CPU Hardwar
2017-08-11 09:28 ☆Ronny丶 阅读(376) 评论(0) 收藏 举报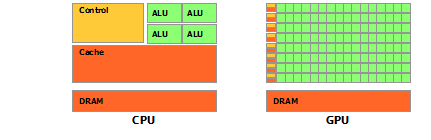
- GPU负责把线程块分配到各个SM上处理。
- CUDA对申请的线程块何时运行,以及在哪个SM上运行是没有保证的。这恰好是GPU的优势,这种方式带来了灵活性,不需程序根据SM的数量去配置程序。
- 但是一个block内的线程执行好像是按顺序启动的,一个block内的所有线程都是在同一个SM上的。
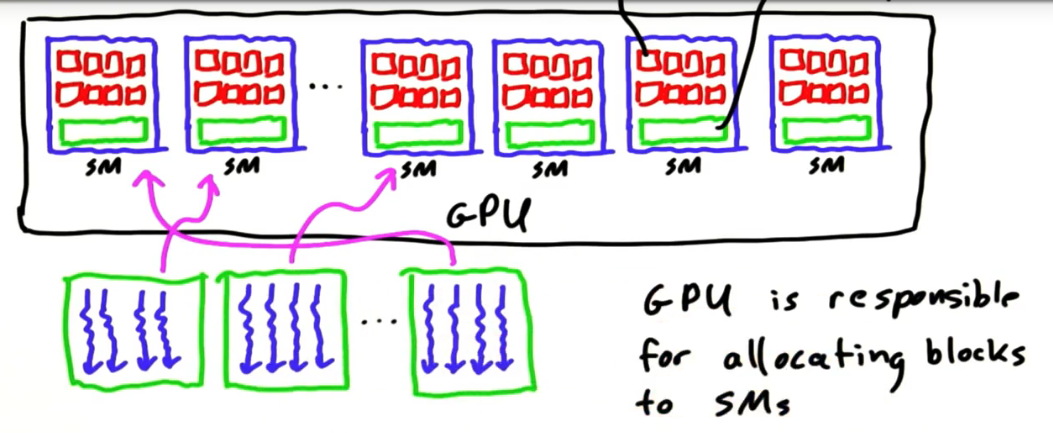
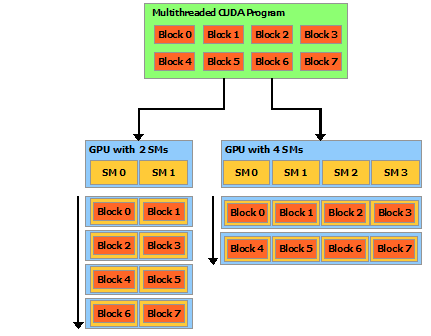
下面程序的打印结果,每次都不一样,说明每个block的执行完全随机的。但是如果把下面的程序NUM_BLOCKS 改为1, 把BLOCK_WIDTH改为16, 程序中打印threadIdx.x,那么每次运行结果都是一致的,都是从0打印到15。
#include <stdio.h>
#define NUM_BLOCKS 16
#define BLOCK_WIDTH 1
__global__ void hello()
{
printf("Hello world! I'm a thread in block %d\n", blockIdx.x);
}
int main(int argc,char **argv)
{
// launch the kernel
hello<<<NUM_BLOCKS, BLOCK_WIDTH>>>();
// force the printf()s to flush
cudaDeviceSynchronize();
printf("That's all!\n");
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号