关于英文文章统计字母单词百分比代码问题总结
代码在此处
第一阶段:输出某个英文文本文件中 26 字母出现的频率 - zrswheart - 博客园 (cnblogs.com)
第二阶段:输出单个文件中的前 N 个最常出现的英语单词 - zrswheart - 博客园 (cnblogs.com)
问题一:找不到英文文章文件
在一开始输入文章地址 这个地方的时候
这个地方的时候
输入的是D盘某某文件夹然后就会报错
最直接简单的解决方法:
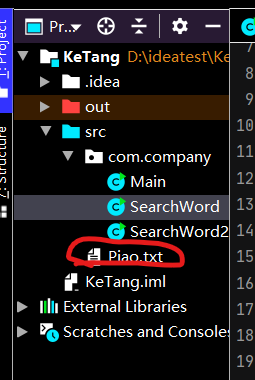
直接把TXT文件放在src文件夹下面,注意设置名称为英文不容易报错,然后可能会出现乱码的情况,那就是自己的编辑器的问题,在设置里面设置一下即可
问题二:split 方法

将一个字符串分割为子字符串,然后将结果作为字符串数组返回。
1.按空格分开
public static void main(String[] args) {
String a = "hello world wk";
String[] a1 = a.split(" ");
System.out.println("a1-->"+Arrays.toString(a1));
}
结果是:a1-->[hello, world, wk]
2.按 | 隔开
String a1="北京|北京市|海淀区|科技大厦";
String[] splitAddress=a1.split("\\|");
System.out.println(Arrays.toString(splitAddress));
结果是:[北京, 北京市, 海淀区, 科技大厦]
3按*隔开
String a1="北京*北京市*海淀区*科技大厦";
String[] splitAddress=a1.split("\\*");
System.out.println(Arrays.toString(splitAddress));
结果是:[北京, 北京市, 海淀区, 科技大厦]
4.按@隔开
String a1="北京@北京市@海淀区@科技大厦";
String[] splitAddress=a1.split("@");
System.out.println(Arrays.toString(splitAddress));
结果是:[北京, 北京市, 海淀区, 科技大厦]
二。多个标记隔开
String a1="北京^北京市@海淀区#科技大厦 wk";
String[] splitAddress=a1.split("\\^|@|#| ");
System.out.println(Arrays.toString(splitAddress));
结果是:[北京, 北京市, 海淀区, 科技大厦, wk]
三。split里面的limit用法,
就是把字符串分成几段。
limit参数指定几个,输出几个,最多为 8 个
String a1="北京 北京市 海淀区 科技大厦 wk";
String[] str=a1.split(" ",3);
System.out.println(Arrays.toString(str));
结果是:[北京, 北京市, 海淀区 科技大厦 wk]
总结:
(1)split表达式,其实就是一个正则表达式。 ^ | 等符号在正则表达式中属于一种有特殊含义的字符,如果使用此种字符作为分隔符,必须使用转义符即\加以转义*。
(2)如果使用多个分隔符则需要借助 | 符号
问题三:增强for循环

for(数据类型 变量名 : 数组或者集合对象)
而图中的这一句for(Map.Entry<String, Integer> map : list) 就是直接输出已经转成list型的所有值
该方法在第一阶段的代码中输出所有字母的比例很合适
如下图

但是在阶段二中输出固定输入的N个单词就不适用
于是我在内层加了一个计数器i

就可以控制啦



