Airflow概念
DAGS(Directed Acyclic Graphs)[有向无环图]
-
DAG是要运行的任务的一组集合, 反应了这些任务间的关系及依赖。
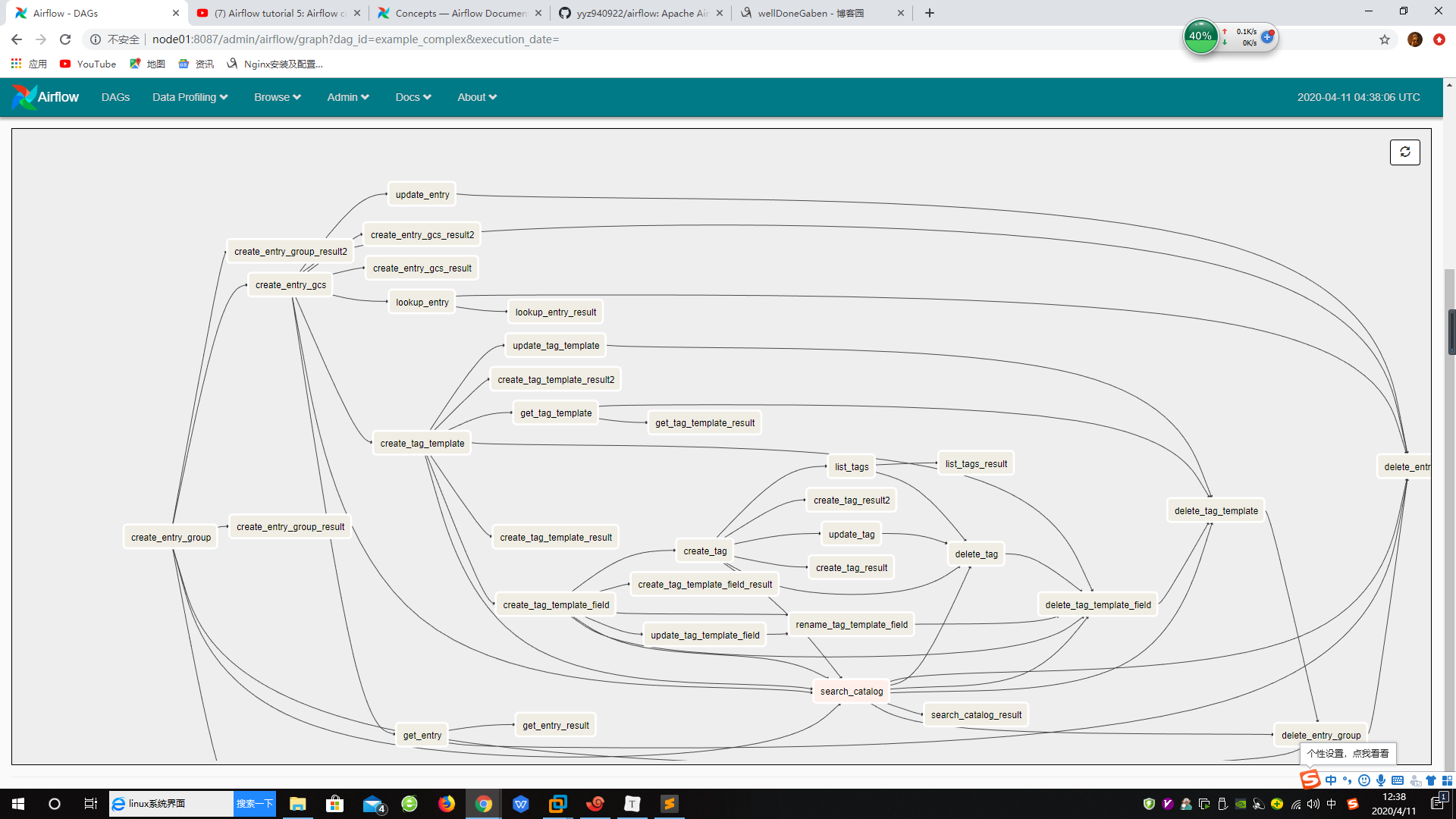
Operators and Tasks
-
DAGS 并不执行任何实际的计算, 相反Operator(操作算子)决定了到底要做什么。
-
Task(任务): 一旦一个算子被初始化, 那么它就被引用为一个 task。每个算子描述了工作流中的单个任务。
- 初始化一个任务需要提供一个唯一的任务id及DAG容器。
-
一个DAG就是一个用于组织任务集并执行它们的内容的容器。
-
Operators 分类:
-
Sensors(传感器)
-
会保持运行直到达到了一个特定标准的一类算子。该标准可以是: 等待一定时间, 获取外部文件或者 获取上游数据源。
-
HdfsSensor: 等待一个文件或文件夹加载到HDFS
-
NamedHivePartitionSensor: 检查最近分区的Hive表是否可以被下游使用执行
-
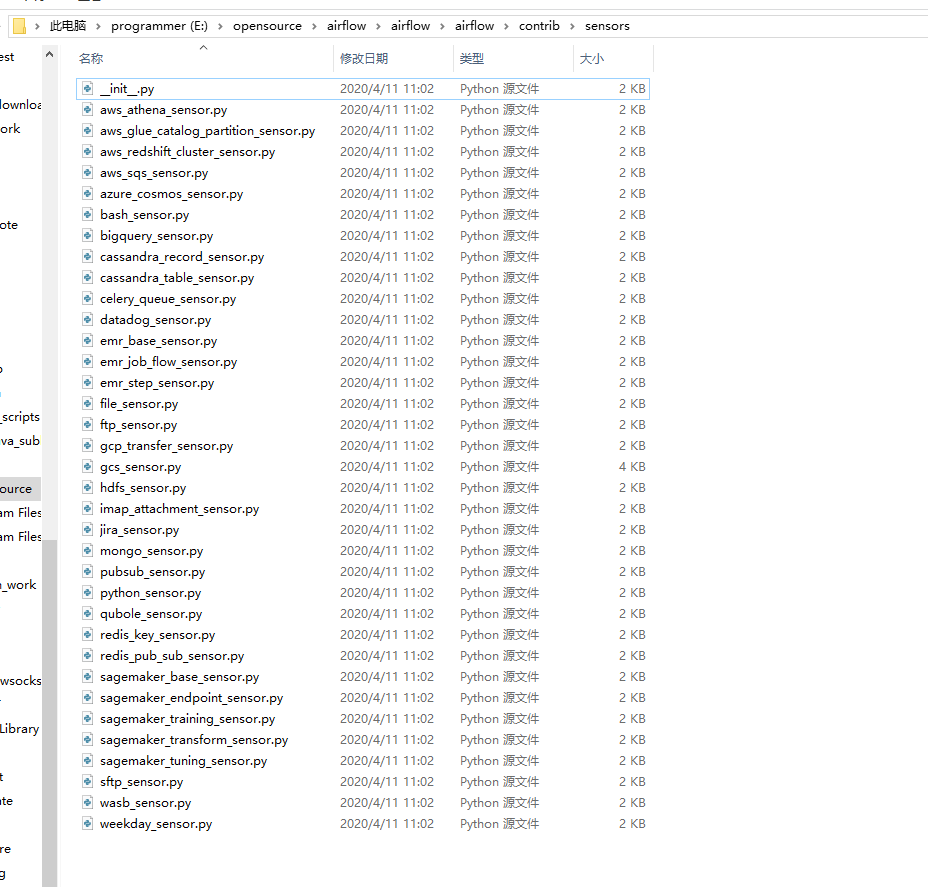
其实你把项目clone下来看一下会发现有很多的现成sensors已经写好了(airflow\airflow\contrib\sensors目录下):
-
-
Operators(操作算子)
-
会触发特定的行为(比如运行一个bash命令, 执行一个python 函数, 或者执行一个Hive查询......)
-
BashOperator: 执行一个bash命令
-
PythonOperator: 执行任意python函数
-
HiveOperator: 在特定Hive数据库中执行 hql 代码或者Hive脚本
-
BigQueryOperator:: 在指定Google BigQuery 数据库中执行Google BigQuery SQL查询
-
airflow\airflow\contrib\operators目录下也有很多现成的 operator
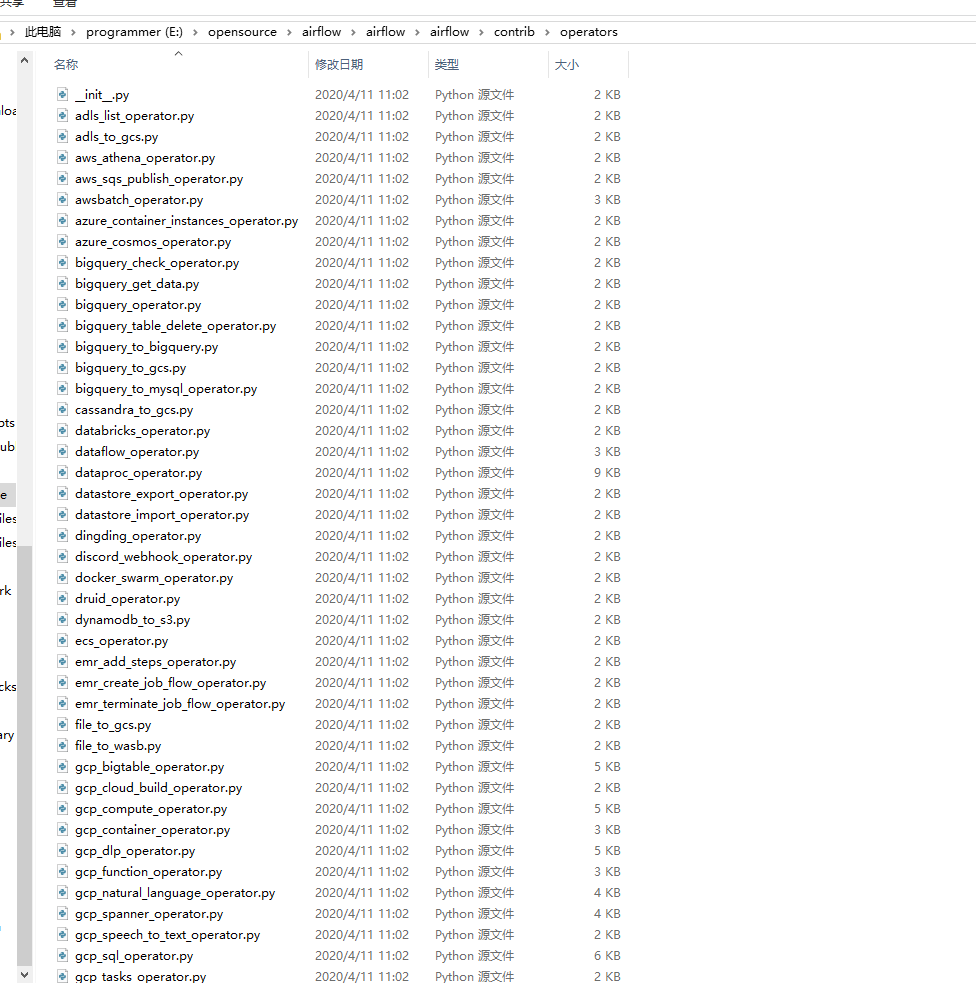
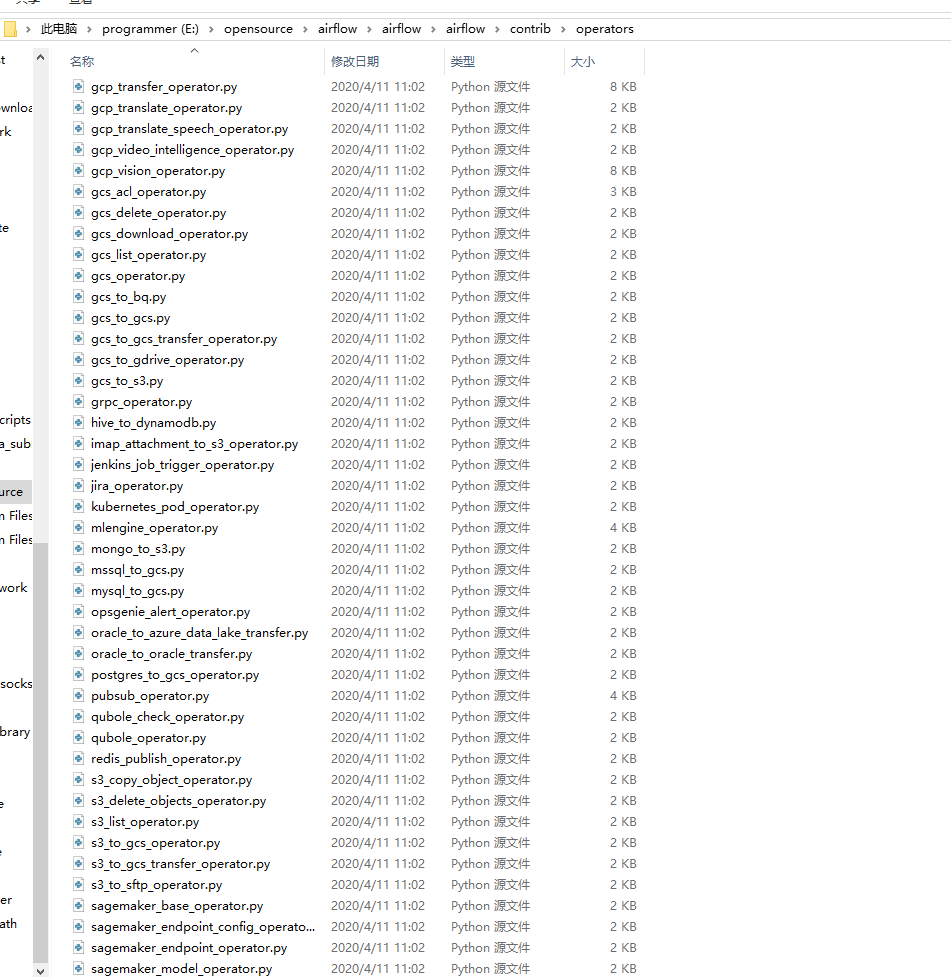
- 我们看到有Spark提交相关操作算子, 但是没有Flink的, 所以后续可能得要自己实现了。
-
-
Transfers: 将数据从一个位置移至另一个位置
- MySqlToHiveTransfer: 将数据从MySQL移至Hive
- S3ToRedshiftTransfer: 将数据从Amazon S3移至 Redshift
- 看了下, 这类算子和会触发特定行为的操作算子混合放在airflow\airflow\contrib\operators目录下。
-
接下来我们来看一下某段调度Google Big Query的代码
import json
from datetime import timedelta, datetime
from airflow import DAG
from airflow.contrib.operators.bigquery_operator import BigQueryOperator
from airflow.contrib.operators.bigquery_check_operator import BigQueryCheckOperator
default_args = {
'owner': 'airflow',
'depends_on_past': True,
'start_date': datetime(2018, 12, 1),
'end_date': datetime(2018, 12, 5),
'email': ['airflow@airflow.com'],
'email_on_failure': True,
'email_on_retry': False,
'retries': 2,
'retry_delay': timedelta(minutes=5),
}
# Set Schedule: Run pipeline once a day. 每天运行一次管道
# Use cron to define exact time. Eg. 8:15am would be "15 08 * * *"
# 每天晚上9点调度
schedule_interval = "00 21 * * *"
# Define DAG: Set ID and assign default args and schedule interval
# 定义DAG, 设置ID并重新标出默认参数及调度间隔
dag = DAG(
'bigquery_github_trends',
default_args=default_args,
schedule_interval=schedule_interval
)
# Config variables 配置变量
BQ_CONN_ID = "my_gcp_conn"
BQ_PROJECT = "my-bq-project"
BQ_DATASET = "my-bq-dataset"
## Task 1: check that the github archive data has a dated table created for that date
## 任务1: 检查github archive 数据是否有过时的表
# To test this task, run this command:
# docker-compose -f docker-compose-gcloud.yml run --rm webserver airflow test bigquery_github_trends bq_check_githubarchive_day 2018-12-01
t1 = BigQueryCheckOperator(
task_id='bq_check_githubarchive_day',
sql='''
#standardSQL
SELECT
table_id
FROM
`githubarchive.day.__TABLES_SUMMARY__`
WHERE
table_id = "{{ yesterday_ds_nodash }}"
''',
use_legacy_sql=False,
bigquery_conn_id=BQ_CONN_ID,
dag=dag
)
## Task 2: check that the hacker news table contains data for that date.
## 任务2: 检查hacker new表是否含有该日的数据
t2 = BigQueryCheckOperator(
task_id='bq_check_hackernews_full',
sql='''
#standardSQL
SELECT
FORMAT_TIMESTAMP("%Y%m%d", timestamp ) AS date
FROM
`bigquery-public-data.hacker_news.full`
WHERE
type = 'story'
AND FORMAT_TIMESTAMP("%Y%m%d", timestamp ) = "{{ yesterday_ds_nodash }}"
LIMIT
1
''',
use_legacy_sql=False,
bigquery_conn_id=BQ_CONN_ID,
dag=dag
)
## Task 3: create a github daily metrics partition table
## 任务3: 创建一个github每日衡量指标的分区表
t3 = BigQueryOperator(
task_id='bq_write_to_github_daily_metrics',
sql='''
#standardSQL
SELECT
date,
repo,
SUM(IF(type='WatchEvent', 1, NULL)) AS stars,
SUM(IF(type='ForkEvent', 1, NULL)) AS forks
FROM (
SELECT
FORMAT_TIMESTAMP("%Y%m%d", created_at) AS date,
actor.id as actor_id,
repo.name as repo,
type
FROM
`githubarchive.day.{{ yesterday_ds_nodash }}`
WHERE type IN ('WatchEvent','ForkEvent')
)
GROUP BY
date,
repo
''',
destination_dataset_table='{0}.{1}.github_daily_metrics${2}'.format(
BQ_PROJECT, BQ_DATASET, '{{ yesterday_ds_nodash }}'
),
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
use_legacy_sql=False,
bigquery_conn_id=BQ_CONN_ID,
dag=dag
)
## Task 4: aggregate past github events to daily partition table
## 聚合过去的github事件到每日分区表
t4 = BigQueryOperator(
task_id='bq_write_to_github_agg',
sql='''
#standardSQL
SELECT
"{2}" as date,
repo,
SUM(stars) as stars_last_28_days,
SUM(IF(_PARTITIONTIME BETWEEN TIMESTAMP("{4}")
AND TIMESTAMP("{3}") ,
stars, null)) as stars_last_7_days,
SUM(IF(_PARTITIONTIME BETWEEN TIMESTAMP("{3}")
AND TIMESTAMP("{3}") ,
stars, null)) as stars_last_1_day,
SUM(forks) as forks_last_28_days,
SUM(IF(_PARTITIONTIME BETWEEN TIMESTAMP("{4}")
AND TIMESTAMP("{3}") ,
forks, null)) as forks_last_7_days,
SUM(IF(_PARTITIONTIME BETWEEN TIMESTAMP("{3}")
AND TIMESTAMP("{3}") ,
forks, null)) as forks_last_1_day
FROM
`{0}.{1}.github_daily_metrics`
WHERE _PARTITIONTIME BETWEEN TIMESTAMP("{5}")
AND TIMESTAMP("{3}")
GROUP BY
date,
repo
'''.format(BQ_PROJECT, BQ_DATASET,
"{{ yesterday_ds_nodash }}", "{{ yesterday_ds }}",
"{{ macros.ds_add(ds, -6) }}",
"{{ macros.ds_add(ds, -27) }}"
)
,
destination_dataset_table='{0}.{1}.github_agg${2}'.format(
BQ_PROJECT, BQ_DATASET, '{{ yesterday_ds_nodash }}'
),
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
use_legacy_sql=False,
bigquery_conn_id=BQ_CONN_ID,
dag=dag
)
# Task 5: aggregate hacker news data to a daily partition table
# 聚合黑客新闻数据到一个每日分区表
t5 = BigQueryOperator(
task_id='bq_write_to_hackernews_agg',
sql='''
#standardSQL
SELECT
FORMAT_TIMESTAMP("%Y%m%d", timestamp) AS date,
`by` AS submitter,
id as story_id,
REGEXP_EXTRACT(url, "(https?://github.com/[^/]*/[^/#?]*)") as url,
SUM(score) as score
FROM
`bigquery-public-data.hacker_news.full`
WHERE
type = 'story'
AND timestamp>'{{ yesterday_ds }}'
AND timestamp<'{{ ds }}'
AND url LIKE '%https://github.com%'
AND url NOT LIKE '%github.com/blog/%'
GROUP BY
date,
submitter,
story_id,
url
''',
destination_dataset_table='{0}.{1}.hackernews_agg${2}'.format(
BQ_PROJECT, BQ_DATASET, '{{ yesterday_ds_nodash }}'
),
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
use_legacy_sql=False,
bigquery_conn_id=BQ_CONN_ID,
dag=dag
)
# Task 6: join the aggregate tables 加到聚合表中
t6 = BigQueryOperator(
task_id='bq_write_to_hackernews_github_agg',
sql='''
#standardSQL
SELECT
a.date as date,
a.url as github_url,
b.repo as github_repo,
a.score as hn_score,
a.story_id as hn_story_id,
b.stars_last_28_days as stars_last_28_days,
b.stars_last_7_days as stars_last_7_days,
b.stars_last_1_day as stars_last_1_day,
b.forks_last_28_days as forks_last_28_days,
b.forks_last_7_days as forks_last_7_days,
b.forks_last_1_day as forks_last_1_day
FROM
(SELECT
*
FROM
`{0}.{1}.hackernews_agg`
WHERE _PARTITIONTIME BETWEEN TIMESTAMP("{2}") AND TIMESTAMP("{2}")
)as a
LEFT JOIN
(
SELECT
repo,
CONCAT('https://github.com/', repo) as url,
stars_last_28_days,
stars_last_7_days,
stars_last_1_day,
forks_last_28_days,
forks_last_7_days,
forks_last_1_day
FROM
`{0}.{1}.github_agg`
WHERE _PARTITIONTIME BETWEEN TIMESTAMP("{2}") AND TIMESTAMP("{2}")
) as b
ON a.url = b.url
'''.format(
BQ_PROJECT, BQ_DATASET, "{{ yesterday_ds }}"
),
destination_dataset_table='{0}.{1}.hackernews_github_agg${2}'.format(
BQ_PROJECT, BQ_DATASET, '{{ yesterday_ds_nodash }}'
),
write_disposition='WRITE_TRUNCATE',
allow_large_results=True,
use_legacy_sql=False,
bigquery_conn_id=BQ_CONN_ID,
dag=dag
)
# Task 7: Check if partition data is written successfully
# 检查分区数据是否被成功写入
t7 = BigQueryCheckOperator(
task_id='bq_check_hackernews_github_agg',
sql='''
#standardSQL
SELECT
COUNT(*) AS rows_in_partition
FROM `{0}.{1}.hackernews_github_agg`
WHERE _PARTITIONDATE = "{2}"
'''.format(BQ_PROJECT, BQ_DATASET, '{{ yesterday_ds }}'
),
use_legacy_sql=False,
bigquery_conn_id=BQ_CONN_ID,
dag=dag)
# Setting up Dependencies 设置依赖
t3.set_upstream(t1)
t4.set_upstream(t3)
t5.set_upstream(t2)
t6.set_upstream(t4)
t6.set_upstream(t5)
t7.set_upstream(t6
将数据加载到hdfs, 再通过Hive将数据加载到MySQL的代码
import airflow
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from airflow.operators.python_operator import PythonOperator
from airflow.operators.hive_operator import HiveOperator
from datetime import date, timedelta
# --------------------------------------------------------------------------------
# Create a few placeholder scripts. 创建一些占位符脚本
# In practice these would be different python script files, which are imported in this section with absolute or relative imports
# 在尝试中这些会是不同的python脚本文件, 在此部分会被以相对或绝对路径的方式导入
# --------------------------------------------------------------------------------
def fetchtweets():
return None
def cleantweets():
return None
def analyzetweets():
return None
def transfertodb():
return None
# --------------------------------------------------------------------------------
# set default arguments 设置默认参数
# --------------------------------------------------------------------------------
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': airflow.utils.dates.days_ago(2),
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
# 'queue': 'bash_queue',
# 'pool': 'backfill',
# 'priority_weight': 10,
# 'end_date': datetime(2016, 1, 1),
}
dag = DAG(
'example_twitter_dag', default_args=default_args,
schedule_interval="@daily")
# --------------------------------------------------------------------------------
# This task should call Twitter API and retrieve tweets from yesterday from and to
# for the four twitter users (Twitter_A,..,Twitter_D)
# 此任务应该会调用Twitter的API并取回昨日四位twitter用户的往来信息
# There should be eight csv output files generated by this task and naming convention
# is direction(from or to)_twitterHandle_date.csv
# 应当会有8个 csv输出文件由此任务生成, 并惯例命名为 数据来往方向_twitterHandle_date.csv
# --------------------------------------------------------------------------------
fetch_tweets = PythonOperator(
task_id='fetch_tweets',
python_callable=fetchtweets,
dag=dag)
# --------------------------------------------------------------------------------
# Clean the eight files. 清理此8个文件
# In this step you can get rid of or cherry pick columns
# 在此阶段你可以完全丢弃或者选择某几个分支并改变部分文档
# and different parts of the text
# --------------------------------------------------------------------------------
clean_tweets = PythonOperator(
task_id='clean_tweets',
python_callable=cleantweets,
dag=dag)
clean_tweets.set_upstream(fetch_tweets)
# --------------------------------------------------------------------------------
# In this section you can use a script to analyze the twitter data.
# 在此部分你可以使用一个脚本来分析twitter数据
# Could simply be a sentiment analysis through algorithms like bag of words or something more
# complicated.
# 可以仅是一个通过算法获取(如bag of words模型或或跟复杂的)观点分析。
# You can also take a look at Web Services to do such tasks
# 你也可以尝试用web服务来做这些任务
# --------------------------------------------------------------------------------
analyze_tweets = PythonOperator(
task_id='analyze_tweets',
python_callable=analyzetweets,
dag=dag)
analyze_tweets.set_upstream(clean_tweets)
# --------------------------------------------------------------------------------
# Although this is the last task, we need to declare it before the next tasks as we
# will use set_downstream This task will extract summary from Hive data and store
# it to MySQL
# 尽管这是最后一个任务, 我们需要在下一个任务之前申明它, 当我们设置下游时, 该任务会抽取Hive中的总结数据并存入MySQL
# --------------------------------------------------------------------------------
hive_to_mysql = PythonOperator(
task_id='hive_to_mysql',
python_callable=transfertodb,
dag=dag)
# --------------------------------------------------------------------------------
# The following tasks are generated using for loop. The first task puts the eight
# csv files to HDFS.
# 接下来的任务通过循环生成。第一个任务把8个csv文件放到hdfs
# The second task loads these files from HDFS to respected Hive
# tables.
# 第二个任务将这些文件从hdfs同步到Hive表中
# These two for loops could be combined into one loop.
# 这两个循环可以被合并为一个
# However, in most cases, you will be running different analysis on your incoming incoming and
# outgoing tweets, and hence they are kept separated in this example.
# 然而, 大多数情况下, 你会根据你的获取的和输出的消息进行不同的分析, 所以它们在此例子中是被分离的。
# --------------------------------------------------------------------------------
from_channels = ['fromTwitter_A', 'fromTwitter_B', 'fromTwitter_C', 'fromTwitter_D']
to_channels = ['toTwitter_A', 'toTwitter_B', 'toTwitter_C', 'toTwitter_D']
yesterday = date.today() - timedelta(days=1)
dt = yesterday.strftime("%Y-%m-%d")
# define where you want to store the tweets csv file in your local directory
# 定义你想要把csv文件发送到本地目录哪里
local_dir = "/tmp/"
# define the location where you want to store in HDFS
# 定义你想把csv文件存到hdfs目录哪里
hdfs_dir = " /tmp/"
for channel in to_channels:
file_name = "to_" + channel + "_" + yesterday.strftime("%Y-%m-%d") + ".csv"
load_to_hdfs = BashOperator(
task_id="put_" + channel + "_to_hdfs",
bash_command="HADOOP_USER_NAME=hdfs hadoop fs -put -f " +
local_dir + file_name +
hdfs_dir + channel + "/",
dag=dag)
load_to_hdfs.set_upstream(analyze_tweets)
load_to_hive = HiveOperator(
task_id="load_" + channel + "_to_hive",
hql="LOAD DATA INPATH '" +
hdfs_dir + channel + "/" + file_name + "' "
"INTO TABLE " + channel + " "
"PARTITION(dt='" + dt + "')",
dag=dag)
load_to_hive.set_upstream(load_to_hdfs)
load_to_hive.set_downstream(hive_to_mysql)
for channel in from_channels:
file_name = "from_" + channel + "_" + yesterday.strftime("%Y-%m-%d") + ".csv"
load_to_hdfs = BashOperator(
task_id="put_" + channel + "_to_hdfs",
bash_command="HADOOP_USER_NAME=hdfs hadoop fs -put -f " +
local_dir + file_name +
hdfs_dir + channel + "/",
dag=dag)
load_to_hdfs.set_upstream(analyze_tweets)
load_to_hive = HiveOperator(
task_id="load_" + channel + "_to_hive",
hql="LOAD DATA INPATH '" +
hdfs_dir + channel + "/" + file_name + "' "
"INTO TABLE " + channel + " "
"PARTITION(dt='" + dt + "')",
dag=dag)
load_to_hive.set_upstream(load_to_hdfs)
load_to_hive.set_downstream(hive_to_mysql)

