
前些年,一提到异步编程大家脑海里浮现的就是声名狼藉的回调地狱(Callback Hell)问题。近几年,随着ReactiveX的发展(Java语言的实现版本是RxJava),回调地狱已经被完美解决了,异步编程已经慢慢开始成熟,Java语言也开始官方支持异步编程:在1.8版本提供了CompletableFuture,Java 9版本提供了更加完备的Flow API,异步编程目前已经完全工业化。因此,学好异步编程还是很有必要的。CompletableFuture已经能够满足简单的异步编程需求,如果你对异步编程感兴趣,可以重点关注RxJava这个项目,利用RxJava,也支持Java1.6。
25.CompletionService:如何批量执行异步任务?
26.ForkJoin:单机版的MapReduce
27.并发工具类模块热点问题答疑
三、并发编程设计模式
28-Immutability模式:如何利用不变性解决并发问题?
29-Copy-on-Write模式:不是延时策略的COW
30-线程本地存储模式:没有共享,就没有伤害
31-GuardedSuspension模式:等待唤醒机制的规范实现
32-Balking模式:再谈线程安全的单例模式
33-Thread-Per-Message模式:最简单实用的分工方法
34-WorkrThrad模式:如何避免重复创建线?
35-两阶段终止模式:如何优雅地终止线程?
优雅的终止线程
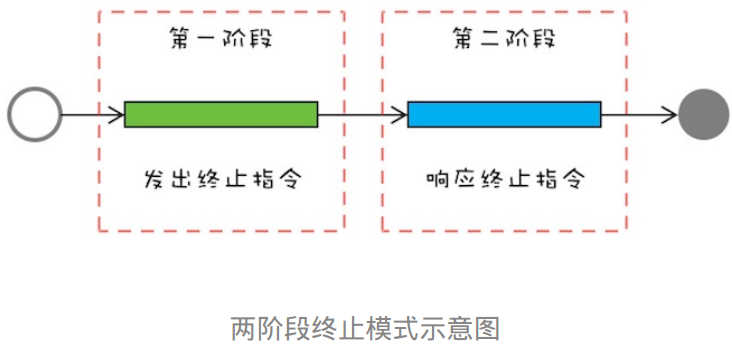
线程自己运行结束后终止,这是自己终止自己。而要在线程T1中终止线程T2,可以使用stop方法,但是stop方法不太优雅,因为粗暴的结束线程可能会导致数据的不一致,所以已被弃用。优雅的终止线程的方式是使用两阶段终止模式,给即将终止的线程料理后事的机会。
两阶段终止模式将终止过程分成两个阶段,其中第一个阶段主要是线程T1向线程T2发送终止指令,而第二阶段则是线程T2响应终止指令。
具体实现起来,有两种方式:
①使用一个volatile标识来控制
②使用中断机制
class Proxy { boolean started = false; //采集线程 Thread rptThread; //启动采集功能 synchronized void start() { //不允许同时启动多个采集线程 if (started) { return; } started = true; rptThread = new Thread(() -> { while (!Thread.currentThread().isInterrupted()) { //省略采集、回传实现 report(); //每隔两秒钟采集、回传⼀次数据 try { Thread.sleep(2000); } catch (InterruptedException e) { //【重新设置线程中断状态】 Thread.currentThread().interrupt(); } } //执⾏到此处说明线程⻢上终⽌ started = false; }); rptThread.start(); } //【终⽌采集功能】 synchronized void stop() { rptThread.interrupt(); } }
上述代码中,我们选择的标志位是线程的中断状态。
但是建议你在实际工作中谨慎使用。原因在于我们很可能在线程的run()方法中调用第三方类库提供的方法,而我们没有办法保证第三方类库正确处理了线程的中断异常,例如第三方类库在捕获到Thread.sleep()方法抛出的中断异常后,没有重新设置线程的中断状态,那么就会导致线程不能够正常终止。所以强烈建议你设置自己的线程终止标志位。
class Proxy { //【线程终⽌标志位】 volatile boolean terminated = false; boolean started = false; //采集线程 Thread rptThread; //启动采集功能 synchronized void start() { if (started) { return; } started = true; terminated = false; rptThread = new Thread(() -> { //【使用自己的线程终止标志位】 while (!terminated) { //省略采集、回传实现 report(); //每隔两秒钟采集、回传⼀次数据 try { Thread.sleep(2000); } catch (InterruptedException e) { //重新设置线程中断状态 Thread.currentThread().interrupt(); } } //执⾏到此处说明线程⻢上终⽌ started = false; }); rptThread.start(); } //终⽌采集功能 synchronized void stop() { //【设置中断标志位】 terminated = true; //中断线程rptThread rptThread.interrupt(); } }
优雅的终止线程池
线程池提供了两个方法:shutdown()和shutdownNow()
如果提交到线程池的任务不允许取消,那就不能使用shutdownNow()方法终止线程池。不过,如果线程池的任务允许后续以补偿的方式重新执行,也是可以使用shutdownNow()方法终止线程池的。参考《Java并发编程实战》这本书第7章《取消与关闭》的“shutdownNow的局限性”一节中。
36-生产者-消费者模式:用流水线思想提高效率
37-设计模式模块热点问题答疑
四、案例分析
五、其它并发模型
