Greenplum简介
Greenplum能做什么?
- 数仓 / OLAP / 即席查询
- 混合负载 / HTAP
- 流数据
- 集成数据分析
- 数据库内嵌机器学习
- 现代 SQL
核心架构
-
架构图

-
Master Host:
- 主节点, 负责协调整个集群
- 没有数据, 只有用户的元数据
-
Standby Master: 备份主
-
Segment Host:
- 每个Segment都是一个单节点的PostgreSQL数据库。
- 包含用户的实际数据, 会等待master给它分配实际任务, 然后进行相互协调执行。
- 每个Segment对应在另外一个节点上会有一个镜像(mirror), 当这台Segment挂了之后, 它的镜像就会自动提升为primary, 从而实现高可用。
-
可以随着业务的扩充进行线性扩展
-
每台机器都是独立的, 机器之间通过Interconnect进行网络通讯, 因为又被称为MPP无共享架构。
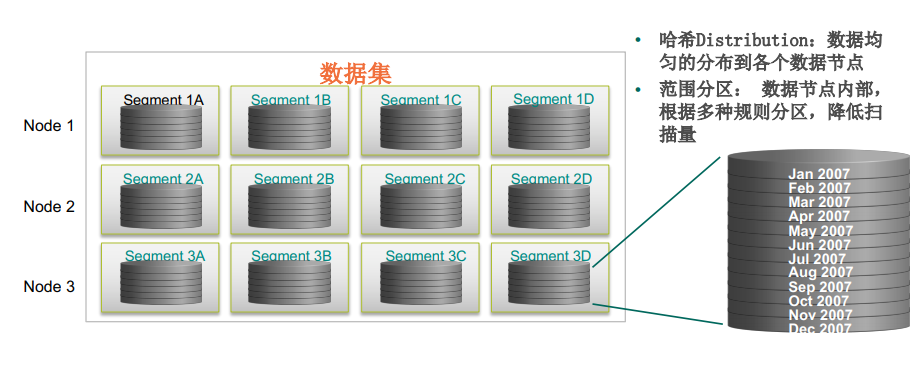
数据分布
-
多种分布策略:
- Hash, 随机, 复制表等
-
最重要的策略和目标是均匀分布: 每个节点 1/n 数据

多级分区
多模存储 / 多态存储
- 通常情况下, 数据价值随着时间越来越低, 所以会有不同的对应处理模式。
- 就比如说一张销售表:
- 最近3个月的数据, 我们可能要做的是对数据的完善及更新。
- 距今3个月到1年的数据, 我们可能做的最多的是做一些查询, 聚集, 报表。
- 1年前+数据, 访问较少。
- 对应存储模式:
- 1年前+数据:
- 采用外部表技术, 数据不放在Greenplum中, 比如hdfs, amazon S3中。
- 无缝查询所有数据:
- Text, CSV, Binary, Avro, Parquet, ORC格式
- 距今3个月到1年的数据:
- 使用列存储, 更适合压缩(不同列可以使用不同压缩方式: gzip, quickz, delta, RLE, zstd), 查询列子集时速度快。
- 最近3个月的数据:
- 使用行存储, 适合OLTP业务, 适合频繁更新或者访问大部分字段的场景。
- 1年前+数据:
查询支持
-
Apache ORCA: 专为复杂查询而生的优化器

- 可以做到比较好的动态分区裁剪
- 处理比较复杂的子查询, 或CTE(是一个命名的临时结果集,仅在单个SQL语句(例如SELECT,INSERT或DELETE)的执行范围内存在)
-
数据shuffle
-
其他技术:
- 高效压缩算法
- 多阶段聚集
- 复制表
- Unlogged table
- 物化视图
- 一致性hash
- 在线扩容
- 安全性
混合负载 / HTAP
-
OLTP 优化技术
- 全局死锁检测 (GDD): 6版本之前用表锁, 优化有使用行锁。
- 锁优化: 有一个锁竞争比较严重, 优化。
- 事务优化
- 复制表
- 多模存储
- 灵活索引
- OLTP 友好的优化器
- 内核升级: PostgreSQL 9.4
-
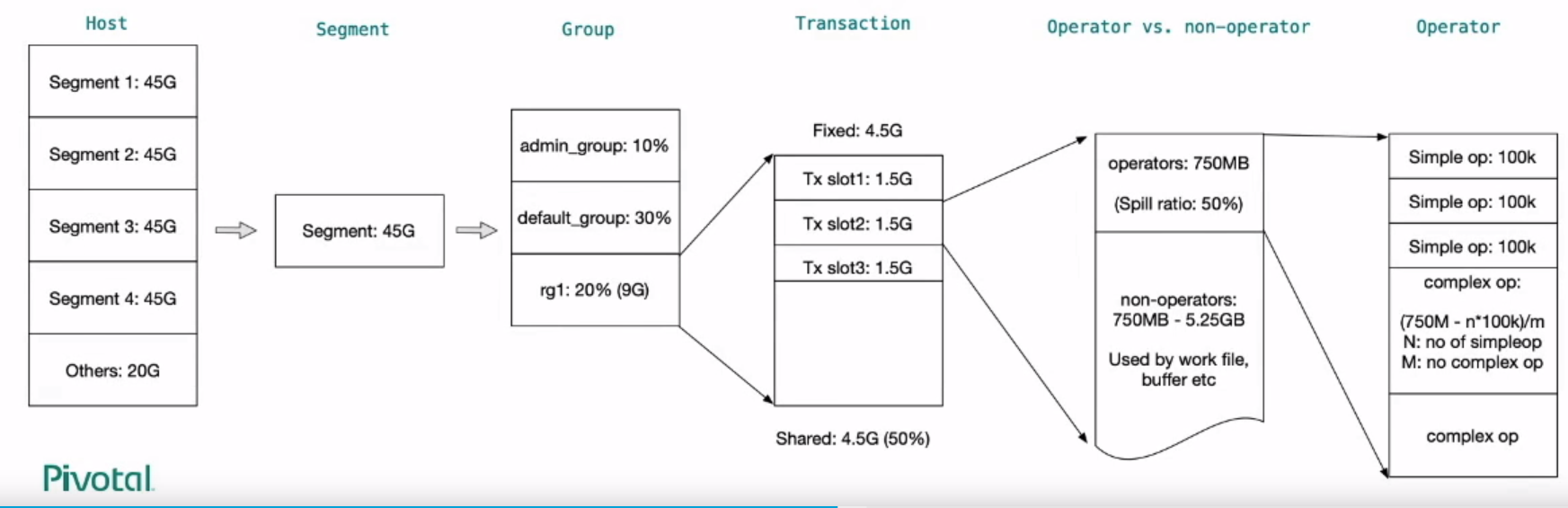
资源管理
特性 资源组(Resource Group) 资源队列(Resource Queue) 并发控制 事务级别 语句级别 死锁 无 极端情况下会出现 CPU管理 基于比例、基于cgroup 基于粗粒度的优先级 CPU 空闲利用率 可以充分利用空闲CPU 部分利用 内存限制 精细 粗粒度 组内内存共享 T F 动态修改资源配置 T 部分 排队 无并发槽位或者内存配额时 无并发槽位时 管理DDL、Utility语句 T F Segment级别监控管理 T F 基于规则的资源管理 T F
细粒度多级内存管理
企业案例
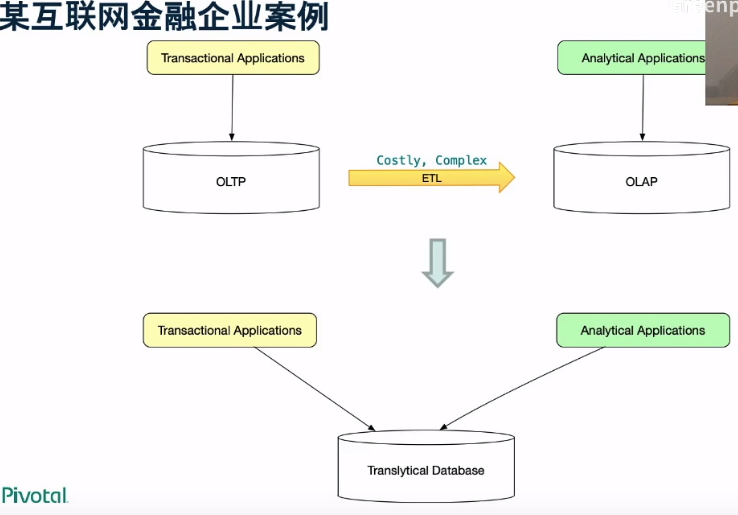
- 如果对TP业务不是追求极致, 可以考虑Greenplum。
流数据(准实时)
-
Greenplum Kafka Connector
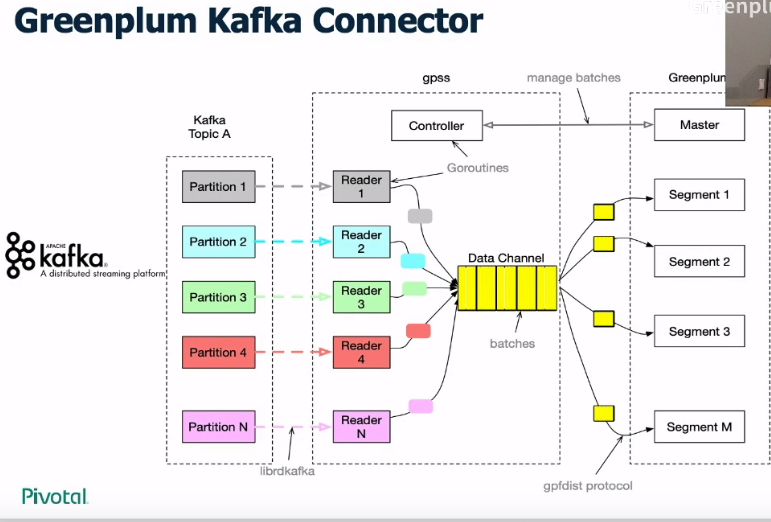
- 该组件的目的是将Kafka Topic中 partition的数据高效导入到Greenplum中。
- 可以看到最终gpss会将数据并行地导入到每个Segment中而不需要通过master, 效率较高。
集成数据分析
-
各种数据类型: 结构化、半结构化、非结构化
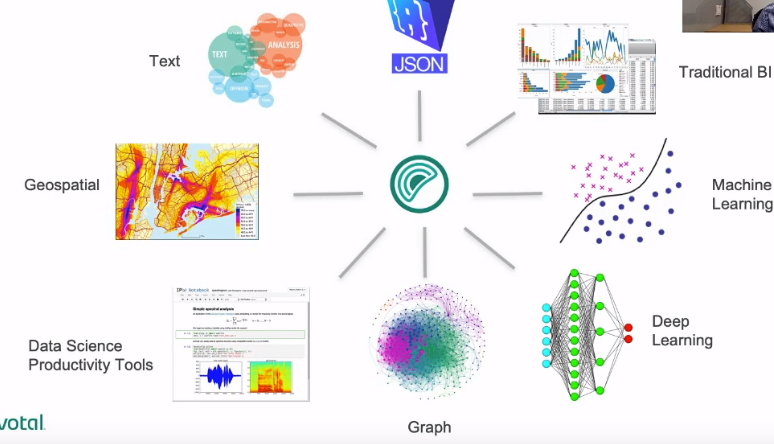
数据融合
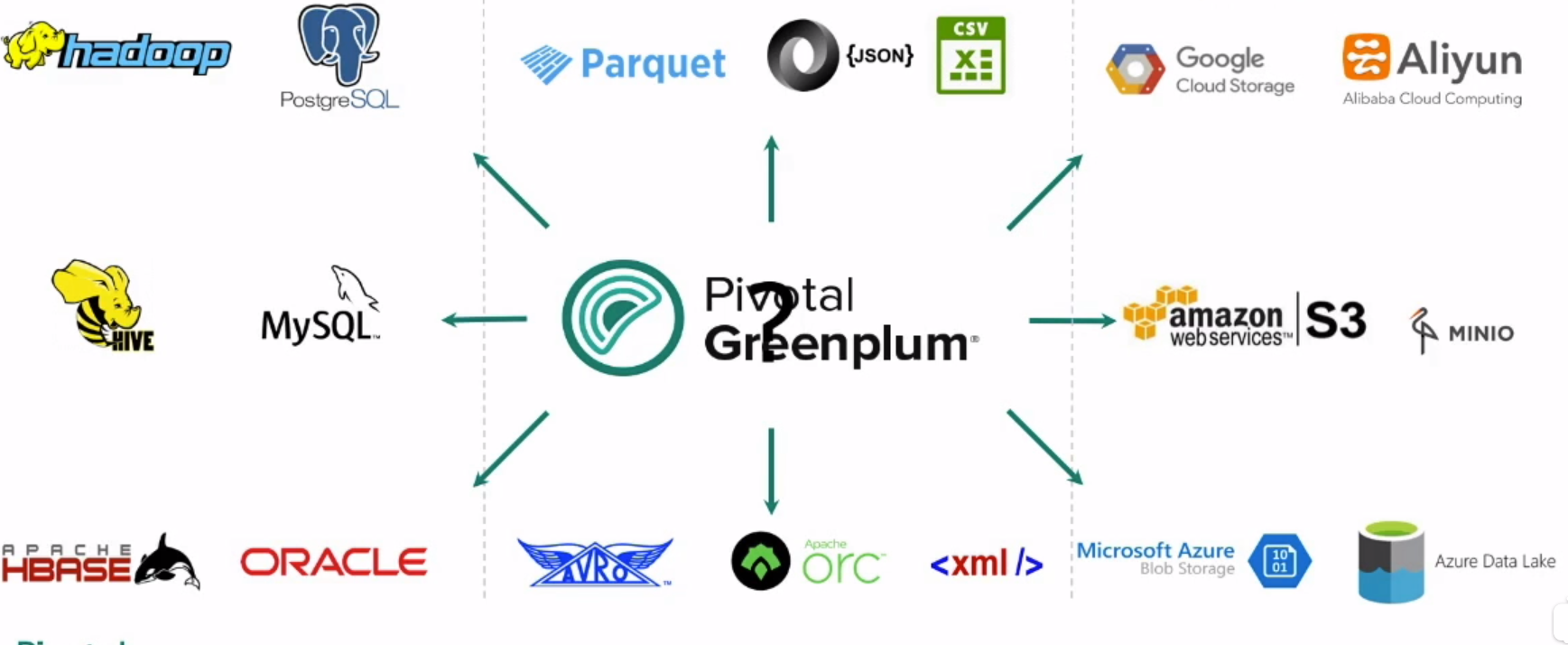
- 数据全都放到Greenplum中的话代价还是很大的。
- 过去会将全部数据从别的平台拉取到Greenplum, 涉及比较复杂的etl过程
- 4版本后的数据融合功能, 不需要拉取数据到Greenplum, 只要在Greenplum上写SQL就可以查询存储在不同数据中的数据。
PXF 架构

- 可以在Greenplum中定义一个外部表, 此外部表通过PXF协议指定到hadoop, hive, hbase, 数据库s3等。
- 我们只需要在Greenplum上写一个SQL, 底层就会自动去对应的存储系统中拿取数据。
- 如果底层是Hive的话, PXF还可以做到谓词下推。
基于 SQL 的数据库内嵌机器学习
-
数据量越大, 模型精度越大。
-
SAS: 需要对数据进行抽样后再训练, 会损失部分精度, 只能用一个节点进行训练。
-
希望对全量数据进行运算, 将算法内嵌到数据库中, 可以使用数据库的并行计算能力。
-
apache madlib
- 在每个Segment上集成成成Keras或者tensorFlow, 可以使用每个节点上的GPU资源。

