Mysql优化之索引生效和失效的典型场景
一、能够使用索引的典型场景
频繁作为查询条件的字段应该创建索引,通常where后面的字段会建立索引。而有些情况不适合创建索引例如:
唯一性太差的字段不适合单独创建索引
select * from emp where sex='男'
频繁变化的字段不应该创建索引
select * from emp where logincount=1
能够使用索引的典型场景
1.匹配全值
对索引中所有列都指定具体值。即是对索引中的所有列都有等值匹配的条件。
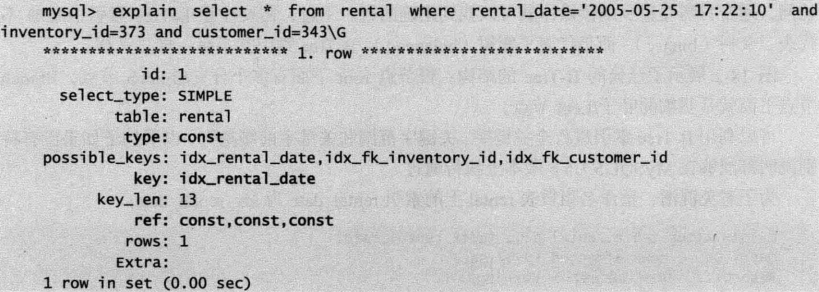
例如,通过指定出租日期、库存标号、客户编号的组合条件进行查询。
select * from rental where inventory=373 and customer_id=343
从执行计划的key和extra两个字段的值看到优化器选择了符合索引idx_rental_date。type为const表示常量,字段 key的值为idx_rental_date,表示优化器选择索引idx_rental_date进行扫描。
2.匹配值的范围查询
对索引的值进行范围查找。
例如,检索租赁表中客户编号在指定范围内的记录
//执行计划的type为range select * from rental where custom_id>=373 and custom_id<400
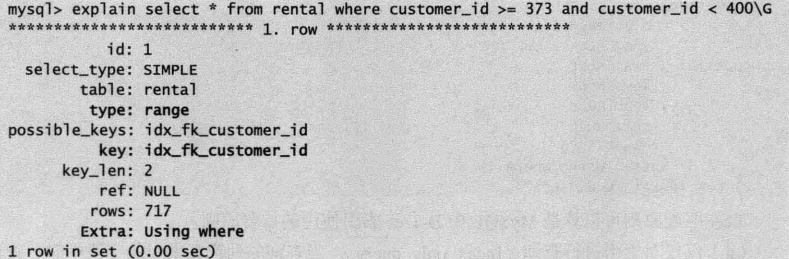
类型type为range说明优化器选择范围查询,索引key为idx_fk_customer_id说明优化器选择索引来加速访问。extra列为Using where,表示优化器除了利用索引加速访问,还需要根据索引回表查询数据。
3.匹配最左前缀
仅仅使用索引中的最左边列进行查找。比如在A+B+C字段上的联合索引能够被包含A、(A+B)、(A+B+C)的等值查询利用,但不能被B、(B+C)的等值查询使用到。
以支付表payment为例,如果查询条件中仅包含索引的第一列支付日期payment_date和索引的第三列更新时间last_update的时候,从执行计划的key和extra看到优化器仍然能够使用复合索引idx_payment_date进行条件过滤。
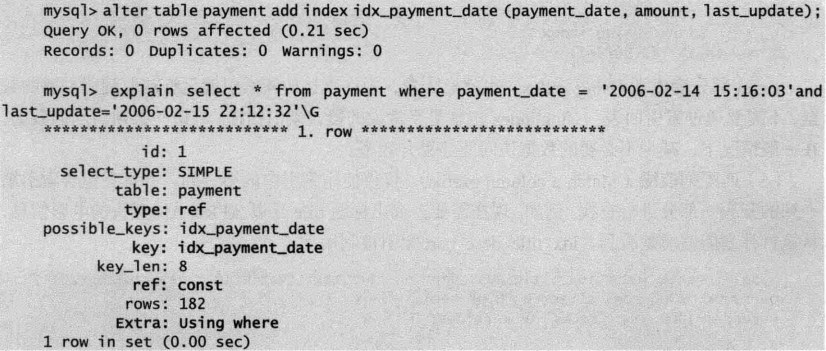
但是,如果仅仅选择符合索引idx_payment_date和第二列支付金额amount和第三列更新时间last_update进行查询时,那么执行计划显示并不会利用索引idx_payment_date。

4.仅仅对索引进行查询
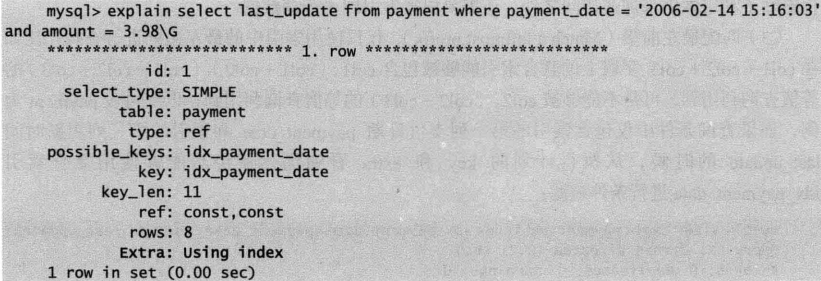
当查询的列都在索引的字段中时,查询的效率更高。
对比上个例子,本次查询的字段都包含在索引idx_payment_date中。Extra部分变成了Using index,意味着现在直接访问索引就足够获取到需要的数据,不需要通过索引回表,Using index相当于覆盖索引扫描。
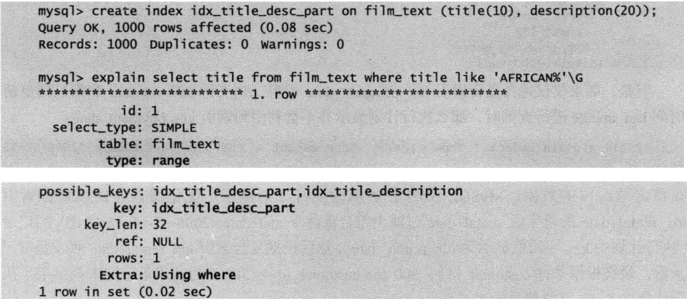
5.匹配列前缀
仅使用索引中的第一列,并且只包含索引第一列的开头一部分进行查找。
例如,查询标题title是以AFRICAN开头的电影信息。从查询计划可以看到,索引被用上了。Extra值为Using where表示优化器需要通过索引回表查询数据。
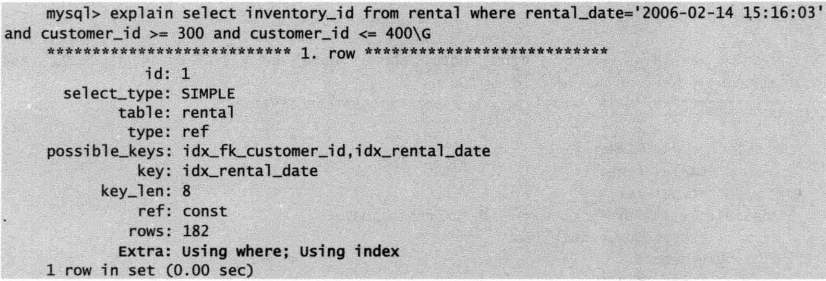
6.能够实现索引匹配部分精确,而其它部分进行范围匹配
例如,需要查询出租日期rental_date为指定日期且客户编号customer_id为指定范围的库存。类型type为range说明优化器选择范围查询,索引key为idx_rental_date说明优化器选择索引帮助加速查询,同时由于只查询索引在这段inventory_id的值,所以在Extra部分能看到Using index,表示查询使用了覆盖索引扫描。
7.如果列名是索引,那么使用column_name is null 就会使用索引
例如,支付表payment的租赁编号rental_id字段为空的记录就用到了索引。

8.Mysql5.6引入了Index Condition Pushdown(ICP)特性,进一步优化了查询。
Index Condition Pushdown(ICP),指的是在某些情况下,将条件过滤操作下放到存储引擎层来完成。ICP的相关介绍可以看我的另一篇博客:Mysql中的索引总结。
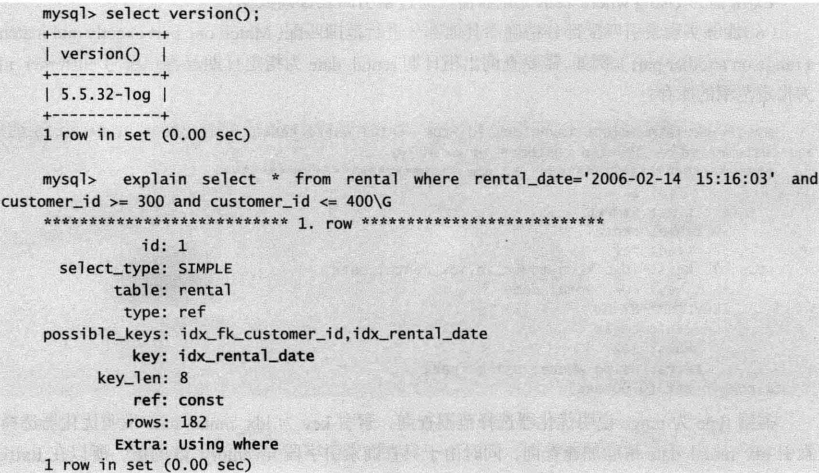
例如,查询租赁表汇总租赁时间在某一指定时间点且客户编号在指定范围内的数据。
select * from rental where rental_date='2006-02-14 15:16:03' and custom_id >= 300 and customer_id <= 400
Mysql5.5中,执行计划显示优化器首先使用复合索引的首字段rental_date过滤出符合条件的记录,然后根据复合索引回表获取记录后,最终根据条件过滤出最后的查询结果。(查询计划中,Extra字段值为Using where)
在Mysql5.6中,执行计划的extra部分从Using where变成了Using index condition,表示Mysql使用ICP来进一步优化查询,将条件custom_id的过滤下放到存储引擎层来完成,这样就能减少不必要的IO访问。

二、索引失效的典型场景
索引并不是创建后就一定会发挥作用,如果使用不恰当,则查询语句可能不利用索引来进行查询。下面是几种存在索引但不使用索引的典型场景。
1.以%开头的LIKE查询不能够利用B+树索引
这种情况,推荐使用全文索引(fulltext)。
select * from emp where last_name like '%NI%'(不会用索引)
2.数据类型中出现隐式转换时不会用到索引
特别是当列类型为字符串时,一定要在where条件中将字符串常量值用引号引起来,否则不会用到索引。
// last_name为字符串类型 // 不存在隐式转换 select * from actor where last_name='1' (会用到索引) // 存在隐式转换 select * from actor where last_name= 1 (不会用索引)
3.复合索引的情况下,查询条件不满足最左原则不会用到索引。
不满足最左原则(Leftmost),即查询条件不包含索引列最左边部分,这种情况是不能用到复合索引的。
select * from payment where amount=3.98 and last_update='2006-01-15 22:12:32(不会用索引)
4.用or分隔的条件,如果or前条件中的列有索引,而后面的列没有索引,那么涉及的索引都不会被用到(前面的索引也不会用到)。
原因:因为or后面的条件没有索引,必然会走全表扫描,在全表扫描情况下,就没有必要多一次索引扫描增加IO访问,一次全表扫描过滤条件就已经足够了。
// 其中customer_id建立了索引,amount未建立索引 select * from payment where customer_id=203 or amount = 3.1 (不会用索引)
5.如果Mysql估计使用索引比全表扫描更慢,则不使用索引。
