Storm 流式计算框架
1. 简介
-
是一个分布式, 高容错的 实时计算框架
-
Storm进程常驻内存, 永久运行
-
Storm数据不经过磁盘, 在内存中流转, 通过网络直接发送给下游
-
流式处理(streaming) 与 批处理(batch)
-
批处理(batch): MapReduce
-
微批处理(MircroBatch): Spark (性能上近似 Streaming, 但是还是有所不及)
-
流(streaming): Storm, Flink(其实Flink也可以做批处理)
-
Storm MapReduce 流式处理 批处理 毫秒级 分钟级 DAG模型 Map+Reduce模型 常驻运行 反复启停
-
-
Storm 计算模型

-
Topology - DAG 有向无环图
- 例图: (Spout: 喷嘴)

-
对Storm实时计算逻辑进行封装
-
由一系列通过数据流相互关联的Spout、Bolt锁组成的拓扑结构
-
生命周期: 此拓扑只要启动就会一直在集群中运行, 直到手动将其kill, 否则不会终止
(与MapReduce中的Job的区别: MR中的Job在计算机执行完成就会终止)
-
Tuple - 元组
- Stream中最小的数据组成单元(熟悉python的一定不会陌生)
-
Stream - 数据流
- 从Spout 中源源不断传递数据给Bolt、以及上一个Bolt传递数据给下一个Bolt, 所形成的的数据通道为Stream
- 在声明Stream时需要给其指定一个Id (默认为Default)
- 实际开发场景中, 多使用单一数据流, 此时不需要单独指定StreamId
-
Spout - 数据源
-
拓扑中数据流的来源。一般会从指定外部的数据源读取元组 (Tuple) 发送到拓扑(Topology) 中。
-
一个Spout可以发送多个数据流(Stream)
- 可以先通过OutputFieldsDeclarer中的declare方法声明定义的不同数据流, 发送数据时通过SpoutOutputCollector 中的 emit 方法指定数据流 Id (streamId) 参数将数据发送出去
-
Spout 中最核心的方法是 nextTuple, 该方法会被Storm线程不断调用、主动从数据源拉取数据, 再通过emit 方法将数据生成元组 (Tuple) 发送给之后的 Bolt 计算
-
-
Bolt - 对数据流进行处理的组件
-
拓扑中数据处理均由Bolt完成。对于简单的任务或者数据流转换, 单个Bolt可以简单实现; 更加复杂场景往往需要多个Bolt分多个步骤完成
-
一个Bolt可以发送多个数据流(Stream)
- 可先通过OutputFieldsDeclarer中的declare方法声明定义的不同数据流, 发送数据时通过收集器(Collector)中的emit方法指定数据流Id(streamId) 参数将数据发送出去
-
Bolt 中最核心的方法是execute方法, 该方法负责接收到一个元组 (Tuple) 数据 以及 真正实现核心的业务逻辑
-
-
简单的WorldCount实例
- WordCountSpout
package com.ronnie.storm.wordCount; import backtype.storm.spout.SpoutOutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichSpout; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Values; import java.util.Map; import java.util.Random; public class WordCountSpout extends BaseRichSpout { private Random random = new Random(); SpoutOutputCollector collector; String[] lines = { "Well done Gaben well fucking done", "What is going wrong with you Bro", "You are so fucking retard", "What the hell is it", "hadoop spark storm flink", "mysql oracle memcache redis mongodb" }; @Override public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector collector) { this.collector = collector; } /** * 1. storm 会一直(死循环)调用此方法 * 2. 每次调用此方法, 往下游发输出 * * while(flag){ * nextTuple(); * } */ @Override public void nextTuple() { int index = random.nextInt(lines.length); String line = lines[index]; System.out.println("line: " + line); collector.emit(new Values(line)); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("liner")); } }- WordCountSplit
package com.ronnie.storm.wordCount; import backtype.storm.task.OutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichBolt; import backtype.storm.tuple.Fields; import backtype.storm.tuple.Tuple; import backtype.storm.tuple.Values; import java.util.Map; public class WordCountSplit extends BaseRichBolt { // 提升作用域 OutputCollector collector; @Override public void prepare(Map map, TopologyContext topologyContext, OutputCollector collector) { System.err.println(this + "============================="); this.collector = collector; } @Override public void execute(Tuple input) { // 从域中获取数据, 要与之前Spout中 declareOutputFields 的域名称一致 String line = input.getStringByField("liner"); // 根据什么分离 String[] words = line.split(" "); for (String word: words){ // Value是一个ArrayList, 其中存的对象要与后面声明的域中属性相对应 collector.emit(new Values(word,"ronnie")); } } /** * Fields中 的名称 与 前面 value 中的属性相应 * @param declarer */ @Override public void declareOutputFields(OutputFieldsDeclarer declarer) { declarer.declare(new Fields("word", "name")); } }-
WordCount
package com.ronnie.storm.wordCount; import backtype.storm.task.OutputCollector; import backtype.storm.task.TopologyContext; import backtype.storm.topology.OutputFieldsDeclarer; import backtype.storm.topology.base.BaseRichBolt; import backtype.storm.tuple.Tuple; import java.util.HashMap; import java.util.Map; public class WordCount extends BaseRichBolt { Map<String, Integer> result = new HashMap<>(); /** * 初始化任务 * @param map * @param topologyContext * @param outputCollector */ @Override public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) { } /** * 最核心方法 * 上游传tuple数据给它, 并调用此方法 * @param input */ @Override public void execute(Tuple input) { String word = input.getString(0); Integer integer = result.get(word); if (null == integer){ integer = 1; } else { integer += 1; } result.put(word, integer); System.err.println(word + " : " + integer); } /** * 声明输出的域类型 * @param outputFieldsDeclarer */ @Override public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) { } } -
WordCountTopology
package com.ronnie.storm.wordCount; import backtype.storm.Config; import backtype.storm.LocalCluster; import backtype.storm.StormSubmitter; import backtype.storm.generated.AlreadyAliveException; import backtype.storm.generated.AuthorizationException; import backtype.storm.generated.InvalidTopologyException; import backtype.storm.generated.StormTopology; import backtype.storm.topology.TopologyBuilder; import backtype.storm.tuple.Fields; public class WordCountTopology { public static void main(String[] args) { TopologyBuilder topologyBuilder = new TopologyBuilder(); topologyBuilder.setSpout("wcSpout", new WordCountSpout()); // setBolt 的第三个参数为并行量 setNumTasks 修改 任务数量为 4 topologyBuilder.setBolt("wcSplit", new WordCountSplit(), 2).setNumTasks(4).shuffleGrouping("wcSpout"); topologyBuilder.setBolt("wcCount", new WordCount(), 5).fieldsGrouping("wcSplit", new Fields("word")); StormTopology topology = topologyBuilder.createTopology(); Config config = new Config(); // 修改配置文件中的worker数量为3 config.setNumWorkers(3); // 只要参数存在 if (args.length > 0){ try { StormSubmitter.submitTopology(args[0],config,topology); } catch (AlreadyAliveException e) { e.printStackTrace(); } catch (InvalidTopologyException e) { e.printStackTrace(); } catch (AuthorizationException e) { e.printStackTrace(); } } else { // 不存在就执行本地任务 LocalCluster localCluster = new LocalCluster(); localCluster.submitTopology("wordCount", config, topology); } } } -
最后可将任务打成 jar 包传送到linux系统上(已经部署好storm集群), 再通过命令行执行任务
[root@node01 storm-0.10.0] bin/storm jar /opt/ronnie/wc.jar com.ronnie.storm.wordCount.WordCountTopology wc # 在storm目录下 bin/storm jar jar文件目录 包结构.任务类 任务参数
-
-
Storm 架构设计

-
Nimbus
- 资源调度
- 任务分配
- 接收jar包
-
Supervisor
-
接收Nimbus分配的任务
-
启动、停止自己管理的worker进程 (当前supervisor上的work数量可通过配置文件设定)
-
-
Worker
-
运行具体处理运算组件的进程 (每个Worker对应执行一个Topology 的子集)
-
worker 任务类型:
- spout 任务
- bolt 任务
-
启动 executor
- executor是 worker JVM 进程中的一个java线程, 一般默认每个executor负责执行一个task任务
-
-
Zookeeper
-
与Hadoop架构对比
Hadoop Storm 主节点 ResourceManager Nimbus 从节点 NodeManager Supervisor 应用程序 Job Topology 工作进程 Child Worker 计算模型 Map/Reduce Spout/Bolt
-
-
Storm 任务提交流程
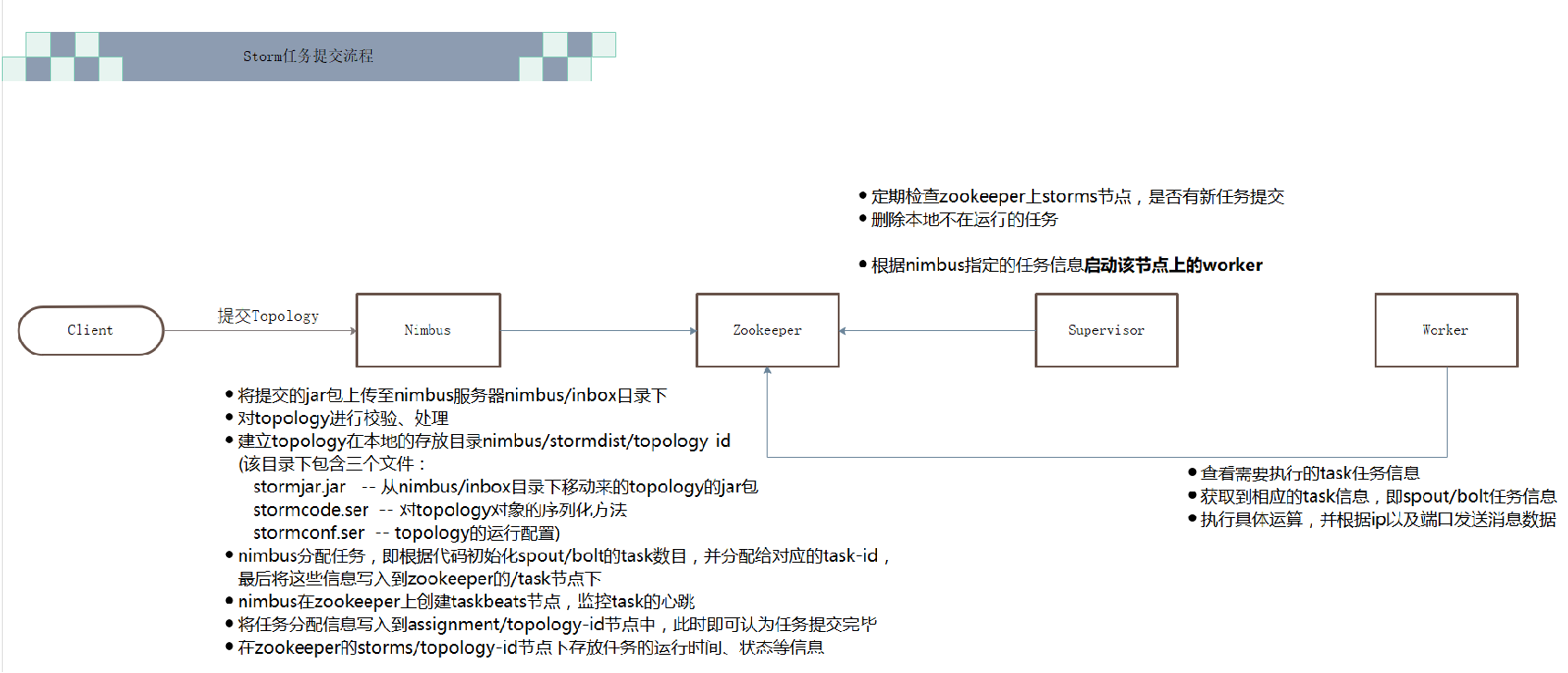
-
Storm 本地目录树


-
Storm DRPC
-
DRPC (Distributed RPC)
-
分布式远程过程调用
-
DRPC 是通过一个 DRPC 服务端(DRPC server)来实现分布式RPC功能的。
-
DRPC Server 负责接收 RPC 请求, 并将该请求发送到Storm中运行的Topology, 等待接收 Topology 发送的处理结果, 并将该结果返回给发送请求的客户端。
-
DRPC设计目的:
- 为了充分利用Storm的计算能力实现高密度的并行实时计算。
- (Storm 接收若干个数据流输入, 数据在Topology 当中运行完成, 然后通过DRPC将结果进行输出。)
- 为了充分利用Storm的计算能力实现高密度的并行实时计算。
-
客户端通过向 DRPC 服务器发送执行函数的名称以及该函数的参数来获取处理结果。
- 实现该函数的拓扑使用一个DRPCSpout 从 DRPC 服务器中接收一盒函数调用流。 DRPC 服务器 会为每个函数调用都标记一个唯一的id。
- 随后拓扑会执行函数来计算结果, 并在拓扑的最后使用一个名为 ReturnResults 的 Bolt 连接到 DRPC服务器, 根据函数调用的结果返回。


-
-
-
Storm 容错机制
-
集群节点宕机
-
Nimbus服务器
- 单点故障的话后续版本可以通过将nimbus.host: 改为 nimbus.seeds: ["node01", "node02"] 来设置备份节点解决
-
非Nimbus服务器
- 故障时, 该节点上所有Task任务都会超时, Nimbus会将这些Task重新分配到其他服务器上运行
-
-
进程挂了
- Worker
- 挂掉时, Supervisor 会重新启动这个进程。
- 如果启动过程中仍然一直失败, 并且无法向Nimbus发送心跳, Nimbus会将该Worker重新分配到其他服务器上
- Supervisor
- 无状态
- 所有的状态信息都存放在Zookeeper中管理
- 快速失败
- 每当遇到任何异常情况, 都会自动毁灭
- 无状态
- Nimbus
- 无状态
- 快速失败
- Worker
-
消息的完整性
- 从Spout中发出的Tuple, 以及基于他所产生的Tuple
- 由这些消息构成了一颗tuple树
- 当这颗tuple树发送完成, 并且树当中每一条消息都被正确地处理, 就表明spout发送的消息被完整地处理过了, 即该消息具有完整性。(Completation 有兴趣的可以去Flink-client 看看 源码中 CompletationFuture的使用)
-
消息完整性的实现机制
-
Acker
- Storm的拓扑中特殊的一些任务
- 负责跟踪每个Spout发出的Tuple的DAG (有向五环图)
-
-
-
Storm 并发机制
-
基本组件
-
Worker - 进程
- 一个Topology会包含一盒或多个Worker (每个Worker进程只能从属于一个特定的Topology)
- 这些Worker进程会并行跑在集群中的不同服务器上, 即一个Topology其实是由并行运行在Storm集群中多台服务器上的进程所组成
-
Executor - 线程
- Executor是由Worker进程中生成的一个线程
- 每个Worker进程中会运行拓扑当中的一个或多个Executor线程
- 一个Executor线程中可以执行一个或多个Task任务, 但是这些Task任务都是对应着同一个组件(Spout、Bolt)
-
Task
- 实际执行数据处理的最小单元
- 每个task即为一个Spout或者一个Bolt
- Task数量在整个Topology声明周期中保持不变, Executor数量key变化或手动调整
- 默认情况下, Task数量和Executor是相同的, 即每个Executor线程中默认运行一个Task任务
-
设置参数
-
Worker进程数
- Config.setNumWorkers(int workers)
-
Executor线程数
- TopologyBuilder.setSpout(String id, IRichSpout spout, Number parallelism_hint)
- TopologyBuilder.setBolt(String id, IRichBolt bolt, Number parallelism_hint)
- parallelism_hint(并行量) 即为 executor 线程数
-
Task数量
- ComponentConfigurationDeclarer.setNumTasks(Number val)
-
-
-
Rebalance - 重平衡
- 动态调整Topology拓扑的Worker进程数量、以及Executor线程数量
- 两种调整方式: 通过Storm UI && 通过Storm CLI
-
-
Storm 通信机制
-
Worker进程间的数据通信
-
ZMQ
- ZeroMQ 开源的消息传递框架, 并不是消息队列(MessageQueue)
-
Netty
-
Nettty 是基于NIO(Not Blocked Input Output)的网络框架(是对NIO包的一种封装, 因为原生API不是很好用),更加高效。
-
Storm 0.9版本之后使用Netty是因为ZMQ的license和Storm的license不兼容。
-
-
-
Worker内部的数据通信
- Disruptor(干扰者? wtf)
- 实现了 “队列” 的功能
- 可以理解为一种时间监听或者消息处理机制, 即在队列当中一边由生产者放入消息数据, 另一边消费者并行去除消息数据进行处理
- 实现了 “队列” 的功能
- Disruptor(干扰者? wtf)
-
-
Storm Grouping -- 流数据流分组(数据分发策略)
-
Shuffle Grouping
- 随机分组, 随机派发stream中的tuple, 保证每个bolt task接收到的tuple数目大致相同。
- 轮询, 平均分配
-
Fields Grouping
- 按字段分组, 比如, 按 "user-id" 分组, 那么具有同样"user-id" 的 tuple 会被分到相同的Bolt中的一个, 而不同的"user-id" 则可能会被分配到不同的task
-
All Grouping
- 广播发送, 对于每一个tuple, 所有的bolts都会收到
-
Global Grouping
- 全局分组, 把tuple分配给task id 最低的task
-
None Grouping
- 不分组, 这个分组的意思是说stream不关系到底怎样分组。 目前这种分组和shuffle grouping是一样的效果。 有一点不同的是storm会把使用none grouping的这个bolt放到这个bolt的订阅者同一个线程里面去执行 (未来Storm如果可能的话会这样设计)
-
Direct Grouping
- 指向型分组, 这是一种比较特别的分组方法, 用这种分组意味着消息(tuple) 的发送者指定由消息接收者的哪个task处理这个消息。 只有被声明为Direct Stream 的消息流可以声明这种分组方法。
- 这种消息tuple必须使用 emitDirect 方法来发射。 消息处理者可以通过TopologyContext 来获取处理它的task的id(OutputCollector.emit 方法也会返回task的id)
-
Local or shuffle Grouping
- 本地或随机分组。 如果目标bolt有一个或者多个task与源bolt的task在同一个工作进程中, tuple将会被随机发送给这些同进程中的tasks。 否则, 和普通的Shuffle Grouping行为一致
-
CustomGrouping
- 自定义, 相当于mapreduce那里自己去实现一个partition一样。
-
Flume + Kafka + Storm 架构设计

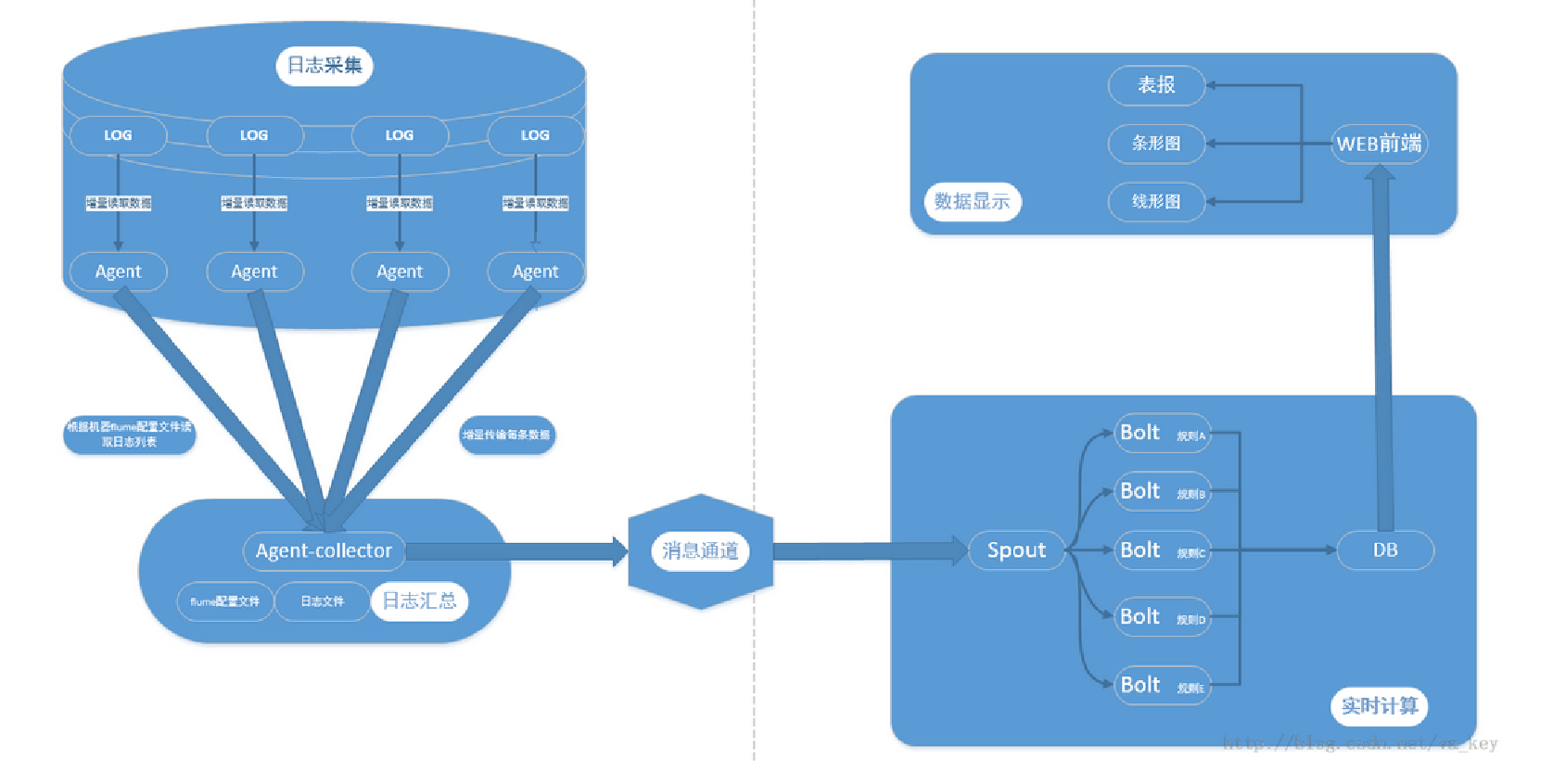
-
采集层: 实现日志收集, 使用负载均衡策略
-
消息队列: 作用是解耦及做不同速度系统缓冲
-
实时处理单元: 用Storm来进行数据处理, 最终数据流入DB中
-
展示单元: 数据可视化, 使用WEB框架展示

