I/O 全虚拟化和准虚拟化 [KVM I/O QEMU Full-Virtualizaiton Para-virtualization]
KVM 介绍(3):I/O 全虚拟化和准虚拟化 [KVM I/O QEMU Full-Virtualizaiton Para-virtualization]
学习 KVM 的系列文章:
- (1)介绍和安装
- (2)CPU 和 内存虚拟化
- (3)I/O QEMU 全虚拟化和准虚拟化(Para-virtulizaiton)
- (4)I/O PCI/PCIe设备直接分配和 SR-IOV
- (5)libvirt 介绍
- (6)Nova 通过 libvirt 管理 QEMU/KVM 虚机
- (7)快照 (snapshot)
- (8)迁移 (migration)
1. 全虚拟化 I/O 设备
1.1 原理

- 客户机的设备驱动程序发起 I/O 请求操作请求
- KVM 模块中的 I/O 操作捕获代码拦截这次 I/O 请求
- 经过处理后将本次 I/O 请求的信息放到 I/O 共享页 (sharing page),并通知用户空间的 QEMU 程序。
- QEMU 程序获得 I/O 操作的具体信息之后,交由硬件模拟代码来模拟出本次 I/O 操作。
- 完成之后,QEMU 将结果放回 I/O 共享页,并通知 KMV 模块中的 I/O 操作捕获代码。
- KVM 模块的捕获代码读取 I/O 共享页中的操作结果,并把结果放回客户机。
1.2 QEMU 模拟网卡的实现
Qemu 纯软件的方式来模拟I/O设备,其中包括经常使用的网卡设备。Guest OS启动命令中没有传入的网络配置时,QEMU默认分配 rtl8139 类型的虚拟网卡类型,使用的是默认用户配置模式,这时候由于没有具体的网络模式的配置,Guest的网络功能是有限的。 全虚拟化情况下,KVM虚机可以选择的网络模式包括:
- 默认用户模式(User);
- 基于网桥(Bridge)的模式;
- 基于NAT(Network Address Translation)的模式;
分别使用的 qemu-kvm 参数为:
- -net user[,vlan=n]:使用用户模式网络堆栈,这样就不需要管理员权限来运行.如果没有指 定-net选项,这将是默认的情况.-net tap[,vlan=n][,fd=h]
- -net nic[,vlan=n][,macaddr=addr]:创建一个新的网卡并与VLAN n(在默认的情况下n=0)进行连接。作为可选项的项目,MAC地址可以进行改变.如果 没有指定-net选项,则会创建一个单一的NIC.
- -net tap[,vlan=n][,fd=h][,ifname=name][,script=file]:将TAP网络接口 name 与 VLAN n 进行连接,并使用网络配置脚本文件进行 配置。默认的网络配置脚本为/etc/qemu-ifup。如果没有指定name,OS 将会自动指定一个。fd=h可以用来指定一个已经打开的TAP主机接口的句柄。
网桥模式是目前比较简单,也是用的比较多的模式,下图是网桥模式下的 VM的收发包的流程。
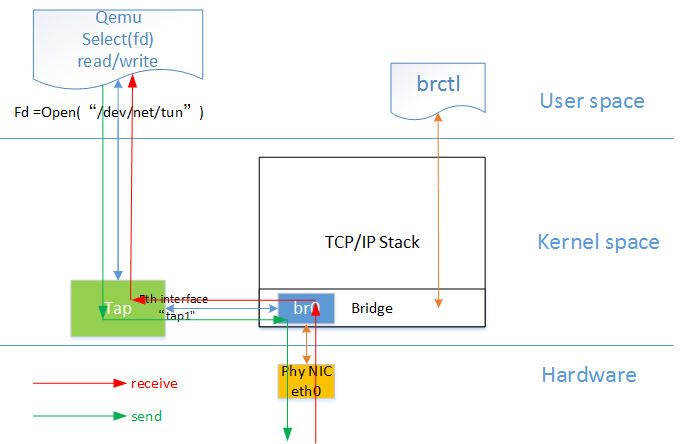
如图中所示,红色箭头表示数据报文的入方向,步骤:
- 网络数据从 Host 上的物理网卡接收,到达网桥;
- 由于 eth0 与 tap1 均加入网桥中,根据二层转发原则,br0 将数据从 tap1 口转发出去,即数据由 Tap设备接收;
- Tap 设备通知对应的 fd 数据可读;
- fd 的读动作通过 tap 设备的字符设备驱动将数据拷贝到用户空间,完成数据报文的前端接收。
1.3 RedHat Linux 6 中提供的模拟设备
- 模拟显卡:提供2块模拟显卡。
- 系统组件:
- ntel i440FX host PCI bridge
- PIIX3 PCI to ISA bridge
- PS/2 mouse and keyboard
- EvTouch USB Graphics Tablet
- PCI UHCI USB controller and a virtualized USB hub
- Emulated serial ports
- EHCI controller, virtualized USB storage and a USB mouse
- 模拟的声卡:intel-hda
- 模拟网卡:e1000,模拟 Intel E1000 网卡;rtl8139,模拟 RealTeck 8139 网卡。
- 模拟存储卡:两块模拟 PCI IDE 接口卡。KVM 限制每个虚拟机最多只能有4块虚拟存储卡。还有模拟软驱。
注意:RedHat Linux KVM 不支持 SCSI 模拟。

1.4 qemu-kvm 关于磁盘设备和网络的主要选项
| 类型 | 选项 |
| 磁盘设备(软盘、硬盘、CDROM等) |
-drive option[,option[,option[,...]]]:定义一个硬盘设备;可用子选项有很多。
file=/path/to/somefile:硬件映像文件路径;
if=interface:指定硬盘设备所连接的接口类型,即控制器类型,如ide、scsi、sd、mtd、floppy、pflash及virtio等;
index=index:设定同一种控制器类型中不同设备的索引号,即标识号;
media=media:定义介质类型为硬盘(disk)还是光盘(cdrom);
format=format:指定映像文件的格式,具体格式可参见qemu-img命令;
-boot [order=drives][,once=drives][,menu=on|off]:定义启动设备的引导次序,每种设备使用一个字符表示;不同的架构所支持的设备及其表示字符不尽相同,在x86 PC架构上,a、b表示软驱、c表示第一块硬盘,d表示第一个光驱设备,n-p表示网络适配器;默认为硬盘设备(-boot order=dc,once=d)
|
| 网络 |
-net nic[,vlan=n][,macaddr=mac][,model=type][,name=name][,addr=addr][,vectors=v]:创建一个新的网卡设备并连接至vlan n中;PC架构上默认的NIC为e1000,macaddr用于为其指定MAC地址,name用于指定一个在监控时显示的网上设备名称;emu可以模拟多个类型的网卡设备;可以使用“qemu-kvm -net nic,model=?”来获取当前平台支持的类型;-net tap[,vlan=n][,name=name][,fd=h][,ifname=name][,script=file][,downscript=dfile]:通过物理机的TAP网络接口连接至vlan n中,使用script=file指定的脚本(默认为/etc/qemu-ifup)来配置当前网络接口,并使用downscript=file指定的脚本(默认为/etc/qemu-ifdown)来撤消接口配置;使用script=no和downscript=no可分别用来禁止执行脚本;-net user[,option][,option][,...]:在用户模式配置网络栈,其不依赖于管理权限;有效选项有: vlan=n:连接至vlan n,默认n=0; name=name:指定接口的显示名称,常用于监控模式中; net=addr[/mask]:设定GuestOS可见的IP网络,掩码可选,默认为10.0.2.0/8; host=addr:指定GuestOS中看到的物理机的IP地址,默认为指定网络中的第二个,即x.x.x.2; dhcpstart=addr:指定DHCP服务地址池中16个地址的起始IP,默认为第16个至第31个,即x.x.x.16-x.x.x.31; dns=addr:指定GuestOS可见的dns服务器地址;默认为GuestOS网络中的第三个地址,即x.x.x.3; tftp=dir:激活内置的tftp服务器,并使用指定的dir作为tftp服务器的默认根目录; bootfile=file:BOOTP文件名称,用于实现网络引导GuestOS;如:qemu -hda linux.img -boot n -net user,tftp=/tftpserver/pub,bootfile=/pxelinux.0 |
对于网卡来说,你可以使用 modle 参数指定虚拟网络的类型。 RedHat Linux 6 所支持的虚拟网络类型有:
[root@rh65 isoimages]# kvm -net nic,model=? qemu: Supported NIC models: ne2k_pci,i82551,i82557b,i82559er,rtl8139,e1000,pcnet,virtio
2. 准虚拟化 (Para-virtualizaiton) I/O 驱动 virtio
2.1 virtio 的架构
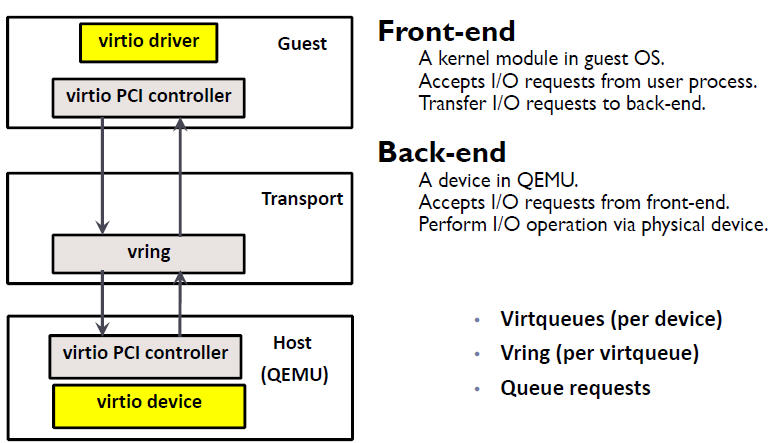
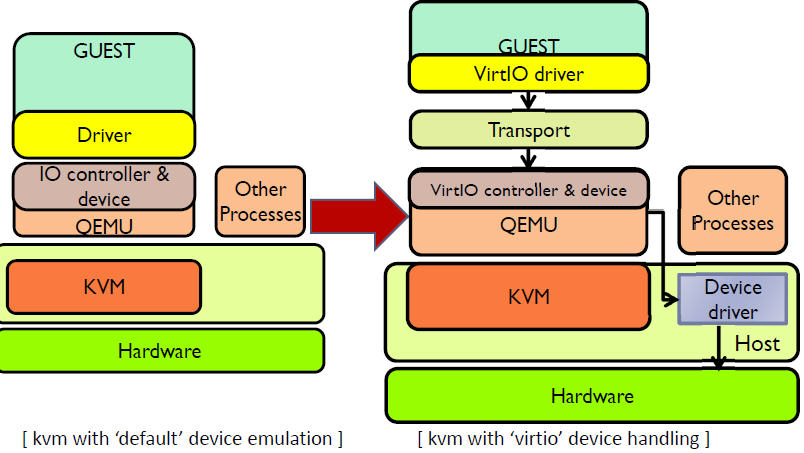

2.2 Virtio 在 Linux 中的实现
- 前端驱动:客户机中安装的驱动程序模块
- 后端驱动:在 QEMU 中实现,调用主机上的物理设备,或者完全由软件实现。
- virtio 层:虚拟队列接口,从概念上连接前端驱动和后端驱动。驱动可以根据需要使用不同数目的队列。比如 virtio-net 使用两个队列,virtio-block只使用一个队列。该队列是虚拟的,实际上是使用 virtio-ring 来实现的。
- virtio-ring:实现虚拟队列的环形缓冲区
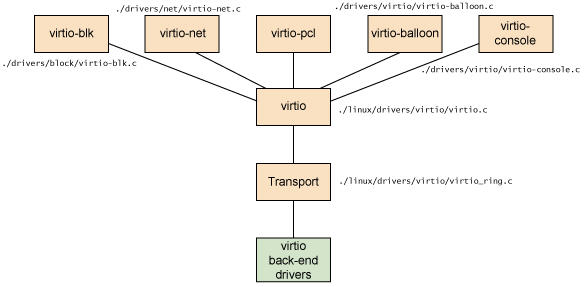
- 块设备(如磁盘)
- 网络设备
- PCI 设备
- 气球驱动程序(动态管理客户机内存使用情况)
- 控制台驱动程序
(1)virtio-net 的原理:
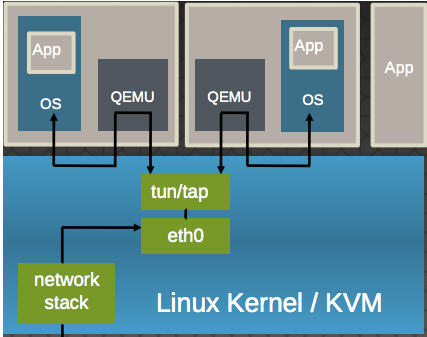
- 多个虚机共享主机网卡 eth0
- QEMU 使用标准的 tun/tap 将虚机的网络桥接到主机网卡上
- 每个虚机看起来有一个直接连接到主机PCI总线上的私有 virtio 网络设备
- 需要在虚机里面安装 virtio驱动
(2)virtio-net 的流程:

- 优点:更高的IO性能,几乎可以和原生系统差不多。
- 缺点:客户机必须安装特定的 virtio 驱动。一些老的 Linux 还没有驱动支持,一些 Windows 需要安装特定的驱动。不过,较新的和主流的OS都有驱动可以下载了。Linux 2.6.24+ 都默认支持 virtio。可以使用 lsmod | grep virtio 查看是否已经加载。
2.3 使用 virtio 设备 (以 virtio-net 为例)
使用 virtio 类型的设备比较简单。较新的 Linux 版本上都已经安装好了 virtio 驱动,而 Windows 的驱动需要自己下载安装。
(1)检查主机上是否支持 virtio 类型的网卡设备
[root@rh65 isoimages]# kvm -net nic,model=? qemu: Supported NIC models: ne2k_pci,i82551,i82557b,i82559er,rtl8139,e1000,pcnet,virtio
(2)指定网卡设备model 为 virtio,启动虚机

(3)通过 vncviewer 登录虚机,能看到被加载了的 virtio-net 需要的内核模块

(4)查看 pci 设备
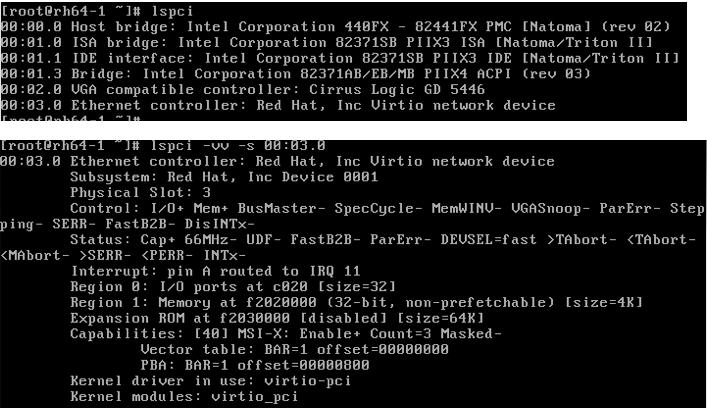
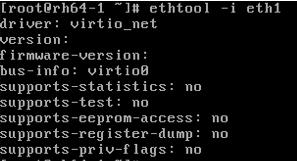
其它 virtio 类型的设备的使用方式类似 virtio-net。
2.4 vhost-net (kernel-level virtio server)
前面提到 virtio 在宿主机中的后端处理程序(backend)一般是由用户空间的QEMU提供的,然而如果对于网络 I/O 请求的后端处理能够在在内核空间来完成,则效率会更高,会提高网络吞吐量和减少网络延迟。在比较新的内核中有一个叫做 “vhost-net” 的驱动模块,它是作为一个内核级别的后端处理程序,将virtio-net的后端处理任务放到内核空间中执行,减少内核空间到用户空间的切换,从而提高效率。
根据 KVM 官网的这篇文章,vhost-net 能提供更低的延迟(latency)(比 e1000 虚拟网卡低 10%),和更高的吞吐量(throughput)(8倍于普通 virtio,大概 7~8 Gigabits/sec )。
vhost-net 与 virtio-net 的比较:
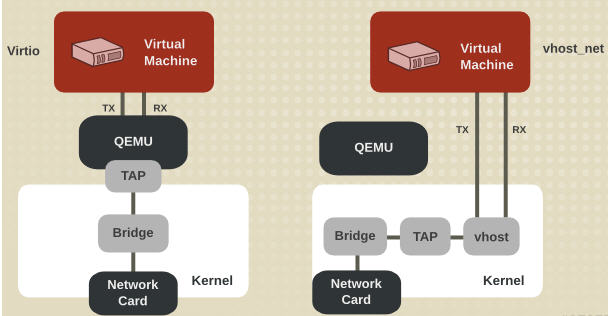
vhost-net 的要求:
- qemu-kvm-0.13.0 或者以上
- 主机内核中设置 CONFIG_VHOST_NET=y 和在虚机操作系统内核中设置 CONFIG_PCI_MSI=y (Red Hat Enterprise Linux 6.1 开始支持该特性)
- 在客户机内使用 virtion-net 前段驱动
- 在主机内使用网桥模式,并且启动 vhost_net
qemu-kvm 命令的 -net tap 有几个选项和 vhost-net 相关的: -net tap,[,vnet_hdr=on|off][,vhost=on|off][,vhostfd=h][,vhostforce=on|off]
- vnet_hdr =on|off:设置是否打开TAP设备的“IFF_VNET_HDR”标识。“vnet_hdr=off”表示关闭这个标识;“vnet_hdr=on”则强制开启这个标识,如果没有这个标识的支持,则会触发错误。IFF_VNET_HDR是tun/tap的一个标识,打开它则允许发送或接受大数据包时仅仅做部分的校验和检查。打开这个标识,可以提高virtio_net驱动的吞吐量。
- vhost=on|off:设置是否开启vhost-net这个内核空间的后端处理驱动,它只对使用MIS-X中断方式的virtio客户机有效。
- vhostforce=on|off:设置是否强制使用 vhost 作为非MSI-X中断方式的Virtio客户机的后端处理程序。
- vhostfs=h:设置为去连接一个已经打开的vhost网络设备。
vhost-net 的使用实例:
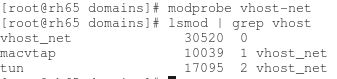
(1)确保主机上 vhost-net 内核模块被加载了
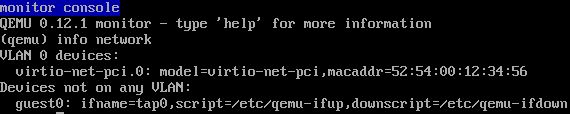
(2)启动一个虚拟机,在客户机中使用 -net 定义一个 virtio-net 网卡,在主机端使用 -netdev 启动 vhost

(3)在虚拟机端,看到 virtio 网卡使用的 TAP 设备为 tap0。
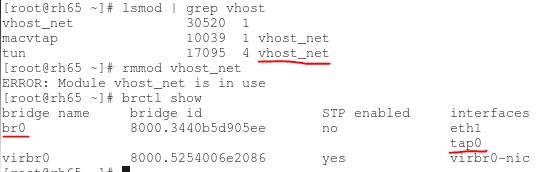
(4)在宿主机中看 vhost-net 被加载和使用了,以及 Linux 桥 br0,它连接物理网卡 eth1 和 客户机使用的 TAP 设备 tap0
一般来说,使用 vhost-net 作为后端处理驱动可以提高网络的性能。不过,对于一些网络负载类型使用 vhost-net 作为后端,却可能使其性能不升反降。特别是从宿主机到其中的客户机之间的UDP流量,如果客户机处理接受数据的速度比宿主机发送的速度要慢,这时就容易出现性能下降。在这种情况下,使用vhost-net将会是UDP socket的接受缓冲区更快地溢出,从而导致更多的数据包丢失。故这种情况下,不使用vhost-net,让传输速度稍微慢一点,反而会提高整体的性能。
使用 qemu-kvm 命令行,加上“vhost=off”(或没有vhost选项)就会不使用vhost-net,而在使用libvirt时,需要对客户机的配置的XML文件中的网络配置部分进行如下的配置,指定后端驱动的名称为“qemu”(而不是“vhost”)。
<interface type=”network”>
…
<model type=”virtio”/>
<driver name=”qemu”/>
…
</interface>
2.6 virtio-balloon
另一个比较特殊的 virtio 设备是 virtio-balloon。通常来说,要改变客户机所占用的宿主机内存,要先关闭客户机,修改启动时的内存配置,然后重启客户机才可以实现。而 内存的 ballooning (气球)技术可以在客户机运行时动态地调整它所占用的宿主机内存资源,而不需要关闭客户机。该技术能够:
- 当宿主机内存紧张时,可以请求客户机回收利用已分配给客户机的部分内存,客户机就会释放部分空闲内存。若其内存空间不足,可能还会回收部分使用中的内存,可能会将部分内存换到交换分区中。
- 当客户机内存不足时,也可以让客户机的内存气球压缩,释放出内存气球中的部分内存,让客户机使用更多的内存。
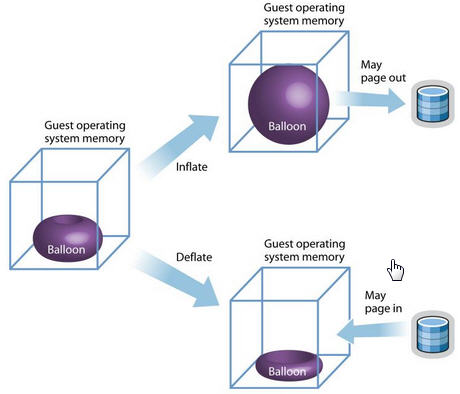
- KVM 发送请求给 VM 让其归还一定数量的内存给KVM。
- VM 的 virtio_balloon 驱动接到该请求。
- VM 的驱动是客户机的内存气球膨胀,气球中的内存就不能被客户机使用。
- VM 的操作系统归还气球中的内存给VMM
- KVM 可以将得到的内存分配到任何需要的地方。
- KM 也可以将内存返还到客户机中。
优势和不足:
| 优势 | 不足 |
|
|
在QEMU monitor中,提供了两个命令查看和设置客户机内存的大小。
- (qemu) info balloon #查看客户机内存占用量(Balloon信息)
- (qemu) balloon num #设置客户机内存占用量为numMB
(1)启动一个虚机,内存为 2048M,启用 virtio-balloon

(2)通过 vncviewer 进入虚机,查看 pci 设备

(3)看看内存情况,共 2G 内存

(4)进入 QEMU Monitor,调整 balloon 内存为 500M

(5)回到虚机,查看内存,变为 500 M

2.7 RedHat 的 多队列 Virtio (multi-queue)
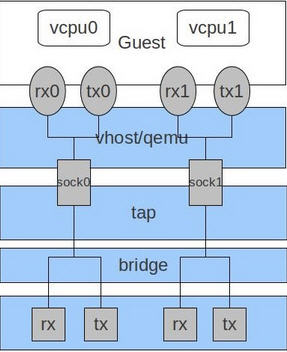
- 网络流量非常大
- 虚机同时有非常多的网络连接,包括虚拟机之间的、虚机到主机的、虚机到外部系统的等
- virtio 队列的数目和虚机的虚拟CPU数目相同。这是因为多队列能够使得一个队列独占一个虚拟CPU。

ethtool -L eth0 combined M ( 1 <= M <= N)
2.8 Windows 客户机的 virtio 前端驱动
- http://linux.web.cern.ch/linux/centos7/docs/rhel/Red_Hat_Enterprise_Linux-7-Virtualization_Tuning_and_Optimization_Guide-en-US.pdf
- http://toast.djw.org.uk/qemu.html
- KVM 官方文档
- KVM 虚拟化技术实战与解析 任永杰、单海涛 著
- RedHat Linux 6 官方文档
- http://www.slideshare.net 中关于 KVM 的一些文档
- http://www.linux-kvm.org/page/Multiqueue
- 以及部分来自于网络,比如 http://smilejay.com/2012/11/use-ballooning-in-kvm/
Refer to : http://www.cnblogs.com/sammyliu
posted on 2017-09-07 16:56 Newbie wang 阅读(630) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号