Spark 搭建
系统环境
操作系统: CentOS 7 主机名: centos02 IP: 192.168.122.1 Java: 1.8 Hadoop: 2.8.5 Scala: 2.12.6 Spark: 2.3.3
新建目录
[root@centos02 opt]# mkdir -m 777 bigdata/spark [root@centos02 opt]#
解压 Spark
[root@centos02 opt]# tar -zxvf spark-2.3.3-bin-hadoop2.7.tgz -C /opt/bigdata/spark [root@centos02 opt]#
目录重命名
[root@centos02 opt]# cd /opt/bigdata/spark [root@centos02 spark]# mv spark-2.3.3-bin-hadoop2.7 spark-2.3.3 [root@centos02 opt]#
修改解压的Spark文件夹的权限
[root@centos02 opt]# chown -R 777 /opt/bigdata/spark/spark-2.3.3 [root@centos02 opt]#
添加环境变量
[root@centos02 opt]# vim /etc/profile
#Spark export SPARK_HOME=/opt/bigdata/spark/spark-2.3.3 export PATH=$PATH:$SPARK_HOME/bin
[root@centos02 opt]# source /etc/profile
进入spark/conf修改配置文件
[root@centos02 opt]# cd /opt/bigdata/spark/spark-2.3.3 [root@centos02 spark-2.3.3]# cd ./conf [root@centos02 spark-2.3.3]#
[root@centos02 conf]# ll 总用量 36 -rw-r--r-- 1 777 centos02 996 2月 4 2019 docker.properties.template -rw-r--r-- 1 777 centos02 1105 2月 4 2019 fairscheduler.xml.template -rw-r--r-- 1 777 centos02 2025 2月 4 2019 log4j.properties.template -rw-r--r-- 1 777 centos02 7801 2月 4 2019 metrics.properties.template -rw-r--r-- 1 777 centos02 865 2月 4 2019 slaves.template -rw-r--r-- 1 777 centos02 1292 2月 4 2019 spark-defaults.conf.template -rwxr-xr-x 1 777 centos02 4221 2月 4 2019 spark-env.sh.template [root@centos02 conf]#
[root@centos02 conf]# mv log4j.properties.template log4j.properties [root@centos02 conf]# mv spark-defaults.conf.template spark-defaults.conf [root@centos02 conf]# mv spark-env.sh.template spark-env.sh [root@centos02 conf]#
[root@centos02 conf]# ll 总用量 36 -rw-r--r-- 1 777 centos02 996 2月 4 2019 docker.properties.template -rw-r--r-- 1 777 centos02 1105 2月 4 2019 fairscheduler.xml.template -rw-r--r-- 1 777 centos02 2025 2月 4 2019 log4j.properties -rw-r--r-- 1 777 centos02 7801 2月 4 2019 metrics.properties.template -rw-r--r-- 1 777 centos02 865 2月 4 2019 slaves.template -rw-r--r-- 1 777 centos02 1292 2月 4 2019 spark-defaults.conf -rwxr-xr-x 1 777 centos02 4221 2月 4 2019 spark-env.sh [root@centos02 conf]#
修改Spark运行环境变量
[root@centos02 conf]# vim spark-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8
export SCALA_HOME=/usr/local/scala/scala-2.12.6
export HADOOP_HOME=/opt/bigdata/hadoop/hadoop-2.8.5
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_MASTER_IP=centos02
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_MEMORY=1G
export SPARK_EXECUTOR_MEMORY=1G
export SPARK_DIST_CLASSPATH=$(/opt/bigdata/hadoop/hadoop-2.8.5/bin/hadoop classpath)
先启动 Hadoop
[root@centos02 conf]# cd $HADOOP_HOME/sbin [root@centos02 sbin]# start-all.sh [root@centos02 sbin]#
[root@centos02 sbin]# jps 4289 SecondaryNameNode 4465 ResourceManager 4084 DataNode 4596 NodeManager 3913 NameNode 7533 RunJar 19501 Jps [root@centos02 sbin]#
再启动 Spark
[root@centos02 sbin]# cd $SPARK_HOME/sbin/ [root@centos02 sbin]# ll 总用量 92 -rwxr-xr-x 1 777 centos02 2803 2月 4 2019 slaves.sh -rwxr-xr-x 1 777 centos02 1429 2月 4 2019 spark-config.sh -rwxr-xr-x 1 777 centos02 5689 2月 4 2019 spark-daemon.sh -rwxr-xr-x 1 777 centos02 1262 2月 4 2019 spark-daemons.sh -rwxr-xr-x 1 777 centos02 1190 2月 4 2019 start-all.sh -rwxr-xr-x 1 777 centos02 1274 2月 4 2019 start-history-server.sh -rwxr-xr-x 1 777 centos02 2050 2月 4 2019 start-master.sh -rwxr-xr-x 1 777 centos02 1877 2月 4 2019 start-mesos-dispatcher.sh -rwxr-xr-x 1 777 centos02 1423 2月 4 2019 start-mesos-shuffle-service.sh -rwxr-xr-x 1 777 centos02 1279 2月 4 2019 start-shuffle-service.sh -rwxr-xr-x 1 777 centos02 3151 2月 4 2019 start-slave.sh -rwxr-xr-x 1 777 centos02 1527 2月 4 2019 start-slaves.sh -rwxr-xr-x 1 777 centos02 1857 2月 4 2019 start-thriftserver.sh -rwxr-xr-x 1 777 centos02 1478 2月 4 2019 stop-all.sh -rwxr-xr-x 1 777 centos02 1056 2月 4 2019 stop-history-server.sh -rwxr-xr-x 1 777 centos02 1080 2月 4 2019 stop-master.sh -rwxr-xr-x 1 777 centos02 1227 2月 4 2019 stop-mesos-dispatcher.sh -rwxr-xr-x 1 777 centos02 1084 2月 4 2019 stop-mesos-shuffle-service.sh -rwxr-xr-x 1 777 centos02 1067 2月 4 2019 stop-shuffle-service.sh -rwxr-xr-x 1 777 centos02 1557 2月 4 2019 stop-slave.sh -rwxr-xr-x 1 777 centos02 1064 2月 4 2019 stop-slaves.sh -rwxr-xr-x 1 777 centos02 1066 2月 4 2019 stop-thriftserver.sh
[root@centos02 sbin]# $SPARK_HOME/sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /opt/bigdata/spark/spark-2.3.3/logs/spark-root-org.apache.spark.deploy.master.Master-1-centos02.out failed to launch: nice -n 0 /opt/bigdata/spark/spark-2.3.3/bin/spark-class org.apache.spark.deploy.master.Master --host centos02 --port 7077 --webui-port 8080 Spark Command: /usr/local/java/jdk1.8/bin/java -cp /opt/bigdata/spark/spark-2.3.3/conf/:/opt/bigdata/spark/spark-2.3.3/jars/*:/opt/bigdata/hadoop/hadoop-2.8.5/etc/hadoop/:/opt/bigdata/hadoop/hadoop-2.8.5/share/hadoop/common/lib/*:/opt/bigdata/hadoop/hadoop-2.8.5/share/hadoop/common/*:/opt/bigdata/hadoop/hadoop-2.8.5/share/hadoop/hdfs/:/opt/bigdata/hadoop/hadoop-2.8.5/share/hadoop/hdfs/lib/*:/opt/bigdata/hadoop/hadoop-2.8.5/share/hadoop/hdfs/*:/opt/bigdata/hadoop/hadoop-2.8.5/share/hadoop/yarn/lib/*:/opt/bigdata/hadoop/hadoop-2.8.5/share/hadoop/yarn/*:/opt/bigdata/hadoop/hadoop-2.8.5/share/hadoop/mapreduce/lib/*:/opt/bigdata/hadoop/hadoop-2.8.5/share/hadoop/mapreduce/*:/opt/bigdata/hadoop/hadoop-2.8.5/contrib/capacity-scheduler/*.jar -Xmx1g org.apache.spark.deploy.master.Master --host centos02 --port 7077 --webui-port 8080 ======================================== full log in /opt/bigdata/spark/spark-2.3.3/logs/spark-root-org.apache.spark.deploy.master.Master-1-centos02.out localhost: starting org.apache.spark.deploy.worker.Worker, logging to /opt/bigdata/spark/spark-2.3.3/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-centos02.out [root@centos02 sbin]#
[root@centos02 sbin]# jps 4289 SecondaryNameNode 4465 ResourceManager 4084 DataNode 4596 NodeManager 19799 Jps 3913 NameNode 7533 RunJar 19565 Master 19694 Worker [root@centos02 sbin]#
查看Web界面
http://centos02:8080/
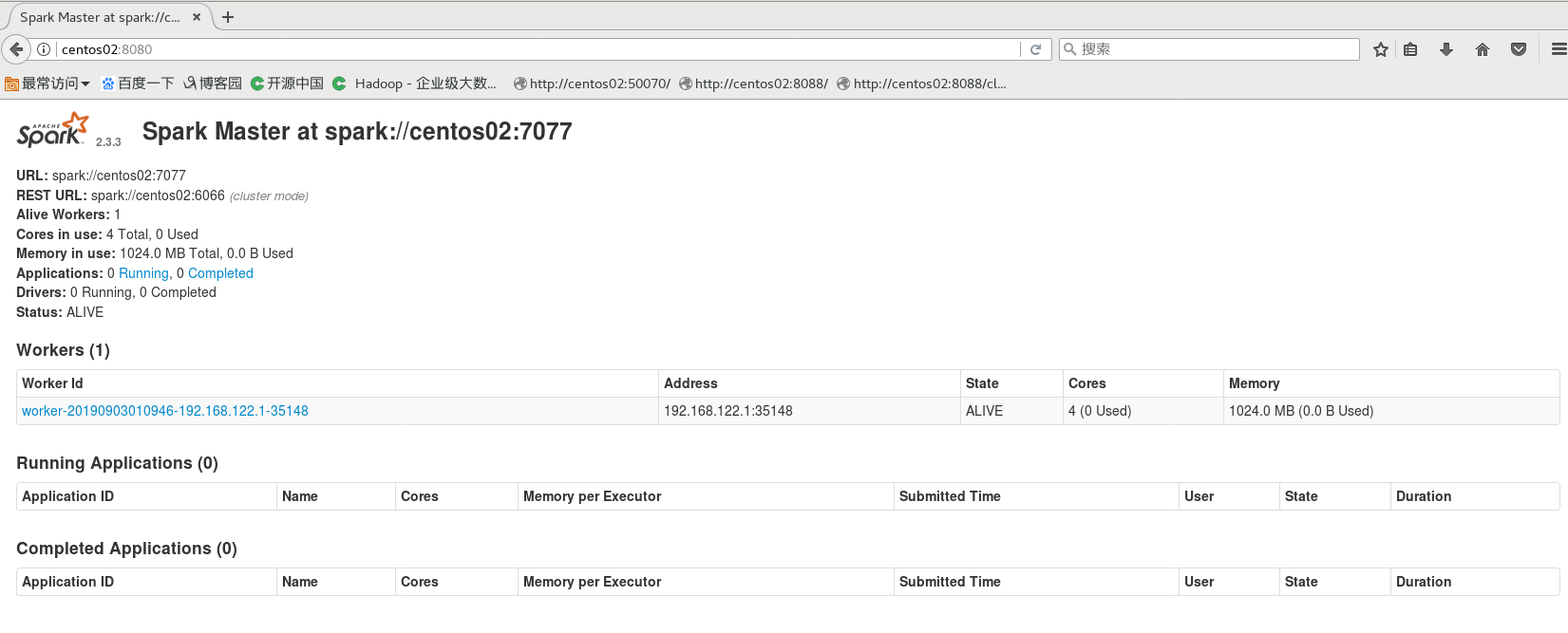
进入交互 /bin/spark-shell
[root@centos02 sbin]# cd $SPARK_HOME/bin [root@centos02 bin]# spark-shell SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/bigdata/spark/spark-2.3.3/jars/slf4j-log4j12-1.7.16.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/bigdata/hadoop/hadoop-2.8.5/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 19/09/03 01:18:15 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Spark context Web UI available at http://centos02:4040 Spark context available as 'sc' (master = local[*], app id = local-1567444848849). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.3.3 /_/ Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_181) Type in expressions to have them evaluated. Type :help for more information. scala>
scala> val array = Array(1, 3, 5, 7, 9, 2, 4, 6, 8, 10); array: Array[Int] = Array(1, 3, 5, 7, 9, 2, 4, 6, 8, 10) scala> val rdd = sc.parallelize(array); rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:26 scala> val data = rdd.filter(x => x > 3); data: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[1] at filter at <console>:25 scala> data.collect().foreach(x => println(x)); 5 7 9 4 6 8 10 scala> println(rdd.partitions.size); 4 scala>
scala> print(sc.getClass.getName); org.apache.spark.SparkContext scala>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号