sec 8.3 Optimization and Indexes 优化与索引
The best way to improve the performance of SELECT operations is to create indexes on one or more of the columns that are tested in the query. The index entries act like pointers to the table rows, allowing the query to quickly determine which rows match a condition in the WHERE clause, and retrieve the other column values for those rows. All MySQL data types can be indexed.
改善SELECT操作性能的最佳方法是在查询中测试的一个或多个列上创建索引。索引条目的作用类似于指向表行的指针,从而使查询可以快速确定哪些行与WHERE子句中的条件匹配,并检索这些行的其他列值。所有MySQL数据类型都可以建立索引。
Although it can be tempting to create an indexes for every possible column used in a query, unnecessary indexes waste space and waste time for MySQL to determine which indexes to use. Indexes also add to the cost of inserts, updates, and deletes because each index must be updated. You must find the right balance to achieve fast queries using the optimal set of indexes.
尽管可能会为查询中使用的每个可能的列创建索引,但不必要的索引会浪费空间和时间,使MySQL难以确定要使用的索引。索引还会增加插入,更新和删除的成本,因为每个索引都必须更新。您必须找到适当的平衡,才能使用最佳索引集来实现快速查询。
8.3.1 MySQL如何使用索引
Indexes are used to find rows with specific column values quickly. Without an index, MySQL must begin with the first row and then read through the entire table to find the relevant rows. The larger the table, the more this costs. If the table has an index for the columns in question, MySQL can quickly determine the position to seek to in the middle of the data file without having to look at all the data. This is much faster than reading every row sequentially.
索引用于快速查找具有特定列值的行。没有索引,MySQL必须从第一行开始,然后通读整个表以找到相关的行。桌子越大,花费越多。如果表中有相关列的索引,MySQL可以快速确定要在数据文件中间查找的位置,而不必查看所有数据。这比顺序读取每一行要快得多。
Most MySQL indexes (PRIMARY KEY, UNIQUE, INDEX, and FULLTEXT) are stored in B-trees. Exceptions: Indexes on spatial data types use R-trees; MEMORY tables also support hash indexes; InnoDB uses inverted lists for FULLTEXT indexes.
大多数MySQL索引(PRIMARY KEY,UNIQUE,INDEX和FULLTEXT)存储在B树中。例外:空间数据类型的索引使用R树; MEMORY表还支持哈希索引。 InnoDB对FULLTEXT索引使用反向列表。
In general, indexes are used as described in the following discussion. Characteristics specific to hash indexes (as used in MEMORY tables) are described in Section 8.3.9, “Comparison of B-Tree and Hash Indexes”.
通常,如以下讨论中所述使用索引。第8.3.9节“ B树和哈希索引的比较”中介绍了哈希索引特有的特性(如MEMORY表中所使用的)。
- To find the rows matching a
WHEREclause quickly. - 用于快速找到匹配where子句的行
- To eliminate rows from consideration. If there is a choice between multiple indexes, MySQL normally uses the index that finds the smallest number of rows (the most selective index).
- 减少需要扫描的行。如果可以在多个索引之间进行选择,则MySQL通常会使用查找最少行数的索引(最具选择性的索引)。
- If the table has a multiple-column index, any leftmost prefix of the index can be used by the optimizer to look up rows. For example, if you have a three-column index on
(col1, col2, col3), you have indexed search capabilities on(col1),(col1, col2), and(col1, col2, col3). For more information, see Section 8.3.6, “Multiple-Column Indexes”. - 如果表具有多列索引,那么优化器可以使用索引的任何最左前缀来查找行。例如,如果在(col1,col2,col3)上有一个三列索引,则在(col1),(col1,col2)和(col1,col2,col3)上都有索引搜索功能。有关更多信息,请参见第8.3.6节“多列索引”。
To retrieve rows from other tables when performing joins. MySQL can use indexes on columns more efficiently if they are declared as the same type and size. In this context, VARCHAR and CHAR are considered the same if they are declared as the same size. For example, VARCHAR(10) and CHAR(10) are the same size, but VARCHAR(10) and CHAR(15) are not.
执行联接时从其他表中检索行。如果声明相同的类型和大小,MySQL可以更有效地在列上使用索引。在这种情况下,如果VARCHAR和CHAR声明为相同的大小,则认为它们相同。例如,VARCHAR(10)和CHAR(10)的大小相同,但VARCHAR(10)和CHAR(15)的大小不同。
For comparisons between nonbinary string columns, both columns should use the same character set. For example, comparing a utf8 column with a latin1 column precludes use of an index.
为了在非二进制字符串列之间进行比较,两个列应使用相同的字符集。例如,将utf8列与latin1列进行比较不能使用索引。
Comparison of dissimilar columns (comparing a string column to a temporal or numeric column, for example) may prevent use of indexes if values cannot be compared directly without conversion. For a given value such as 1 in the numeric column, it might compare equal to any number of values in the string column such as '1', ' 1', '00001', or '01.e1'. This rules out use of any indexes for the string column.
如果不能不通过转换直接比较值,则比较不同的列(例如,将字符串列与时间或数字列进行比较)可能会阻止使用索引。对于数字列中的给定值(例如1),它可能等于字符串列中的任意数量的值,例如“ 1”,“ 1”,“ 00001”或“ 01.e1”。这排除了对字符串列使用任何索引的可能性。
- To find the
MIN()orMAX()value for a specific indexed columnkey_col. This is optimized by a preprocessor that checks whether you are usingWHEREon all key parts that occur beforekey_part_N=constantkey_colin the index. In this case, MySQL does a single key lookup for eachMIN()orMAX()expression and replaces it with a constant. If all expressions are replaced with constants, the query returns at once. For example: - 查找特定索引列key_col的MIN()或MAX()值。这由预处理器优化,该预处理器检查是否在索引中出现在key_col之前的所有关键部分上使用WHERE key_part_N = constant。在这种情况下,MySQL对每个MIN()或MAX()表达式执行一次键查找,并将其替换为常量。如果所有表达式都用常量替换,查询将立即返回。例如
![]()

- To sort or group a table if the sorting or grouping is done on a leftmost prefix of a usable index (for example,
ORDER BY). If all key parts are followed bykey_part1,key_part2DESC, the key is read in reverse order. (Or, if the index is a descending index, the key is read in forward order.) See Section 8.2.1.16, “ORDER BY Optimization”, Section 8.2.1.17, “GROUP BY Optimization”, and Section 8.3.13, “Descending Indexes”. - 如果排序或分组是在可用索引的最左前缀(例如,ORDER BY key_part1,key_part2)上完成的,则对表进行排序或分组。如果在所有关键部分后面都按DESC键,则按相反顺序读取key。 (或者,如果索引是降序索引,则按向前顺序读取key。)请参见第8.2.1.16节“按优化排序”,第8.2.1.17节“按优化分组”和第8.3.13节“降序索引”。
- In some cases, a query can be optimized to retrieve values without consulting the data rows. (An index that provides all the necessary results for a query is called a covering index.) If a query uses from a table only columns that are included in some index, the selected values can be retrieved from the index tree for greater speed:
- 在某些情况下,查询可以优化为检索值而无需查询数据行。 (为查询提供所有必要结果的索引称为覆盖索引。)如果查询仅从表中使用某些索引中包含的列,则可以从索引树中检索所选值,以提高速度:

Indexes are less important for queries on small tables, or big tables where report queries process most or all of the rows. When a query needs to access most of the rows, reading sequentially is faster than working through an index. Sequential reads minimize disk seeks, even if not all the rows are needed for the query. See Section 8.2.1.23, “Avoiding Full Table Scans” for details.
对于查询小型表,或者查询大型表需要返回大多数或所有行时,索引的重要性不那么高。当查询需要访问大多数行时,顺序读取要比处理索引快。顺序读取可以最大程度地减少磁盘查找,即使查询不需要返回所有行。有关详细信息,请参见第8.2.1.23节“避免全表扫描”。
8.3.2 Primary Key Optimization主键优化
The primary key for a table represents the column or set of columns that you use in your most vital queries. It has an associated index, for fast query performance. Query performance benefits from the NOT NULL optimization, because it cannot include any NULL values. With the InnoDB storage engine, the table data is physically organized to do ultra-fast lookups and sorts based on the primary key column or columns.
表的主键表示您在最重要的查询中使用的一列或一组列。它具有关联的索引,可提高查询性能。查询性能得益于NOT NULL优化,因为它不能包含任何NULL值。使用InnoDB存储引擎,表数据在物理上进行了组织,以基于一个或多个主键列进行超快速查找和排序。
If your table is big and important, but does not have an obvious column or set of columns to use as a primary key, you might create a separate column with auto-increment values to use as the primary key. These unique IDs can serve as pointers to corresponding rows in other tables when you join tables using foreign keys.
如果您的表又大又重要,但是没有明显的列或一组列用作主键,则可以创建一个单独的列,并使用自动增量值作为主键。当您使用外键联接表时,这些唯一的ID可用作指向其他表中相应行的指针。
8.3.3 SPATIAL Index Optimization 空间索引优化
MySQL permits creation of SPATIAL indexes on NOT NULL geometry-valued columns (see Section 11.4.10, “Creating Spatial Indexes”). The optimizer checks the SRID attribute for indexed columns to determine which spatial reference system (SRS) to use for comparisons, and uses calculations appropriate to the SRS. (Prior to MySQL 8.0, the optimizer performs comparisons of SPATIAL index values using Cartesian calculations; the results of such operations are undefined if the column contains values with non-Cartesian SRIDs.)
SPATIAL index must be SRID-restricted. That is, the column definition must include an explicit SRID attribute, and all column values must have the same SRID. The optimizer considers SPATIAL indexes only for SRID-restricted columns:
- Indexes on columns restricted to a Cartesian SRID enable Cartesian bounding box computations.
- 限于笛卡尔SRID的列上的索引启用笛卡尔边界框计算。
- Indexes on columns restricted to a geographic SRID enable geographic bounding box computations.
- 限于地理SRID的列上的索引可启用地理边界框计算。
The optimizer ignores SPATIAL indexes on columns that have no SRID attribute (and thus are not SRID-restricted). MySQL still maintains such indexes, as follows:
- They are updated for table modifications (
INSERT,UPDATE,DELETE, and so forth). Updates occur as though the index was Cartesian, even though the column might contain a mix of Cartesian and geographical values. - 它们被更新以进行表修改(INSERT,UPDATE,DELETE等)。即使列可能包含笛卡尔和地理值的混合,也会像索引是笛卡尔索引一样进行更新。
- They exist only for backward compatibility (for example, the ability to perform a dump in MySQL 5.7 and restore in MySQL 8.0). Because
SPATIALindexes on columns that are not SRID-restricted are of no use to the optimizer, each such column should be modified: - 它们仅是为了向后兼容而存在(例如,能够在MySQL 5.7中执行转储并在MySQL 8.0中还原)。因为不受SRID限制的列上的SPATIAL索引对优化器没有用,所以应该修改每个这样的列:
- Verify that all values within the column have the same SRID. To determine the SRIDs contained in a geometry column
col_name, use the following query: - 验证列中的所有值都具有相同的SRID。要确定几何列col_name中包含的SRID,请使用以下查询:
- Verify that all values within the column have the same SRID. To determine the SRIDs contained in a geometry column

If the query returns more than one row, the column contains a mix of SRIDs. In that case, modify its contents so all values have the same SRID.
如果查询返回多行,则该列包含SRID的混合。在这种情况下,请修改其内容,以便所有值都具有相同的SRID。
-
- Redefine the column to have an explicit
SRIDattribute. - 重新定义该列以具有显式SRID属性。
- Redefine the column to have an explicit
- Recreate the
SPATIALindex. - 重新创建SPATIAL索引。
8.3.4 Foreign Key Optimization 外键优化
If a table has many columns, and you query many different combinations of columns, it might be efficient to split the less-frequently used data into separate tables with a few columns each, and relate them back to the main table by duplicating the numeric ID column from the main table. That way, each small table can have a primary key for fast lookups of its data, and you can query just the set of columns that you need using a join operation. Depending on how the data is distributed, the queries might perform less I/O and take up less cache memory because the relevant columns are packed together on disk. (To maximize performance, queries try to read as few data blocks as possible from disk; tables with only a few columns can fit more rows in each data block.)
如果一个表有很多列,并且您查询了许多不同的列组合,将不常用的数据拆分为单独的表(每个表包含几列),然后通过复制数字ID将它们关联回主表可能会比较有效。主表中的列。这样,每个小表都可以具有用于快速查找其数据的主键,并且您可以使用联接操作仅查询所需的一组列。根据相关数据的分布方式,查询可能执行较少的I / O并占用较少的缓存,因为相关的列在磁盘上打包在一起。 (为了最大化性能,查询尝试从磁盘上读取尽可能少的数据块;只有几列的表可以在每个数据块中容纳更多的行。)
8.3.5 Column Indexes 列索引
The most common type of index involves a single column, storing copies of the values from that column in a data structure, allowing fast lookups for the rows with the corresponding column values. The B-tree data structure lets the index quickly find a specific value, a set of values, or a range of values, corresponding to operators such as =, >, ≤, BETWEEN, IN, and so on, in a WHERE clause.
索引的最常见类型涉及单个列,该列将来自该列的值的副本存储在一种数据结构中,从而允许快速查找具有相应列值的行。 B树数据结构使索引可以在WHERE子句中快速找到与运算符(例如=,>,≤,BETWEEN,IN等)相对应的特定值,一组值或一系列值。
The maximum number of indexes per table and the maximum index length is defined per storage engine. See Chapter 15, The InnoDB Storage Engine, and Chapter 16, Alternative Storage Engines. All storage engines support at least 16 indexes per table and a total index length of at least 256 bytes. Most storage engines have higher limits.
每个存储引擎定义每个表的最大索引数和最大索引长度。请参阅第15章,InnoDB存储引擎和第16章,备用存储引擎。所有存储引擎每个表至少支持16个索引,并且总索引长度至少为256个字节。大多数存储引擎都有更高的限制。
For additional information about column indexes, see Section 13.1.15, “CREATE INDEX Statement”.
有关列索引的更多信息,请参见第13.1.15节“ CREATE INDEX语句”。
Index Prefixes 索引前缀
With col_name(N)N characters of the column. Indexing only a prefix of column values in this way can make the index file much smaller. When you index a BLOB or TEXT column, you must specify a prefix length for the index. For example:
使用字符串列的索引规范中的col_name(N)语法,可以创建仅使用该列的前N个字符的索引。以这种方式仅索引列值的前缀可以使索引文件小得多。对BLOB或TEXT列建立索引时,必须为索引指定前缀长度。例如:

Prefixes can be up to 767 bytes long for InnoDB tables that use the REDUNDANT or COMPACT row format. The prefix length limit is 3072 bytes for InnoDB tables that use the DYNAMIC or COMPRESSED row format. For MyISAM tables, the prefix length limit is 1000 bytes.
对于使用REDUNDANT或COMPACT行格式的InnoDB表,前缀的最大长度为767个字节。对于使用DYNAMIC或COMPRESSED行格式的InnoDB表,前缀长度限制为3072字节。对于MyISAM表,前缀长度限制为1000个字节。
Note
Prefix limits are measured in bytes, whereas the prefix length in CREATE TABLE, ALTER TABLE, and CREATE INDEX statements is interpreted as number of characters for nonbinary string types (CHAR, VARCHAR, TEXT) and number of bytes for binary string types (BINARY, VARBINARY, BLOB). Take this into account when specifying a prefix length for a nonbinary string column that uses a multibyte character set.
注意
前缀限制以字节为单位,而CREATE TABLE,ALTER TABLE和CREATE INDEX语句中的前缀长度被解释为非二进制字符串类型(CHAR,VARCHAR,TEXT)的字符数和二进制字符串类型(BINARY, VARBINARY,BLOB)。为使用多字节字符集的非二进制字符串列指定前缀长度时,请考虑到这一点。
If a search term exceeds the index prefix length, the index is used to exclude non-matching rows, and the remaining rows are examined for possible matches.
如果搜索词超过索引前缀长度,则使用索引排除不匹配的行,然后检查其余行是否可能匹配。
For additional information about index prefixes, see Section 13.1.15, “CREATE INDEX Statement”.
有关索引前缀的更多信息,请参见第13.1.15节“ CREATE INDEX语句”。
FULLTEXT Indexes 全文索引
FULLTEXT indexes are used for full-text searches. Only the InnoDB and MyISAM storage engines support FULLTEXT indexes and only for CHAR, VARCHAR, and TEXT columns. Indexing always takes place over the entire column and column prefix indexing is not supported. For details, see Section 12.9, “Full-Text Search Functions”.
FULLTEXT索引用于全文搜索。仅InnoDB和MyISAM存储引擎支持FULLTEXT索引,并且仅支持CHAR,VARCHAR和TEXT列。索引始终在整个列上进行,并且不支持列前缀索引。有关详细信息,请参见第12.9节“全文搜索功能”。
Optimizations are applied to certain kinds of FULLTEXT queries against single InnoDB tables. Queries with these characteristics are particularly efficient:
FULLTEXT queries that only return the document ID, or the document ID and the search rank.
仅返回文档ID或文档ID和搜索等级的FULLTEXT查询。
FULLTEXT queries that sort the matching rows in descending order of score and apply a LIMIT clause to take the top N matching rows. For this optimization to apply, there must be no WHERE clauses and only a single ORDER BY clause in descending order.
FULLTEXT查询以分数的降序对匹配的行进行排序,并应用LIMIT子句获取前N个匹配的行。为了应用此优化,必须没有WHERE子句,并且只有一个降序的ORDER BY子句。
FULLTEXT queries that retrieve only the COUNT(*) value of rows matching a search term, with no additional WHERE clauses. Code the WHERE clause as WHERE MATCH(, without any text) AGAINST ('other_text')> 0 comparison operator.
EXPLAIN for full-text queries is typically slower than for non-full-text queries for which no expression evaluation occurs during the optimization phase.EXPLAIN for full-text queries may show Select tables optimized away in the Extra column due to matching occurring during optimization; in this case, no table access need occur during later execution.
全文查询的EXPLAIN可能会由于优化过程中发生匹配而在Extra列中显示已优化的Select表;在这种情况下,以后执行期间无需进行表访问。
Spatial Indexes 空间索引
You can create indexes on spatial data types. MyISAM and InnoDB support R-tree indexes on spatial types. Other storage engines use B-trees for indexing spatial types (except for ARCHIVE, which does not support spatial type indexing).
您可以在空间数据类型上创建索引。 MyISAM和InnoDB支持空间类型上的R树索引。其他存储引擎使用B树来为空间类型建立索引(ARCHIVE除外,ARCHIVE不支持空间类型建立索引)。
Indexes in the MEMORY Storage Engine memory存储引擎的索引
The MEMORY storage engine uses HASH indexes by default, but also supports BTREE indexes.
默认情况下,MEMORY存储引擎使用HASH索引,但也支持BTREE索引。
8.3.6 Multiple-Column Indexes 多列索引
MySQL can create composite indexes (that is, indexes on multiple columns). An index may consist of up to 16 columns. For certain data types, you can index a prefix of the column (see Section 8.3.5, “Column Indexes”).
MySQL可以创建复合索引(即,多列上的索引)。一个索引最多可以包含16列。对于某些数据类型,可以为列的前缀建立索引(请参见第8.3.5节“列索引”)。
MySQL can use multiple-column indexes for queries that test all the columns in the index, or queries that test just the first column, the first two columns, the first three columns, and so on. If you specify the columns in the right order in the index definition, a single composite index can speed up several kinds of queries on the same table.
A multiple-column index can be considered a sorted array, the rows of which contain values that are created by concatenating the values of the indexed columns.
多列索引可以被认为是排序数组,其行包含通过串联索引列的值而创建的值。
Note
As an alternative to a composite index, you can introduce a column that is “hashed” based on information from other columns. If this column is short, reasonably unique, and indexed, it might be faster than a “wide” index on many columns. In MySQL, it is very easy to use this extra column:
注意
作为复合索引的替代方法,您可以引入基于其他列信息“散列”的列。如果此列较短,合理唯一并且已建立索引,则它可能比许多列上的“宽”索引要快。在MySQL中,使用此额外的列非常容易:

Suppose that a table has the following specification:
假设一个表具有以下规范:

The name index is an index over the last_name and first_name columns. The index can be used for lookups in queries that specify values in a known range for combinations of last_name and first_name values. It can also be used for queries that specify just a last_name value because that column is a leftmost prefix of the index (as described later in this section). Therefore, the name index is used for lookups in the following queries:
索引name是在last_name和first_name列上的索引。该索引可用于查询中的查找,这些查询指定了last_name和first_name值组合的已知范围内的值。它也可以用于仅指定last_name值的查询,因为该列是索引的最左前缀(如本节稍后所述)。因此,名称索引用于以下查询中的查找:

However, the name index is not used for lookups in the following queries:
但是,在以下查询中,名称索引不用于查找:

Suppose that you issue the following SELECT statement:
假设您发出以下SELECT语句:

If a multiple-column index exists on col1 and col2, the appropriate rows can be fetched directly. If separate single-column indexes exist on col1 and col2, the optimizer attempts to use the Index Merge optimization (see Section 8.2.1.3, “Index Merge Optimization”), or attempts to find the most restrictive index by deciding which index excludes more rows and using that index to fetch the rows.
如果col1和col2上存在多列索引,则可以直接获取适当的行。如果col1和col2上存在单独的单列索引,则优化器将尝试使用索引合并优化(请参见第8.2.1.3节“索引合并优化”),或通过确定哪个索引排除更多行来尝试查找限制性最大的索引。并使用该索引来获取行。
If the table has a multiple-column index, any leftmost prefix of the index can be used by the optimizer to look up rows. For example, if you have a three-column index on (col1, col2, col3), you have indexed search capabilities on (col1), (col1, col2), and (col1, col2, col3).
如果表具有多列索引,那么优化器可以使用索引的任何最左前缀来查找行。例如,如果在(col1,col2,col3)上有一个三列索引,则在(col1),(col1,col2)和(col1,col2,col3)上都有索引搜索功能。
MySQL cannot use the index to perform lookups if the columns do not form a leftmost prefix of the index. Suppose that you have the SELECT statements shown here:

If an index exists on (col1, col2, col3), only the first two queries use the index. The third and fourth queries do involve indexed columns, but do not use an index to perform lookups because (col2) and (col2, col3) are not leftmost prefixes of (col1, col2, col3).
如果索引存在于(col1,col2,col3)上,则仅前两个查询使用该索引。第三和第四查询确实涉及索引列,但是不使用索引来执行查找,因为(col2)和(col2,col3)并不是(col1,col2,col3)的最左前缀。
8.3.7 Verifying Index Usage 验证索引使用
Always check whether all your queries really use the indexes that you have created in the tables. Use the EXPLAIN statement, as described in Section 8.8.1, “Optimizing Queries with EXPLAIN”.
8.3.8 InnoDB and MyISAM Index Statistics Collection InnoDB和MyISAM索引统计信息收集
Storage engines collect statistics about tables for use by the optimizer. Table statistics are based on value groups, where a value group is a set of rows with the same key prefix value. For optimizer purposes, an important statistic is the average value group size.
存储引擎收集有关表的统计信息,以供优化器使用。表统计信息基于值组,其中值组是一组具有相同键前缀值的行。出于优化目的,重要的统计数据是平均值组的大小。
MySQL uses the average value group size in the following ways:
MySQL通过以下方式使用平均值组大小:
-
To estimate how many rows must be read for each
refaccess -
估计每个引用访问必须读取多少行
- To estimate how many rows a partial join will produce; that is, the number of rows that an operation of this form will produce:
- 估计部分联接将产生多少行;也就是说,这种形式的操作将产生的行数:

As the average value group size for an index increases, the index is less useful for those two purposes because the average number of rows per lookup increases: For the index to be good for optimization purposes, it is best that each index value target a small number of rows in the table. When a given index value yields a large number of rows, the index is less useful and MySQL is less likely to use it.
The average value group size is related to table cardinality, which is the number of value groups. The SHOW INDEX statement displays a cardinality value based on N/S, where N is the number of rows in the table and S is the average value group size. That ratio yields an approximate number of value groups in the table.
平均值组的大小与表基数有关,表基数是值组的数目。 SHOW INDEX语句显示基于N / S的基数值,其中N是表中的行数,S是平均值组大小。该比率在表中产生大约数量的值组。
For a join based on the <=> comparison operator, NULL is not treated differently from any other value: NULL <=> NULL, just as N <=> NN.
However, for a join based on the = operator, NULL is different from non-NULL values: expr1 = expr2expr1 or expr2 (or both) are NULL. This affects ref accesses for comparisons of the form tbl_name.key = exprexpr is NULL, because the comparison cannot be true.
For = comparisons, it does not matter how many NULL values are in the table. For optimization purposes, the relevant value is the average size of the non-NULL value groups. However, MySQL does not currently enable that average size to be collected or used.
对于=比较,表中有多少个NULL值并不重要。为了优化目的,相关值是非NULL值组的平均大小。但是,MySQL当前不支持收集或使用该平均大小。
For InnoDB and MyISAM tables, you have some control over collection of table statistics by means of the innodb_stats_method and myisam_stats_method system variables, respectively. These variables have three possible values, which differ as follows:
- When the variable is set to
nulls_equal, allNULLvalues are treated as identical (that is, they all form a single value group).
- 当变量设置为nulls_equal时,所有NULL值都被视为相同(也就是说,它们全部形成一个值组)。
If the NULL value group size is much higher than the average non-NULL value group size, this method skews the average value group size upward. This makes index appear to the optimizer to be less useful than it really is for joins that look for non-NULL values. Consequently, the nulls_equal method may cause the optimizer not to use the index for ref accesses when it should.
- When the variable is set to
nulls_unequal,NULLvalues are not considered the same. Instead, eachNULLvalue forms a separate value group of size 1 - 当变量设置为nulls_unequal时,NULL值将被视为不相同。而是,每个NULL值形成一个单独的大小为1的值组。
If you have many NULL values, this method skews the average value group size downward. If the average non-NULL value group size is large, counting NULL values each as a group of size 1 causes the optimizer to overestimate the value of the index for joins that look for non-NULL values. Consequently, the nulls_unequal method may cause the optimizer to use this index for ref lookups when other methods may be better.
如果您有许多NULL值,则此方法会使平均值组的大小向下倾斜。如果平均非NULL值组的大小很大,则将每个NULL值作为一组大小1进行计数会导致优化器高估查找非NULL值的联接的索引值。因此,当其他方法可能更好时,nulls_unequal方法可能会导致优化器将此索引用于引用查找。
- When the variable is set to
nulls_ignored,NULLvalues are ignored. - 当变量设置为nulls_ignored时,将忽略NULL值。
If you tend to use many joins that use <=> rather than =, NULL values are not special in comparisons and one NULL is equal to another. In this case, nulls_equal is the appropriate statistics method.
如果您倾向于使用许多使用<=>而不是=的联接,则NULL值在比较中并不特殊,并且一个NULL等于另一个。在这种情况下,nulls_equal是适当的统计方法。
The innodb_stats_method system variable has a global value; the myisam_stats_method system variable has both global and session values. Setting the global value affects statistics collection for tables from the corresponding storage engine. Setting the session value affects statistics collection only for the current client connection. This means that you can force a table's statistics to be regenerated with a given method without affecting other clients by setting the session value of myisam_stats_method.
To regenerate MyISAM table statistics, you can use any of the following methods:
要重新生成MyISAM表统计信息,可以使用以下任何一种方法:
- Execute myisamchk --stats_method=
method_name--analyze - 执行myisamchk --stats_method =method_name --analyze
- Change the table to cause its statistics to go out of date (for example, insert a row and then delete it), and then set
myisam_stats_methodand issue anANALYZE TABLEstatement
- 更改表以使其统计信息过时(例如,插入一行然后将其删除),然后设置myisam_stats_method并发出ANALYZE TABLE语句
Some caveats regarding the use of innodb_stats_method and myisam_stats_method:
-
You can force table statistics to be collected explicitly, as just described. However, MySQL may also collect statistics automatically. For example, if during the course of executing statements for a table, some of those statements modify the table, MySQL may collect statistics. (This may occur for bulk inserts or deletes, or some
ALTER TABLEstatements, for example.) If this happens, the statistics are collected using whatever valueinnodb_stats_methodormyisam_stats_methodhas at the time. Thus, if you collect statistics using one method, but the system variable is set to the other method when a table's statistics are collected automatically later, the other method will be used.
- 如前所述,您可以强制显式收集表统计信息。但是,MySQL可能还会自动收集统计信息。例如,如果在执行表语句的过程中,其中一些语句修改了表,则MySQL可能会收集统计信息。 (例如,这可能发生在批量插入或删除操作或某些ALTER TABLE语句中。)如果发生这种情况,则使用当时innodb_stats_method或myisam_stats_method的任何值来收集统计信息。因此,如果您使用一种方法收集统计信息,但是稍后稍后自动收集表的统计信息时,系统变量设置为另一种方法,则将使用另一种方法。
- There is no way to tell which method was used to generate statistics for a given table.
- 无法确定之前使用哪种方法为给定表生成了统计信息。
- These variables apply only to
InnoDBandMyISAMtables. Other storage engines have only one method for collecting table statistics. Usually it is closer to thenulls_equalmethod.
- 这些变量仅适用于InnoDB和MyISAM表。其他存储引擎只有一种收集表统计信息的方法。通常,它更接近nulls_equal方法。
8.3.9 Comparison of B-Tree and Hash Indexes B-树和哈希索引的比较
Understanding the B-tree and hash data structures can help predict how different queries perform on different storage engines that use these data structures in their indexes, particularly for the MEMORY storage engine that lets you choose B-tree or hash indexes.
B-Tree Index Characteristics B-树索引的特性
A B-tree index can be used for column comparisons in expressions that use the =, >, >=, <, <=, or BETWEEN operators. The index also can be used for LIKE comparisons if the argument to LIKE is a constant string that does not start with a wildcard character. For example, the following SELECT statements use indexes:
B树索引可用于使用=,>,> =,<,<=或BETWEEN运算符的表达式中的列比较。如果LIKE的参数是一个不以通配符开头的常量字符串,则该索引也可以用于LIKE比较。例如,以下SELECT语句使用索引:

In the first statement, only rows with 'Patrick' <= are considered. In the second statement, only rows with key_col < 'Patricl''Pat' <= are considered.key_col < 'Pau'
在第一条语句中,仅考虑'Patrick'<= key_col <'Patricl'的行。在第二条语句中,仅考虑'Pat'<= key_col <'Pau'的行。
The following SELECT statements do not use indexes:
以下SELECT语句不使用索引:

In the first statement, the LIKE value begins with a wildcard character. In the second statement, the LIKE value is not a constant.
在第一条语句中,LIKE值以通配符开头。在第二条语句中,LIKE值不是常数。
If you use ... LIKE '% and string%'string is longer than three characters, MySQL uses the Turbo Boyer-Moore algorithm to initialize the pattern for the string and then uses this pattern to perform the search more quickly.
如果您使用...像'%string%'并且string的长度超过三个字符,则MySQL使用Turbo Boyer-Moore算法初始化字符串的模式,然后使用该模式更快地执行搜索。
A search using col_name IS NULLcol_name is indexed.
如果对col_name进行了索引,则使用col_name IS NULL的搜索将使用索引。
Any index that does not span all AND levels in the WHERE clause is not used to optimize the query. In other words, to be able to use an index, a prefix of the index must be used in every AND group.
没有覆盖WHERE子句中所有AND级别的任何索引都不会用于优化查询。换句话说,为了能够使用索引,必须在每个AND组中使用索引的前缀。
The following WHERE clauses use indexes:
以下WHERE子句使用索引:

These WHERE clauses do not use indexes:
这些WHERE子句不使用索引:

Sometimes MySQL does not use an index, even if one is available. One circumstance under which this occurs is when the optimizer estimates that using the index would require MySQL to access a very large percentage of the rows in the table. (In this case, a table scan is likely to be much faster because it requires fewer seeks.) However, if such a query uses LIMIT to retrieve only some of the rows, MySQL uses an index anyway, because it can much more quickly find the few rows to return in the result.
有时,即使索引可用,MySQL也不使用索引。发生这种情况的一种情况是,优化器估计使用索引将需要MySQL访问表中很大比例的行。 (在这种情况下,表扫描可能会更快,因为它需要更少的查找。)但是,如果这样的查询使用LIMIT只检索某些行,则MySQL仍然使用索引,因为它可以更快地找到返回结果的几行。
Hash Index Characteristics 哈希索引特性
Hash indexes have somewhat different characteristics from those just discussed:
哈希索引与刚刚讨论的索引具有一些不同的特征:
- They are used only for equality comparisons that use the
=or<=>operators (but are very fast). They are not used for comparison operators such as<that find a range of values. Systems that rely on this type of single-value lookup are known as “key-value stores”; to use MySQL for such applications, use hash indexes wherever possible. - 它们仅用于使用=或<=>运算符的相等比较(但非常快)。它们不用于比较运算符(例如<)来查找值的范围。依赖于这种单值查找类型的系统称为“键值存储”。要将MySQL用于此类应用程序,请尽可能使用哈希索引。
- The optimizer cannot use a hash index to speed up
ORDER BYoperations. (This type of index cannot be used to search for the next entry in order.) - 优化器无法使用哈希索引来加快ORDER BY操作。 (此类型的索引不能用于按顺序搜索下一个条目。)
- MySQL cannot determine approximately how many rows there are between two values (this is used by the range optimizer to decide which index to use). This may affect some queries if you change a
MyISAMorInnoDBtable to a hash-indexedMEMORYtable. - MySQL无法确定两个值之间大约有多少行(范围优化器使用它来决定使用哪个索引)。如果将MyISAM或InnoDB表更改为哈希索引的MEMORY表,则这可能会影响某些查询。
- Only whole keys can be used to search for a row. (With a B-tree index, any leftmost prefix of the key can be used to find rows.)
- 仅整个键可用于搜索行。 (对于B树索引,键的任何最左边的前缀都可用于查找行。)
8.3.10 Use of Index Extensions 索引扩展的使用
InnoDB automatically extends each secondary index by appending the primary key columns to it. Consider this table definition:
InnoDB通过将主键列附加到辅助索引来自动扩展每个辅助索引。考虑此表定义:

This table defines the primary key on columns (i1, i2). It also defines a secondary index k_d on column (d), but internally InnoDB extends this index and treats it as columns (d, i1, i2).
该表在列(i1,i2)上定义了主键。它还在列(d)上定义了二级索引k_d,但是InnoDB在内部扩展了该索引并将其视为列(d,i1,i2)。
The optimizer takes into account the primary key columns of the extended secondary index when determining how and whether to use that index. This can result in more efficient query execution plans and better performance.
在确定如何以及是否使用该索引时,优化器会考虑扩展二级索引的主键列。这可以导致更有效的查询执行计划和更好的性能。
The optimizer can use extended secondary indexes for ref, range, and index_merge index access, for Loose Index Scan access, for join and sorting optimization, and for MIN()/MAX() optimization.
The following example shows how execution plans are affected by whether the optimizer uses extended secondary indexes. Suppose that t1 is populated with these rows:
以下示例显示了优化程序是否使用扩展二级索引如何影响执行计划。假设t1填充了以下行:

Now consider this query:
现在考虑以下查询:

The execution plan depends on whether the extended index is used.
执行计划取决于是否使用扩展索引。
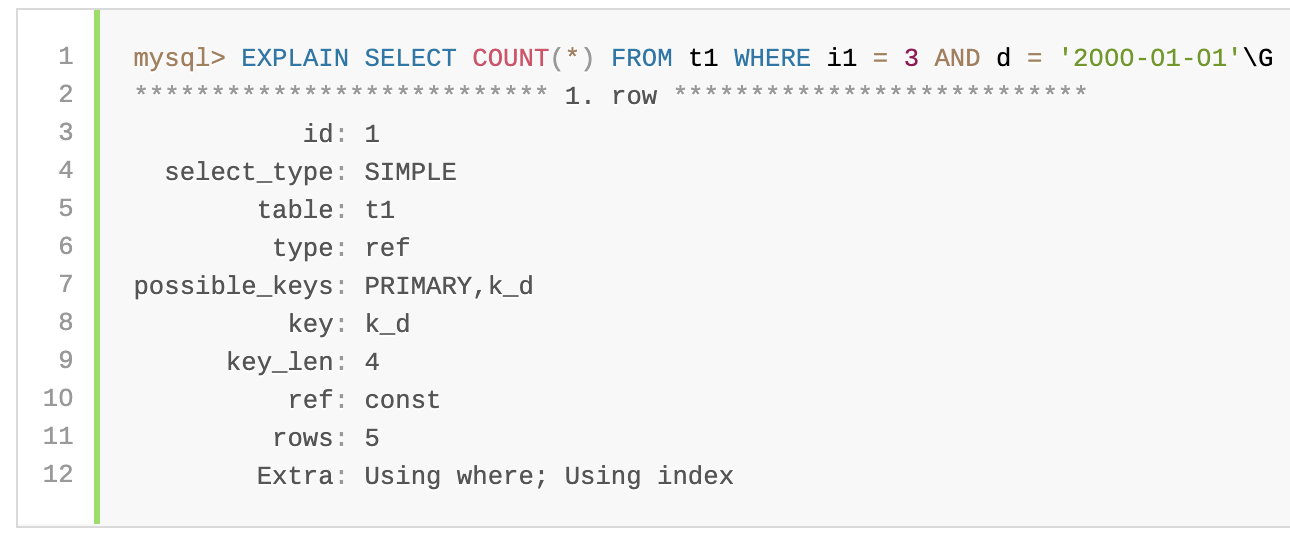
When the optimizer takes index extensions into account, it treats k_d as (d, i1, i2). In this case, it can use the leftmost index prefix (d, i1) to produce a better execution plan:
当优化器考虑索引扩展时,它将k_d视为(d,i1,i2)。在这种情况下,它可以使用最左边的索引前缀(d,i1)来制定更好的执行计划:

In both cases, key indicates that the optimizer will use secondary index k_d but the EXPLAIN output shows these improvements from using the extended index:
key_lengoes from 4 bytes to 8 bytes, indicating that key lookups use columnsdandi1, not justd.- key_len从4字节变为8字节,这表明索引查找使用的是列d和i1,而不仅仅是d。
- The
refvalue changes fromconsttoconst,constbecause the key lookup uses two key parts, not one. - ref值从const变为const,const,因为键查找使用两个键部分,而不是一个。
- The
rowscount decreases from 5 to 1, indicating thatInnoDBshould need to examine fewer rows to produce the result. - 行数从5减少到1,这表明InnoDB应该只需要检查更少的行来产生结果。
- The
Extravalue changes fromUsing where; Using indextoUsing index. This means that rows can be read using only the index, without consulting columns in the data row. - Extra值从Using where;Using index到Using index。这意味着可以仅使用索引来读取行,而无需查阅数据行中的列。
Differences in optimizer behavior for use of extended indexes can also be seen with SHOW STATUS:
还可以通过SHOW STATUS看到使用扩展索引的优化器行为上的差异:

The preceding statements include FLUSH TABLES and FLUSH STATUS to flush the table cache and clear the status counters.
前面的语句包括FLUSH TABLES和FLUSH STATUS,以刷新表缓存并清除状态计数器。
Without index extensions, SHOW STATUS produces this result:
如果没有索引扩展,SHOW STATUS会产生以下结果:

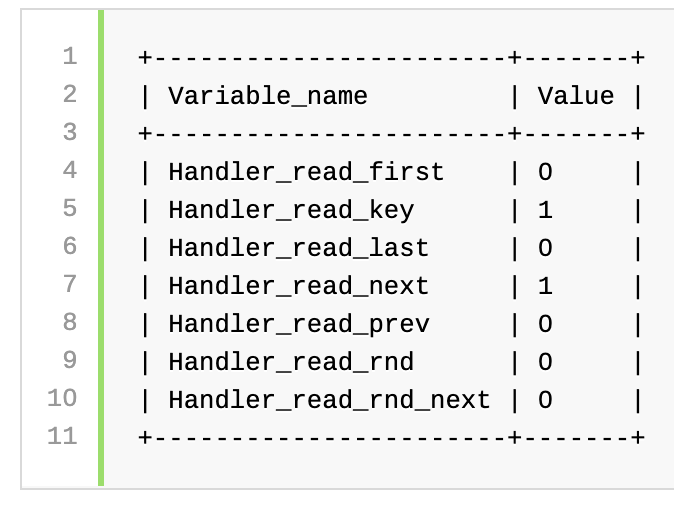
With index extensions, SHOW STATUS produces this result. The Handler_read_next value decreases from 5 to 1, indicating more efficient use of the index:
通过索引扩展,SHOW STATUS产生此结果。 Handler_read_next值从5减少到1,指示索引的使用效率更高:
The use_index_extensions flag of the optimizer_switch system variable permits control over whether the optimizer takes the primary key columns into account when determining how to use an InnoDB table's secondary indexes. By default, use_index_extensions is enabled. To check whether disabling use of index extensions will improve performance, use this statement:
Optimizer_switch系统变量的use_index_extensions标志允许控制在确定如何使用InnoDB表的二级索引时优化器是否考虑了主键列。默认情况下,use_index_extensions处于启用状态。要检查禁用索引扩展的使用是否可以提高性能,请使用以下语句:

Use of index extensions by the optimizer is subject to the usual limits on the number of key parts in an index (16) and the maximum key length (3072 bytes).
优化程序对索引扩展的使用受制于对索引中键部分的数量(16)和最大键长度(3072字节)的通常限制。
8.3.11 Optimizer Use of Generated Column Indexes 优化器对生成的列索引的使用MySQL supports indexes on generated columns. For exampleMySQL支持在生成的列上建立索引。例如![]() The generated column,
The generated column, gc, is defined as the expression f1 + 1. The column is also indexed and the optimizer can take that index into account during execution plan construction. In the following query, the WHERE clause refers to gc and the optimizer considers whether the index on that column yields a more efficient plan:
 The generated column,
The generated column, 生成的列gc定义为表达式f1 +1。该列也已建立索引,优化程序可以在执行计划构建期间考虑该索引。在以下查询中,WHERE子句引用gc,优化器考虑该列上的索引是否产生更有效的计划:

The optimizer can use indexes on generated columns to generate execution plans, even in the absence of direct references in queries to those columns by name. This occurs if the WHERE, ORDER BY, or GROUP BY clause refers to an expression that matches the definition of some indexed generated column. The following query does not refer directly to gc but does use an expression that matches the definition of gc:
即使在按名称查询这些列时没有直接引用的情况下,优化器也可以使用所生成列的索引来生成执行计划。如果WHERE,ORDER BY或GROUP BY子句引用的表达式与某些索引生成的列的定义匹配,则会发生这种情况。以下查询不直接引用gc,而引用与gc定义匹配的表达式:

The optimizer recognizes that the expression f1 + 1 matches the definition of gc and that gc is indexed, so it considers that index during execution plan construction. You can see this using EXPLAIN:
优化器认识到表达式f1 +1与gc的定义匹配,并且gc已建立索引,因此它在执行计划构建期间会考虑该索引。您可以使用EXPLAIN查看此内容:
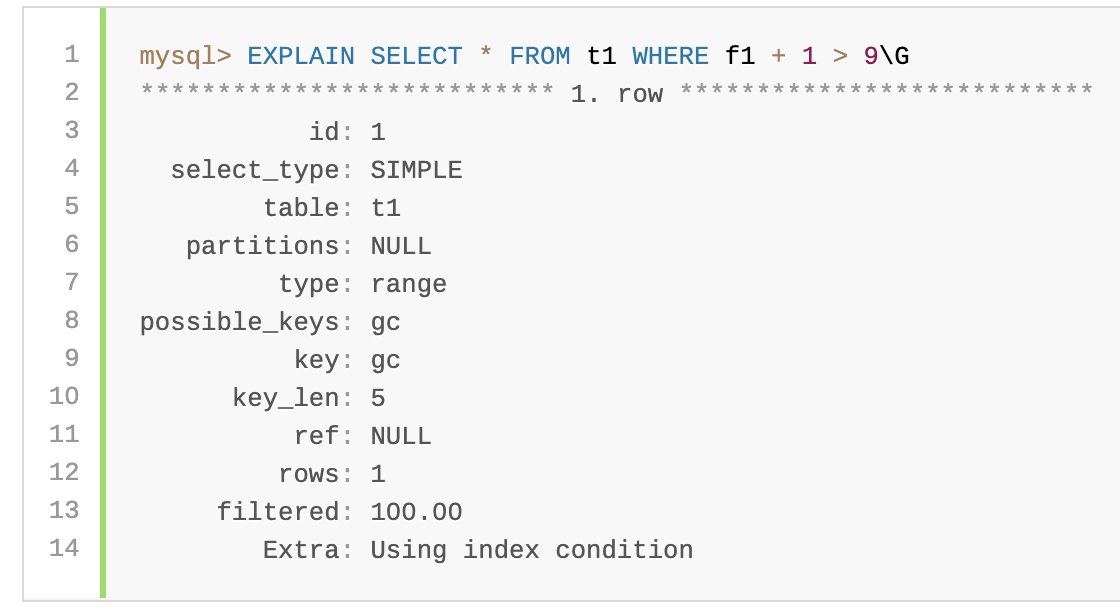
In effect, the optimizer has replaced the expression f1 + 1 with the name of the generated column that matches the expression. That is also apparent in the rewritten query available in the extended EXPLAIN information displayed by SHOW WARNINGS:
实际上,优化器已将表达式f1 +1替换为与表达式匹配的生成列的名称。这在SHOW WARNINGS显示的扩展EXPLAIN信息中可用的重写查询中也很明显:

The following restrictions and conditions apply to the optimizer's use of generated column indexes:
以下限制和条件适用于优化器对生成的列索引的使用:
- For a query expression to match a generated column definition, the expression must be identical and it must have the same result type. For example, if the generated column expression is
f1 + 1, the optimizer will not recognize a match if the query uses1 + f1, or iff1 + 1(an integer expression) is compared with a string. - 为了使查询表达式与生成的列定义匹配,该表达式必须相同并且其结果类型必须相同。例如,如果生成的列表达式为f1 + 1,则在查询使用1 + f1或将f1 + 1(整数表达式)与字符串进行比较的情况下,优化器将无法识别匹配项。
- The optimization applies to these operators:
=,<,<=,>,>=,BETWEEN, andIN(). - 优化适用于以下运算符:=,<,<=,>,> =,BETWEEN和IN()。
BETWEEN and IN(), either operand can be replaced by a matching generated column. For BETWEEN and IN(), only the first argument can be replaced by a matching generated column, and the other arguments must have the same result type. BETWEEN and IN() are not yet supported for comparisons involving JSON values.对于BETWEEN和IN()以外的运算符,可以用匹配的生成列替换任何一个操作数。对于BETWEEN和IN(),只能将第一个参数替换为匹配的生成列,而其他参数必须具有相同的结果类型。涉及JSON值的比较尚不支持BETWEEN和IN()。
- The generated column must be defined as an expression that contains at least a function call or one of the operators mentioned in the preceding item. The expression cannot consist of a simple reference to another column. For example,
gc INT AS (f1) STOREDconsists only of a column reference, so indexes ongcare not considered. - 必须将生成的列定义为至少包含一个函数调用或前一项中提到的运算符之一的表达式。该表达式不能包含对另一列的简单引用。例如,gc INT AS(f1)STORED仅由列引用组成,因此不考虑gc上的索引。
- For comparisons of strings to indexed generated columns that compute a value from a JSON function that returns a quoted string,
JSON_UNQUOTE()is needed in the column definition to remove the extra quotes from the function value. (For direct comparison of a string to the function result, the JSON comparator handles quote removal, but this does not occur for index lookups.) For example, instead of writing a column definition like this:

Write it like this:
像这样写:

With the latter definition, the optimizer can detect a match for both of these comparisons:
使用后一个定义,优化器可以为以下两个比较检测到匹配:

Without JSON_UNQUOTE() in the column definition, the optimizer detects a match only for the first of those comparisons.
在列定义中没有JSON_UNQUOTE()的情况下,优化器仅针对这些比较中的第一个进行检测匹配。
- If the optimizer picks the wrong index, an index hint can be used to disable it and force the optimizer to make a different choice.
- 如果优化器选择了错误的索引,则可以使用索引提示将其禁用,并强制优化器做出其他选择。
8.3.2 Invisible Indexes 不可见索引
MySQL supports invisible indexes; that is, indexes that are not used by the optimizer. The feature applies to indexes other than primary keys (either explicit or implicit).
MySQL支持不可见索引;也就是说,优化器未使用的索引。该功能适用于除主键(显式或隐式)以外的索引。
Indexes are visible by default. To control index visibility explicitly for a new index, use a VISIBLE or INVISIBLE keyword as part of the index definition for CREATE TABLE, CREATE INDEX, or ALTER TABLE:
默认情况下,索引可见。要显式控制新索引的索引可见性,请使用VISIBLE或INVISIBLE关键字作为CREATE TABLE,CREATE INDEX或ALTER TABLE的索引定义的一部分:

To alter the visibility of an existing index, use a VISIBLE or INVISIBLE keyword with the ALTER TABLE ... ALTER INDEX operation:
要更改现有索引的可见性,请在ALTER TABLE ... ALTER INDEX操作中使用VISIBLE或INVISIBLE关键字:

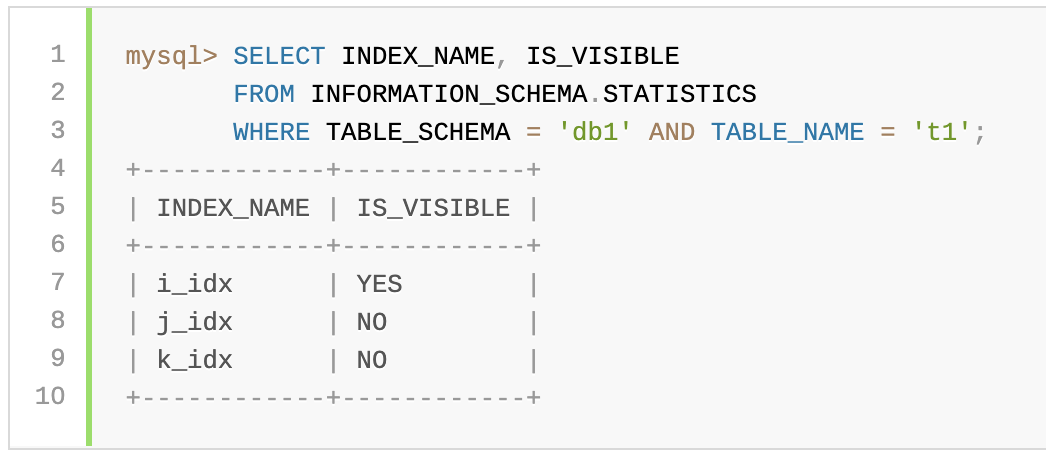
Information about whether an index is visible or invisible is available from the INFORMATION_SCHEMA.STATISTICS table or SHOW INDEX output.
有关索引是可见还是不可见的信息可从INFORMATION_SCHEMA.STATISTICS表或SHOW INDEX输出中获得。
For example:
例如:
Invisible indexes make it possible to test the effect of removing an index on query performance, without making a destructive change that must be undone should the index turn out to be required. Dropping and re-adding an index can be expensive for a large table, whereas making it invisible and visible are fast, in-place operations.
If an index made invisible actually is needed or used by the optimizer, there are several ways to notice the effect of its absence on queries for the table:
- Errors occur for queries that include index hints that refer to the invisible index.
- 对于包含引用不可见索引的索引提示的查询,会发生错误。
- Performance Schema data shows an increase in workload for affected queries.
- 性能架构数据显示了受影响查询的工作量增加。
- Queries have different
EXPLAINexecution plans. -
查询具有不同的EXPLAIN执行计划。
-
Queries appear in the slow query log that did not appear there previously.
-
查询出现在慢查询日志中,以前没有出现在查询日志中。
The use_invisible_indexes flag of the optimizer_switch system variable controls whether the optimizer uses invisible indexes for query execution plan construction. If the flag is off (the default), the optimizer ignores invisible indexes (the same behavior as prior to the introduction of this flag). If the flag is on, invisible indexes remain invisible but the optimizer takes them into account for execution plan construction.
optimizer_switch系统变量的use_invisible_indexes标志控制优化器是否使用不可见索引来构建查询执行计划。如果该标志为off(默认设置),则优化器将忽略不可见索引(与引入该标志之前的行为相同)。如果该标志处于打开状态,则不可见索引将保持不可见,但是优化程序会在执行计划构建时将它们考虑在内。
Index visibility does not affect index maintenance. For example, an index continues to be updated per changes to table rows, and a unique index prevents insertion of duplicates into a column, regardless of whether the index is visible or invisible.
索引可见性不影响索引维护。例如,对于表行的更改,索引将继续更新,并且唯一索引可防止将重复项插入到列中,而不管索引是可见还是不可见。
A table with no explicit primary key may still have an effective implicit primary key if it has any UNIQUE indexes on NOT NULL columns. In this case, the first such index places the same constraint on table rows as an explicit primary key and that index cannot be made invisible. Consider the following table definition:
没有显式主键的表如果在NOT NULL列上具有任何UNIQUE索引,则仍可能具有有效的隐式主键。在这种情况下,第一个这样的索引对表行施加与显式主键相同的约束,并且该索引不能不可见。考虑以下表定义:

The definition includes no explicit primary key, but the index on NOT NULL column j places the same constraint on rows as a primary key and cannot be made invisible:
该定义不包含任何显式主键,但是NOT NULL列j上的索引对行的约束与主键相同,并且不能使其不可见:

Now suppose that an explicit primary key is added to the table:
现在,假设将一个显式主键添加到表中:

The explicit primary key cannot be made invisible. In addition, the unique index on j no longer acts as an implicit primary key and as a result can be made invisible:
显式主键不能不可见。此外,j上的唯一索引不再充当隐式主键,因此可以使其不可见:

8.3.13 Descending Indexes 降序索引
MySQL supports descending indexes: DESC in an index definition is no longer ignored but causes storage of key values in descending order. Previously, indexes could be scanned in reverse order but at a performance penalty. A descending index can be scanned in forward order, which is more efficient. Descending indexes also make it possible for the optimizer to use multiple-column indexes when the most efficient scan order mixes ascending order for some columns and descending order for others.
MySQL支持降序索引:索引定义中的DESC不再被忽略,而是导致键值以降序存储。以前,索引可以以相反的顺序进行扫描,但会降低性能。降序索引可以按向前顺序进行扫描,这样效率更高。当最有效的扫描顺序混合某些列的升序和其他列的降序时,降序索引还使优化程序可以使用多列索引。
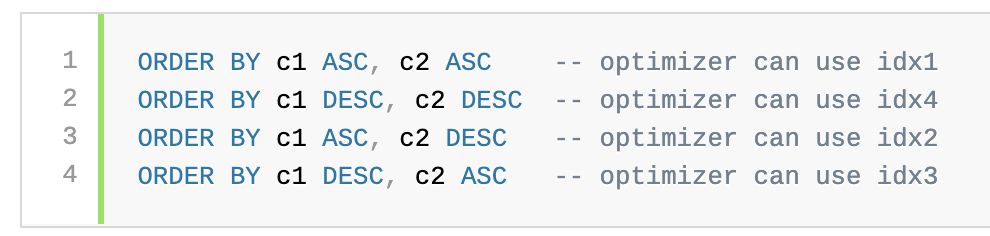
Consider the following table definition, which contains two columns and four two-column index definitions for the various combinations of ascending and descending indexes on the columns:
考虑以下表定义,该表定义包含两列和四个两列索引定义,用于定义列上的升序和降序索引的各种组合:

The table definition results in four distinct indexes. The optimizer can perform a forward index scan for each of the ORDER BY clauses and need not use a filesort operation:
该表定义产生四个不同的索引。优化器可以对每个ORDER BY子句执行前向索引扫描,并且不需要使用文件排序操作:
Use of descending indexes is subject to these conditions:
使用降序索引必须符合以下条件:
- Descending indexes are supported only for the
InnoDBstorage engine, with these limitations:
- Change buffering is not supported for a secondary index if the index contains a descending index key column or if the primary key includes a descending index column.
- The
InnoDBSQL parser does not use descending indexes. ForInnoDBfull-text search, this means that the index required on theFTS_DOC_IDcolumn of the indexed table cannot be defined as a descending index. For more information, see Section 15.6.2.4, “InnoDB FULLTEXT Indexes”.
- 仅InnoDB存储引擎支持降序索引,但有以下限制:
- 如果索引包含降序索引键列或主键包含降序索引列,则辅助索引不支持更改缓冲。
- InnoDB SQL解析器不使用降序索引。对于InnoDB全文搜索,这意味着不能将索引表的FTS_DOC_ID列上所需的索引定义为降序索引。有关更多信息,请参见第15.6.2.4节“ InnoDB FULLTEXT索引”。
- Descending indexes are supported for all data types for which ascending indexes are available.
- 所有可用升序索引的数据类型均支持降序索引。
- Descending indexes are supported for ordinary (nongenerated) and generated columns (both
VIRTUALandSTORED). - 普通(非生成)列和生成的列(VIRTUAL和STORED)都支持降序索引。
DISTINCTcan use any index containing matching columns, including descending key parts.- DISTINCT可以使用任何包含匹配列的索引,包括降序的关键部分。
- Indexes that have descending key parts are not used for
MIN()/MAX()optimization of queries that invoke aggregate functions but do not have aGROUP BYclause. - 具有降序关键部分的索引不会用于调用聚合函数但没有GROUP BY子句的查询的MIN()/ MAX()优化。
- Descending indexes are supported for
BTREEbut notHASHindexes. Descending indexes are not supported forFULLTEXTorSPATIALindexes. - BTREE支持降序索引,但HASH索引不支持。 FULLTEXT或SPATIAL索引不支持降序索引。
Explicitly specified ASC and DESC designators for HASH, FULLTEXT, and SPATIAL indexes results in an error.
明确为HASH,FULLTEXT和SPATIAL索引指定ASC和DESC指示符会导致错误。
8.3.14 Indexed Lookups from TIMESTAMP Columns TIMESTAMP列中的索引查询
Temporal values are stored in TIMESTAMP columns as UTC values, and values inserted into and retrieved from TIMESTAMP columns are converted between the session time zone and UTC. (This is the same type of conversion performed by the CONVERT_TZ() function. If the session time zone is UTC, there is effectively no time zone conversion.)
时间值作为UTC值存储在TIMESTAMP列中,并且在会话时区和UTC之间转换插入到TIMESTAMP列中或从中提取的值。 (这与CONVERT_TZ()函数执行的转换类型相同。如果会话时区为UTC,则实际上没有时区转换。)
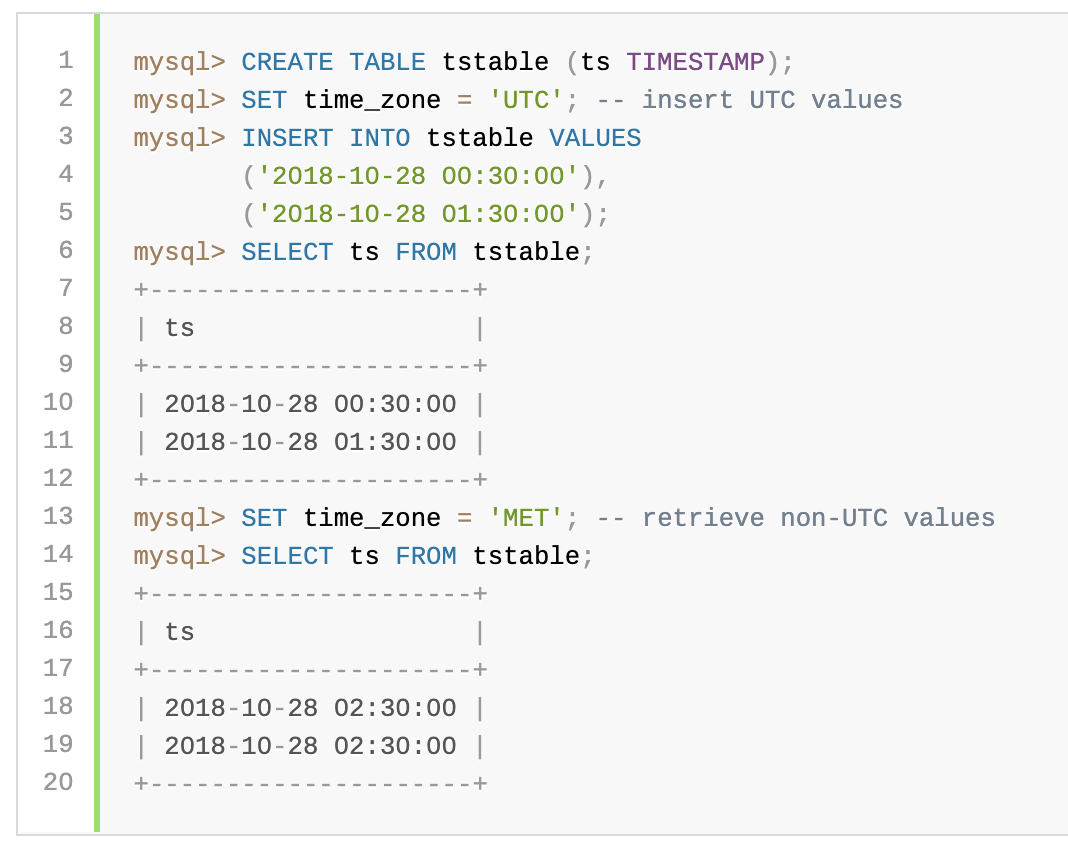
Due to conventions for local time zone changes such as Daylight Saving Time (DST), conversions between UTC and non-UTC time zones are not one-to-one in both directions. UTC values that are distinct may not be distinct in another time zone. The following example shows distinct UTC values that become identical in a non-UTC time zone:
由于诸如夏令时(DST)之类的本地时区更改约定,UTC和非UTC时区之间的转换在两个方向上都不一对一。不同的UTC值在另一个时区可能不会不同。以下示例显示了不同的UTC值,它们在非UTC时区中变得相同:
Note
To use named time zones such as 'MET' or 'Europe/Amsterdam', the time zone tables must be properly set up. For instructions, see Section 5.1.13, “MySQL Server Time Zone Support”.
注意
要使用诸如“ MET”或“ Europe / Amsterdam”之类的命名时区,必须正确设置时区表。有关说明,请参见第5.1.13节“ MySQL服务器时区支持”。
You can see that the two distinct UTC values are the same when converted to the 'MET' time zone. This phenomenon can lead to different results for a given TIMESTAMP column query, depending on whether the optimizer uses an index to execute the query.
您会看到两个不同的UTC值在转换为“ MET”时区时是相同的。对于给定的TIMESTAMP列查询,此现象可能导致不同的结果,具体取决于优化器是否使用索引来执行查询。
Suppose that a query selects values from the table shown earlier using a WHERE clause to search the ts column for a single specific value such as a user-provided timestamp literal:
假设查询使用WHERE子句从前面显示的表中选择值,以在ts列中搜索单个特定值,例如用户提供的时间戳文字:

Suppose further that the query executes under these conditions:
进一步假设查询在以下条件下执行:
- The session time zone is not UTC and has a DST shift. For example:
- 会话时区不是UTC,并且具有DST偏移。例如:

- Unique UTC values stored in the
TIMESTAMPcolumn are not unique in the session time zone due to DST shifts. (The example shown earlier illustrates how this can occur.) -
由于DST偏移,存储在TIMESTAMP列中的唯一UTC值在会话时区中不是唯一的。 (前面显示的示例说明了这种情况的发生。)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号