

MySQL索引数据结构选择
索引(index)是帮助MySQL高效获取数据的数据结构(有序)。在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
1、优缺点:
优势:
- 提高数据检索的效率,降低数据库的IO成本。
- 通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗。
劣势:
- 索引列也要占用空间的。
- 索引大大提高了查询效率,同时也降低更新表的速度,如果对表进行INSERT、UPDATE、DELETE时,效率降低。
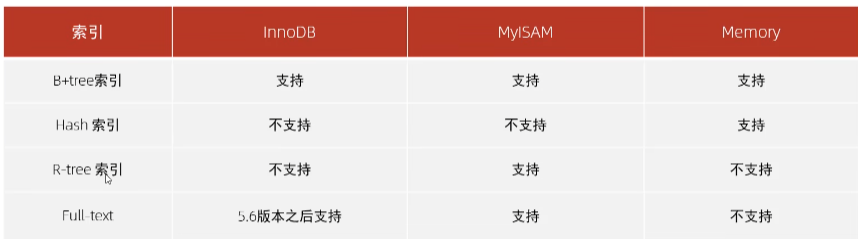
2、索引结构:
Mysql的索引是在存储引擎层实现的,不同的存储引擎有不同的结构,主要包含以下几种
- B+Tree索引:最常见的索引类型,大部分引擎都支持B+树索引;
- Hash索引:底层数据结构是用哈希表实现的,只有精确匹配索引列的查询才有效,不支持范围查询;
- tree(空间索引):空间索引是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少;
- Full-text(全文索引):是一种通过建立倒排索引,快速匹配文档的方式,类似于Lucene、Solr、ES;
3、数据结构特点分析:
二叉树

- 二叉树:顺序插入时,会形成一个链表,查询性能大大降低,大数量情况下,层级较深,检索速度慢。
- 红黑树:大数据量情况下,层级较深,检索速度慢。
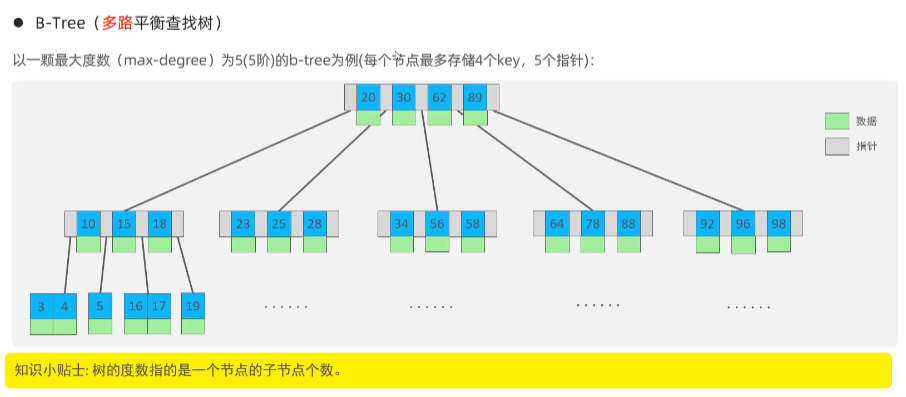
B-Tree
B+Tree
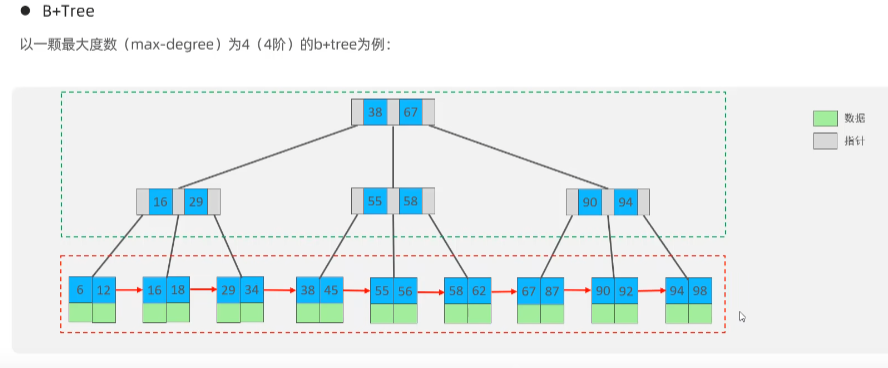
B+Tree相对于B-Tree区别:所有的数据都会出现在叶子节点;叶子节点形成一个单向链表;
MySQL索引数据结构对经典的B+Tree进行了优化,在原B+Tree的基础上,增加一个指向相邻叶子节点的链表指针,就形成了带有顺序指针的B+Tree,提高区间访问的性能。
Hash
哈希索引就是采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在hash表中。如果两个(或多个)键值,映射到一个相同的槽位上,他们就产生了hash冲突(也成为hash碰撞),可以通过链表来解决。
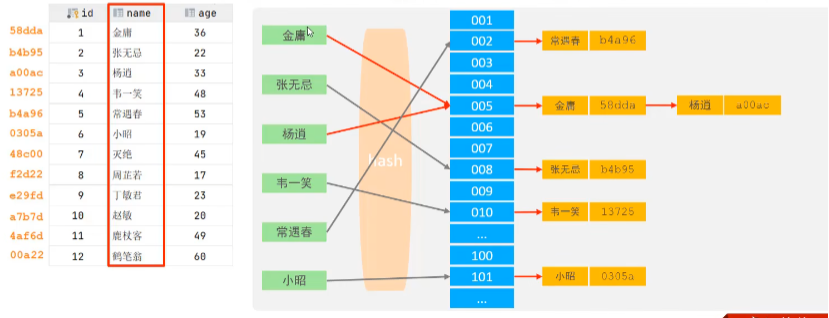
特点:
- hash索引只能用于对等比较(=,in),不支持范围查询(between,>,<);
- 无法利用索引完成排序操作;
- 查询效率高,通常只需要一次检索就可以了,效率通常要高于B+Tree索引;
- 在MySQL中,支持hash索引的是Memory引擎,而InnoDB中具有自适应hash功能,hash索引是存储引擎根据B+Tree索引在指定条件下自动构建的;
4、总结为什么选择B+Tree:
- 相对于二叉树,层级更少,索引效率高;
- B-Tree无论是叶子节点还是非叶子节点,都会保存数据,这样导致一页中存储的键值减少,指针跟着减少,要同样保存大量数据行,只能增加树的高度,导致性能降低;
- 相对于hash索引,B+Tree支持范围匹配及排序操作;
小贴士:https://www.cs.usfca.edu/~galles/visualization/Algorithms.html 数据结构可视化网站


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· SQL Server 2025 AI相关能力初探
· 单线程的Redis速度为什么快?
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码