RCNN系列算法总结
RCNN
物体检测不再是对单一物体进行分类,而是要分类多个物体,另一方面还需要知道这些物体在什么地方,也就是bounding box。这两点使得识别比分类更加困难。
因此采用来扣一块区域出来,放卷积神经网络来看一看是不是我要的物体,如果不是就丢弃,如果是,那就找到这个物体了。如此使用Selective Search生成若干个区域,然后对每一个区域进行一次分类,就可以了。
每一个生成的感兴趣区域的框大小肯定是不一样的,因此卷积神经网络会将这些区域resize成大小相等的框,然后丢进卷积神经网络生成特征
1、分类,最早的RCNN是采用单分类的SVM,比如有十个感兴趣的物体则采用十个SVM分类器
2、定位,Selective Search出来的box不一定就是我所需要的box,可能会存在偏差,因此会采用回归来判断预测框与真实框的loss。

选择性搜索算法使用《Efficient Graph-Based Image Segmentation》论文里的方法产生初始的分割区域作为输入,通过下面的步骤进行合并:
- 首先将所有分割区域的外框加到候选区域列表中
- 基于相似度合并一些区域
- 将合并后的分割区域作为一个整体,跳到步骤1
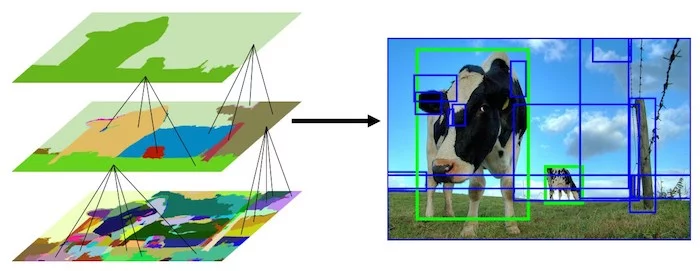
通过不停的迭代,候选区域列表中的区域越来越大。可以说,我们通过自底向下的方法创建了越来越大的候选区域。表示效果如下:
选择性搜索算法如何计算两个区域的像素度的呢?
主要是通过以下四个方面:颜色、纹理、大小和形状交叠
最终的相似度是这四个值取不同的权重相加
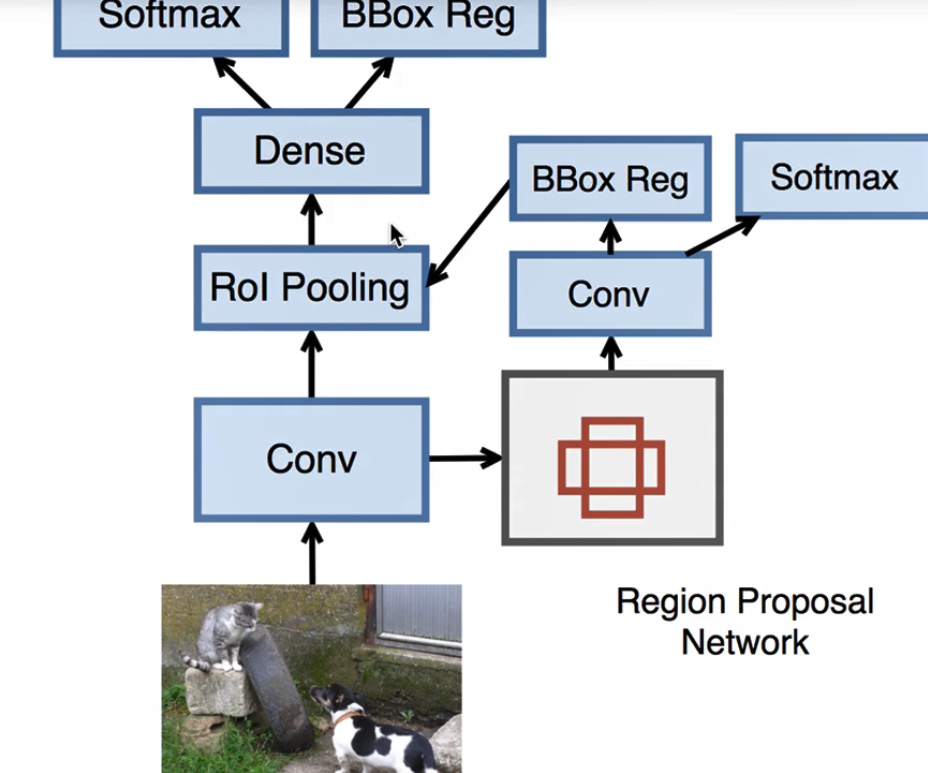
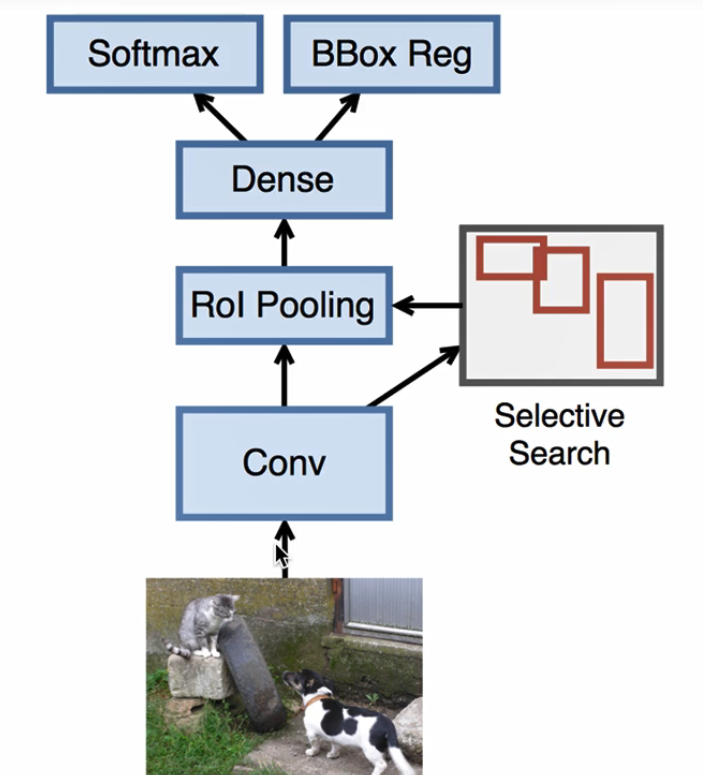
FAST RCNN
由于RCNN一张图片大概会生成两千个候选区域,fast RCNN 想让速度提升,并不是在原始图片上进行感兴趣区域搜索,而是先对图片进行卷积,也就是只对原始图片进行一次卷积。然后在特征图片上进行,Selective Search操作得到感兴趣区域,同时不再对区域进行resize操作(不好求导),而是ROI Pooling。
另一个区别就是用SoftMax代替了SVM.
ROI Pooling
ROI pooling具体操作如下:
根据输入image,将ROI映射到feature map对应位置;
将映射后的区域划分为相同大小的sections(sections数量与输出的维度相同);
对每个sections进行max pooling操作;
这样我们就可以从不同大小的方框得到固定大小的相应 的feature maps。值得一提的是,输出的feature maps的大小不取决于ROI和卷积feature maps大小。ROI pooling 最大的好处就在于极大地提高了处理速度。
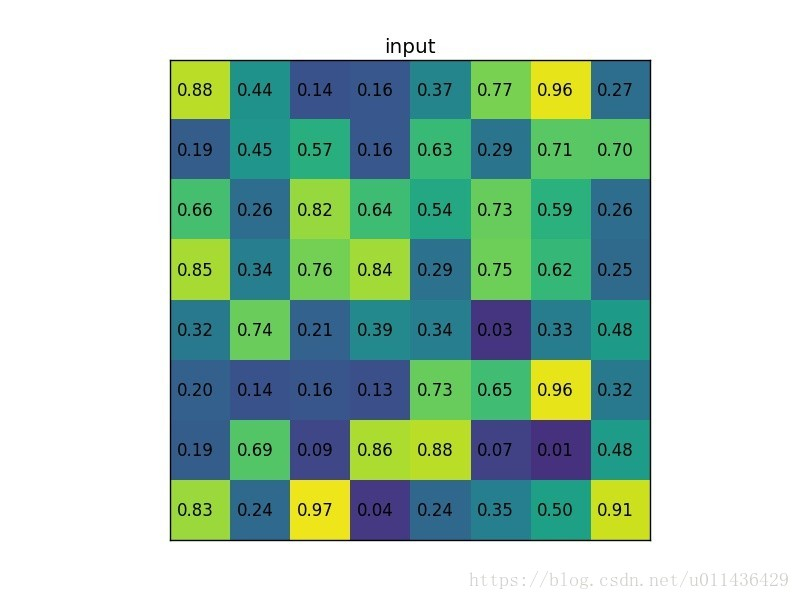
ROI pooling example
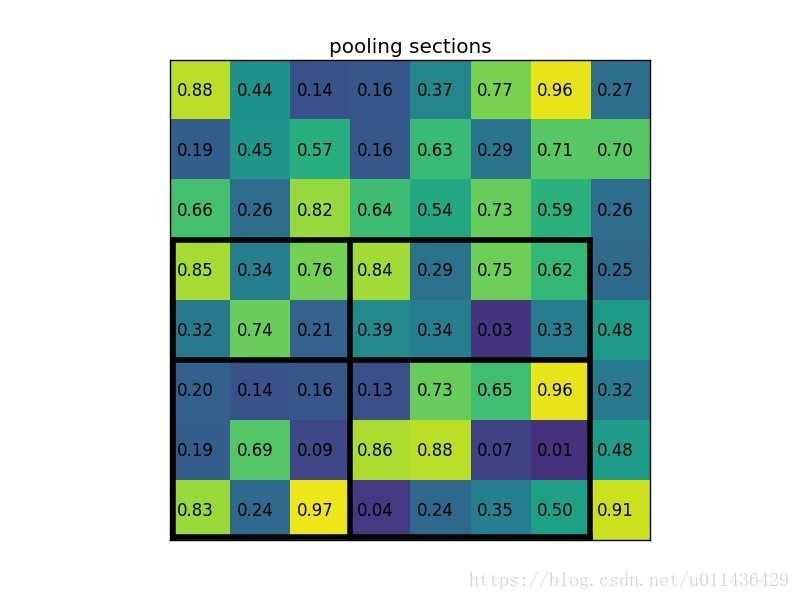
我们有一个8*8大小的feature map,一个ROI,以及输出大小为2*2.
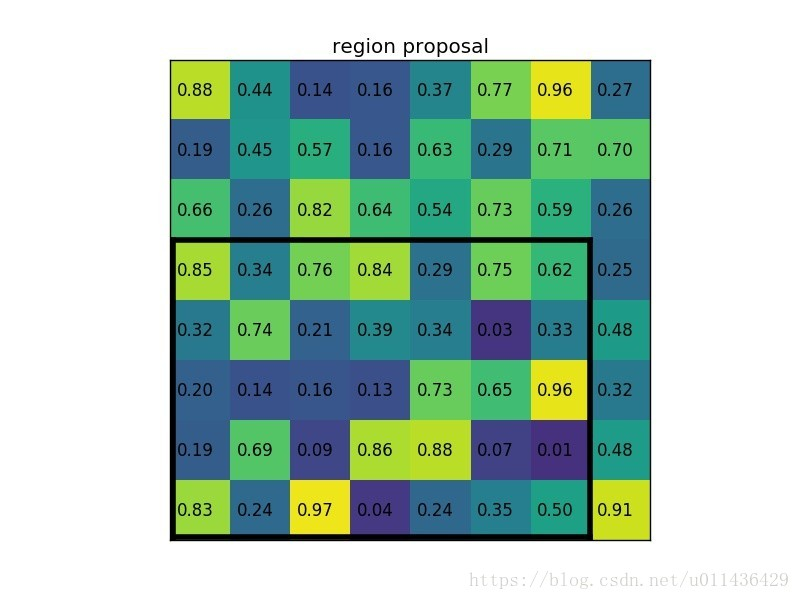
region proposal 投影之后位置(左上角,右下角坐标):(0,3),(7,8)。
将其划分为(2*2)个sections(因为输出大小为2*2),我们可以得到:
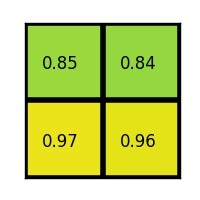
对每个section做max pooling,可以得到:
整体过程如下:

说明:在此案例中region proposals 是5*7大小的,在pooling之后需要得到2*2的,所以在5*7的特征图划分成2*2的时候不是等分的,行是5/2,第一行得到2,剩下的那一行是3,列是7/2,第一列得到3,剩下那一列是4。
Faster RCNN
主要改进就是用RPN代替了Selective Search
对每个像素生成9个锚框,因为这样生成的锚框在大部分情况下只是背景,所以 利用一个二分类的Softmax,判断锚框内是否为感兴趣物体,如果不是则抛弃,如果是则放入ROI Pooling内
后面的Softmax则是判断具体为哪个物体