

1,注意力机制
想象一下,假如你面前有五个物品:一份报纸、一篇研究论文、一杯咖啡、一本笔记本和一本书。所有纸制品都是黑白印刷的,但咖啡杯是红色的。换句话说,这个咖啡杯在这种视觉环境中是突出和显眼的,不由自主地引起人们的注意。所以人们会把视力最敏锐的地方放到咖啡上。
喝咖啡后,你会变得兴奋并想读书。所以你转过头,重新聚焦你的眼睛,然后看看书。与上面红色咖啡杯由于突出性导致的选择不同,此时选择书是受到了认知和意识的控制,因此注意力在基于自主性提示去辅助选择。
想将选择偏向于感官输入,例如咖啡杯引起的非自主性注意,我们可以简单地使用参数化的全连接层,甚至是非参数化的最大汇聚层或平均汇聚层。
“是否包含自主性提示”将注意力机制与全连接层或汇聚层区别开来。注意力机制通过注意力汇聚使选择偏向于值(感官输入),注意力汇聚其中包含查询(自主性提示)和键(非自主性提示)。键和值是成对的,一般是匹配查询和键,通过不同的方式计算他们的相关性,得到键对应值的权重。
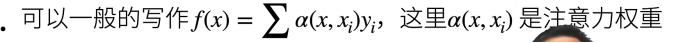
事实上a(x,xi)可以看作是经过人为设定的一种评分函数(scoring function)后把这个评分函数的输出结果输入到softmax函数中进行运算得到的结果。通过上述步骤,我们将得到与键对应的值的概率分布(即注意力权重)。最后,注意力汇聚的输出就是基于这些注意力权重的值的加权和。

2,注意力机制三个关键的组件query,key,value
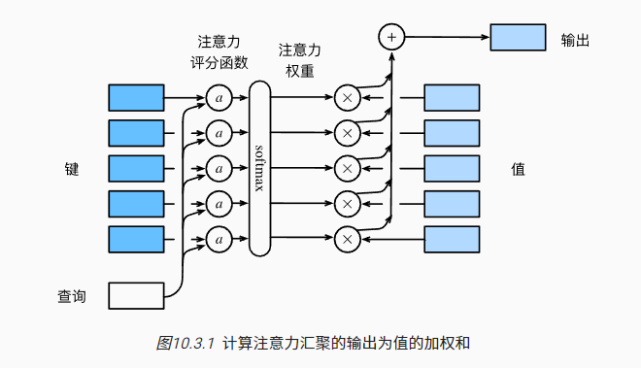
Attention机制的具体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为两个过程:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性即我们说的注意力分数;第二个阶段对第一阶段的原始分值进行归一化处理;这样,可以将Attention的计算过程抽象为三个阶段。
我们可以理解为query对应我们的输入。我们想要的输出就是value根据权重系数的加权和结果。
3,计算注意力分数的方法
当查询和键是不同长度的矢量时,可以使用可加性注意力评分函数。
当它们的长度相同时,使用缩放的“点积”注意力评分函数的计算效率更高。
4,Seq2Seq(sequence to sequence序列到序列)
Seq2Seq模型是RNN最重要的一个变种:N vs M(输入与输出序列长度不同)。这种结构又叫Encoder-Decoder模型。原始的N vs N RNN要求序列等长,然而我们遇到的大部分问题序列都是不等长的,如机器翻译中,源语言和目标语言的句子往往并没有相同的长度。
为此,Encoder-Decoder结构先将输入数据编码成一个上下文向量c:
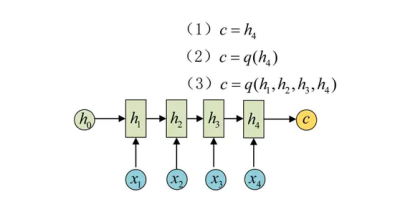
得到c有多种方式,最简单的方法就是把Encoder的最后一个隐状态赋值给c,还可以对最后的隐状态做一个变换得到c,也可以对所有的隐状态做变换。
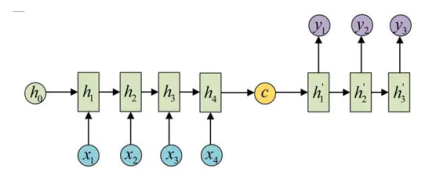
拿到c之后,就用另一个RNN网络对其进行解码,这部分RNN网络被称为Decoder。具体做法就是将c当做之前的初始状态h0输入到Decoder中(两种):
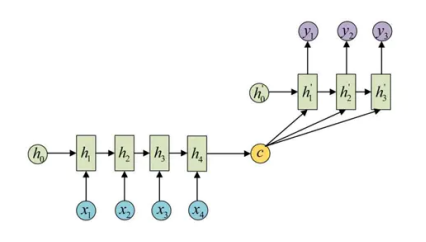
(在时间步t,循环神经网络将词元xt的输入特征向量xt和ht−1(即上一时间步的隐状态)转换为ht(即当前步的隐状态)。)
seq2seq存在着两个缺点:
<1>信息损失。因为encoder是对整个字符串进行学习,得到c,c的大小是固定的,如果遇见特别长的句子,那么c中所学习到信息会有损失,这样在decoder的过程中,就会出现误差。
<2>字符对齐。因为使用了一个固定大小的c来作为解码的输入,但是输入和输出其实不等长,c中并不包括字符位置的信息,所以在decode的过程中,如何能更加准确的将一次元素映射成对应应该的位置也是一个优化的方向。
加入attention机制可以缓解这两点问题:
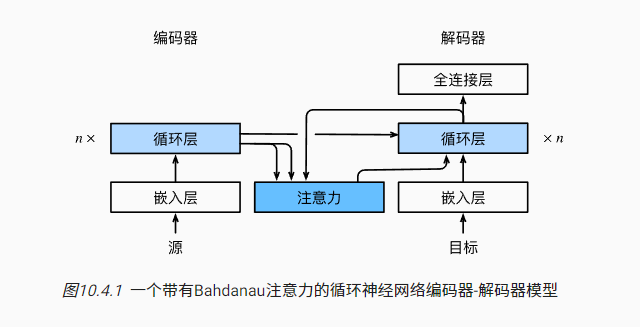
!编码器对每次词的输出作为key和value(他们是等价的)
!解码器RNN对上一个词的输出是query
!注意力的输出和下一个词的词嵌入合并进入Recurrent layer
5,自注意力
!在自注意力中,查询、键和值都来自同一组输入。
!卷积神经网络和自注意力都拥有并行计算的优势,而且自注意力的最大路径长度最短。但是因为其计算复杂度是关于序列长度的二次方,所以在很长的序列中计算会非常慢。
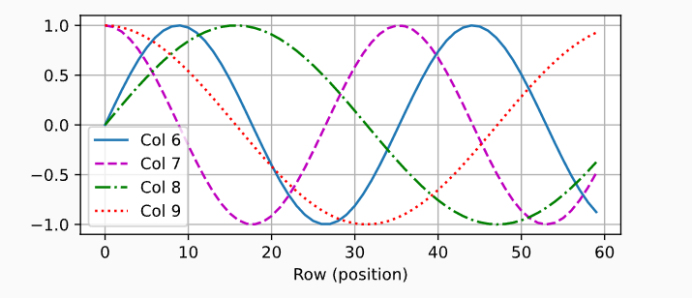
!为了使用序列的顺序信息,我们可以通过在输入表示中添加位置编码,来注入绝对的或相对的位置信息。
由于每个时间步的状态向量是不同的,所以即使在不同的时间步出现相同的词,RNN仍会区分开前后出现的词,从而产生不同的输出。我们可以认为,状态向量隐含了输入序列中的位置信息。其实它包含了过去时间步输入的词之间的语法和语义信息,这个信息对后续输入的词和输出产生的作用可以与位置信息的作用等同起来。
但是当一个序列输入进一个Self-Attention模块时,由于序列中所有的tokens是同时进入并被处理的,如果不提供位置信息,那么这个序列里的相同的token对Self-Attention模块来说就不会有语法和语义上的差别,它们会产生相同的输出。

在位置嵌入矩阵中,行代表词元在序列中的位置,列代表位置编码的不同维度。
这样不同列就带有了位置信息,也就是位置编码有了作用。
6,Transformers
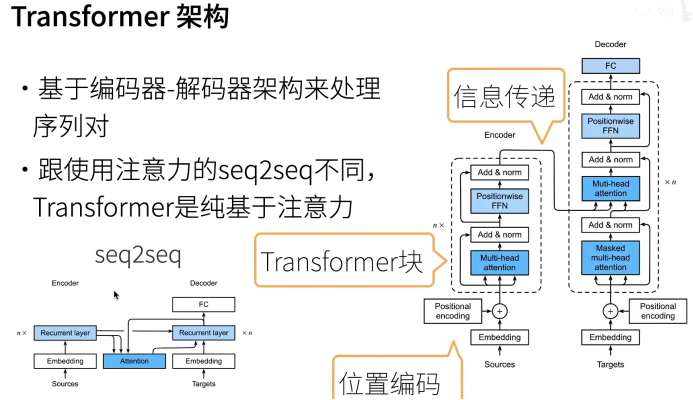
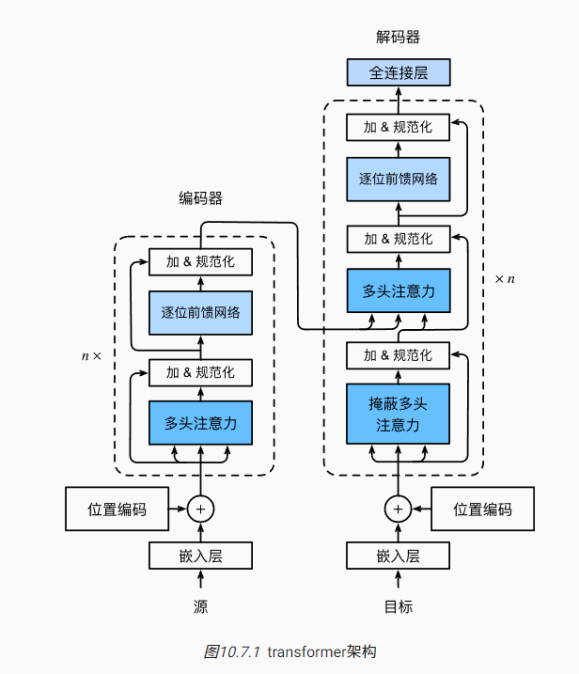
从宏观角度来看,transformer的编码器是由多个相同的层叠加而成的,每个层都有两个子层(子层表示为)。第一个子层是多头自注意力(multi-head self-attention)汇聚;第二个子层是基于位置的前馈网络(positionwise feed-forward network)。具体来说,在计算编码器的自注意力时,查询、键和值都来自前一个编码器层的输出。受残差网络的启发,每个子层都采用了残差连接(residual connection)。在transformer中,对于序列中任何位置的任何输入,都要求满足,以便残差连接满足。在残差连接的加法计算之后,紧接着应用层规范化(layer normalization)。因此,输入序列对应的每个位置,transformer编码器都将输出一个维表示向量。
Transformer解码器也是由多个相同的层叠加而成的,并且层中使用了残差连接和层规范化。除了编码器中描述的两个子层之外,解码器还在这两个子层之间插入了第三个子层,称为编码器-解码器注意力(encoder-decoder attention)层。在编码器-解码器注意力中,查询来自前一个解码器层的输出,而键和值来自整个编码器的输出。在解码器自注意力中,查询、键和值都来自上一个解码器层的输出。但是,解码器中的每个位置只能考虑该位置之前的所有位置。这种掩蔽(masked)注意力保留了自回归(auto-regressive)属性,确保预测仅依赖于已生成的输出词元。
多头注意力机制
在实践中,当给定相同的查询、键和值的集合时, 我们希望模型可以基于相同的注意力机制学习到不同的行为, 然后将不同的行为作为知识组合起来, 捕获序列内各种范围的依赖关系 (例如,短距离依赖和长距离依赖关系)。类似与CNN的多通道可以融合不同的特征信息。
为此,与其只使用单独一个注意力汇聚,我们可以用独立学习得到的组不同的 线性投影(linear projections)来变换查询、键和值。然后,这组变换后的查询、键和值将并行地送到注意力汇聚中。最后,将这个注意力汇聚的输出拼接在一起,并且通过另一个可以学习的线性投影进行变换,以产生最终输出。 这种设计被称为多头注意力(multihead attention)。对于个注意力汇聚输出,每一个注意力汇聚都被称作一个头(head)。图展示了使用全连接层来实现可学习的线性变换的多头注意力。
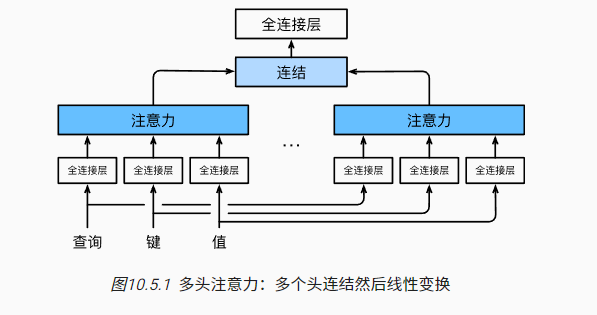
基于这种设计,每个头都可能会关注输入的不同部分。
7,Bert
微调

word2vec和GloVe等词嵌入模型与上下文无关。它们将相同的预训练向量赋给同一个词,而不考虑词的上下文(如果有的话)。它们很难处理好自然语言中的一词多义或复杂语义。对于上下文敏感的词表示,如ELMo和GPT,词的表示依赖于它们的上下文。
ELMo对上下文进行双向编码,但使用特定于任务的架构(然而,为每个自然语言处理任务设计一个特定的体系架构实际上并不容易);而GPT是任务无关的,但是从左到右编码上下文。
BERT结合了这两个方面的优点:它对上下文进行双向编码,并且需要对大量自然语言处理任务进行最小的架构更改。
8,优化算法
凸函数优化,能够保证局部最优就是全局最优。
但是,深度学习涉及到的基本上是非凸函数。

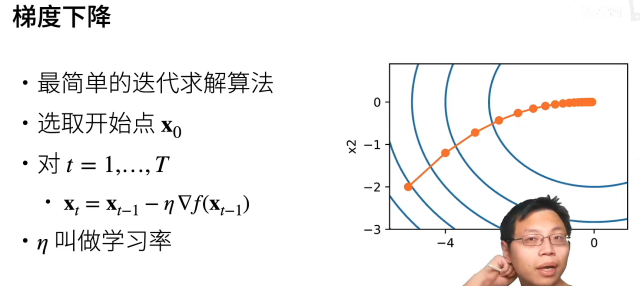
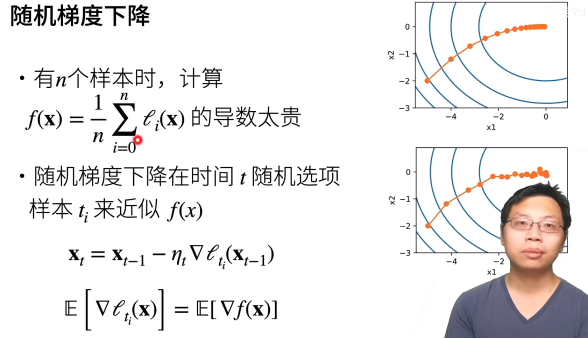

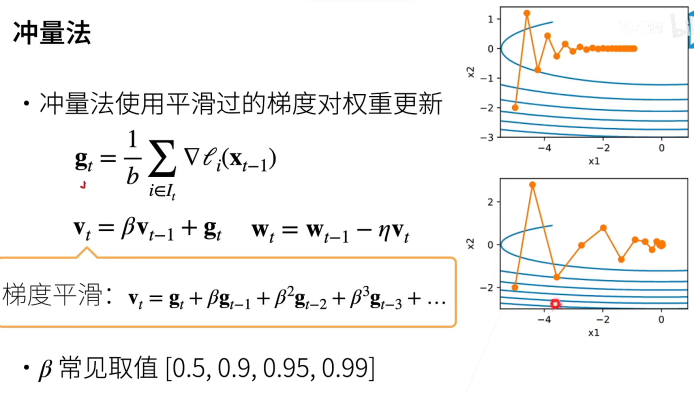


(对学习率不敏感,所以很常用,不用太调参)
9,大纲



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通