爬虫8:Scrapy-取内容
scrapy的实例都分了好几次来写了,因为平时要工作,而且总是遇到这样那样的问题,所以进度一直很慢
写程序有的时候也是玄学,好好的程序总是莫名其妙的就不能运行,然后又莫名其妙的好了,很是奇葩,就像今天的问题
搞了半天搞不好,还像程序员求救,最后什么都没干又自己好了
不过程序员哥哥还是说得对,代码之前能运行那说明代码逻辑没问题,又确定了格式没问题,那剩下的多半是环境的问题了,写代码一定要多注意细节。
因为之前在学selenium的时候,已经学过xpath的提取了,所以这个倒没费多大的功夫,直接上代码了
from scrapy.spiders import Spider from scrapy.selector import Selector from tutorial.items import DmozItem class DmozSpider(Spider): name = "dmoz" allowed_domains = ["dmoz.org"] start_urls=[ "http://www.dmoz.org/Computers/Programming/Languages/Python/Books/", "http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/" ] def parse(self,response): sel = Selector(response) sites = sel.xpath('//div[@class="site-title"]/text()') items=[] for site in sites: item =DmozItem() item['title'] = site.extract() items.append(item) return items
再接下来是存储内容了
信息保存主要有四种:JSON, JSON lines, CSV, XML
我们用json导出
-o后面是文件名,-t后面是导出类型
scrapy crawl dmoz -o axiba.json -t json
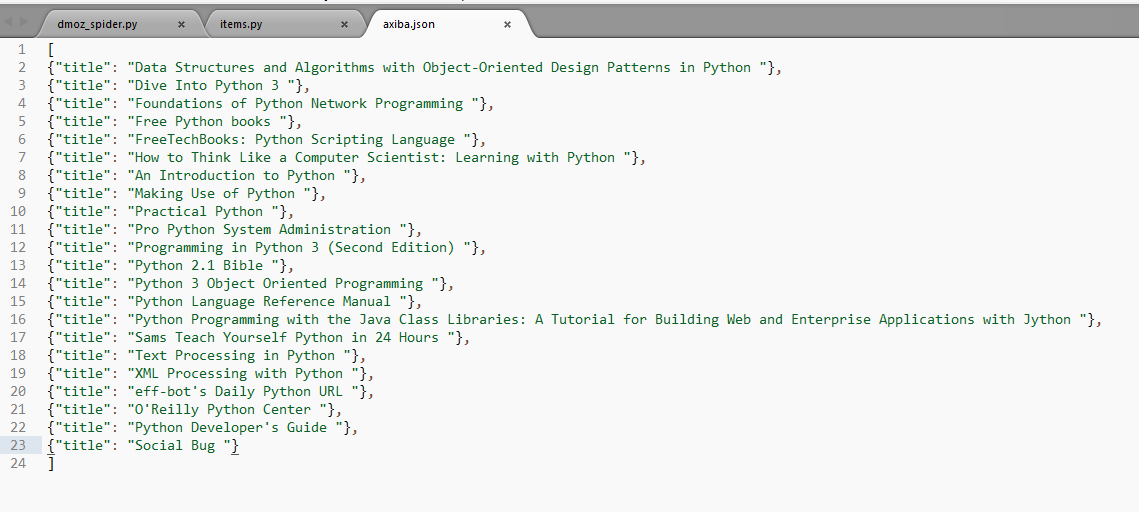
目前为止这个例子就学完了,下一步去研究项目的爬虫了
嘿嘿
我走的很慢,但从不后退

 浙公网安备 33010602011771号
浙公网安备 33010602011771号