[源码分析] Facebook如何训练超大模型---(1)
[源码分析] Facebook如何训练超大模型---(1)
0x00 摘要
我们在前文介绍过,微软 ZeRO 可以对一个万亿参数模型可以使用 8 路模型并行、64 路管道并行和 8 路数据并行在 4,096 个 NVIDIA A100 GPU 上进行扩展。
而FSDP(Fully Sharded Data Parallel)是Facebook 深度借鉴微软ZeRO之后提出的PyTorch DDP升级版本,可以认为是对标微软 ZeRO,其本质是 parameter sharding。Parameter sharding 就是把模型参数等切分到各个GPU之上。我们会以 Google,微软和 Facebook 的论文,博客以及代码来进行学习分析。
本系列其他文章如下:
[源码解析] PyTorch 分布式之 ZeroRedundancyOptimizer
[论文翻译] 分布式训练 Parameter sharding 之 ZeRO
[论文翻译] 分布式训练 Parameter Sharding 之 Google Weight Sharding
0x01 简介
1.1 FAIR & FSDP
大规模训练人工智能模型并不容易。除了需要大量的计算能力和资源外,训练非常大的模型背后还有相当大的工程复杂性。Facebook人工智能研究(FAIR)工程部一直致力于构建工具和基础设施,以使大型人工智能模型的培训变得更容易。
Fully Sharded Data Parallel(FSDP)是FAIR引入的最新工具。它将AI模型的参数在数据并行worker之间进行切分,并且可以选择将部分训练计算卸载到CPU。顾名思义,FSDP是一种数据并行训练算法。尽管参数被分片到不同的GPU,但每个微批次数据的计算对于每个GPU worker来说仍然是本地的。这种概念上的简单性使FSDP更易于理解,并且更适用于各种使用场景(与层内并行和流水线并行相比)。与optimizer state+gradient sharding数据并行方法相比,FSDP在训练过程中通过通信和计算重叠对模型参数进行更均匀的切分,具有更好的性能。
FSDP可以使用更少的GPU更有效地训练数量级更大的模型。FSDP已在FairScale库中实现,允许工程师和开发人员使用简单的API扩展和优化其模型的培训。在Facebook,FSDP已经被整合并测试,用于训练一些NLP和Vision模型。
1.2 大规模训练计算能力需求
大规模模型训练需要大量的计算资源,比如OpenAI的GPT-3 拥有1750亿个参数。其训练估计需要355年的GPU时间,相当于1000个GPU连续工作4个月以上。
除了需要大量计算和工程资源外,大多数的训练扩展方法都会带来额外的通信成本,并且需要工程师仔细评估内存使用和计算效率之间的权衡。例如,典型的数据并行培训要求在每个GPU上维护模型的冗余副本,而模型并行培训为在worker(GPU)之间移动激活引入了额外的通信成本。
相比之下,FSDP相对而言没有做任何权衡。它通过在GPU上分割模型参数、梯度和优化器状态来提高内存效率,并通过分解通信并将其与前向和后向过程重叠来提高计算效率。FSDP产生与标准分布式数据并行(DDP)培训相同的结果,并提供易于使用的接口,该接口是PyTorch分布式数据并行模块的替代品。Facebook 的早期测试表明,FSDP可以扩展到数万亿个参数。
0x02 FSDP 如何工作
在标准DDP训练中,每个worker处理一个单独的批次,并使用all-reduce对worker之间的梯度进行汇总。虽然DDP已经变得非常流行,但它占用的GPU内存比它实际需要的要多,因为模型权重和优化器状态在所有DDP worker中都有一个副本。
2.1 全参数分片
减少副本的一种方法是应用全参数分片( full parameter sharding)的过程,其中仅提供局部计算所需的模型参数、梯度和优化器的子集。这种方法的一个实现 ZeRO-3 已经被微软所普及。
解锁全参数切分的关键是:我们可以把DDP之中的all reduce操作分解为独立的 reduce-scatter 和 all-gather 操作。

图来自 :https://engineering.fb.com/wp-content/uploads/2021/07/FSDP-graph-2a.png?w=1024
“All-reduce”是“reduce-scatter”和“all-gather”的组合。聚合梯度的标准 “All-reduce”操作可以分解为两个单独的阶段:“reduce-scatter”和“all-gather”。
- “reduce-scatter”阶段,在每个GPU上,会基于rank 索引对 rank 之间相等的块进行求和。
- “all-gather”阶段,每个GPU上的聚合梯度分片可供所有GPU使用。
通过重新安排reduce scatter和all gather,每个DDP worker只需要存储一个参数分片和优化器状态。
2.2 比对
下图显示了标准DDP训练(上半部分)和FSDP训练(下半部分):
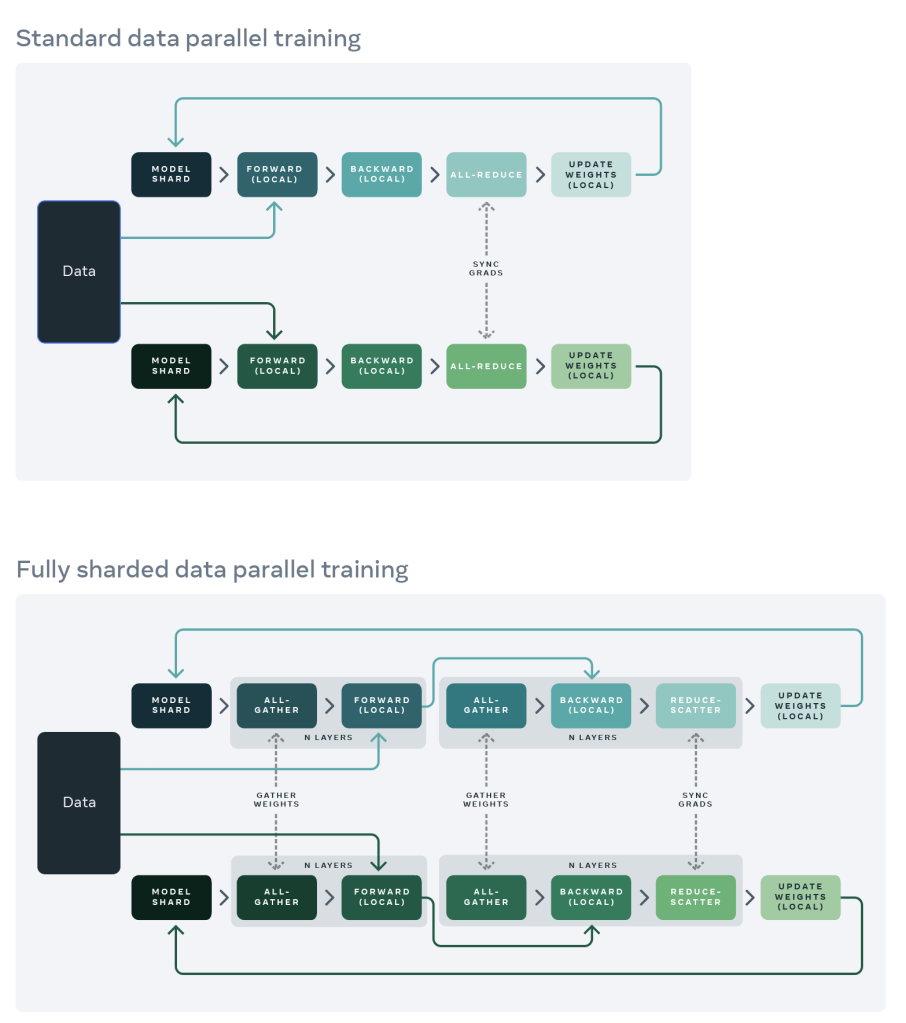
-
在标准的数据并行训练方法中,每个GPU上都有一个模型副本,向前和向后传递的序列只在自己的数据分片上进行运行。在这些局部计算之后,每个局部过程的参数和优化器与其他GPU共享,以便计算全局权重更新。
-
在FSDP中:
- Model shard :每个GPU上仅存在模型的分片。
- All-gather :每个GPU通过all-gather从其他GPU收集所有权重,以在本地计算前向传播。就是论文思路Pp下划线部分。
- Forward(local):在本地进行前向操作。前向计算和后向计算都是利用完整模型。
- All-gather :然后在后向传播之前再次执行此权重收集。就是论文思路Pp之中的下划线部分。
- Backward(local):本地进行后向操作。前向计算和后向计算都是利用完整模型,此时每个GPU上也都是全部梯度。
- Reduce-scatter :在向后传播之后,局部梯度被聚合并且通过 reduce-scatter 在各个GPU上分片,每个分片上的梯度是聚合之后本分区对应的那部分,就是论文思路Pg之中的下划线部分。
- Update Weight(local):每个GPU更新其局部权重分片。
为了最大限度地提高内存效率,我们可以在每层向前传播后丢弃全部权重,为后续层节省内存。这可以通过将FSDP包装应用于网络中的每一层来实现(通过设置reshard_after_forward=True)。
下面是伪代码实现:
FSDP forward pass:
for layer_i in layers:
all-gather full weights for layer_i # 权重
forward pass for layer_i
discard full weights for layer_i # 权重
FSDP backward pass:
for layer_i in layers:
all-gather full weights for layer_i # 权重
backward pass for layer_i
discard full weights for layer_i # 权重
reduce-scatter gradients for layer_i # 梯度
2.3 梳理
我们结合论文思路再来梳理一下 FSDP。
2.3.1 思路
论文思路如下:
- Pp: Parameter Partitioning,每个进程只存储与其分区对应的参数。当正向和反向传播需要其分区外的参数时,会通过broadcast操作从适当的数据并行进程接收这些参数。虽然乍一看,这可能会导致显著的通信开销,但我们发现,这种方法只会将基线DP系统的总通信量增加到1.5倍,同时实现与Nd成比例的内存减少。
- Pos : Optimizer State Partitioning,对于一个\(N_d\)并行度的DP来说,我们将优化器状态分组到\(N_d\)个相等的分区中,这样第i个数据并行进程只更新与第i个分区对应的优化器状态。因此,每个数据并行过程只需要存储和更新总优化器状态 的$ \frac{1}{N_d}\(,然后只更新\) \frac{1}{N_d}$个参数。在每个训练步骤结束时,我们会执行一个跨数据并行进程的all-gather操作,以获得跨所有数据并行进程的完全更新的参数。
- Pg: Gradient Partitioning,由于每个数据并行进程只负责更新其相应的参数分区,因此,每个节点仅仅对自己负责的那部分参数的梯度进行规约。在归并之后,每个节点只需要自己参数分区对应的梯度,对于其他的梯度不再需要,所以它们的内存可以被释放。这将梯度的内存占用从2ψ字节缩减到 \(\frac{2ψ}{N_d}\)。实际上,这是一种 Reduce-Scatter操作,不同参数的梯度被减少到不同的进程之中。
总结一下:因为模型参数被分区,所以参数梯度(在框架实现中,梯度往往是参数的成员变量)自然就被分区了。分区的参数被设置到优化器之中,所以优化器只会优化本分区的参数,所以优化器状态自然就是分区之后的。注意,在前向传播和后向传播时候,每个GPU都是用全部模型来计算,得到的梯度也是全部的梯度,只是存储时候只存储自己分区对应的部分。
2.3.2 流程步骤
我们再来展示一下具体流程。假设数据并行度为 n,则有 n 个GPU,那么每个GPU之上保存总模型参数的 1/n,同时梯度,优化器状态就自然被分区了,每个GPU之上还有数据并行。
- 起始状态:每个GPU之上是\(P_n, G_n, O_n\)。注意,因为本GPU上模型是\(P_n\),所以\(O_n\)自然就对应了\(P_n\),就自动分片了。
- 正向计算时候,每个 \(GPU_n\) 都把自己负责的参数 \(P_n\) 广播给其他所有的 GPU,前向计算之后,每个 \(GPU_n\) 都得到自己输入训练数据 \(data_n\) 的损失 \(loss_n\)。
- 反向计算时候,每个 \(GPU_n\) 也都把自己负责的参数 \(P_n\) 广播给其他所有的 GPU,最后计算得到对应于数据 \(data_n\)的梯度 \(G_n\)。
- 将梯度 \(G_n\)聚合到对应的\(GPU_n\)上,这时候\(GPU_n\) 上的梯度就是 \(reduce(G_0, ..., G_n)\) 之中自己rank对应的部分。注意,梯度聚合过程则使用了 reduce-scatter,因为每个gpu只需要更新自己负责的部分\(P_n,G_n,O_n\),所以不需要进行all-gather了。

0x03 How to use FSDP
目前,FAIR 提供四种解决方案来使用FSDP,以适应不同的需求。
3.1 在语言模型中使用FSDP
对于语言模型,可以在通过以下新参数,在 fairseq framework 之中支持 FSDP:
- –ddp-backend=fully_sharded: 通过FSDP启用完全切分。
- –cpu-offload: 将优化器状态和FP32模型副本卸载到cpu(与–optimizer=cpu_adam结合使用)。
- –no-reshard-after-forward: 提高大模型训练速度 (1B+ params) ,类似于 ZeRO stage 2。
- 其他常见选项 (–fp16, –update-freq, –checkpoint-activations, –offload-activations, etc.) 还是继续正常工作。
具体请参阅fairseq教程。
3.2 在计算机视觉模型之中使用FSDP
对于计算机视觉模型, VISSL 中可以支持FSDP,并在regnet架构上进行了测试。像BatchNorm和ReLU这样的层已经被无缝地处理并已经测试过其收敛性。可以使用下面选项来启用 FSDP。
- config.MODEL.FSDP_CONFIG.AUTO_SETUP_FSDP=True
- config.MODEL.SYNC_BN_CONFIG.SYNC_BN_TYPE=pytorch
- config.MODEL.AMP_PARAMS.AMP_TYPE=pytorch
在如下链接可以继续研究 this section 。
3.3 在PyTorch Lightning使用FSDP
为了更容易地与更通用的用例集成,PyTorch Lightning已经将FSDP作为beta功能。[此教程](https://pytorch-lightning.readthedocs.io/en/latest/advanced/advanced_gpu.html#fully-sharded training) 包含一个关于如何将FSDP插件与PyTorch Lightning一起使用的详细示例。如下所示,添加plugins='fsdp'可以激活它。
model = MyModel()
trainer = Trainer(gpus=4, plugins='fsdp', precision=16)
trainer.fit(model)
trainer.test()
trainer.predict()
3.4 直接从FairScale使用FSDP库
FSDP的主要开发库是FairScale.。您可以通过以下示例直接使用FairScale的FSDP,只需更换DDP。
from fairscale.nn.data_parallel import FullyShardedDataParallel as FSDP
...
# sharded_module = DDP(my_module)
sharded_module = FSDP(my_module)
optim = torch.optim.Adam(sharded_module.parameters(), lr=0.0001)
for sample, label in dataload.next_batch:
out = sharded_module(x=sample, y=3, z=torch.Tensor([1]))
loss = criterion(out, label)
loss.backward()
optim.step()
FairScale中的FSDP库为大规模训练的许多重要方面提供了选项。当你希望使用FSDP的全部功能,你可以自行研究如下方面。
- 模型封装:为了最大限度地减少短期内的GPU内存需求,用户需要以嵌套方式封装模型。这增加了复杂性,但是在移植现有PyTorch模型代码时非常有用。
- 模型初始化:与DDP不同,FSDP不会在GPU工作进程之间自动同步模型权重。这意味着必须小心地进行模型初始化,以便所有GPU worker具有相同的初始权重。
- 优化器设置:由于分片和包装,FSDP只支持某些类型的优化器和优化器设置。特别是,如果模块被FSDP包装,并且其参数被展平为单个张量,则用户不能对此类模块中的不同参数组使用不同的超参数。
- **混合精度 **:FSDP支持FP16主权重的高级混合精度训练,以及在梯度上FP16类型的reduce和scatter。但是,模型的某些部分可能只有在使用全精度时才收敛,在这些情况下,需要额外的wrapping,以便有选择地以全精度运行模型的某些部分。
- 状态检查点和推断:当模型规模较大时,保存和加载模型状态可能会变得很困难。FSDP支持多种方法使该任务成为可能,但这些方法是有代价的。
- 最后,FSDP通常与激活检查点函数一起使用,如checkpoint_wrapper 。用户可能需要仔细调整激活检查点策略,以便在有限GPU内存空间内容纳一个大型模型。
0x04 内存管理
我们接下来看看FSDP如何管理内存。
FairScale提供了受ZeRO <https://arxiv.org/pdf/1910.02054.pdf> 启发的算法:当使用数据并行训练时,您需要在计算/通信效率方面权衡内存的使用。另一方面,在使用模型并行训练时,需要为了内存而权衡计算/通信。
模型训练的内存使用通常分为两类:
-
模型状态:优化器状态、梯度、参数。
-
剩余状态:激活、临时缓冲区、碎片内存。
为了减少模型状态下的冗余,ZeRO提出了三种不同的算法。这些在FairScale中实现为优化器状态分片(Optimizer State Sharding,即OSS)、分片数据并行(Sharded Data Parallel,即SDP)和最终完全分片数据并行(Fully Sharded Data Parallel,即FSDP)。让我们深入了解每一个算法的实际机制,并理解它们为什么能够节省内存。
4.1 Optimizer State Sharding (OSS)
FairScale已经实现了与优化器内存相关的内存优化 OSS。
像Adam这样的优化器通常需要保持动量、方差。即使可以使用FP16精度的参数和梯度进行训练,参数和梯度也需要保存为FP32精度。当每个rank更新完整模型时,这意味着相当大一部分内存被优化器状态的冗余表示所占用。
为了克服这种冗余,优化器状态分片需要将模型优化步骤划分在不同的rank之间,以便每个rank只负责更新模型的对应分片。这反过来又确保优化器状态在每个rank上小得多,并且它不包含跨rank的冗余信息。

4.1.1 训练流程
训练流程可以从DDP的执行流程做如下修改:
-
wrapped optimizer根据参数大小(而不是使用顺序)以贪心算法方式来分割优化器状态。这是为了确保每个rank具有几乎相同的优化器内存占用。
-
训练过程类似于PyTorch的分布式数据并行(DDP)的过程。在每个rank上完成前向传播,然后是向后传播。在后向传播过程中,使用allreduce同步梯度。
-
每个rank只更新它负责的优化器分配状态参数,然后丢弃其余的。
-
更新后,将执行broadcast或allgather操作,以确保所有rank都收到最新更新的参数值。
当您使用具有附加状态的优化器(如Adam)时,OSS非常有用。如果您使用的是SGD或任何内存占用有限的优化器,那么在使用多个节点时,由于步骤4中的额外通信,您可能会看到速度减慢。在第2步的allreduce过程中,也有一些用于存储梯度的浪费内存,这些内存随后被丢弃。
4.1.2 最佳实践
-
OSS公开了一个broadcast_fp16 flag,您可能应该在多节点作业中使用它。在单节点实验中通常不需要这样做。
-
如果您的模型在大小方面极不平衡(例如,存在一个巨大的张量),那么这种方法将不会有很大帮助,而张量切分选项,如'fairscale.nn.FullyShardedDataParallel'将更可取。
-
3.OSS应该是DDP环境中的一个临时解决方案,其与大多数DDP功能保持兼容。
4.1.3 性能
-
在单个节点上,OSS应该总是比vanilla PyTorch快,内存节省会因使用的优化器而异
-
当使用多个节点时,OSS也可以比vanilla PyTorch快或慢,具体取决于所使用的优化器和可选标志(如上文提到的broadcast_fp16、梯度压缩、梯度累积)
-
如果您的实验可以使用更大的batch size,则采取更大的batch size并减少所涉及的rank数通常是有益的,或者使用梯度累积,因为这样可以降低通信成本。
4.2 Optimizer + Gradient State Sharding
虽然OSS解决了优化器中的冗余问题,但依然存在梯度聚合计算的重复以及存在用于梯度的额外内存。为了克服冗余梯度内存,我们可以使用梯度分片或ZeRO-2。这已由FairScale中的分片数据并行(SDP)API实现。
为了启用梯度分片,每个 rank 都被分配一组参数,它们负责管理优化器状态以及梯度聚合。通过将一个模型分片分配给一个给定的rank,我们确保梯度被规约到特定的rank,而这些rank又负责相应的更新。因此这减少了通信和内存使用。

4.2.1 训练过程
训练过程如下:
-
与之前一样,包装的优化器在不同的列组中分割参数。
-
该模型现在使用分片数据并行(SDP)包装器进行包装,该包装器允许我们在训练过程中添加适当的hook并维护状态。
-
SDP关注于可训练的参数,并为每个参数添加了一个反向hook。
-
在反向传播过程中,梯度将规约到指定rank,rank是在 1 中作为切分过程的一部分指定的。使用reduce op代替allreduce op,从而减少通信开销。
-
每个rank更新其负责的参数。
-
更新后,将执行广播或allgather,以确保所有rank都收到最新更新的参数值。
OSS和SDPAPI都允许您减少用于梯度和优化器状态的内存,但是如果网络缓慢,则可能存在额外的通信成本。当遇到内存不足(OOM)问题时,可以把OSS和SDP作为第一步尝试。
4.2.2 最佳实践
-
如果使用多个节点,请通过指定
reduce_buffer_size参数确保SDP正在使用reduce buffers。改变它们的大小可能是一个优化目标,最佳配置可能取决于互连状况。 -
如果在单个节点上,通常最好不要使用'reduce_buffer_size',因为它会带来延迟成本,但不会增加内存。将此值设置为0表示不使用此功能。
-
如果您的实验可以使用更大的batch size,则采取更大的batch size并减少所涉及的rank数通常是有益的,或者使用梯度累积,因为这样可以降低通信成本。
4.3 Optimizer + Gradient + Horizontal Model Sharding
为了进一步优化训练并实现更大的内存节省,我们需要启用参数切分。
参数切分类似于梯度和优化器状态,即,每个数据并行rank负责模型参数的一个分片。FairScale通过完全分片数据并行(FSDP)API实现参数分片,该API深受 ZeRO-3 <https://arxiv.org/pdf/1910.02054.pdf>的启发。
参数分片有两个如下关键点:
-
Allreduce操作可以分为reduce和allgather,类似于以前的分片技术(优化器状态和梯度)。
-
可以使用FSDP API包装各个层,该API允许我们在给定实例中将单个层所需的所有参数引入给定GPU,计算前向传递,然后丢弃不属于该rank的参数。

使用FSDP很简单,只需要在代码中简单地替换原来的DDP即可。注意:FSDP目前要求模型是一个nn.Sequential模型。
from torch.utils.data.dataloader import DataLoader
from torchvision.datasets import FakeData
from torchvision.transforms import ToTensor
from fairscale.experimental.nn.offload import OffloadModel
num_inputs = 8
num_outputs = 8
num_hidden = 4
num_layers = 2
batch_size = 8
transform = ToTensor()
dataloader = DataLoader(
FakeData(
image_size=(1, num_inputs, num_inputs),
num_classes=num_outputs,
transform=transform,
),
batch_size=batch_size,
)
model = torch.nn.Sequential(
torch.nn.Linear(num_inputs * num_inputs, num_hidden),
*([torch.nn.Linear(num_hidden, num_hidden) for _ in range(num_layers)]),
torch.nn.Linear(num_hidden, num_outputs),
)
4.3.1 训练过程
具体训练过程如下:
-
在开始计算特定层之前,
allgather模型每个层的正向传播所需的参数。 -
计算向前计算。
-
在特定层开始反向传递之前,
allgather模型每个层反向传播所需的参数。 -
计算向后传播。
-
规约梯度,以便在负责相应参数的rank上累积聚合梯度。
-
让每个rank使用聚合梯度更新已分配给它的参数。
有了FSDP,在使用API进行检查点设置和保存优化器状态时,需要做一些小的更改。鉴于优化器状态和参数的分片性质,任何旨在保存模型状态以供训练或推理的API都需要考虑保存所有worker的权重。FSDP实现所需的管道(required plumbing)以保存所有worker的权重、保存单个worker的权重以及保存所有worker的优化器状态。
FSDP还支持混合精度训练,其中计算和通信均以FP16精度进行。如果要减少在FP32中执行的操作(这是DDP的默认行为),则必须设置 fp32_reduce_scatter=True。
为了进一步节省内存,FSDP支持将当前未使用的参数和梯度卸载到CPU上。这可以通过将“move_params_to_cpu”和“move_grads_to_cpu”设置为True来启用。
4.3.2 最佳实践
-
对于FSDP,最好使用
model.zero_grad(set_to_none=True),因为它在单步执行后节省了大量内存。 -
torch.cuda.amp.autocast与FSDP完全兼容。您需要将'mixed_precision'arg设置为True。 -
如果与激活检查点相结合,则最好使用 FSDP(checkpoint_wrapper(module))而不是checkpoint_wrapper(FSDP(module)).。后者将导致更多的通信,速度也会变慢。
-
FSDP与使用pointwise优化器的DDP兼容,例如Adam、AdamW、ADADDelta、Adamax、SGD等。当使用non-pointwise优化器(例如Adagrad、Adafactor、LAMB等)时,sharding将导致略有不同的结果。
4.3.3 性能
-
为了获得最佳内存效率,请使用“auto_wrap”将网络中的每一层用FSDP进行封装,并将
reshard_after_forward设置为True。这样速度会慢,但是显存开销最小。 -
为了获得最佳训练速度,请将
reshard_after_forward设置为False(不需要包装每一层,但如果设置,则会进一步提高速度)。
支持,FSDP基本原理和如何使用我们已经介绍完毕,下一篇我们介绍其代码细节,看看究竟如何做到最大程度减少内存使用。
0xFF 参考
Fully Sharded Data Parallel: faster AI training with fewer GPUs
ZeRO & DeepSpeed:可以让训练模型拥有超过1000亿个参数的优化(微软)
Fully Sharded Data Parallel: faster AI training with fewer GPUs
https://github.com/microsoft/DeepSpeed
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
Automatic Cross-Replica Sharding of Weight Update in Data-Parallel Training

 浙公网安备 33010602011771号
浙公网安备 33010602011771号