1,文本预处理
在nlp工程中,文本预处理的流程通常包含以下步骤:获取原始文本、分词、文本清洗、标准化、特征提取、建模等。
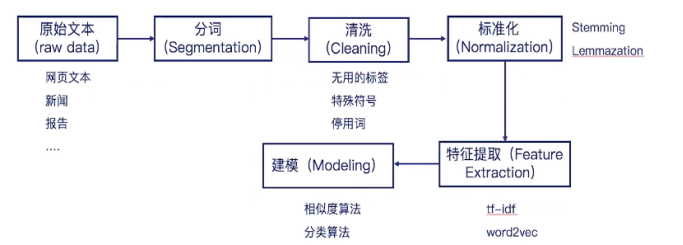
!文本获取
获取语料库,一个方法就是去网络上寻找一些第三方提供的语料库,出名的开放语料库比如wiki。但事实上,很多情况中所研究或开发的系统往往是应用于某种特定的领域,这些开放语料库经常无法满足我们的需求。这种时候就需要使用另一种方法,使用爬虫去主动的获取想要的信息。可以使用如pyspider、scrapy等python框架非常轻松地编写出自己需要的爬虫,从而让机器自动地去获取大量数据,从而继续我们的研究。
!分词
中英文在分词上,由于语言的特殊性导致分词的思路也会不一样。大多数情况下,英文直接使用空格就可以进行分词。但是在中文上,由于语法更为复杂,我们通常会使用jieba等第三方库进行分词的操作。

!清洗
由于大多数情况下,我们准备好的文本里都有很多无用的部分,例如爬取来的一些html代码,css标签等。或者我们去除不需要用的标点符号、停用词等,我们需要分步骤去清洗。
!标准化
通常我们需要用到词形还原(Lemmatization)和词干提取(Stemming)。
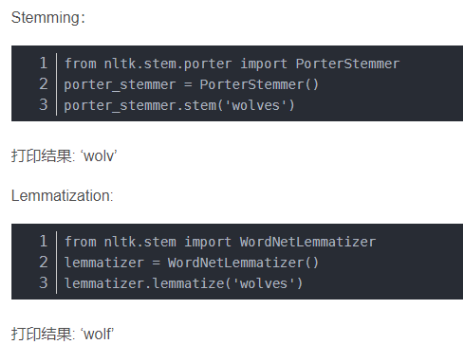
在原理上,词干提取主要是采用“缩减”的方法,将词转换为词干,如将“cats”处理为“cat”,将“effective”处理为“effect”。而词形还原主要采用“转变”的方法,将词转变为其原形,如将“drove”处理为“drive”,将“driving”处理为“drive”。
在复杂性上,词干提取方法相对简单,词形还原则需要返回词的原形,需要对词形进行分析,不仅要进行词缀的转化,还要进行词性识别,区分相同词形但原形不同的词的差别。词性标注的准确率也直接影响词形还原的准确率,因此,词形还原更为复杂。
在结果上,词干提取和词形还原也有部分区别。词干提取的结果可能并不是完整的、具有意义的词,而只是词的一部分,如“revival”词干提取的结果为“reviv”,“ailiner”词干提取的结果为“airlin”。而经词形还原处理后获得的结果是具有一定意义的、完整的词,一般为词典中的有效词。
在应用领域上,同样各有侧重。虽然二者均被应用于信息检索和文本处理中,但侧重不同。词干提取更多被应用于信息检索领域,如Solr、Lucene等,用于扩展检索,粒度较粗。词形还原更主要被应用于文本挖掘、自然语言处理,用于更细粒度、更为准确的文本分析和表达,所以我们要根据实际使用场景去选择我们的标准化方法。
!特征提取
通常会采用TF-IDF、Word2Vec、CountVectorizer等方式实现对文本特征的提取。
2,语言模型

3,RNN循环神经网络
循环神经网络(recurrent neural networks,RNNs) 是具有隐状态的神经网络。隐藏层和隐状态指的是两个截然不同的概念。如上所述,隐藏层是在从输入到输出的路径上(以观测角度来理解)的隐藏的层,而隐状态则是在给定步骤所做的任何事情(以技术角度来定义)的输入,并且这些状态只能通过先前时间步的数据来计算。
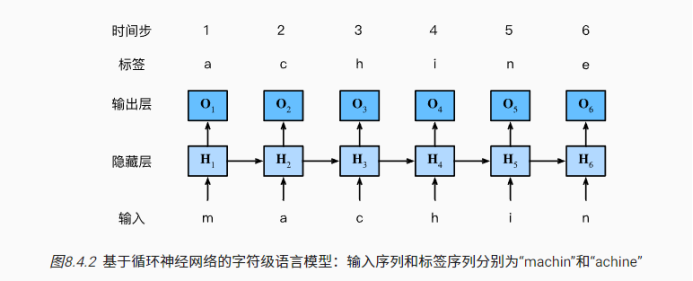
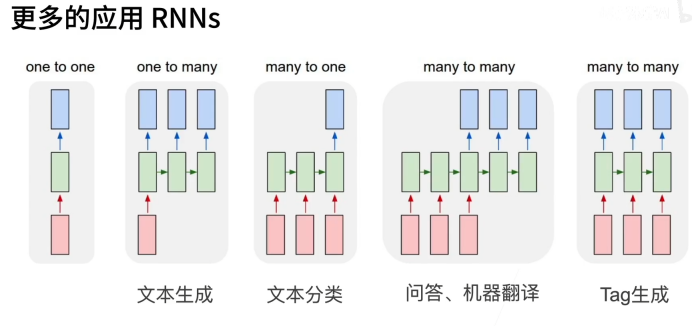
为什么需要RNN?(循环神经网络)
传统的神经网络只能单独的取处理一个个的输入,前一个输入和后一个输入是完全没有关系的。但是,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。
比如,当我们在理解一句话意思时,孤立的理解这句话的每个词是不够的,我们需要处理这些词连接起来的整个序列;当我们处理视频的时候,我们也不能只单独的去分析每一帧,而要分析这些帧连接起来的整个序列。
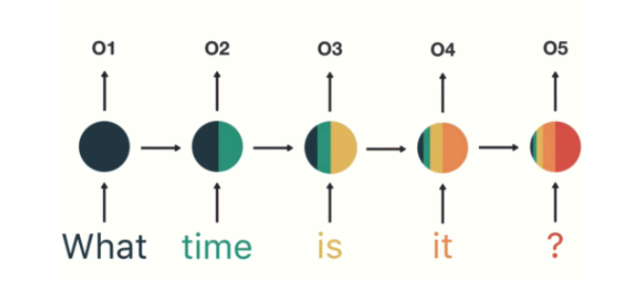
以nlp的一个最简单词性标注任务来说,将“我”“吃”“苹果”三个单词标注词性为“我/nn”“吃/v”“苹果/nn”。
那么这个任务的输入就是:
我 吃 苹果 (已经分词好的句子)
这个任务的输出是:
我/nn 吃/v 苹果/nn(词性标注好的句子)
对于这个任务来说,我们当然可以直接用普通的神经网络来做,给网络的训练数据格式了就是我-> 我/nn 这样的多个单独的单词->词性标注好的单词。
但是很明显,一个句子中,前一个单词其实对于当前单词的词性预测是有很大影响的,比如预测苹果的时候,由于前面的吃是一个动词,那么很显然苹果作为名词的概率就会远大于动词的概率,因为动词后面接名词很常见,而动词后面接动词很少见。
所以为了解决一些这样类似的问题,能够更好的处理序列的信息,RNN就诞生了。
梯度消失
注意隐藏状态中奇怪的颜色分布。这是RNN被称为短期记忆的原因。
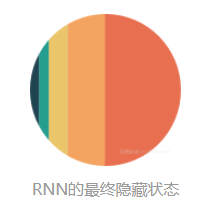
短期记忆问题是由臭名昭着的梯度消失问题引起的,这在其他神经网络架构中也很普遍。由于RNN处理很多步骤,因此难以保留先前步骤中的信息。在最后的时间步骤中,“what”和“time”这两个词的信息几乎不存在。短期记忆和梯度消失是由于反向传播的性质引起的,反向传播是用于训练和优化神经网络的算法。
由于梯度消失,RNN不会跨时间步骤学习远程依赖性。这意味着在尝试预测用户的意图时,有可能不考虑“what”和“time”这两个词。然后网络就可能作出的猜测是“is it?”。这很模糊,即使是人类也很难辨认这到底是什么意思。因此,无法在较早的时间步骤上学习会导致网络具有短期记忆。
RNN会受到短期记忆的影响,那么我们如何应对呢?为了减轻短期记忆的影响,研究者们创建了两个专门的递归神经网络,一种叫做长短期记忆或简称LSTM。另一个是门控循环单位或简称GRU。LSTM和GRU本质上就像RNN一样,但它们能够使用称为“门”的机制来学习长期依赖。这些门是不同的张量操作,可以学习添加或删除隐藏状态的信息。由于这种能力,短期记忆对他们来说不是一个问题。
4,门控循环单位GRU
LSTM和GRU通过门控机制使循环神经网络不仅能记忆过去的信息,同时还能选择性地忘记一些不重要的信息而对长期语境等关系进行建模。
GRU(Gate Recurrent Unit)是循环神经网络(Recurrent Neural Network, RNN)的一种。和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。
GRU和LSTM在很多情况下实际表现上相差无几,但是相比LSTM,使用GRU能够达到相当的效果,并且相比之下更容易进行训练,能够很大程度上提高训练效率,因此很多时候会更倾向于使用GRU。
怎么理解GRU是如何解决长期记忆丢失问题的呢?
!首先介绍重置门(reset gate)和更新门(update gate)。我们把它们设计成(0,1)区间中的向量,这样我们就可以进行凸组合。重置门允许我们控制“可能还想记住”的过去状态的数量;更新门将允许我们控制新状态中有多少个是旧状态的副本。
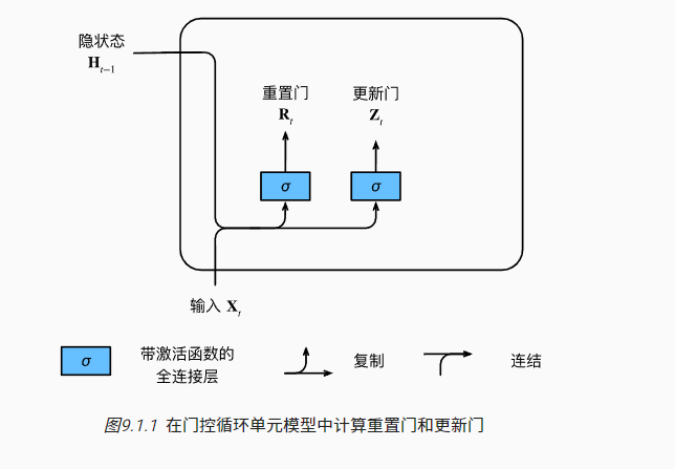
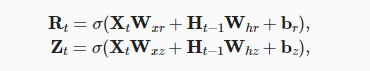
!接下来,将重置门应用,得到在时间步Ht的候选隐状态。
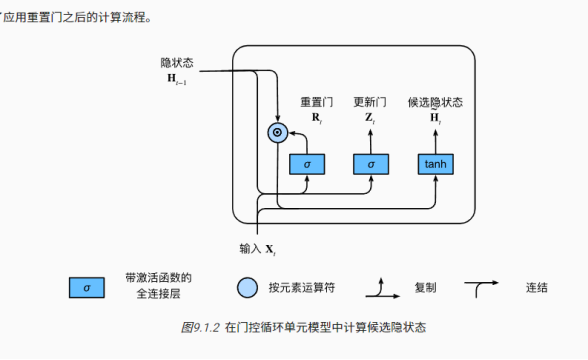
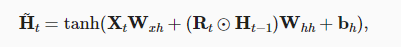
!上述的计算结果只是候选隐状态,我们仍然需要结合更新门Zt的效果。这一步确定新的隐状态Ht在多大程度上来自旧的状态Ht−1和新的候选状态H~t。
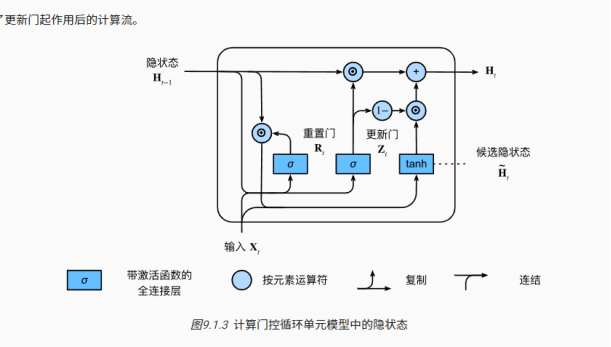
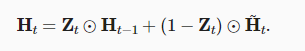
每当更新门Zt接近1时,模型就倾向只保留旧状态。此时,来自Xt的信息基本上被忽略,从而有效地跳过了依赖链条中的时间步t。相反,当Zt接近0时,新的隐状态Ht就会接近候选隐状态H~t。(如果我们将重置门设置为 1,更新门设置为 0,那么我们将再次获得标准RNN模型。)
小结:
重置门有助于捕获序列中的短期依赖关系。
更新门有助于捕获序列中的长期依赖关系。
5,长短期记忆网络LSTM
就如在门控循环单元中一样,当前时间步的输入和前一个时间步的隐状态 作为数据送入长短期记忆网络的门中。
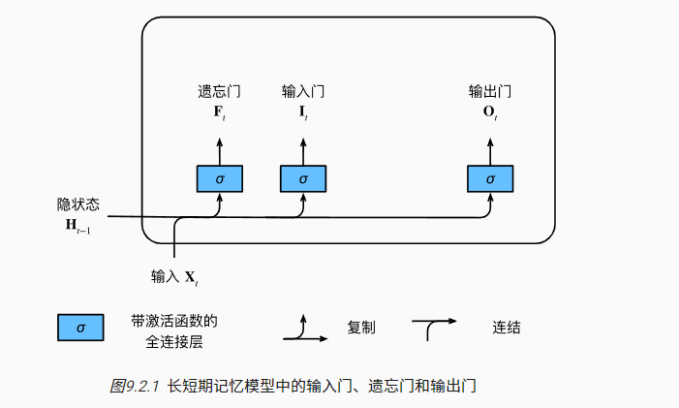
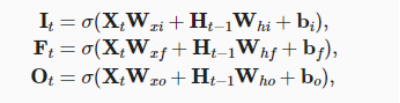
LSTM比GRU复杂,参数更多,有三个门:遗忘门,输入门和输出门。
那么LSTM是如何解决长期记忆丢失问题的呢?
!首先介绍候选记忆元(candidate memory cell),它的计算与上面描述的三个门的计算类似。但是,使用tanh函数作为激活函数而不是三个门都使用的sigmoid函数,函数的值范围为(-1,1)。
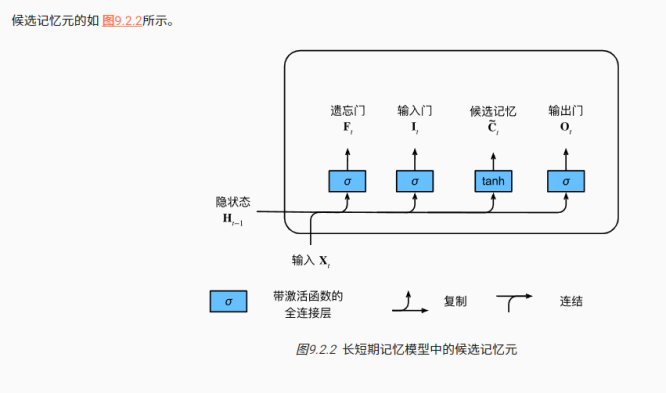
!接下来是计算记忆元C,在门控循环单元中,有一种机制来控制输入和遗忘(或跳过)。类似地,在长短期记忆网络中,也有两个门用于这样的目的:输入门It控制采用多少来自C~的新数据,而遗忘门Ft控制保留多少过去的记忆元Ct-1的内容。
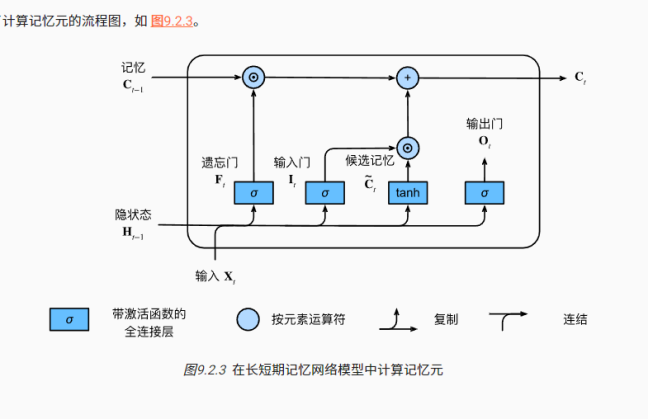
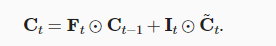
!最后,我们需要定义如何计算隐状态Ht,这就是输出门发挥作用的地方。在长短期记忆网络中,它仅仅是记忆元的tanh的门控版本。这就确保了Ht的值始终在区间(-1,1)。
只要输出门接近1,我们就能够有效地将所有记忆信息传递给预测部分,对于输出门接近0,我们只保留记忆元的所有信息,而不需要更新隐状态Ht。
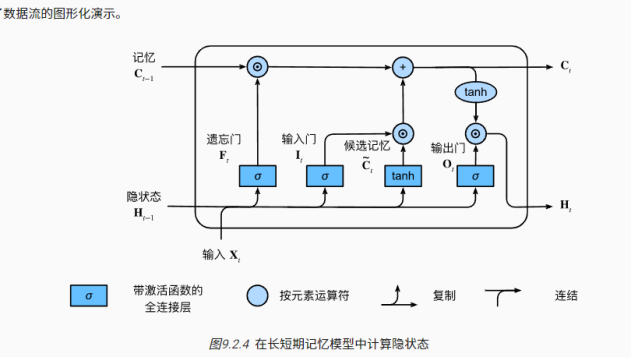

6,编码器-解码器架构
机器翻译是序列转换模型的一个核心问题,其输入和输出都是长度可变的序列。为了处理这种类型的输入和输出,我们可以设计一个包含两个主要组件的架构:第一个组件是编码器(encoder):它接受一个长度可变的序列作为输入,并将其转换为具有固定形状的编码状态第二个组件是解码器(decoder):它将固定形状的编码状态映射到长度可变的序列。这被称为编码器-解码器(encoder-decoder)架构。
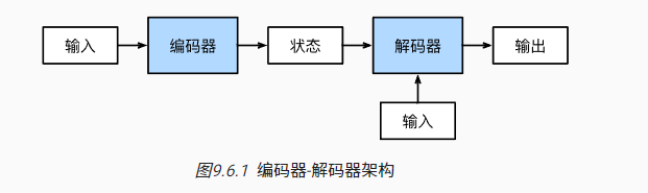
7,Seq2Seq


 浙公网安备 33010602011771号
浙公网安备 33010602011771号