SQL SERVER 物理分区和读写分离主从库数据同步
对于对现有系统进行数据性能优化顺序建议
1. 先考虑物理分区,因为物理分区对我们代码业务不会有改动,但是有局限性,优化效果不是很好
2. 再考虑读写分离,读写分离对代码改动不会太多,并且只试用超过读:写=8:2的比例,因为读写分离主要是缓解读数据库的压力,如果读的压力并没有那么大,就不用考虑这种方式
3. 最后考虑分库分表或者微服务,这种就是对业务代码进行大改,但是效果也是最好的
数据库物理分区
优势
1. 可以快速、高效地传输或访问数据的子集,同时又能维护数据收集的完整性。 例如,将数据从 OLTP 加载到 OLAP 系统之类的操作仅需几秒钟即可完成,而如果不对数据进行分区,执行此操作需要几分钟或几小时。 2. 可以更快地对一个或多个分区执行维护或数据保留操作。 这些操作的效率更高,因为它们仅针对这些数据子集,而非整个表。 例如,可以选择压缩一个或多个分区中的数据、重新生成索引的一个或多个分区或截断单个分区中的数据。 还可以将单个分区从一个表切换到存档表。 3. 可以根据经常运行的查询类型提高查询性能。 例如,在分区依据列与表联接的列相同时,查询优化器可以更快地处理两个或多个已分区表之间的相等联接查询。 有关详细信息,请参阅下面的查询。
使用
官网地址:https://learn.microsoft.com/zh-cn/sql/relational-databases/partitions/create-partitioned-tables-and-indexes?view=sql-server-ver16
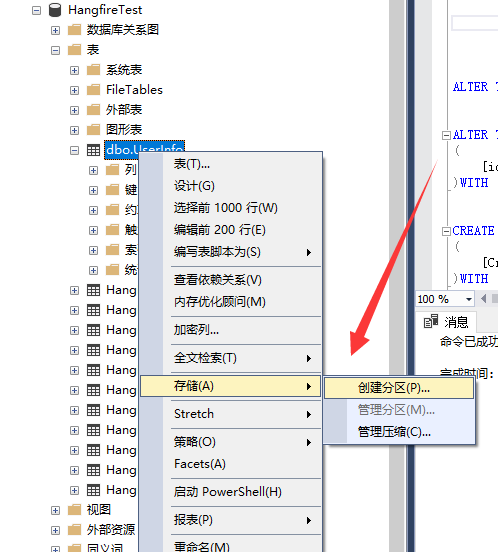
选择分区的列,我这里用的时间,也可以根据其他列作为分区的算法
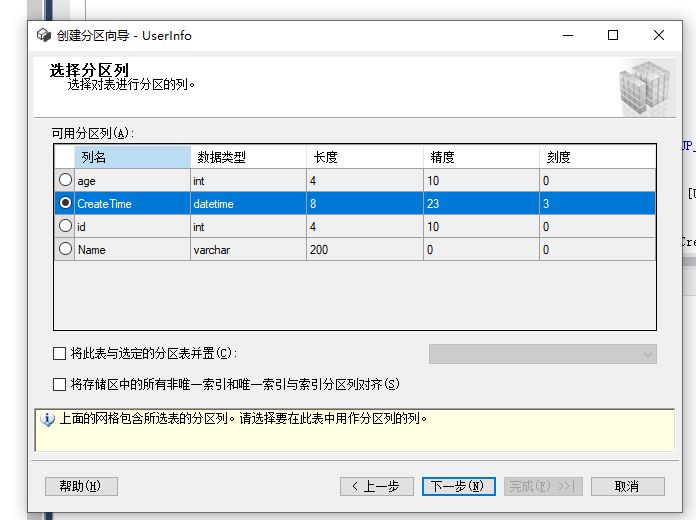
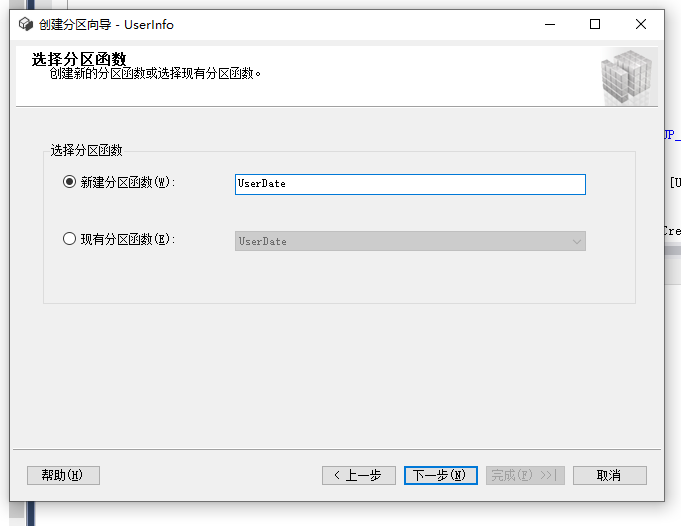
随便填写一个函数和方案
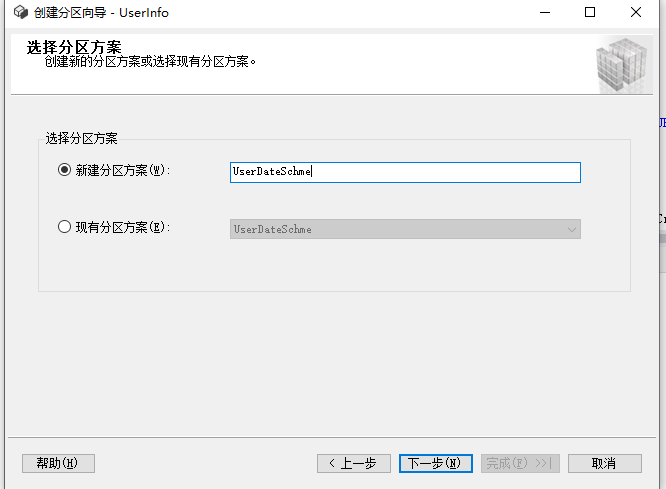
这里边界就是设置刚才那列的值,根据自己使用情况设置,文件组用的同一个,官网说不会影响分区的优势
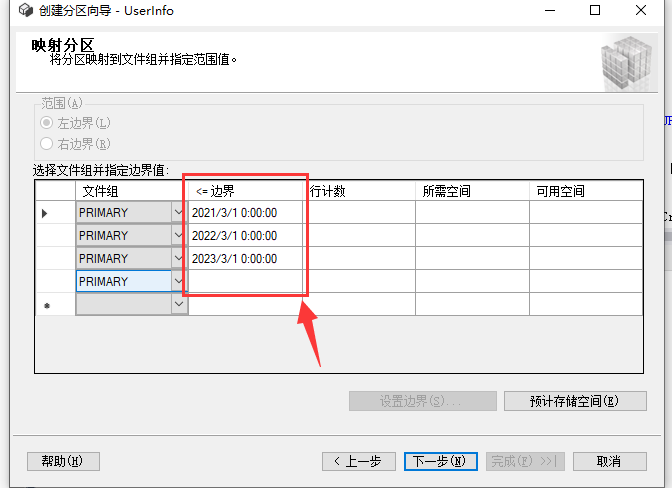
分配好后点击预计存储空间可以看到分区后的数据信息预计值
点击下一步生成脚本,然后执行就行了
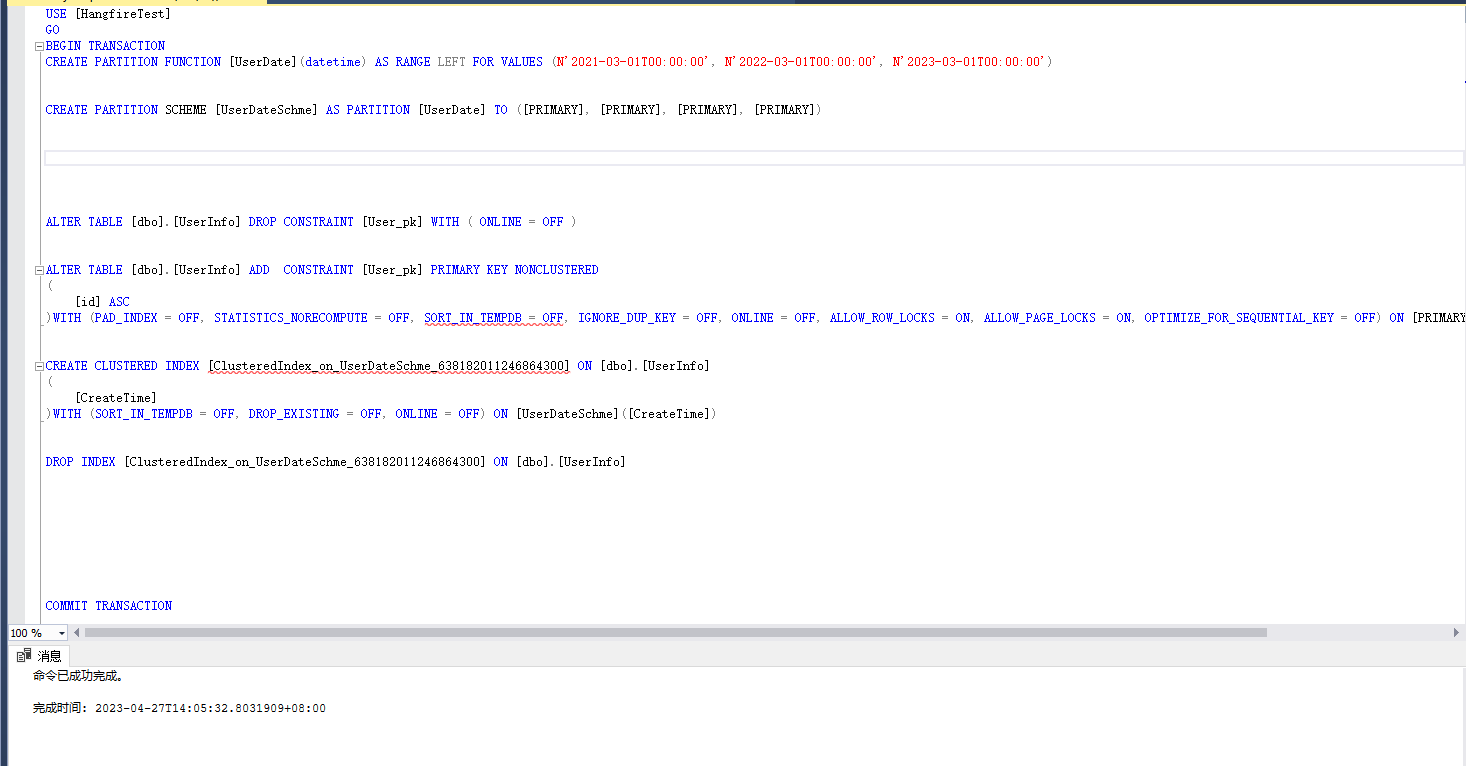
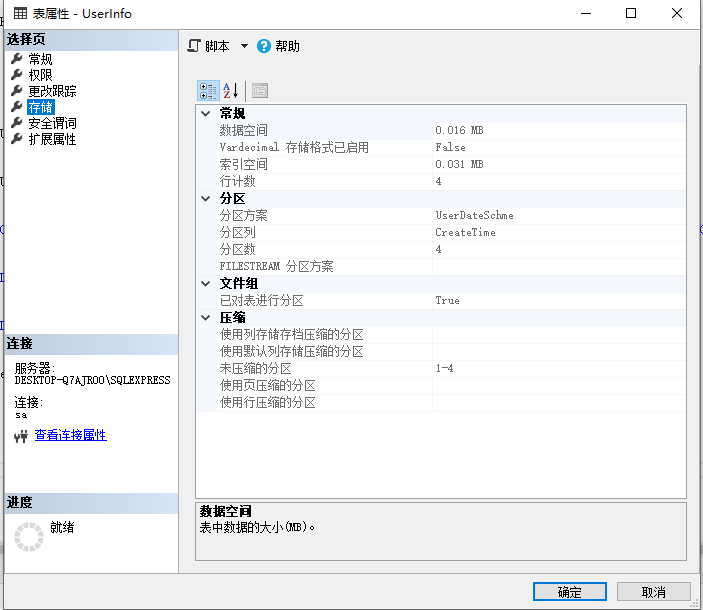
最后我们右键这张表的属性页,在存储里面就可以看到分区信息
读写分离配置主从库
这里就不演示代码了,只演示主从库配置和数据同步,
就相当于主库主要负责写(增删改),从库负责读(查),一般业务需要读:写=8 : 2 ,并且数据一致性要求不高的场景,因为主从数据同步有延迟,正因为有延迟,所以主库除了负责写,特定情况比如对数据要求一致性比较高的情景就也可以用于读
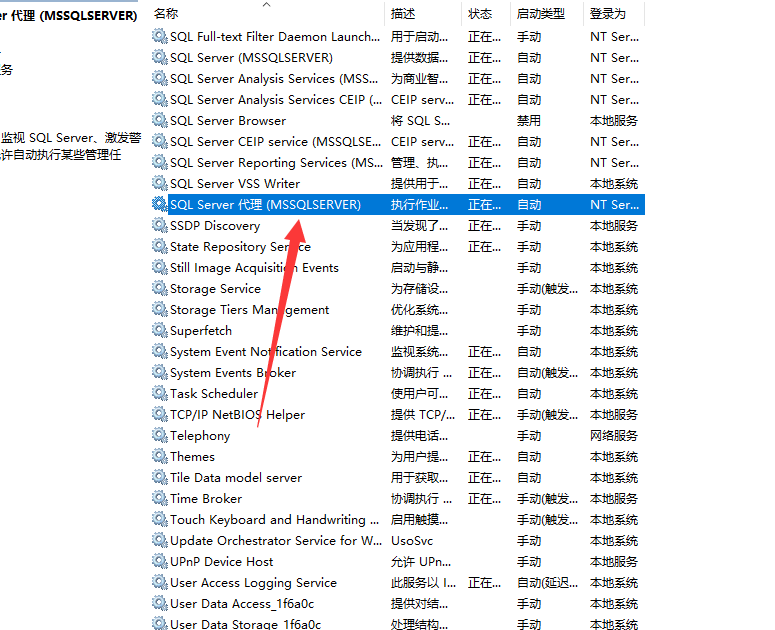
先打开sql server服务代理
配置分发服务器
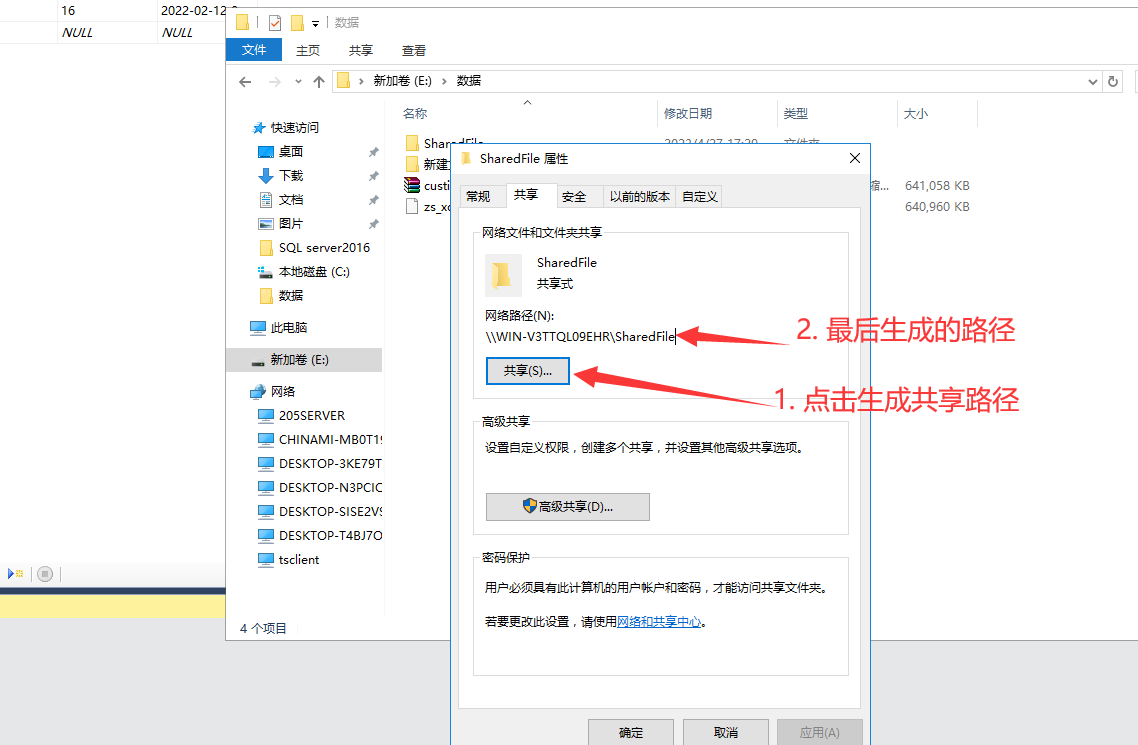
先创建共享文件夹并设置访问权限,不然后期会提示没有权限导致失败
随便新建一个文件夹,点击属性-》共享就可以生成一个路径,复制这个路径待会儿会用。
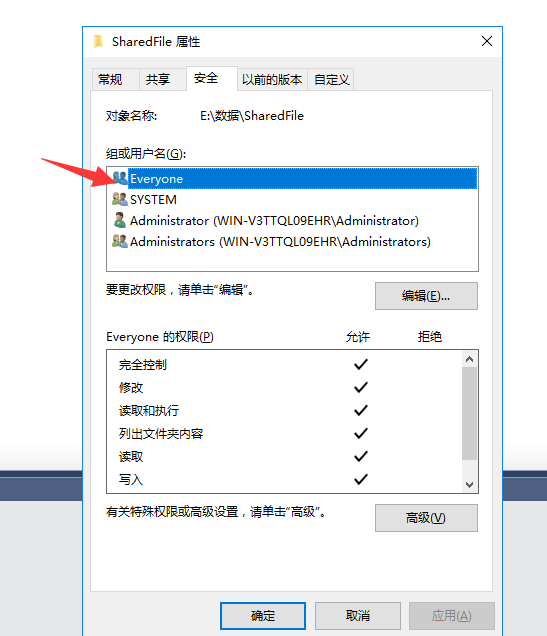
再设置这个文件访问权限,我这里加了个Everyone都可以访问读写
现在就可以配置分发了,如果没有这个配置分发的选项,要么是版本不对,我本地是express版本就没有这个选项和本地发布文件夹。下载企业版就有了
如果版本对了就是没有这个选项就是之前用过,直接选择禁用配置和分发,删除之前的记录就可以了
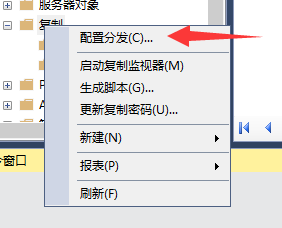
一直点击下一步,到这里配置快照文件夹路径就选择刚才共享的路径就行了
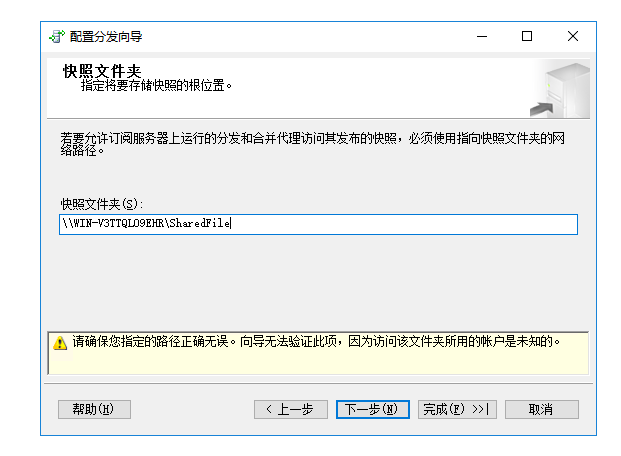
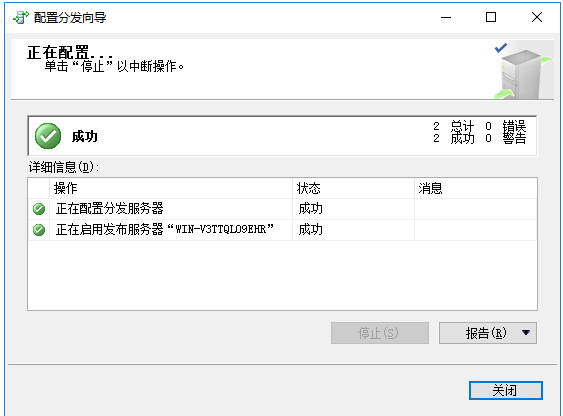
一直点下一步,最后点完成就可以出现这个界面了
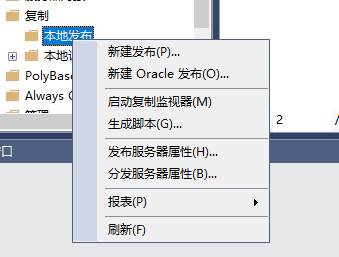
添加发布
选择需要发布的数据库
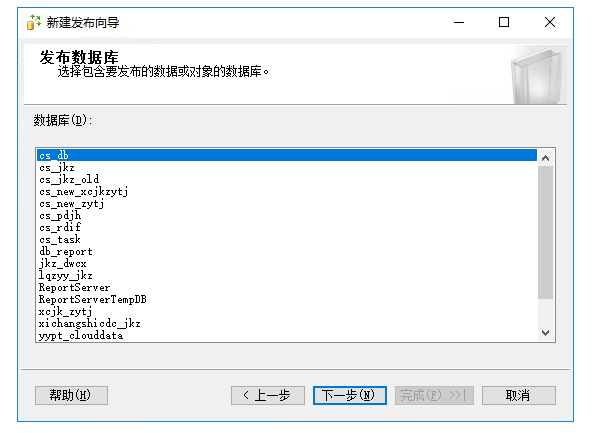
选择发布类型,这里一般选择事务发布,主从同步比较快,具体看业务
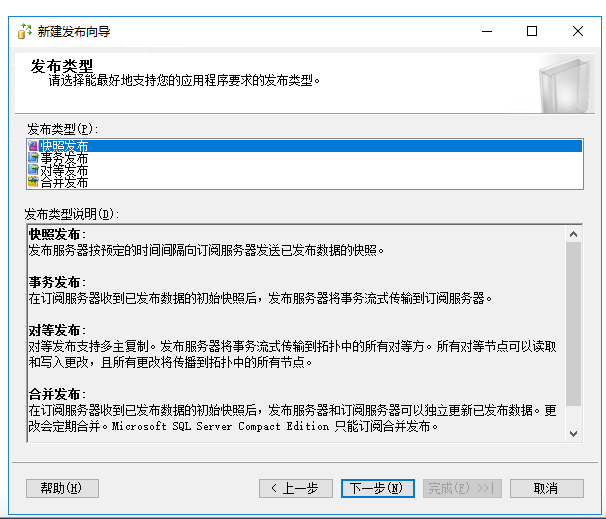
选择需要发布的表字段和存储过程(我这里没有)
点击下一步这里要配置账户
点击安全设置
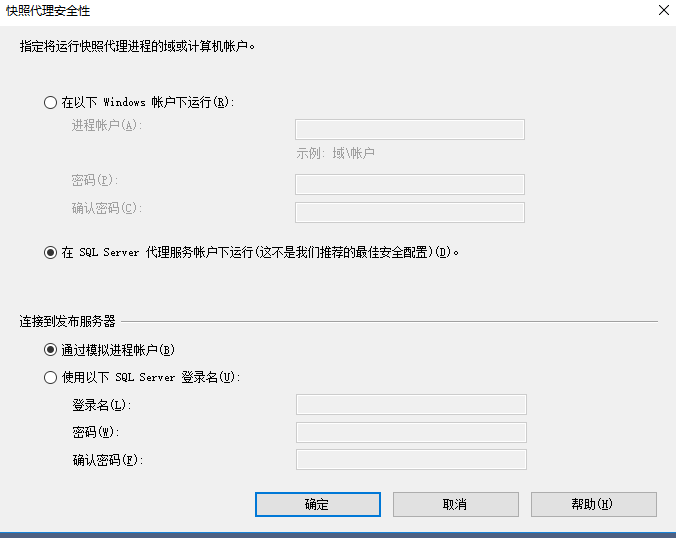
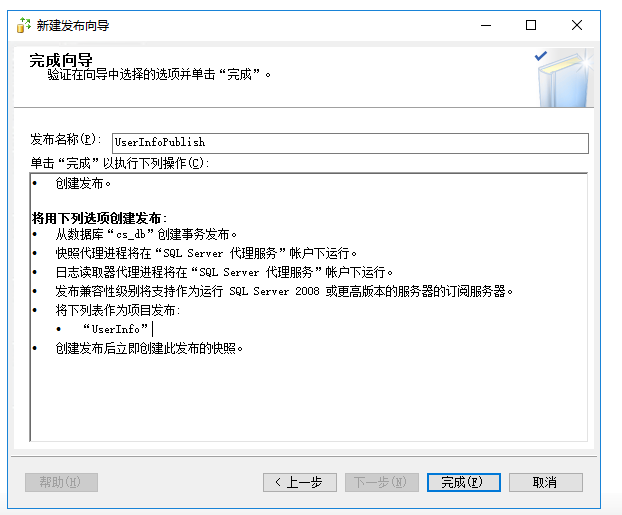
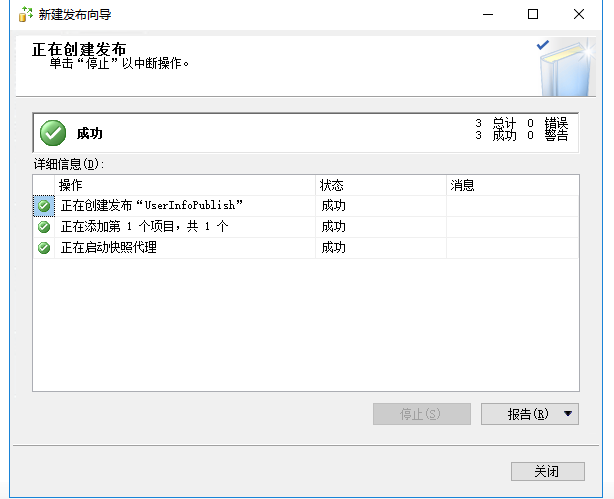
确定之后,点击下一步,填写发布名称,点击完成等待就可以了
添加订阅
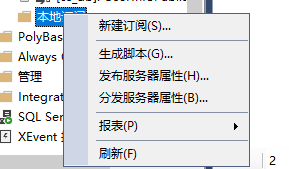
这里新建一个数据库,新建了一个cs_db_s1的库

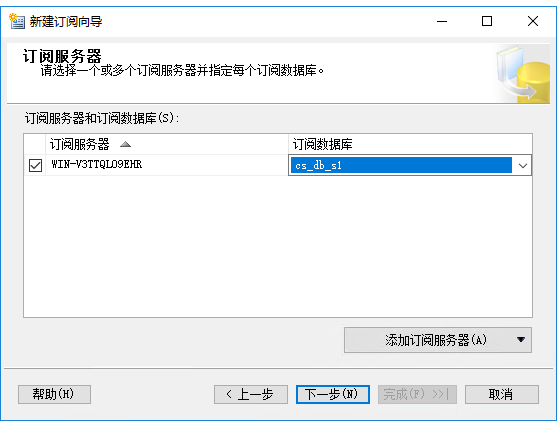
下一步,点击这个按钮配置服务连接
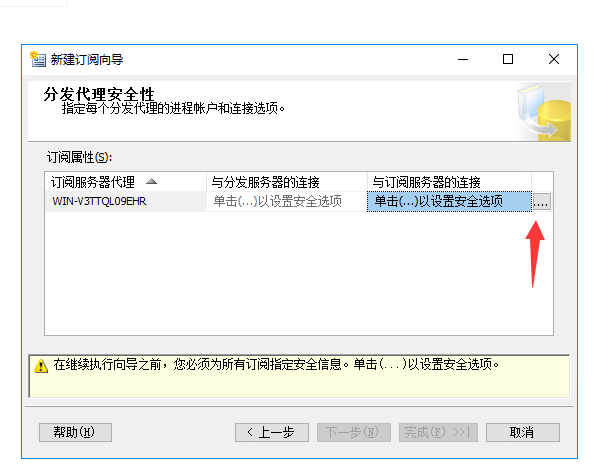
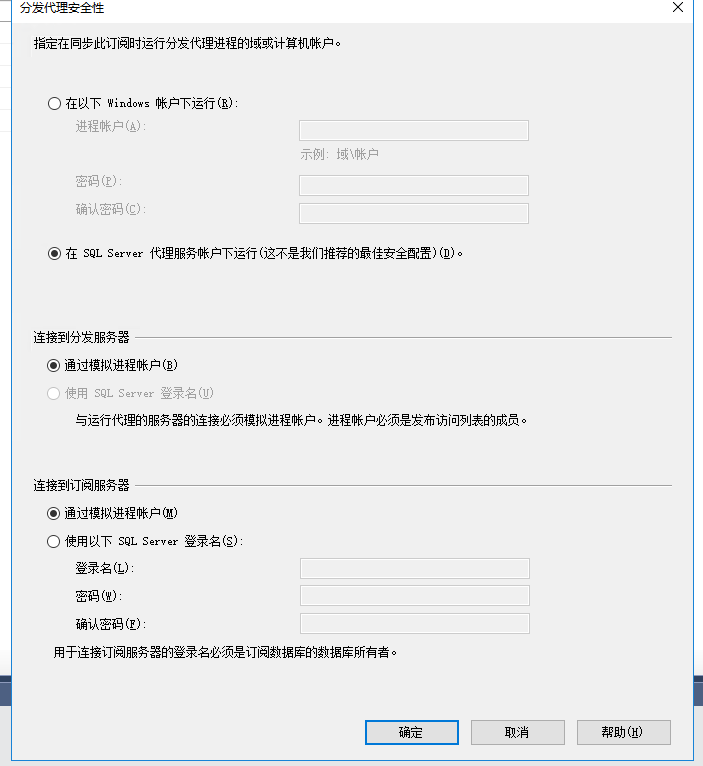
确定之后下一步,最后点击完成就可以了
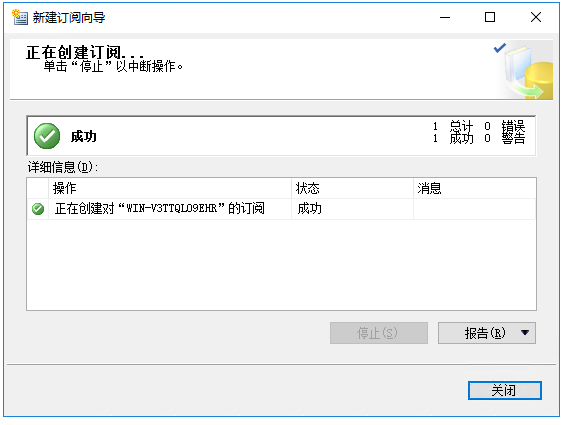
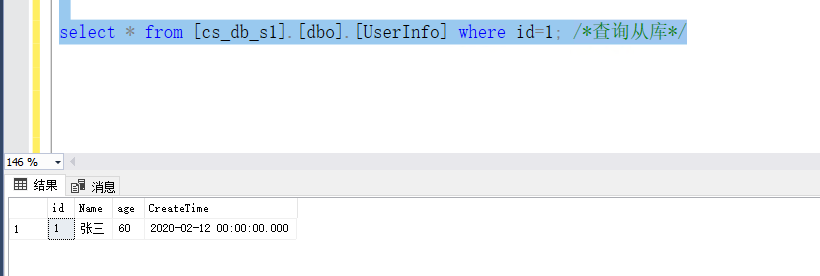
这里校验一下,可以看到刚刚新建的数据库,已经把数据表同步过去了
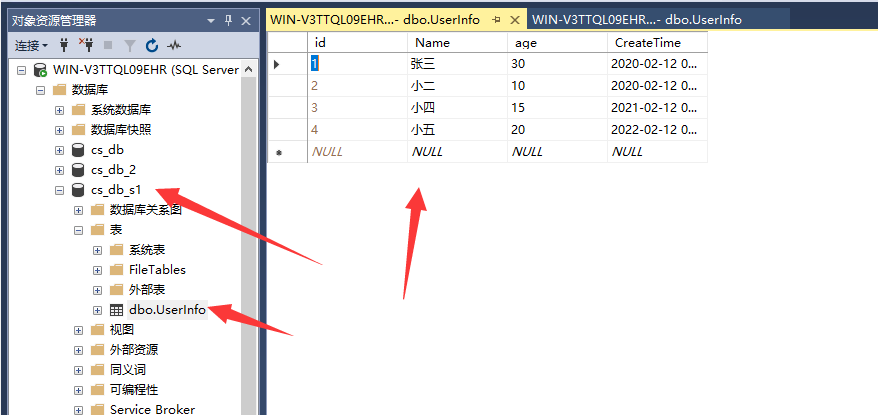
测试一下
这里修改主库后马上查询主库和从库,发现数据对不上,这里就可以看出问题,主从同步需要时间,所以读写分离主从库这种模式适用对数据一致性要求不高的场景
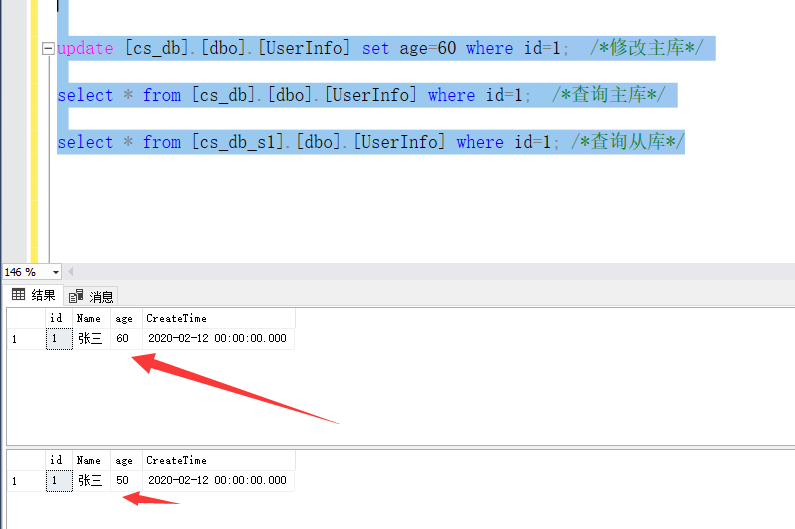
等过几秒再查询从库,这个时候就可以看出数据已经同步了