Java面试总结-基础篇1
-
java多线程-- 自旋锁,偏向锁
好处:可以举Servlet和CGI的对比
用户线程和守护线程的区别:用户线程结束后JVM会退出,然后守护线程才会终止(比如垃圾回收线程),如何在java中创建守护线程
创建方法:推荐Runnable接口;继承Thread;Callable(可返回值,与Future配合使用实现异步) 示例
生命周期:New,Runnable,Running,Waiting,Blocked(join方法),Dead (见下图)
优先级:比较依赖OS的线程调度器,所以最好用自己的代码控制
上下文切换(context-switching):存储和回复CPU状态
确保main线程最后终止:join方法
线程间通信:wait,notify,notifyAll(主要还是线程间锁的控制)
Thread的方法:sleep和yield是静态的,因为只能在正在执行的线程执行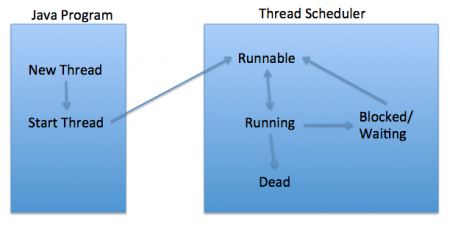
线程安全如何确保线程安全:原子类,并发锁,volatile关键字 参考链接
同步块和同步方法:倾向同步块,锁的更少
ThreadLocal:不想很麻烦的使用同步全局变量机制时,可以使用
死锁:排查方法(blocked的线程锁住的资源id),java thread dump
避免死锁:避免嵌套锁,只在需要的地方使用锁,避免无限期等待
原子操作:多线程下避免数据不一致(AtomicInteger等类),int++不是原子操作
Lock接口
集合类:都是快速失败(ConcurrentModificationException),可使用ConcurrentMap等在多线程使用线程池
好处:避免内存溢出,可以回收利用
创建方法:Executors
阻塞队列:线程安全,可用于生产者-消费者问题 -
spring boot -- aop,ioc原理
IOC:Inversion of Control,或者叫Dependency Injection
Spring的IOC:对象的创建,销毁都是由容器控制
原理:反射
优点:降低耦合,更易维护AOP:Aspect Orientied Programming,基于IOC
特点:与具体业务无关,比如日志记录,权限检查,事务管理等
原理:动态代理,静态植入(编译后植入)
Spring的实现:JDK的动态代理(InvocationHandler和Proxy类),CGLIB代理 -
spring boot -- 关于jpa,假如逻辑与预想完全正确,但是结果不正确,应该怎么调查,处理
配置:spring.jpa.show-sql
-
Mybatis熟悉程度
Mybatis常用知识
-
工作中常用的设计模式
创建型:单例、工厂、抽象工厂、生成器
结构型:适配器、组合器、代理、装饰器
行为:访问者、观察者、策略 -
mysql -- 如何解决千万级别数据,查询很慢
缓存
查询优化(索引,避免全表扫描):注意索引失效的几种情况
数据库集群(master/slave)、库表散列、负载均衡 -
对redis数据库的熟悉程度
描述:Redis是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。
优点:速度快、支持数据类型多、支持事务、过期设置
支持的数据类型:string,hash、list、set、zset
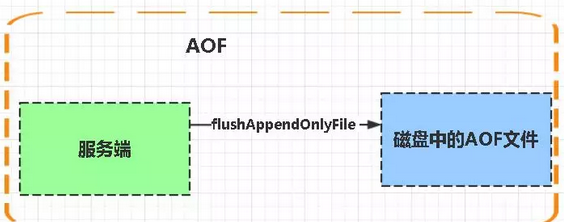
持久化方式:RDB和AOF(见下图)
注意:Master最好不好写快照(会阻塞主线程)和AOF
其他:redis是单进程单线程,用队列控制串行访问常用命令
redis-cli -h host -p port -a password 启动一个客户端(本地则无需参数)
ping:检查redis服务是否启动(回复pong)
quit:关闭连接
select xx:切换到指定数据库
keys pattern(比如keys * 查询所有key)
EXISTS key:key是否存在
EXPIRE key seconds(timestamp):设置key失效时间
PEXPIRE key milliseconds:设置失效毫秒
set
setnx:如果已存在key,则返回0
...缓存穿透和缓存雪崩
缓存穿透 一般的缓存系统,都是按照key去缓存查询,如果不存在对应的value,就应该去后端系统查找(比如DB)。一些恶意的请求会故意查询不存在的key,请求量很大,就会对后端系统造成很大的压力。
这就叫做缓存穿透。 如何避免? 1:对查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该key对应的数据insert了之后清理缓存。 2:对一定不存在的key进行过滤。可以把所有的可能存在的key放到一个大的Bitmap中,查询时通过该bitmap过滤。 缓存雪崩 当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,会给后端系统带来很大压力。导致系统崩溃。 如何避免? 1:在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。 2:做二级缓存,A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期 3:不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。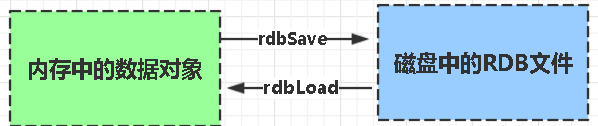
-
RDB和AOF比较 1、aof文件比rdb更新频率高,优先使用aof还原数据。 2、aof比rdb更安全也更大 3、rdb性能比aof好 4、如果两个都配了优先加载AOF
RESP协议
RESP 是redis客户端和服务端之前使用的一种通讯协议; RESP 的特点:实现简单、快速解析、可读性好 For Simple Strings the first byte of the reply is "+" 回复 For Errors the first byte of the reply is "-" 错误 For Integers the first byte of the reply is ":" 整数 For Bulk Strings the first byte of the reply is "$" 字符串 For Arrays the first byte of the reply is "*" 数组
架构类型
1. 单机 2. 主从复制:减轻读的压力,但无法解决高可用
3. 哨兵(sentinel):自动故障转移,保证高可用
4. 集群(twemproxy)
5. 集群(直连型) - 对mongodb数据库的熟悉程度
- linux熟悉程度
- docker -- container原理
参考:
线程:https://www.cnblogs.com/dolphin0520/p/3932934.html
IOC:https://www.cnblogs.com/cyhzzu/p/6644981.html
AOP:https://www.cnblogs.com/lcngu/p/5339555.html
设计模式:https://www.cnblogs.com/jianzhixuan/p/9882756.html
MySQL查询优化:
https://www.cnblogs.com/simadongyang/p/8205607.html
https://www.cnblogs.com/fnlingnzb-learner/p/9939752.html
Redis:
---栖息之鹰(一个外表懒洋洋的内心有激情的程序员)
此博客为笔者原著,转载时请注明出处,谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号