
[源码解析] PyTorch 分布式之 ZeroRedundancyOptimizer
[源码解析] PyTorch 分布式之 ZeroRedundancyOptimizer
0x00 摘要
PyTorch Zero Redundancy Optimizer 是一类旨在解决数据并行训练和模型并行训练之间权衡问题的算法。Zero Redundacy Optimizer 的思想来源于微软的ZeRO,具体实现是基于 Fairscale 的OSS。
Fairscale 实现了 ZeRO 的三个阶段的算法,Fairscale 是 Facebook AI Research (FAIR) 开源的项目,个人理解为是Facebook 大规模深度学习分布式训练的一个试验田,如果其中某个模块发展成熟,就会合并到 PyTorch 之中。
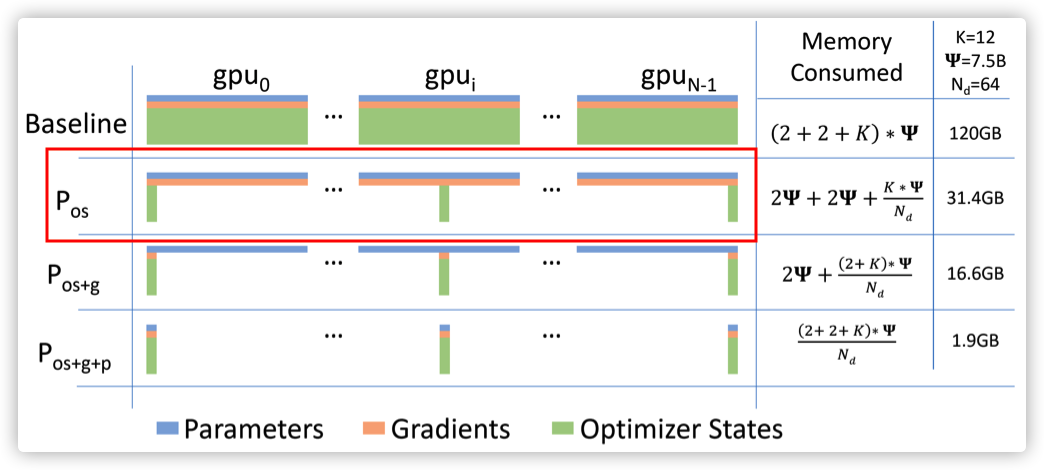
OSS 就是Fairscale实现的 ZeRO-1,其实现了优化器状态分片(参见下图红色方框)。PyTorch 则是基于 FairScale 的 OSS 实现了 ZeroRedundancyOptimizer。
注:本文基于 PyTorch 1.9.0。
0x01 历史
1.1 Github说明
ZeroRedundancyOptimizer 是在 https://github.com/pytorch/pytorch/pull/46750 引入的,我们看看其说明。
ZeroRedundancyOptimizer: an implementation of a standalone sharded optimizer wrapper #46750
Implement the first stage of ZeRO, sharding of the optimizer state, as described in this blog post and this paper. This implementation is completely independent from the DeepSpeed framework, and aims at providing ZeRO-compliant building blocks within the PyTorch scheme of things.
This works by:
- acting as a wrapper to a pytorch optimizer. ZeROptimizer does not optimize anything by itself, it only shards optimizers for distributed jobs
- each rank distributes parameters according to a given partitioning scheme (could be updated), and owns the update of a given shard only
- the .step() is called on each rank as expected, the fact that the optimizer actually works on a shard of the model is not visible from the outside
- when the update is completed, each rank broadcasts the updated model shard to all the other ranks
This can be used with DDP, although some communications are wasted in that case (gradients are all-reduced to all ranks). This implementation was initially developed in Fairscale, and can also be used with an optimized DDP which only reduces to the relevant ranks. More context on ZeRO and PyTorch can be found in this RFC
The API with respect to loading and saving the state is a known pain point and should probably be discussed an updated. Other possible follow ups include integrating more closely to a modularized DDP, making the checkpoints partition-agnostic, exposing a gradient clipping option and making sure that mixed precision states are properly handled.
original authors include @msbaines, @min-xu-ai and myself(blefaudeux )
1.2 解析
因此,我们可以知道如下信息:
- Zero Redundacy Optimizer 的思想来源于微软的ZeRO。
- Fairscale 实现了 ZeRO 的三个阶段的算法,Fairscale 是 Facebook AI Research (FAIR) 开源的项目,个人理解为是Facebook 大规模深度学习分布式训练的一个试验田,如果某个模块发展成熟,就会合并到 PyTorch 之中。
- OSS 是Fairscale实现的 ZeRO-1,其实现了优化器状态分片。
- PyTorch 就是基于 FairScale 的 OSS 实现了 ZeroRedundancyOptimizer。
我们有必要具体看一下。
0x02 背景知识
2.1 ZeRO
ZeRO(零冗余优化器,Zero Redundacy Optimizer)是微软开源的DeepSpeed(一种优化大规模训练的框架)的一部分。ZeRO 是一种深度学习模型的内存优化方法,其寻求模型并行和数据并行的一个中间点,以最大化模型的可扩展性。
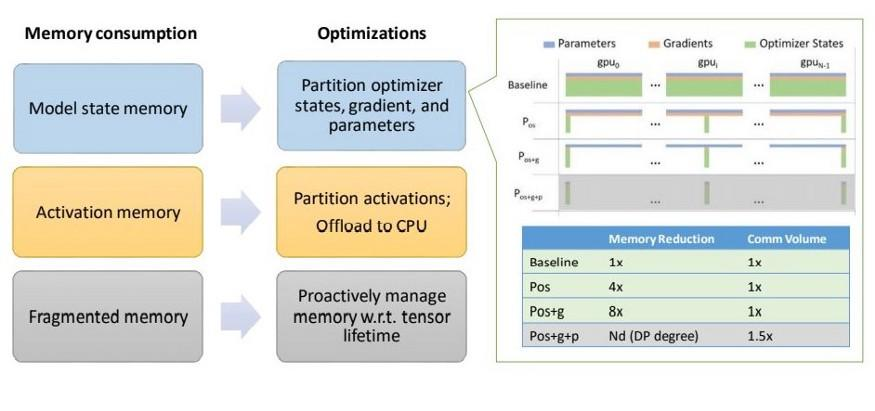
ZeRO的优化涉及了深度学习模型内存使用的多个方面,包括激活内存、碎片内存和模型状态内存。
- 模型状态内存(Model State Memory): 深度学习模型的状态可归为:优化器状态、梯度和参数这三个基本过程。
- 激活内存(Activation Memory):在优化了模型状态内存之后,人们发现激活函数也会导致瓶颈。激活函数计算位于前向传播之中,用于支持后向传播。
- 碎片内存(Fragmented Memory):深度学习模型的低效有时是由于内存碎片所导致的。在模型之中,每个张量的生命周期不同,由于不同张量寿命的变化而会导致一些内存碎片。由于这些碎片的存在,会导致即使有足够的可用内存,也会因为缺少连续内存而使得内存分配失败。ZeRO 根据张量的不同寿命主动管理内存,防止内存碎片。
比如优化可以参见下图:
2.2 Fairscale 的 ZeRO 实现
我们接下来看看 Fairscale 的使用指南。

这其实是分布式/大规模机器学习方案的一个梳理,从中可以看到,其依据 ZeRO <https://arxiv.org/pdf/1910.02054.pdf>实现了三种不同的算法,分别对应了 ZeRO的三个阶段:
- Optimizer State Sharding (OSS) 实现了 Optimizer 分片,优化了分区优化器状态的内存使用。
- Sharded Data Parallel (SDP) 负责 Optimizer + Gradient State Sharding。
- Fully Sharded Data Parallel (FSDP) 实现了 Optimizer + Gradient + Horizontal Model Sharding。
2.3 Optimizer State Sharding (OSS)
因为OSS是ZeroRedundancyOptimizer的源头,所以我们先看看其思路。OSS实现了与优化器内存相关的优化。像Adam这样的优化器通常需要保持动量、方差。即便可以使用FP16精度的参数和梯度进行训练,参数和梯度也需要保存为FP32精度。当每个rank更新完整模型时,这意味着相当大一部分内存被优化器状态的冗余表示所占用。为了克服这种冗余,优化器状态分片需要将模型优化步骤划分在不同的rank之间,以便每个rank只负责更新模型的对应分片。这反过来又确保优化器状态在每个rank上小得多,并且它不包含跨rank的冗余信息。
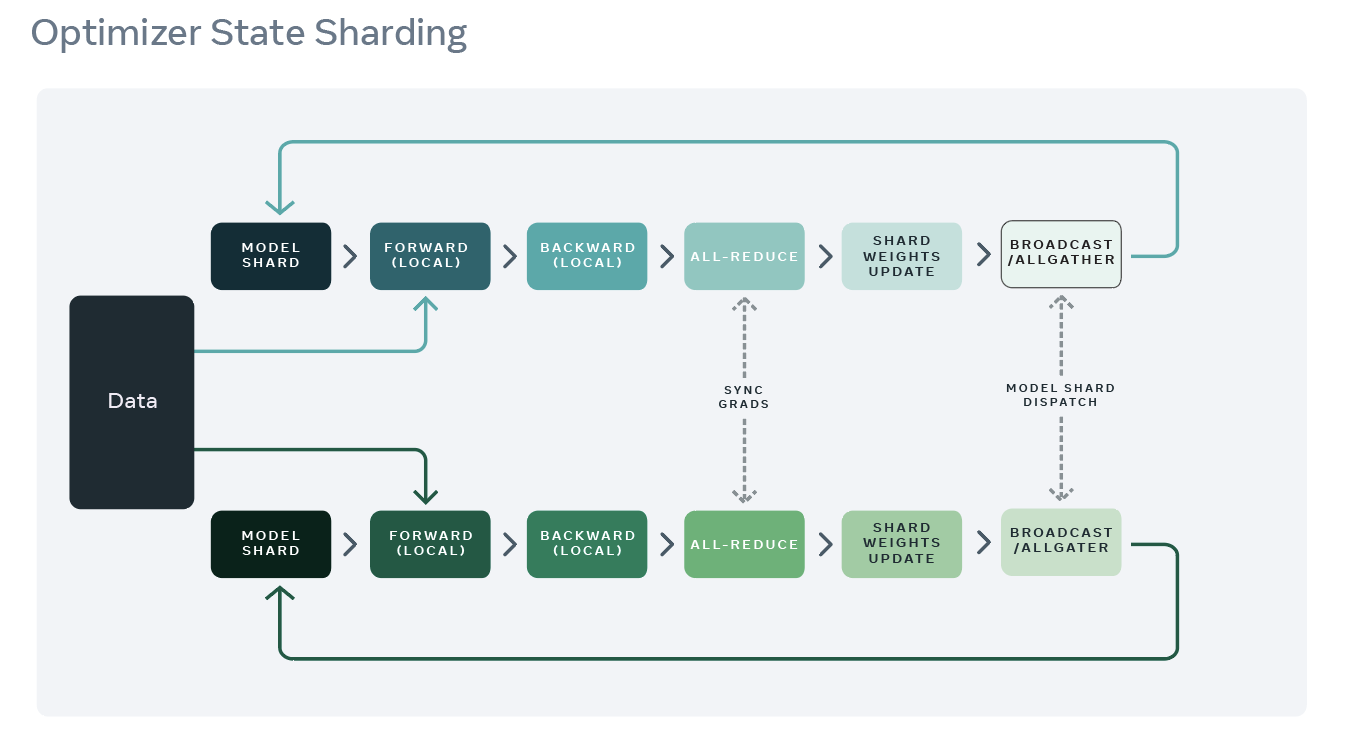
2.3.1 训练流程
OSS 训练流程可以从DDP的执行流程做如下修改:
-
wrapped optimizer根据参数大小(而不是使用顺序)以贪心算法方式来对优化器状态进行分片。这是为了确保每个rank具有几乎相同大小的优化器内存。
-
训练过程类似于PyTorch的分布式数据并行(DDP)的过程。在每个rank上先完成前向传播,然后是向后传播。在后向传播过程中,使用allreduce同步梯度。
-
每个rank只更新它负责的优化器状态参数,然后丢弃其余的优化器参数。
-
更新后,将执行broadcast或allgather操作,以确保所有rank都收到最新更新的参数值。
具体参见下图。
2.3.2 最佳实践
几条最佳实践如下:
- OSS公开了一个broadcast_fp16 flag,您可能应该在多节点作业中使用它。在单节点实验中通常不需要这样做。
- 如果您的模型在大小方面极不平衡(例如,存在一个巨大的张量),那么这种方法将不会有很大帮助,而张量切分选项,如 fairscale.nn.FullyShardedDataParallel 将更可取。
- OSS与大多数DDP功能保持兼容。
- OSS应该是DDP环境中的一个临时解决方案。
2.3.3 性能说明
以下是一些关于性能的说明。
-
在单个节点上,OSS应该总是比vanilla PyTorch快,内存节省会因使用的优化器而异。
-
当您使用具有附加状态的优化器(如Adam)时,OSS非常有用。
-
如果您使用的是SGD或任何内存占用有限的优化器,那么在使用多个节点时,由于上面流程之中步骤4中的额外通信,您可能会看到速度减慢。在第2步的allreduce过程中,也有一些用于存储梯度的浪费内存,这些内存随后被丢弃。
-
当使用多个节点时,OSS也可以比vanilla PyTorch快或慢,具体取决于所使用的优化器和可选标志(如上文提到的broadcast_fp16、梯度压缩、梯度累积)
-
如果您可以使用更大的batch size,最好是则采取更大的batch size并减少所涉及的rank数,或者使用梯度累积,因为这样可以降低通信成本。
我们接下来正式进入 ZeroRedundancyOptimizer。
0x03 如何使用
我们首先使用 https://pytorch.org/tutorials/recipes/zero_redundancy_optimizer.html 来看看如何使用 ZeroRedundancyOptimizer。
3.1 背后思想
ZeroRedundancyOptimizer的思想来自 DeepSpeed/ZeRO project 和 Marian ,这两个项目会跨分布式数据并行进程对优化器状态进行分片,以减少每个进程的内存占用。ZeRO的优化策略主要是通过对模型状态进行切分以优化显存占用,模型状态主要包括优化器状态,梯度和模型参数。
ZeroRedundancyOptimizer 则实现了对优化器状态(optimizer states)的切分,优化器状态就是优化器运行所需要的参数和本地状态。例如,SGD需要和模型参数一样大小的动量,Adam优化器对于用每个参数保存了exp_avg 和 exp_avg_sq 状态。因此,Adam优化器的内存消耗至少是模型大小的两倍。所以,当模型较大时,优化器状态是不小的显存开销。
在分布式数据并行入门教程(Getting Started With Distributed Data Parallel )中,我们展示了如何使用DistributedDataParallel(DDP)来训练模型。在DDP中:
- 每个worker进程(rank,node或者device)都保留优化器的专用副本。
- 由于DDP已经在反向传播中用all-reduce同步了梯度,因此所有优化器副本在每次迭代中都将在相同的参数和梯度值上运行。
- 这些优化器用all-reduce后的gradients去更新模型参数,这就是DDP可以使各个模型副本(rank)保持相同参数状态的原因。
根据这一观察结果,我们可以通过在DDP进程之间分割优化器状态来减少优化器内存占用。更具体地说,就是:
- 把优化器切分到不同worker之上,每个worker上的优化器实例只保留其模型参数分片所对应的那部分(1/world_size)优化器状态,而不是为所有参数创建对应的参数状态。
- 优化器
step()函数只负责更新其分片中的参数,当worker完成参数更新之后,会将更新后的参数广播给所有其他对等DDP进程,以便所有模型副本仍处于相同的状态。
3.2 如何使用
ZeroRedundancyOptimizer可与torch.nn.parallel.DistributedDataParallel结合使用,以减少每个rank的内存峰值消耗。下面的代码演示了如何使用ZeroRedundancyOptimizer. 大部分代码类似于 Distributed Data Parallel notes中给出的简单DDP示例。 主要区别在于example函数中的if else子句,这个语句包装了优化器构造,可以在ZeroRedundancyOptimizer和Adam 之间进行切换。我们只要使用 ZeroRedundancyOptimizer对常规的optimizer进行warp即可。
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.distributed.optim import ZeroRedundancyOptimizer
from torch.nn.parallel import DistributedDataParallel as DDP
def print_peak_memory(prefix, device):
if device == 0:
print(f"{prefix}: {torch.cuda.max_memory_allocated(device) // 1e6}MB ")
def example(rank, world_size, use_zero):
torch.manual_seed(0)
torch.cuda.manual_seed(0)
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '29500'
# create default process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)
# create local model
model = nn.Sequential(*[nn.Linear(2000, 2000).to(rank) for _ in range(20)])
print_peak_memory("Max memory allocated after creating local model", rank)
# construct DDP model
ddp_model = DDP(model, device_ids=[rank])
print_peak_memory("Max memory allocated after creating DDP", rank)
# define loss function and optimizer
loss_fn = nn.MSELoss()
if use_zero:
optimizer = ZeroRedundancyOptimizer( # 这里使用了ZeroRedundancyOptimizer
ddp_model.parameters(),
optimizer_class=torch.optim.Adam, # 包装了Adam
lr=0.01
)
else:
optimizer = torch.optim.Adam(ddp_model.parameters(), lr=0.01)
# forward pass
outputs = ddp_model(torch.randn(20, 2000).to(rank))
labels = torch.randn(20, 2000).to(rank)
# backward pass
loss_fn(outputs, labels).backward()
# update parameters
print_peak_memory("Max memory allocated before optimizer step()", rank)
optimizer.step()
print_peak_memory("Max memory allocated after optimizer step()", rank)
print(f"params sum is: {sum(model.parameters()).sum()}")
def main():
world_size = 2
print("=== Using ZeroRedundancyOptimizer ===")
mp.spawn(example,
args=(world_size, True),
nprocs=world_size,
join=True)
print("=== Not Using ZeroRedundancyOptimizer ===")
mp.spawn(example,
args=(world_size, False),
nprocs=world_size,
join=True)
if __name__=="__main__":
main()
输出如下所示。
无论是否使用ZeroRedundancyOptimizer,在每个迭代之后,模型参数都使用了同样内存,所以打印的输出是一样的。当启用 ZeroRedundancyOptimizer 来封装 Adam时,优化器 step() 的内存峰值消耗是 Adam内存消耗的一半。这与我们的预期相符,因为我们把 Adam优化器状态分片到了两个进程之上。
=== Using ZeroRedundancyOptimizer ===
Max memory allocated after creating local model: 335.0MB
Max memory allocated after creating DDP: 656.0MB
Max memory allocated before optimizer step(): 992.0MB
Max memory allocated after optimizer step(): 1361.0MB
params sum is: -3453.6123046875
params sum is: -3453.6123046875
=== Not Using ZeroRedundancyOptimizer ===
Max memory allocated after creating local model: 335.0MB
Max memory allocated after creating DDP: 656.0MB
Max memory allocated before optimizer step(): 992.0MB
Max memory allocated after optimizer step(): 1697.0MB
params sum is: -3453.6123046875
params sum is: -3453.6123046875
3.3 小结
经过上面的原理分析和使用说明,我们知道:ZeroRedundancyOptimizer类可以对任意一个optim.Optimizer 进行封装,并可以在组中的ranks之中分割自己的状态。每个rank中的本地优化器实例只负责更新大约 1 / world_size 的参数,因此只需要保持 1 / world_size 大小的优化器状态。
所以我们下面分析的重点就是:
- 如何将优化器参数进行分区?
- 每个rank如何知道自己对应的参数?
0x04 初始化
我们首先从 __init__ 看看如何构建,其主要做了三步:
- 初始化基类。
- 初始化各种成员变量。
- 使用 _update_trainable 内部同步&构建buffer,其内部会调用 _optim_constructor 来构建内部优化器。
def __init__(
self,
params,
optimizer_class: Type[Optimizer], # 就是被包装的原生优化器类型
group: Optional[Any] = None,
parameters_as_bucket_view: bool = False,
**default: Any,
):
# Hold all the model params in the root .param_groups
# NOTE: the default constructor uses `add_param_group` which is partially overloaded here
# we introduce the `initialized` flag for be able to dissociate the behaviour of
# `add_param_group` in between super() and ZeroRedundancyOptimizer
self.initialized = False
super().__init__(params, default) # 初始化基类
# Partition information. lazy evaluation, computed if requested
self._per_device_params_cache: "OrderedDict[torch.device, List[List[Parameter]]]" = (
OrderedDict()
) # device, rank, params
# Build the wrapped optimizer, responsible for a shard of the params
self._param_rank_cache: Dict[torch.Tensor, int] = {} # 初始化各种成员变量
self._param_to_index_cache: Dict[int, int] = {}
self._partition_parameters_cache: List[List[Dict]] = []
self._index_to_param_cache: Dict[int, torch.Tensor] = {}
self._all_params = params
self._reference_is_trainable_mask = list(map(_is_trainable, self._all_params))
self.group = group if group is not None else dist.group.WORLD
self.world_size = dist.get_world_size(self.group)
self.rank = dist.get_rank(self.group)
# global是用来在进程之间同步
self.global_rank = _get_global_rank(self.group, self.rank)
self.parameters_as_bucket_view = parameters_as_bucket_view
self._optim_defaults = default
self._optim_constructor = optimizer_class # 如何生成原生优化器
# Optional consolidated optimizer state
self._all_states: List[Dict[str, Any]] = []
# Current default device is set by the parameters allocated to this rank
self._device = list(self._per_device_params.keys())[0]
self.buckets: Dict[torch.device, List[torch.Tensor]] = {}
self._update_trainable() # 内部同步&构建buffer,调用 _optim_constructor 来构建内部优化器
self.initialized = True
因为 Python 语言的特点,没有专门的地方来初始化成员变量,而是在程序运行之中遇到了某个变量就即时初始化。所以,我们不会按照程序实际初始化的顺序来分析,而是按照成员变量逻辑上初始化的顺序来分析。
以下分析的这些函数或者说成员变量都是在__init__方法之中被间接调用或者初始化。
4.1 将参数分区
partition_parameters 方法会将参数进行分区,其返回 _partition_parameters_cache。
被包装(wrapped)的optimizer根据参数大小(而不是使用顺序)以排序贪婪(sorted-greedy)算法来对优化器状态进行分片,在每个rank中打包一些参数,这样每个参数都属于一个rank,不在ranks之间划分。分区是任意的,可能与参数注册或使用顺序不匹配。这是为了确保每个rank具有几乎相同大小的优化器内存。
def partition_parameters(self) -> List[List[Dict]]:
r"""
Partitions parameters across distributed data parallel ranks.
Returns:
a list of ``param_groups`` (which is a list of dict) where each
element of the list contains the param_groups for a rank. Element 0
corresponds to rank 0, etc. We need all the ranks for the broadcast
inside ``step()``.
"""
if len(self._partition_parameters_cache) == 0:
self._partition_parameters_cache = [list() for _ in range(self.world_size)]
# 生成一个数组,用来记录每个rank的大小,一共有world size个rank
sizes = [0] * self.world_size
for param_group in self.param_groups: # 遍历参数组
param_lists: List[List] = [list() for _ in range(self.world_size)]
for param in param_group["params"]:
# Add this param to rank with smallest size.
rank = sizes.index(min(sizes)) # 找到最小的那个rank
param_lists[rank].append(param) # 把参数放到最小rank之中
sizes[rank] += param.numel() # 增加rank的大小
for rank, params in enumerate(param_lists): # 遍历list
param_group_rank = copy.copy(param_group)
param_group_rank["params"] = params
self._partition_parameters_cache[rank].append(param_group_rank)
return self._partition_parameters_cache
这里就分区好了,最终返回一个param_groups 的列表(这是一个dict列表),列表的每个元素都包含一个rank的param_groups,比如元素0对应于rank 0,每个rank的group的参数有差不多大小。在step()中,我们需要所有rank的信息来进行广播。下图给出了rank 0和 rank 5 对应的param_groups。
_partition_parameters_cache
+
|
|
v +---------------+
+-------+---------+ | param_group |
| 0 +----> | | <-------+ 100 M +------------->
+-----------------+ +---------------+
| 1 | | | +--------+---------+------+--------+
+-----------------+ | "params" +------> |param 1 | param 2 | ... | param 6|
| 2 | | | | | | | |
+-----------------+ +---------------+ +--------+---------+------+--------+
| |
| |
| ...... |
| | +---------------+
+-----------------+ | param_group | <-------+ 105 M +----------------->
| 5 +----> | |
+-----------------+ +---------------+ +--------+---------+-------+---------+
| | | | | | |
| "params" +------> | param 7| param 8 | ... | param 11|
| | | | | | |
+---------------+ +--------+---------+-------+---------+
4.2 将参数分给rank
现在,参数已经分成大小相近的group,接下来需要把这些group分到各个rank之上。
_param_to_rank 方法生成一个表,里面记录每一个参数对应的rank,就是哪个参数在哪个rank之中。
@property
def _param_to_rank(self) -> Dict[torch.Tensor, int]:
r"""Look up table to match a given param with a data parallel rank"""
if len(self._param_rank_cache) == 0:
for rank, param_groups in enumerate(self.partition_parameters()):
for param_group in param_groups:
for param in param_group["params"]:
self._param_rank_cache[param] = rank
return self._param_rank_cache
依据上图例子,我们知道param 1,param 2,param 6 在rank 0之中,param 8,param 11 在 rank 5 之中.....,具体如下:
_param_rank_cache
+
|
|
|
v
+----+--------------+------------+
| | |
| param 1 | 0 |
+--------------------------------+
| | |
| param 2 | 0 |
+--------------------------------+
| | |
| param 6 | 0 |
+--------------------------------+
| | |
| param 8 | 5 |
+--------------------------------+
| | |
| param 11 | 5 |
+--------------------------------+
| | |
| param n | n |
| | |
+-------------------+------------+
4.3 _per_device_params
现在,参数已经分配给各个rank,接下来就要具体分配到设备之上,每个设备上可能包含多个rank的参数组。_per_device_params 方法就是把优化器的param_groups在各个设备之间进行分配,其返回_per_device_params_cache。
请注意,_per_device_params 这里包括全部的模型参数,虽然已经按照设备进行了分类。即,在每个ZeRO优化器之中都是相同的。这样ZeRO优化器之间可以广播同步这些参数。
@property
def _per_device_params(self) -> Dict[torch.device, List[List[Parameter]]]:
r"""
Sorted list of all the params, first per device then per rank.
Within a list params are sorted per number of elements to allow for an easy bucketing.
"""
if len(self._per_device_params_cache) == 0:
# Go through all params, log them per device
# The ordering is important here, needs to be the same on all ranks
# So that ulterior broadcast calls are matching
for param_group in self.param_groups: # 遍历参数
for param in param_group["params"]:
device = param.device # 找到其设备
if self._per_device_params_cache.get(device) is None:
self._per_device_params_cache[device] = [[] for _ in range(self.world_size)]
# 每个设备内部还需要按照rank来分开
self._per_device_params_cache[device][self._param_to_rank[param]] += [param]
# Sort param_lists by size
for k in self._per_device_params_cache.keys():
for r in self._per_device_params_cache[k]:
r.sort(key=lambda x: x.numel())
return self._per_device_params_cache
比如,下面 CPU,GPU 1(忽略),GPU 2 都有自己的参数列表,每个列表之内都是按照参数大小排列。
_per_device_params_cache
+
| +--------+--------+-------+--------+
| | | | | |
| +---------+ | param1 | param3 |param5 | param6 |
v | | | | | | |
+----+--------------+ | rank 0 +----> | 1k | 2k | 3k | 7k |
| | | | +--------+--------+-------+--------+
| "CPU" +----> +---------+
| | | |
+-------------------+ | rank 1 | +--------+--------+-------+--------+
| | | +----> | | | | |
| "GPU 1" | +---------+ | param9 | param2 | param4| param8 |
| | | | | | |
+-------------------+ | 0.5k | 1k | 4k | 8k |
| | +--------+--------+-------+--------+
| "GPU 2" | +---------+
| +----> | | +---------+------------+-----------+
+-------------------+ | | | | | |
| rank 5 +----> | param 11| param 13 | param 15 |
| | | | | |
+---------+ +---------+------------+-----------+
| |
| rank 6 | +---------+------------+-----------+
| +----> | | | |
| | | param 19| param 12 | param 14 |
+---------+ | | | |
+---------+------------+-----------+
4.4 _update_trainable
因为某些参数会变化,所以需要在本地优化器和ZeroRedundancyOptimizer 之间彼此同步。
- 首先得到 self._default_device 为 "CPU" 或者 "GPU #"。
- 然后调用 _optim_constructor 来构建内部优化器。注意,这里就是告诉本地优化器,你就负责优化这些参数即可,不用管其他的shard。partition_parameters 方法前面提到,其会将参数进行分区,其返回 _partition_parameters_cache。
# 只是选取自己rank对应的参数进行优化
self.optim = self._optim_constructor(self.partition_parameters()[self.rank], **self._optim_defaults)
# 运行时变量如下:
#_optim_constructor = {type} <class 'torch.optim.adam.Adam'>
#_optim_defaults = {dict: 1} {'lr': 0.01}
-
接着,调用 _sync_param_groups 同步参数。
-
最后,建立 flat buffer。
具体代码如下:
def _update_trainable(self) -> None:
r"""
Updates the partitioning and communication patterns if the trainability
(``requires_grad``) of some parameters changed.
"""
# Create the optim which will work on the param shard
if not hasattr(self, "optim"):
self._clear_cache()
# 获得缺省设备
self._default_device = list(self._per_device_params.keys())[0]
# 构建本地优化器,只是选取本rank对应的参数
self.optim = self._optim_constructor(self.partition_parameters()[self.rank], **self._optim_defaults)
# 调用 _sync_param_groups 同步参数,self.optim 是被包装的优化器
self._sync_param_groups(self.optim.param_groups, self.param_groups)
if self.parameters_as_bucket_view:
self._setup_flat_buffers() # 建立 flat buffer
我们用 rank 5 为例,其本地优化器就只是指向 _partition_parameters_cache[5] 对应的那部分待优化参数,本地优化器只优化这些参数即可。
这样就实现了优化器参数分区。_partition_parameters_cache[5] 这样的参数可以在后续被放置到 GPU 之上,这样每个GPU就只包括 优化器的部分分区。
需要注意的是:模型参数,梯度都没有变化,只是本地 ZeroRedundancyOptimizer 指向了部分需要优化的参数,所以 ZeroRedundancyOptimizer 的优化器状态也相应减少了。
就下图来说,原先优化器需要优化全部的参数,可能有 100 M + 105 M + ....,现在ZeroRedundancyOptimizer只需要优化 105 M。
_partition_parameters_cache
+
|
|
v +---------------+
+-------+---------+ | param_group |
| 0 +----> | | <-------+ 100 M +------------->
+-----------------+ +---------------+
| 1 | | | +--------+---------+------+--------+
+-----------------+ | "params" +------> |param 1 | param 2 | ... | param 6|
| 2 | | | | | | | |
+-----------------+ +---------------+ +--------+---------+------+--------+
| |
| |
| ...... |
| | +---------------+
+-----------------+ | param_group | <-------+ 105 M +----------------->
| 5 +----> | |
+-----------------+ +---------------+ +--------+---------+-------+---------+
| | | | | | |
+--> | "params" +------> | param 7| param 8 | ... | param 11|
| | | | | | | |
| +---------------+ +--------+---------+-------+---------+
|
|
|
+-----------------------+
| Local Optimizer | |
| | |
| | |
| + |
| |
| |
| |
| |
+-----------------------+
我们还需要再细化一下,看看 _sync_param_groups 和 _setup_flat_buffers 这两个函数。
4.4.1 同步参数组
_sync_param_groups 用来把内部优化器的参数组同步到本Zero优化器的参数组。
@staticmethod
def _sync_param_groups(source: List[Dict[Any, Any]], destination: List[Dict[Any, Any]]) -> None:
r"""Sync learning rate and other optimizer attributes (needed to support schedulers)."""
for source_group, destination_group in zip(source, destination):
# Sync everything but the parameters
for k in filter(lambda x: x != "params", source_group.keys()):
destination_group[k] = source_group[k]
4.4.2 建立single buffer
如果设置了parameters_as_bucket_view,则调用_setup_flat_buffers 建立若干buffer。同样设备上同样rank的张量被视为一个buffer。就是处理 _per_device_params。
def _setup_flat_buffers(self) -> None:
r"""
Make all params which are on the same device and tied to the same rank
views of a single buffer. This is used at construction time, and anytime
parameter trainability is changed (frozen or unfrozen) and
``_update_trainable`` is called.
"""
for device, per_rank_params in self._per_device_params.items():
# Only wipe the existing buckets if there are none
# (could be that this is called twice, when trainability changes)
if device not in self.buckets.keys():
self.buckets[device] = []
# Make parameters a view of the bucket
for dst_rank, params in enumerate(per_rank_params):
if len(params) > 0:
# Clone the non-trainable params, if in a bucket it will get destroyed
for param in filter(lambda x: not x.requires_grad, params):
param.data = param.data.detach().clone()
# Merge all the trainable params in a single bucket
trainable_params = list(filter(_is_trainable, params))
buffer_size = sum(map(lambda x: x.numel(), trainable_params))
bucket = torch.empty(buffer_size, dtype=params[0].dtype, device=device)
offset = 0
for param in trainable_params:
offset_next = offset + param.numel()
bucket[offset:offset_next].copy_(param.data.flatten())
param.data = bucket[offset:offset_next].view_as(param.data)
offset = offset_next
# Either replace the existing bucket, or create it
if len(self.buckets[device]) == dst_rank:
self.buckets[device].append(bucket)
else:
self.buckets[device][dst_rank] = bucket
else:
self.buckets[device].append(torch.zeros(1, device=device))
具体可以看看如下图例,同样设备上同样rank的张量被视为一个buffer。
buckets
+
|
| +---------------------------------------+
v | Tensor |
+----+-------+ | +-----------------------------------+ |
| | | | | |
| "CPU" +-----> | | Param 1, param 2, Param 3...... | |
| | | +-----------------------------------+ |
+------------+ +---------------------------------------+
| |
| "GPU 1" +-----> +---------------------------------------+
| | | Tensor |
+------------+ | +-----------------------------------+ |
| | | | | |
| | | | Param 6, Param 7, Param 8...... | |
| | | +-----------------------------------+ |
| | +---------------------------------------+
| |
+------------+
0x05 更新参数
我们接下来看看优化器如何更新参数,其逻辑如下:
- 如果计算图有变化,则需要重新处理。
- 调用 _sync_param_groups 将本地优化器参数同步给 ZeRO优化器,防止其被 scheduler 已经修改。
- 调用 self.optim.step,让本地优化器在本地参数之上进行更新。
- 调用 dist.broadcast 在ranks 之间同步参数。
- 再次调用 _sync_param_groups 将本地优化器参数同步给 ZeRO优化器,因为其已经被更新了。
def step(self, closure: Optional[Callable[[], float]] = None, **kwargs: Any) -> Optional[float]:
r"""
Performs a single optimization step (parameter update).
Arguments:
closure (callable): A closure that reevaluates the model and
returns the loss. Optional for most optimizers.
Returns:
optional loss, depends on the underlying optimizer
.. note: Any extra parameter is passed to the base optimizer as-is
"""
# Check whether the model trainability graph changed
# 如果计算图有变化,则需要重新处理
trainable_mask = list(map(_is_trainable, self._all_params))
if trainable_mask != self._reference_is_trainable_mask:
self._update_trainable()
self._reference_is_trainable_mask = trainable_mask
# Sync oss param_groups attributes in case they've been updated by a scheduler.
self._sync_param_groups(self.param_groups, self.optim.param_groups)
# Run the optimizer step on this shard only:
# 更新本地参数
if closure is not None:
loss = self.optim.step(closure=closure, **kwargs) # type: ignore[call-arg]
else:
loss = self.optim.step(**kwargs)
# Sync all the updated shards in between the ranks
handles = []
if self.parameters_as_bucket_view:
for device in self.buckets.keys():
for src_rank, bucket in enumerate(self.buckets[device]):
global_src_rank = _get_global_rank(self.group, src_rank)
handles.append(dist.broadcast(tensor=bucket, src=global_src_rank, group=self.group, async_op=True))
else:
for device, per_rank_params in self._per_device_params.items(): # 遍历设备+其参数
for dst_rank, params in enumerate(per_rank_params): # 遍历rank
global_dst_rank = _get_global_rank(self.group, dst_rank)
for param in params: # 对于每一个参数,都进行broadcast
handles.append(
dist.broadcast(tensor=param.data, src=global_dst_rank, group=self.group, async_op=True)
)
_ = list(map(lambda x: x.wait(), handles))
# Sync hypothethical new results from the wrapped optimizer to the exposed param_groups
self._sync_param_groups(self.optim.param_groups, self.param_groups)
return loss
5.1 更新
首先是本地更新模型参数。
# 更新本地参数
if closure is not None:
loss = self.optim.step(closure=closure, **kwargs) # type: ignore[call-arg]
else:
loss = self.optim.step(**kwargs)
假设模型一共有8个参数,分成上下两个节点,每个节点有一个优化器。这里为了更好说明,在上下两个优化器中,把参数和rank序号大的放在上面。
再次强调:模型参数,梯度都没有变化,只是本地 ZeroRedundancyOptimizer 指向了部分需要优化的参数,所以 ZeroRedundancyOptimizer 的优化器状态也相应减少了。
所以,上下两个优化器之中,模型(需要优化的参数)大小都一样,但是:
-
ZeroRedundancyOptimizer 0 之中,优化的是 rank 0,参数 0 ~ 3 是本地优化的,对应两个节点来说,这部分参数是全局最新的。
-
ZeroRedundancyOptimizer 1 之中,优化的是 rank 1,参数 4 ~ 7 是本地优化的,对应两个节点来说,这部分参数是全局最新的。
+--------------------------------------------------------------------------------+
| ZeroRedundancyOptimizer 0 |
| |
| _per_device_params_cache |
| + |
| | |
| v +--------+ +--------+--------+-------+--------+ |
| +---+-----+ | rank 1 | | | | | | |
| | | | +---------> | param4 | param5 | param6| param7 | |
| | "GPU"1" +--> +--------+ | | | | | |
| | | | | +--------+--------+-------+--------+ |
| +---------+ | rank 0 | |
| | | +--------+--------+-------+--------+ |
| | +---------> | | | | | |
| +--------+ | param0 | param1 |param2 | param3 | NEW |
| +----> | | | | | |
| +----------------+ | +--------+--------+-------+--------+ |
| |Local Optimizer | | |
| | +----------+ |
| | | |
| +----------------+ |
| | Node 0
+--------------------------------------------------------------------------------+
+--------------------------------------------------------------------------------+
| | Node 1
| |
| _per_device_params_cache |
| + |
| | +--------+--------+-------+--------+ |
| v +--------+ +---> | | | | | |
| +---+-----+ | rank 1 | | | param4 | param5 | param6| param7 | NEW |
| | | | +---------> | | | | | |
| | "GPU"1" +--> +--------+ | +--------+--------+-------+--------+ |
| | | | | | |
| +---------+ | rank 0 | | +--------+--------+-------+--------+ |
| | +---------> | | | | | |
| | | | | param0 | param1 |param2 | param3 | |
| +--------+ | | | | | | |
| | +--------+--------+-------+--------+ |
| +----------------+ | |
| |Local Optimizer | | |
| | +------------+ |
| | | |
| +----------------+ ZeroRedundancyOptimizer 1 |
| |
+--------------------------------------------------------------------------------+
5.2 广播
首先需要注意,_per_device_params 这里包括全部的模型参数,虽然已经按照设备进行了分类。
现在状态是,本rank的优化器参数(本分区)已经更新了,就是模型的部分得到了更新。为了维持模型的最新,需要彼此进行广播。
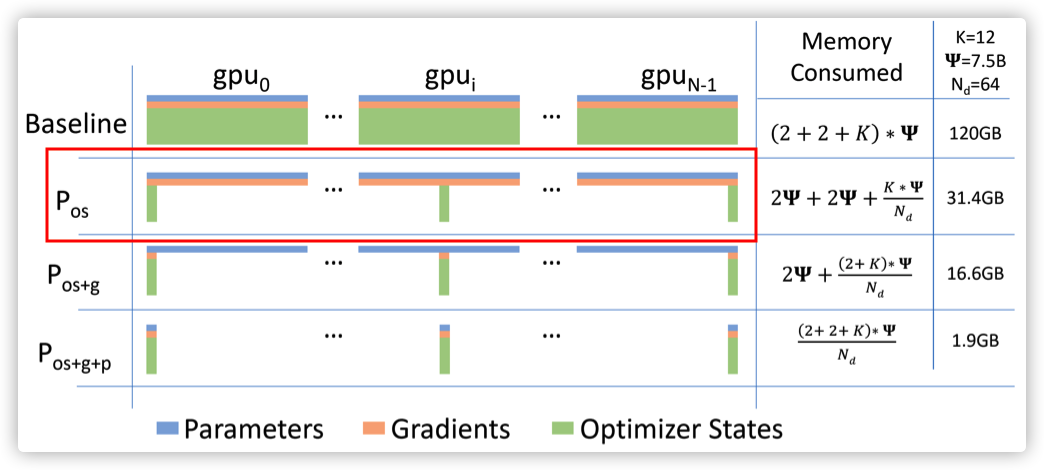
在本地更新参数后,每个rank将向所有其他对等方广播其参数,以保持所有模型副本处于相同状态。
+--------------------------------------------------------------------------------+
| ZeroRedundancyOptimizer 0 |
| |
| _per_device_params_cache |
| + |
| | |
| v +--------+ +--------+--------+-------+--------+ |
| +---+-----+ | rank 1 | | | | | | |
| | | | +---------> | param4 | param5 | param6| param7 | |
| | "GPU"1" +--> +--------+ | | | | | |
| | | | | +--------+--------+-------+--------+ |
| +---------+ | rank 0 | |
| | | +--------+--------+-------+--------+ |
| | +---------> | | | | | |
| +--------+ | param0 | param1 |param2 | param3 | NEW |
| +----> | | | | | |
| +----------------+ | +---+----+---+----+-+-----+--+-----+ |
| |Local Optimizer | | | | | | |
| | +----------+ | | | | |
| | | | ^ | ^ | ^ | ^ |
| +----------------+ | | | | | | | | |
| | | | | | | | | | Node 0
+--------------------------------------------------------------------------------+
| | | | | | | |
| | | | | | | |
| | | | | | | |
+--------------------------------------------------------------------------------+
| | | | | | | | | | Node 1
| v | v | v | v | |
| _per_device_params_cache | | | | |
| + | | | | |
| | +------+-+------+-+----+--+------+-+ |
| v +--------+ +---> | | | | | |
| +---+-----+ | rank 1 | | | param4 | param5 | param6| param7 | NEW |
| | | | +---------> | | | | | |
| | "GPU"1" +--> +--------+ | +--------+--------+-------+--------+ |
| | | | | | |
| +---------+ | rank 0 | | +--------+--------+-------+--------+ |
| | +---------> | | | | | |
| | | | | param0 | param1 |param2 | param3 | |
| +--------+ | | | | | | |
| | +--------+--------+-------+--------+ |
| +----------------+ | |
| |Local Optimizer | | |
| | +------------+ |
| | | |
| +----------------+ ZeroRedundancyOptimizer 1 |
| |
+--------------------------------------------------------------------------------+
5.3 同步本地参数
最后,需要再次调用 _sync_param_groups 将本地优化器参数同步给 ZeRO优化器,因为其已经被更新了。
# Sync hypothethical new results from the wrapped optimizer to the exposed param_groups
self._sync_param_groups(self.optim.param_groups, self.param_groups)
具体函数我们再揪出来温习一下。
@staticmethod
def _sync_param_groups(source: List[Dict[Any, Any]], destination: List[Dict[Any, Any]]) -> None:
r"""Sync learning rate and other optimizer attributes (needed to support schedulers)."""
for source_group, destination_group in zip(source, destination):
# Sync everything but the parameters
for k in filter(lambda x: x != "params", source_group.keys()):
destination_group[k] = source_group[k]
0xFF 参考
谈谈torch1.10中的ZeroRedundancyOptimizer和Join
https://pytorch.org/tutorials/recipes/zero_redundancy_optimizer.html
https://pytorch.org/docs/master/distributed.optim.html
https://medium.com/swlh/inside-microsofts-new-frameworks-to-enable-large-scale-ai-953e9a977912

