
key1
import os
g = os.walk(r'D:\Users\Quincy_C\PycharmProjects\S6')
print(next(g))
print(next(g))
第一次next结果:
得到的结果是是一个元组,元组的第一个元素是输入的文件路径,第二个元素是当前路径下所有的文件夹组成的列表,第三个元素是当前路径下所有文件组成的列表:
(‘D:\Users\Quincy_C\PycharmProjects\S6’, [‘.idea’, ‘socket并发’, ‘socket编程’, ‘pycache‘, ‘互斥锁’, ‘并发’, ‘序列化与反序列化’], [‘logging模块.py’, ‘os.walk()用法.py’])
第二次next结果
(‘D:\Users\Quincy_C\PycharmProjects\S6\.idea’, [‘inspectionProfiles’, ‘scopes’], [‘.name’, ‘encodings.xml’, ‘misc.xml’, ‘modules.xml’, ‘S6.iml’, ‘vcs.xml’, ‘workspace.xml’])
这次会进到当前文件夹下的第一个子文件夹进行遍历,得到第一个子文件夹路径以及该子文件夹下的文件夹和文件
依次类推=—>
--------------------------------------------------------------------------------------------------------------------------------------
http://www.sohu.com/a/198572539_697750
图片数据的扩增
datagen = image.ImageDataGenerator(rescale= 1/255, width_shift_range=0.1)
rescale的作用是对图片的每个像素值均乘上这个放缩因子,这个操作在所有其它变换操作之前执行,在一些模型当中,直接输入原图的像素值可能会落入激活函数的“死亡区”,因此设置放缩因子为1/255,把像素值放缩到0和1之间有利于模型的收敛,避免神经元“死亡”。
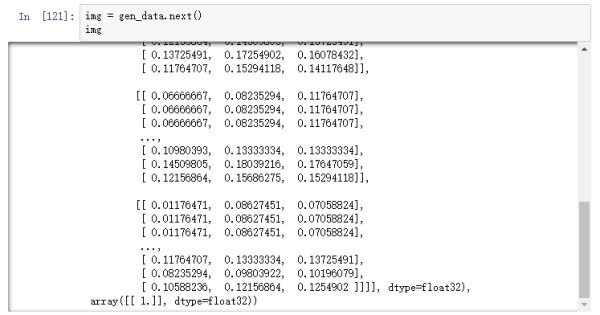
图片经过rescale之后,保存到本地的图片用肉眼看是没有任何区别的,如果我们在内存中直接打印图片的数值,可以看到以下结果:
datagen = image.ImageDataGenerator(fill_mode='wrap', zoom_range=[4, 4])
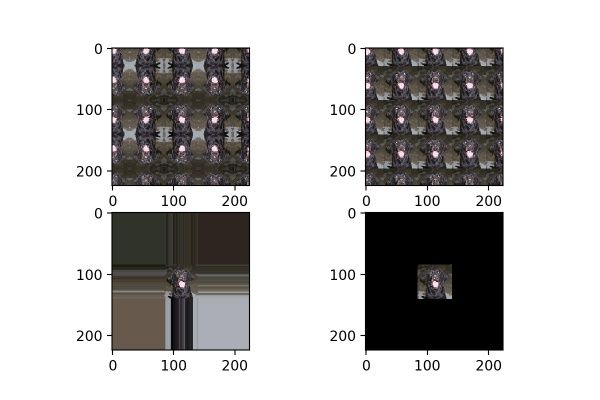
fill_mode为填充模式,如前面提到,当对图片进行平移、放缩、错切等操作时,图片中会出现一些缺失的地方,那这些缺失的地方该用什么方式补全呢?就由fill_mode中的参数确定,包括:“constant”、“nearest”(默认)、“reflect”和“wrap”。这四种填充方式的效果对比如图18所示,从左到右,从上到下分别为:“reflect”、“wrap”、“nearest”、“constant”。
----------------------------------------------------------------------------------------------------------------------------------------
rle_encoding(x):
- In order to reduce the submission file sizes, this competition uses run-length encoding (RLE) on the pixel values.
http://blog.csdn.net/hewb14/article/details/53414068
如果想在Keras中自定义各种层和函数,一定会用到的就是backend。一般导入的方法是
from keras import backend as K
这是因为Keras可以有两种后台,即theano和tensorflow,所以一些操作张量的函数可能是随后台的不同而不同的,通过引入这个backend,就可以让Keras来处理兼容性。比如求x的平均,就是K.mean(x)。backend文件本身在keras/backend文件夹下,可以通过阅读代码来了解backend都支持哪些操作。backend里面函数很多
-----------------------------------------------------------------------------------------------------------------------------------------
http://blog.csdn.net/star_bob/article/details/48598417
optimizer: str (优化函数的名称) 或者优化对象
verbose: 0 表示不更新日志, 1 更新日志, 2 每个epoch一个进度行.
-----------------------------------------------------------------------------------------------------------------------------------
x = np.array([[[0], [1], [2]]]) print(x) """
x=
[[[0] [1] [2]]] """ print(x.shape) # (1, 3, 1) x1 = np.squeeze(x) # 从数组的形状中删除单维条目,即把shape中为1的维度去掉
print(x1) # [0 1 2] print(x1.shape) # (3,)
------------------------------------------------------------------------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号