刷
Reverse
IDA使用指令 链接
内涵 0707
直接拖进IDA看到疑似flag,按A可以转中文
A ASCII解析成ASCII
[BJDCTF 2nd]guessgame
拖进IDA 发现flag
xor
拖进IDA
int __cdecl main(int argc, const char **argv, const char **envp)
{
char *v3; // rsi
int result; // eax
signed int i; // [rsp+2Ch] [rbp-124h]
char v6[264]; // [rsp+40h] [rbp-110h]
__int64 v7; // [rsp+148h] [rbp-8h]
memset(v6, 0, 0x100uLL);
v3 = (char *)256;
printf("Input your flag:\n", 0LL);
get_line(v6, 256LL);
if ( strlen(v6) != 33 ) //如果不等于33则提示failed
goto LABEL_12;
for ( i = 1; i < 33; ++i )//如果等于33
v6[i] = v6[i]^v6[i - 1]; //与前一位异或
v3 = global;
if ( !strncmp(v6, global, 0x21uLL) )
printf("Success", v3);
else
LABEL_12:
printf("Failed", v3);
result = __stack_chk_guard;
if ( __stack_chk_guard == v7 )
result = 0;
return result;
}****
查看Global数据
创建数组:
点击选中你想要转换成数组的一块区域,Edit->Array
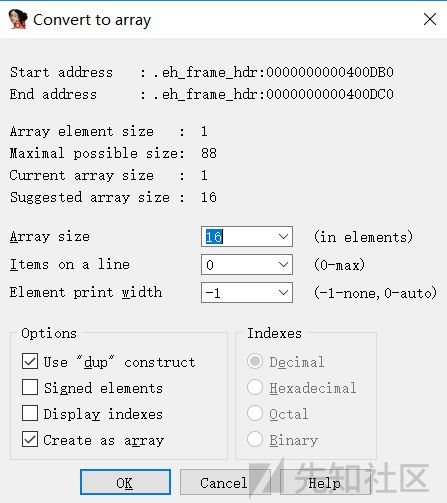
Array element size 这个值表示各数组元素的大小(这里是1个字节),是根据你选中的数据值的大小所决定的
Maximum possible size 这个值是由自动计算得出的,他表示数组中的元素的可能的最大值
Array size 表示数组元素的数量,一般都根据你选定的自动产生默认值
Items on a line 这个表示指定每个反汇编行显示的元素数量,它可以减少显示数组所需的空间
Element print width 这个值用于格式化,当一行显示多个项目时,他控制列宽
Use “dup” construct :使用重复结构,这个选项可以使得相同的数据值合并起来,用一个重复说明符组合成一项
Signed elements 表示将数据显示为有符号数还是无符号数
Display indexes 显示索引,使得数组索引以常规的形式显示,如果选了这个选项,还会启动右边的Indexes选项栏,用于选择索引的显示格式
Create as array 创建为数组,这个一般默认选上的
转为数组 提取得到:
66h, 0Ah, 6Bh, 0Ch, 77h, 26h, 4Fh, 2Eh, 40h, 11h, 78h,0Dh, 5Ah, 3Bh, 55h, 11h, 70h, 19h, 46h, 1Fh, 76h, 22h,4Dh, 23h, 44h, 0Eh, 67h, 6, 68h, 0Fh, 47h, 32h, 4Fh
第一位未被异或 逐位还原即可
hex_xor=[0x66,0x0A,0x6B,0x0C,0x77,0x26,0x4F,0x2E,0x40,0x11,0x78,0x0D,0x5A,0x3B,0x55,0x11,0x70,0x19,0x46,0x1F,0x76,0x22,0x4D,0x23,0x44,0x0E,0x67,0x6,0x68,0x0F,0x47,0x32,0x4F]
orgin=[]
print(len(hex_xor))
i=0
while i<32:
dig=hex_xor[i]^hex_xor[i+1]
orgin.append(dig)
i=i+1
print(orgin)
lag{QianQiuWanDai_YiTongJiangHu}
reverse3
IDA分析
__int64 main_0()
{
int length; // eax
const char *v1; // eax
size_t v2; // eax
int v3; // edx
__int64 v4; // ST08_8
signed int j; // [esp+DCh] [ebp-ACh]
signed int i; // [esp+E8h] [ebp-A0h]
signed int v8; // [esp+E8h] [ebp-A0h]
char Dest[108]; // [esp+F4h] [ebp-94h]
char user_in; // [esp+160h] [ebp-28h]
char v11; // [esp+17Ch] [ebp-Ch]
for ( i = 0; i < 100; ++i )
{
if ( (unsigned int)i >= 100 )
j____report_rangecheckfailure();
Dest[i] = 0;
}
sub_41132F((int)"please enter the flag:");
sub_411375("%20s", (unsigned int)&user_in);
length = j_strlen(&user_in);
v1 = (const char *)sub_4110BE((int)&user_in, length, (int)&v11);
strncpy(Dest, v1, 0x28u);
v8 = j_strlen(Dest);
for ( j = 0; j < v8; ++j )
Dest[j] += j;
v2 = j_strlen(Dest);
if ( !strncmp(Dest, Str2, v2) ) //将Dest和Str2进行比较 str2='e3nifIH9b_C@n@dH'
sub_41132F((int)"rigth flag!\n");
else
sub_41132F((int)"wrong flag!\n");
HIDWORD(v4) = v3;
LODWORD(v4) = 0;
return v4;
}
从下向上分析
Dest从v1来 v1从函数sub_4110BE来
进入sub_4110BE函数发现静态分析比较复杂
其实是base64..

脚本:
def reverse():
final=[101,51,110,105,102,73,72,57,98,95,67,64,110,64,100,72]
orgin=""
i=0
while i<len(final):
res=final[i]-i
orgin=orgin+chr(res)
i=i+1
print(base64.b64decode(orgin))
输出结果b'{i_l0ve_you}'
simpleRev
不一样的flag
不会 看wp说是走迷宫
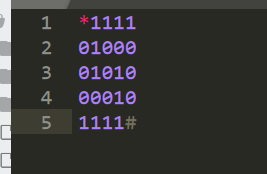
222441144222
走0不走1
开始想上来盲破一波
刮开有奖
太菜了 啥都不会
lea指令
lea是“load effective address”的缩写,简单的说,lea指令可以用来将一个内存地址直接赋给目的操作数,例如:lea eax,[ebx+8]就是将ebx+8这个值直接赋给eax,而不是把ebx+8处的内存地址里的数据赋给eax。而mov指令则恰恰相反,例如:mov eax,[ebx+8]则是把内存地址为ebx+8处的数据赋给eax。
https://blog.csdn.net/xiangshangbashaonian/article/details/89058924?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
问题:
1.反汇编后的4*i为什么变成代码里的i
2.OD修改标志位走向GetDlgItemTextA
在标志位窗口右键至1确实可以跳转 跳转之后没有运行
——————————————————————————
IDA置两次ZF=1确实可以走向GetDlgItemTextA,不过怎么没弹窗让运行???
Check_1n
IDA找到"结束字符串" 之前汇编指令有比较HelloWorld
里面还有一串base64字符 提示打砖块
打砖块就拿到flag
lucky guy
这题也懵
IDA看下伪代码
unsigned __int64 get_flag()
{
unsigned int v0; // eax
char v1; // al
signed int i; // [rsp+4h] [rbp-3Ch]
signed int j; // [rsp+8h] [rbp-38h]
__int64 s; // [rsp+10h] [rbp-30h]
char v6; // [rsp+18h] [rbp-28h]
unsigned __int64 v7; // [rsp+38h] [rbp-8h]
v7 = __readfsqword(0x28u);
v0 = time(0LL);
srand(v0);
for ( i = 0; i <= 4; ++i )
{
switch ( rand() % 200 ) //随机生成的数据对200取余
{
case 1:
puts("OK, it's flag:");
memset(&s, 0, 0x28uLL);
strcat((char *)&s, f1); //GXY{do_not_
strcat((char *)&s, &f2);//第二段
printf("%s", &s);
break;
case 2:
printf("Solar not like you");
break;
case 3:
printf("Solar want a girlfriend");
break;
case 4:
v6 = 0;
s = 9180147350284624745LL;
strcat(&f2, (const char *)&s); // 给f2 7F 66 6F 60 67 75 63 69
break;
case 5: //对f2进行处理
for ( j = 0; j <= 7; ++j )
{
if ( j % 2 == 1 )
v1 = *(&f2 + j) - 2;
else
v1 = *(&f2 + j) - 1;
*(&f2 + j) = v1;
}
break;
default:
puts("emmm,you can't find flag 23333");
break;
}
}
return __readfsqword(0x28u) ^ v7;
}
看了WP推断顺序为4-5-1
尝试处理case5
发现无法得出正确结果,看了下和wp脚本的区别,wp脚本是倒序赋值字符串的
f2=[127,102,111,96,103,117,99,105]
j=0
for i in range(0,8):
if i%2==1:
j=f2[i]-2
else:
j=f2[i]-1
f2[i]=j
小端序标记法
https://blog.csdn.net/a1351937368/article/details/105983106
字节顺序,又被称为端序或者是尾序,在计算机科学领域中,这存储器中或在数字通信链路中,组成多个字节的字的字节的排列顺序。
在几乎所有的机器上,多字节的对象都被存储为连续的字节序列,例如在 C 语言中,一个类型为 int 的变量 x 的地址为 0x100,那么其对应的指针为 &x = 0x100,并且 x 的四个字节将被存储在内存的 0x100,0x101,0x102,0x103的位置。
字节的排列顺序通常有两种方式,例如一个多位的整数,按照春初地址从低到高排序的字节中,如果这个整数的最低有效字节(类似于最低有效位)在最高有效字节的前面,则被称为小端序,反之则称为大端序,在网络应用中,字节序是一个必须被考虑到的因素,因为不同的机器类型可能采取不同的标准的字节序,所以需要按照网络标准进行转化。
如果我们加上上述变量 x 的类型为 int ,位于地址 0x100 处,他的值是 0x1234567,地址范围是 0x100 ~ 0x103 字节,但是其内部排列顺序则依赖于机器的类型,大端法从首位开始将是:0x100 0x101 0x102 0x103,而小端法将是:0x103 0x102 0x101 0x100
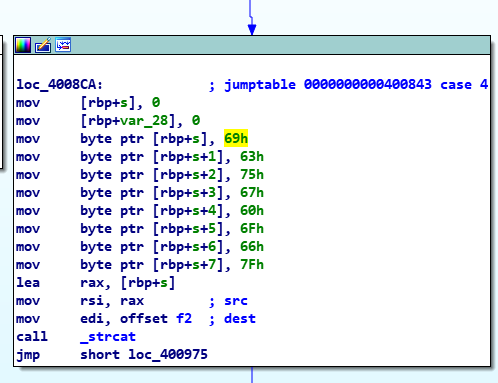
看下汇编代码就比较直观了
CrackRTF
PEID走一套
看到里面有hash和sha
F5看源码
int main_0()
{
DWORD v0; // eax
DWORD v1; // eax
CHAR second_input; // [esp+4Ch] [ebp-310h]
int v4; // [esp+150h] [ebp-20Ch]
CHAR sha1res; // [esp+154h] [ebp-208h]
BYTE getinput; // [esp+258h] [ebp-104h]
memset(&getinput, 0, 260u);
memset(&sha1res, 0, 260u);
v4 = 0;
printf("pls input the first passwd(1): ");
scanf("%s", &getinput);
if ( strlen((const char *)&getinput) != 6 ) // 长度为6
{
printf("Must be 6 characters!\n");
ExitProcess(0);
}
v4 = atoi((const char *)&getinput); // 字符串转整形数
if ( v4 < 100000 )
ExitProcess(0);
strcat((char *)&getinput, "@DBApp");
v0 = strlen((const char *)&getinput);
sub_40100A(&getinput, v0, &sha1res);
if ( !_strcmpi(&sha1res, "6E32D0943418C2C33385BC35A1470250DD8923A9") )// 123321
{
printf("continue...\n\n");
printf("pls input the first passwd(2): ");
memset(&second_input, 0, 0x104u);
scanf("%s", &second_input);
if ( strlen(&second_input) != 6 )
{
printf("Must be 6 characters!\n");
ExitProcess(0);
}
strcat(&second_input, (const char *)&getinput);
memset(&sha1res, 0, 0x104u);
v1 = strlen(&second_input);
sub_401019((BYTE *)&second_input, v1, &sha1res);
if ( !_strcmpi("27019e688a4e62a649fd99cadaafdb4e", &sha1res) )
{
if ( !sub_40100F(&second_input) )
{
printf("Error!!\n");
ExitProcess(0);
}
printf("bye ~~\n");
}
}
return 0;
}
看起来应该是两次调用 第一次是sha1 40位 第二次是hash 32位(peid也可以看出0
第一层写脚本爆破,爆破到第二层发现爆破没用了
import hashlib
def sha1():
for i in range(100000,999999):
data=str(i)+'@DBApp'
right='6E32D0943418C2C33385BC35A1470250DD8923A9'
result=hashlib.sha1(data).hexdigest()
print result+"["+str(i)+"]"
def crackhash():
data='6E32D0943418C2C33385BC35A1470250DD8923A9'
for i in range(33,126):
commbine=''
str1=chr(i)
for j in range(33,126):
str2=chr(j)
for m in range(33,126):
str3=chr(m)
for n in range(33,126):
str4=chr(n)
for o in range(33,126):
str5=chr(o)
for p in range(33,126):
str6=chr(p)
combine=str1+str2+str3+str4+str5+str6
result=combine+data
print result+"|"+hashlib.md5(result).hexdigest()
crackhash()
看wp 下面还有一个函数
char __cdecl sub_4014D0(LPCSTR input)
{
LPCVOID lpBuffer; // [esp+50h] [ebp-1Ch]
DWORD NumberOfBytesWritten; // [esp+58h] [ebp-14h]
DWORD nNumberOfBytesToWrite; // [esp+5Ch] [ebp-10h]
HGLOBAL hResData; // [esp+60h] [ebp-Ch]
HRSRC hResInfo; // [esp+64h] [ebp-8h]
HANDLE hFile; // [esp+68h] [ebp-4h]
hFile = 0;
hResData = 0;
nNumberOfBytesToWrite = 0;
NumberOfBytesWritten = 0;
hResInfo = FindResourceA(0, (LPCSTR)0x65, "AAA");
if ( !hResInfo )
return 0;
nNumberOfBytesToWrite = SizeofResource(0, hResInfo);
hResData = LoadResource(0, hResInfo);
if ( !hResData )
return 0;
lpBuffer = LockResource(hResData);
sub_401005(input, (int)lpBuffer, nNumberOfBytesToWrite);
hFile = CreateFileA("dbapp.rtf", 0x10000000u, 0, 0, 2u, 0x80u, 0);
if ( hFile == (HANDLE)-1 )
return 0;
if ( !WriteFile(hFile, lpBuffer, nNumberOfBytesToWrite, &NumberOfBytesWritten, 0) )
return 0;
CloseHandle(hFile);
return 1;
}
使用工具resourceHacker提取AAA内容
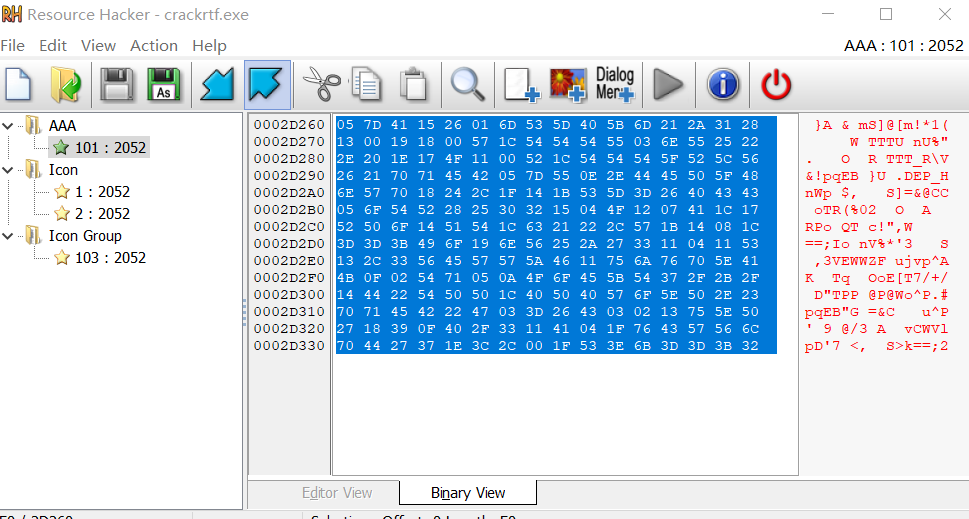
跟进中间函数
unsigned int __cdecl sub_401420(LPCSTR input, int a2, int a3)
{
unsigned int result; // eax
unsigned int i; // [esp+4Ch] [ebp-Ch]
unsigned int v5; // [esp+54h] [ebp-4h]
v5 = lstrlenA(input);
for ( i = 0; ; ++i )
{
result = i;
if ( i >= a3 )
break;
*(_BYTE *)(i + a2) ^= input[i % v5];
}
return result;
}
写入文件的是a2区域 a2=a2^input a2原来的内容来自AAA
RTF文件头格式为 {\rtf1\ansi,将其与AAA前六位异或 得到第二层密码
输入即可得到flag
Young drive
IDA 开启指针
Option->General
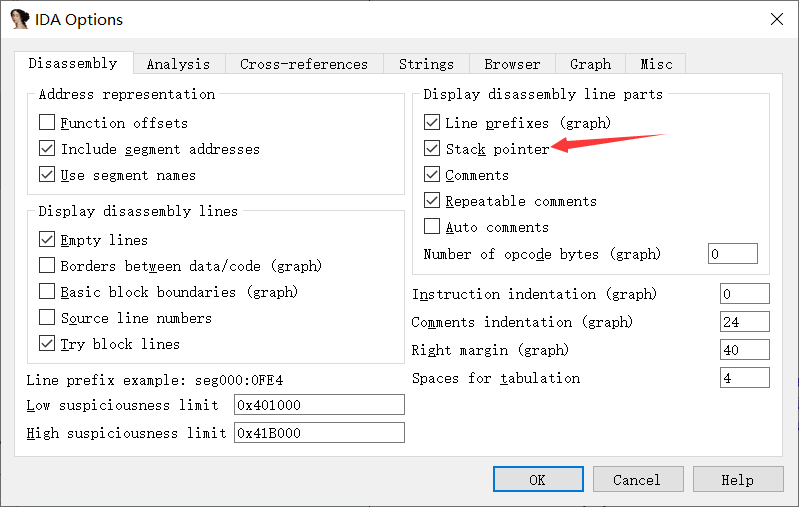
调整sp指针 alt+k
一路跟到这个函数 修改sp的值位0x0
可以f5了
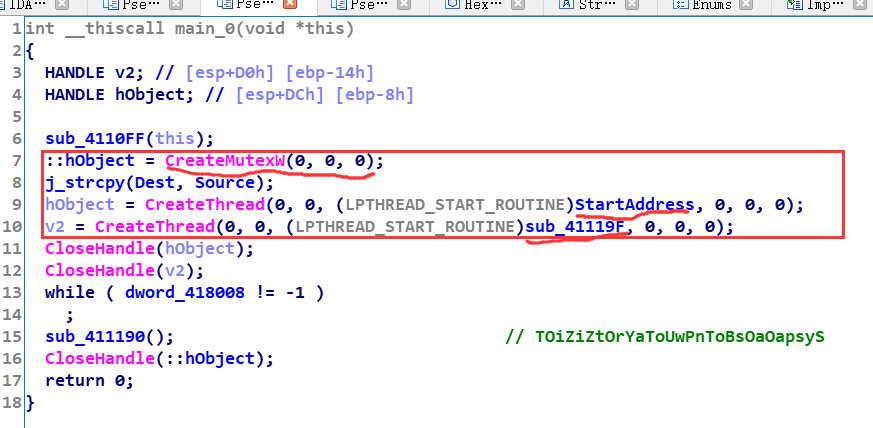
在这里调用createMuteX创建互斥量
分别跟进两个函数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号