RabbitMQ知识汇总
1、引入RabbitMQ能带来哪些好处和坏处?
消息队列的作用,可以用四个词来概括:削峰,填谷,异步,解耦。
应用解耦(系统拆分)
异步处理(预约挂号业务处理成功后,异步发送短信、推送消息、日志记录等)
消息分发
流量削峰
消息缓冲
引入消息队列,会有什么缺点?
- 降低了系统可用性:本来系统运行好好的,引入消息队列进去,如果消息队列挂了,业务系统也可能会跟着挂。因此,系统可用性降低
- 增加了系统复杂性:引入消息队列需要多考虑很多方面的问题,比如一致性问题、如何保证消息不被重复消费,如何保证保证消息可靠传输。因此,系统复杂性增加。
2、消息队列如何选型?
使用MQ之前,需要对市面上的MQ进行调研,不同的MQ可能会支持不同的特性。
参考:RabbitMQ、Kafka、RocketMQ正确选型姿势【消息中间件篇】
3、RabbitMQ的几种工作模式
官网:https://www.rabbitmq.com/getstarted.html
RabbitMQ有以下几种工作模式 :
1、Work queues
Distributing tasks among workers (the competing consumers pattern)

2、Publish/Subscribe
Sending messages to many consumers at once
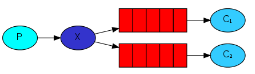
3、Routing
Receiving messages selectively

4、Topics
Receiving messages based on a pattern (topics)

5、RPC
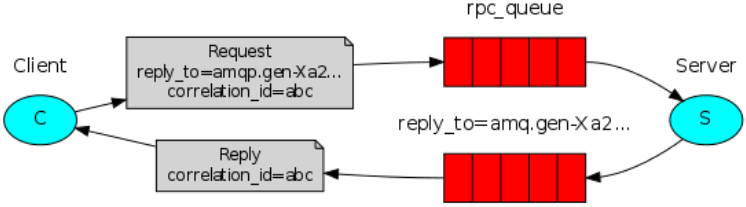
4、消息队列高可用
5、如何保证消息的可靠传输?
6、如何保证消息不被重复消费(消息幂等)?
在互联网应用中,尤其在网络不稳定的情况下,RabbitMQ的消息有可能会出现重复,消息重复的可能原因如下:
- 发送时消息重复
当一条消息已被成功发送到服务端并完成持久化,此时出现了网络闪断或者客户端宕机,导致服务端对客户端应答失败。 如果此时Producer意识到消息发送失败并尝试再次发送消息,Consumer后续会收到两条内容相同并且Message ID也相同的消息。
- 投递时消息重复
消息消费的场景下,消息已投递到Consumer并完成业务处理,当客户端给服务端反馈应答的时候网络闪断。为了保证消息至少被消费一次,消息队列RabbitMQ版的服务端将在网络恢复后再次尝试投递之前已被处理过的消息,Consumer后续会收到两条内容相同并且Message ID也相同的消息。
- 负载均衡时消息重复(包括但不限于网络抖动、服务端重启以及Consumer应用重启)
当RabbitMQ服务端或客户端重启、扩容或缩容时,会触发Rebalance,此时Consumer可能会收到重复消息。
需要结合业务来处理,有以下几种思路:
1)(写Mysql)借助数据库的主键唯一性
如果是重复数据,再次重复插入时,会因数据库主键冲突而插入失败,这样就保证不会插入重复数据。(捕获该主键重复的异常,就能得知是重复消息了)
2)(写Redis)借助Redis的原子性
接收到消息后,将消息ID作为key执行 setnx 命令,如果执行成功就表示没有处理过这条消息,可以进行消费了。执行失败表示消息已经被消费了。
3)状态机
有些业务是有状态流转的,每个状态都有前置状态、后置状态和最终状态。例如,订单的待提交,待支付,已支付,取消。在订单支付时,先从数据库查询一下订单的状态,如果未支付则调用支付接口扣款。如果是已支付,则不再处理,也就不会重复扣款。
4)全局消息ID
可以是用全局的消息id来控制幂等性。发消息时为消息设置全局唯一的ID,在消息被消费了之后我们可以选择缓存保存这个消息id,然后当再次消费的时候,我们可以查询缓存,如果存在这个消息id,我们就不做处理直接返回即可。
以Message ID为幂等键对消息进行幂等处理的步骤如下:
3.在Consumer客户端根据唯一Message ID对消息进行幂等处理。
channel.basicConsume(Producer.QueueName, false, "YourConsumerTag", new DefaultConsumer(channel) { @Override public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException { // 1. 获取业务唯一性索引数据。 try{ String messageId = properties.getMessageId(); // Message ID或者其他作为unique key的信息。 // 2. 开启数据库事务。 idempTable.insert(messageId); // 3. 对接收到的消息,进行业务逻辑处理。 // 4. 提交或回滚事务。// 处理成功,则进行ACK,否则不要进行ACK。 channel.basicAck(envelope.getDeliveryTag(), false); } catch (数据库主键冲突异常 e){ // 重复消息,直接确认掉。 channel.basicAck(envelope.getDeliveryTag(), false); } } });
7、如何保证消息的顺序消费?
(中华石杉)生产案例:基于mysql的binlog实现的系统。binlog必须要按照顺序来被重放。
消息错乱的场景
rabbitmq中,一个队列有多个消费者
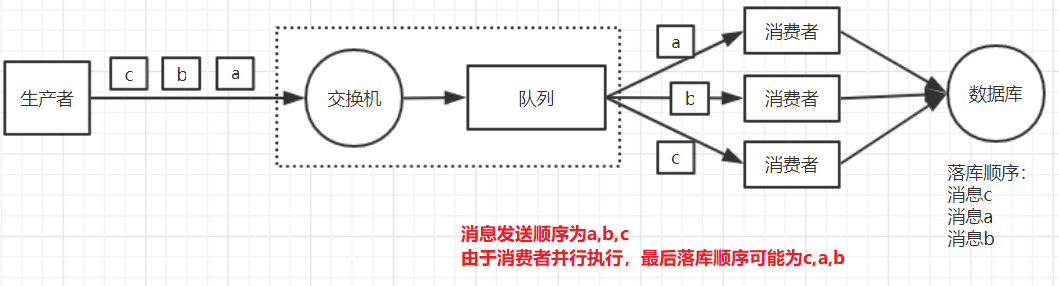
解决方法
将要保证顺序的消息都路由到同一队列,且该队列只有一个消费者,消费者就会按照顺序来消费消息。
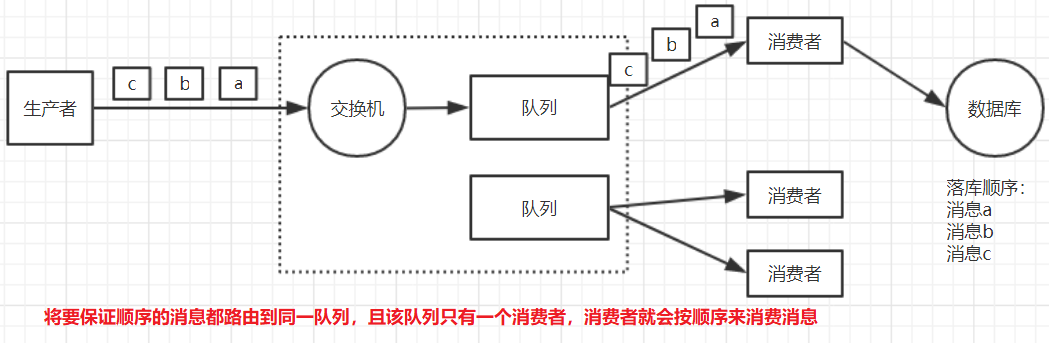
如果有多组消息,每组消息都要保证顺序,则可以用hash来将不同组的消息路由到不同队列。同一组的消息发到同一个队列中,同样每个队列只有一个消费者。

8.如何实现消息延迟消费?
RabbitMQ有两种方式来实现消息延迟:
①使用TTL和死信队列来实现
②使用RabbitMQ延迟插件来实现(推荐这种方式)
可以参考:
SpringBoot+RabbitMQ用死信队列和插件形式实现延迟队列
RabbitMQ延迟插件下载地址:rabbitmq-delayed-message-exchange
Delayed Message 插件实现 RabbitMQ 延迟队列(含原理和局限性)
9.如何解决线上消息积压问题?消息过期失效问题?队列满后该怎么处理?
第一个坑:大量消息在MQ里积压了几个小时
问题描述:
比如消费端出现问题,导致消息积压。比如,消费端挂了(如数据库挂了,不能落库),或者消费及其慢。
假设有3个消费者,每个消费者一秒处理1000条消息,一分钟则是六万条,一小时则是360万条,三个消费者一个小时就能消费大概一千万条了。如果消费者挂了,每个小时有一千万的消息积压量。
中华石杉线上遇到的生产问题:几千万条数据在MQ里积压了七八个小时。
解决方案:
修复消费者,让其恢复消费能力,然后等待慢慢的消费完。如果比较紧急,只能进行临时紧急扩容了,具体思路和操作如下:
①先修复消费者,确保其恢复消费能力,然后将现有消费者都停掉。
②临时建立好原有的10倍的队列数。
③写一个临时分发数据的消费者程序,进行部署用于消费积压的数据,消费时不做耗时的处理,直接均匀地轮询写入临时建立好的10倍数量的队列中。
④部署10倍的机器来部署消费者,每一批消费者消费一个临时队列的数据。
这种做法相当于临时将Queue和Consumer资源扩大了10倍,以正常的10倍速度来消费数据。等积压的数据消费完后,恢复原有的部署架构。
第二个坑:RabbitMQ设置TTL过期时间,导致消息丢失。
问题描述:
RabbitMQ可以设置消息的TTL过期时间,这是一个很大的坑,会造成消息过期丢失。(实际上TTL过期后,消息会变成死信消息)
解决方案:
方案一:
批量重导,相当于手动补偿消息。
中华石杉:也就是开发个临时程序将丢失的那批数据查出来,等过了高峰期,然后重新灌入MQ中,把丢失的消息补偿回来。我们生产上不允许设置过期时间,坑太大。
方案二(我的补充):
实际上TTL过期后,消息会变成死信消息,使用死信交换机,让消息进入死信队列,后续处理。
第三个坑:大量消息在MQ里积压了几个小时,导致磁盘空间都快满了
问题描述:
这与第一个坑的情况类似,都是消息积压,但是这种积压导致的MQ磁盘空间快满了。此时可能还有大量消息继续进来。所以快速将MQ中的消息削减掉是最重要的。
解决方案:
临时修改消费者代码,消费者不要落库,或拿到消息直接扔掉,让MQ中积压的消息快速削减下来。接下来与第一个坑中的解决方案类似,重新写个程序将丢失的数据查出来,等过了高峰期再灌入MQ中。
10.如何设计一个消息队列中间件?
1.可伸缩性,可以快速库容。
设计一个分布式的系统。
2.磁盘落地
磁盘落地怎么落?顺序写,这样就没有吸盘随机读写的寻址开销,磁盘顺序读写的性能是很高的,这就是kafka的思路。
3.高可用性
多副本。比如kafka的leader和follower,broker挂了就进行重新选举新leader对外服务。
Rabbitmq消费失败死信队列 (使用到业务交换机、死信交换机和告警交换机)
参考:分布式之消息队列复习精讲
