
引言
记得我们那时候刚开始学习Java的时候都只是一个单体项目,项目里面的配置基本都是写在项目里面的properties文件中,比如数据库配置啥的,各种逻辑开关,一旦这些配置修改了,还需要重启项目这修改才会生效。随着各种微服务的诞生,服务的拆分也越来越细,可能涉及的服务成千上百,服务基本也是集群部署,这样再去一个一个项目修改配置,然后重启这显然是行不通的。所以分布式配置中心就诞生了,现在开源的分布式配置中心也挺多的比如:开源分布式配置中心有很多,比如spring-cloud/spring-cloud-config、淘宝/diamond、百度/disconf、携程/apollo、netflix/archaius、Qconf、XDiamond、nacos等等。我们是不是很好奇配置中心如何做到实时更新并且通知到客户端的这也是一个面试中经常会问到的题目。下面我们就以apollo为例吧去分析分析它是如何实现的。为什么选择Apollo来分析列?因为现在的公司就在使用它作为配置中心。虽然Apollo是携程开源的,但是携程内部也不用它。
Apoll简介
要去了解一个玩意,就要先会去使用它。它的使用基本上很简单。虽然使用简单方便,但是它的设计还是挺复杂的,下面我们看一个它官网提供的架构图,是不是挺复杂的。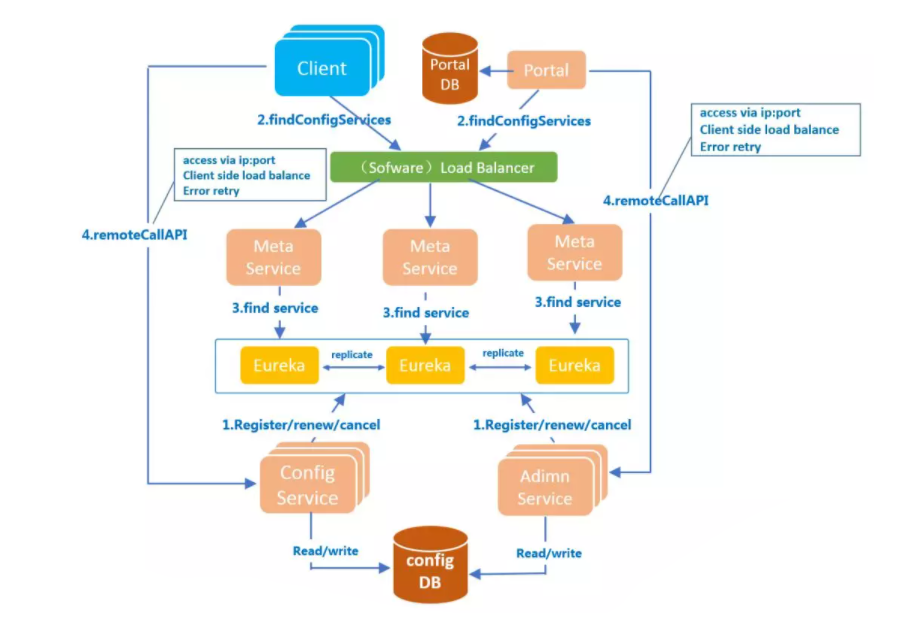
通过上述架构图我们可以看到ConfigService、AdminService、Client、Portal、 Meta Server、Eureka这几个模块,主要的还是前面四个模块Meta Server、Eureka这两个模块只是Apollo本身内部所需要的辅助模块,我们暂时可以不需要关注它。
ConfigService
- 提供配置获取接口
- 提供配置推送接口
- 服务于Apollo客户端
AdminService
- 提供配置管理接口
- 提供配置修改发布接口
- 服务于管理界面Portal
Client
- 为应用获取配置,支持实时更新
- 通过MetaServer获取ConfigService的服务列表\
- 使用客户端软负载SLB方式调用ConfigService
Portal
- 配置管理界面
- 通过MetaServer获取AdminService的服务列表
- 使用客户端软负载SLB方式调用AdminService
Apoll更新配置
介绍完了上面这些Apollo组成的模块回到正题,配置中心如何做到实时更新并且到客户端如何感知配置被更新了?看这个问题之前我们先回顾下每到周末我们去人气比较旺的餐厅吃饭的时候流程是什么样的?
- 首先肯定是现场取号,或者手机端取号。
- 然后就是排队刷手机等着被叫号。中途你还会主动问一问还要等多久,服务员会告诉你等着吧,你前面还有几桌。
上面这个吃饭的例子怎么知道到号了列?两种方式,一种使我们我每隔一段时间然后主动去问下服务员,是否到号,没到号继续刷手机,如果到号直接进去吃饭,还有一种的话就是干脆一直坐在那里刷手机我反正不赶时间,等着被通知到号。同样的配置中心的更新是如何通知到客户端列?是服务端主(configService)动通知到客户端(client)告诉它某某你的应用的配置被修改了,原来的值是啥被修改后的值是啥?还是说客户端(Client)每隔多久去问下服务端我的配置有没有被修改呀?如果是你你会怎么选择列?你也许会说我肯定两种方式都要呀!小朋友才会做选择?
![在这里插入图片描述]()

客户端长链接获取配置更新通知
再回到我们使用apollo的时候我们应用里面引入的Apollo的Client在我们应用启动的时候会有一个线程每隔5s向服务短发起一个http请求,不过这个http请求是不会立即返回的。它是一个长链接如果配置没有被更新,这个请求会被阻塞挂起,这个实现挂起的方式是通过Spring的DeferredResult来实现的,如果对这个Spring的DeferredResult不是很了解的推荐看下这个文章《5种SpringMvc的异步处理方式你都了解吗?》
挂起60s后会返回HTTP状态码为304给到客户端,如果再阻塞的过程中服务端配置有更新,这个Http请求会立马返回,并且把变化的nameSpace信息返回出去,并且返回的http的状态码是200。客户端得到状态码是200并且会根据nameSpace立即去服务端拉取最新的配置。
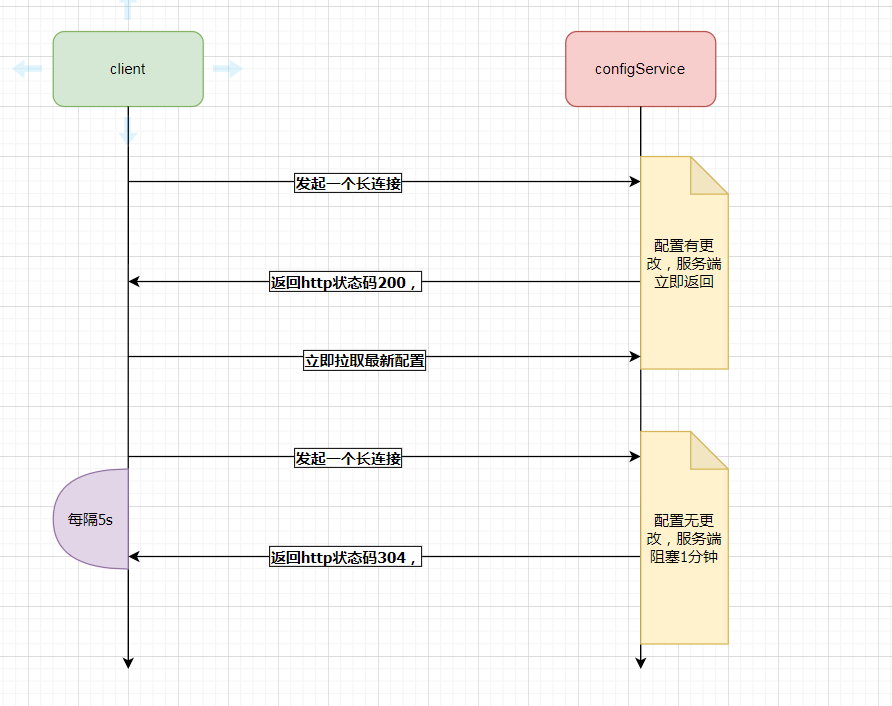
这里其实有一个问题,为什么不直接在长链接中返回变更后的结果,而是返回一个变更的通知,需要客户端根据这个变更通知立即去拉取新的配置?
感兴趣的可以参考下这个issue :https://github.com/apolloconfig/apollo/issues/652
这样推送消息就是有状态了,做不到幂等了,会带来很多问题。目前推送是单连接走http的,所以问题可能不大,不过在设计上而言是有这个问题的,比如如果推送是走的tcp长连接的话。另外,长轮询和推送之间也会有冲突,如果连续两次配置变化,就可能造成双写。还有一点,就是保持逻辑的简单,目前的做法推送只负责做简单的通知,不需要去计算客户端的配置应该是什么,因为计算逻辑挺复杂的,需要考虑集群,关联,灰度等,总而言之,就是在满足幂等性,实时性的基础上保持设计的简单。
客户端定时任务全量拉取配置
这样是不是就是很完美了,客户端可以实时接收到配置的更新。但是客户端如果接收服务端的更新内容处理失败,比如服务异常或者空指针的时候。这时候我们的客户端配置如果不重启是不是永远都不会被更新了。没关系这种情况apollo也帮你想到啦,你既然告诉我更新失败,那我就自己每隔一段时间主动去把我所有的配置都拉到客服端,拉回客服端之后和客户端的缓存配置做比较,如果一致直接结束,不一致就更新客户端的缓存,并且还会去异步更新本地文件。通过定时任务的补充,可以让配置达到最终的一致性。
客户端本地文件缓存配置
主动轮询,和定时任务全量拉取配置是不是就万无一失呢?只要涉及到分布式我们就要考虑到其他系统的宕机,比如哪一天挖机直接把部署Apollo的机房的光纤给挖断了,这样整个配置服务直接挂了,这时候主动轮询以及定时任务都没法起到作用了。是不是拉取不了配置,整个我们的客户端应用也要跟着受影响列,我们的配置基本上是改动的频率也是比较小的,即使我们的配置中心挂掉了,我们还有一份本地文件系统来兜底,这个文件目录默认是/opt/data或C:\opt\data,

所以即使配置中心挂了,对应用的影响也比较小。因为它还会去读取本地文件来兜底。
小结
到现在为止我们应该知道Apollo客户端是如何感知服务端配置更新了的把?
- 主要是通过客户端应用发起一个长连接去
Apollo ConfigServer端,如果Apollo ConfigServer端有配置更改会告诉应用端有配置修改,让客户端立马去拉取全量的配置,并且把配置更新到本地缓存,并且还会异步去更新本地文件缓存。 - 客户端还有一个默认
5min执行一次的定时任务,去拉取全量的配置。拉回配置之后也是对比本地缓存和远程是否一致,如果不一致则更新本地进程缓存为远程的,同时还去异步更新下本地文件。
结束
- 由于自己才疏学浅,难免会有纰漏,假如你发现了错误的地方,还望留言给我指出来,我会对其加以修正。
- 如果你觉得文章还不错,你的转发、分享、赞赏、点赞、留言就是对我最大的鼓励。
- 感谢您的阅读,十分欢迎并感谢您的关注。
- 站在巨人的肩膀
https://www.apolloconfig.com/#/zh/design/apollo-design?id=一、总体设计
https://www.iocoder.cn/Apollo/client-polling-config/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号