DIN(Deep Interest Network of CTR) [Paper笔记]
背景
经典MLP不能充分利用结构化数据,本文提出的DIN可以(1)使用兴趣分布代表用户多样化的兴趣(不同用户对不同商品有兴趣)(2)与attention机制一样,根据ad局部激活用户兴趣相关的兴趣(用户有很多兴趣,最后导致购买的是小部分兴趣,attention机制就是保留并激活这部分兴趣)。
评价指标
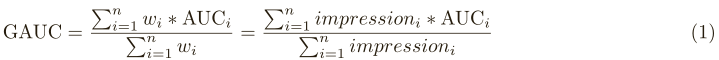
按照user聚合样本,累加每个user组的sum(shows*AUC)/sum(shows)。paper说实验表明GAUC比AUC准确稳定。
DIN算法
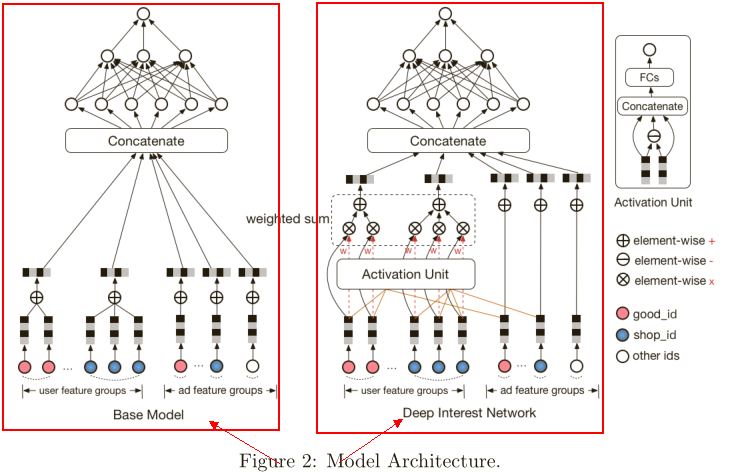
左边是基础模型,也是实验的对照组,paper介绍大部分线上模型使用的是左面的base model。user和ad的特征做one_hot编码,为了定长采用池化层,网络结构是全连接的MLP。
右边是DIN,不同是为了处理上述两个数据结构,输入层增加了激活单元。
激活函数
激活函数g如下所示。

其中,vi代表用户的行为编码id,vu代表用户的兴趣编码id,va代表ad的编码id,wi代表对于某个候选广告,attention机制中行为id对总体兴趣编码id的贡献度。
激活函数采用本文提出的Dice,如下yi所示。
其中,pi和 mini batch数据的期望和方差,如下所示。

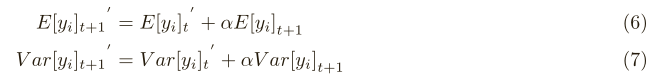
Dice激活函数的优点是根据minibatch的期望方差自适应调整校正点,而Relu采用硬校正点0。
对照组的PRelu(又叫leaky Relu)激活函数如下所示。

正则化
优化方法梯度下降法,如下所示。
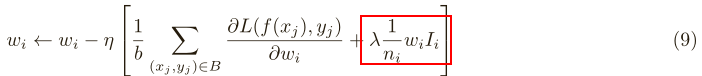
其中,Ii如下所示。
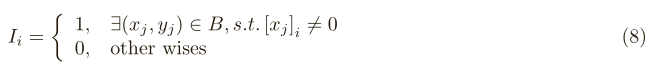
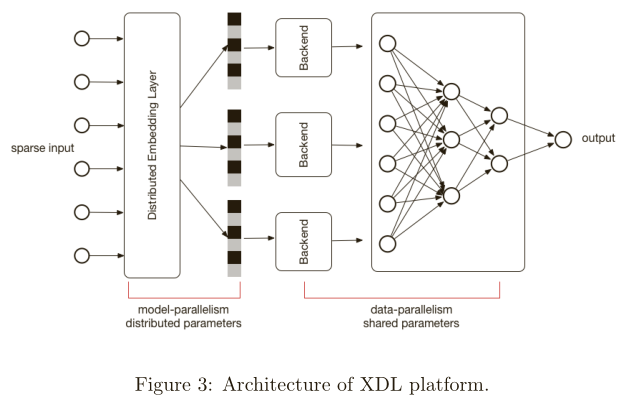
架构实现
实现基于XDL平台,分为三部分:分布式特征编码层,本地后台(Tensorflow)和沟通机制(MPI)。如下图所示。
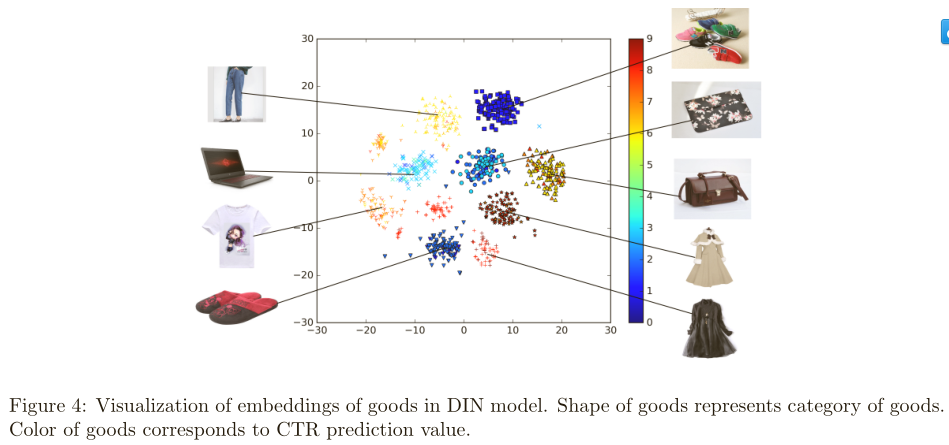
实验结果
1)特征编码:聚类效果明显,而且红色的CTR最高,DIN模型能够正确的辨别商品是否符合用户的兴趣,如下图所示。
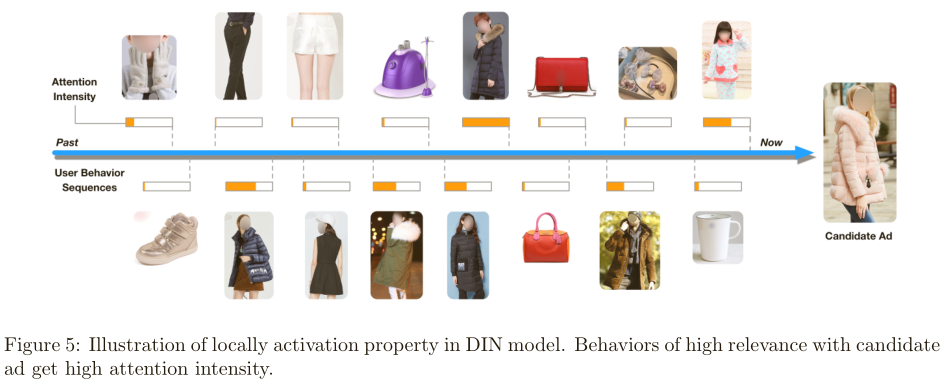
2)局部激活效果:与候选广告越相关的行为的attention分数越高,如下图所示。
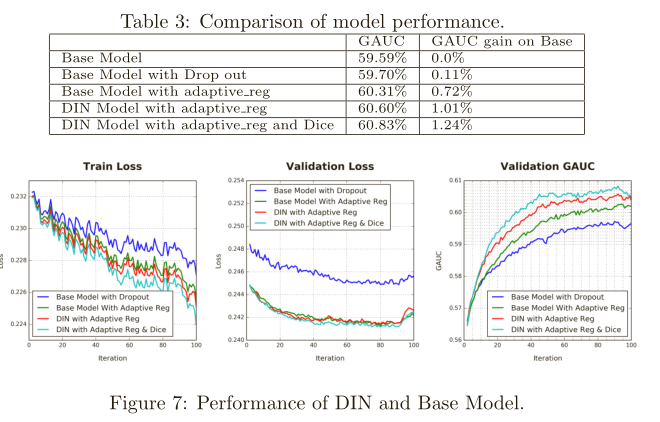
3)正则化效果:DIN效果最好,如下图所示。

4)与基础MLP模型相比:DIN最佳,如下图所示。
参考Paper:Deep Interest Network for Click-Through Rate Prediction

 浙公网安备 33010602011771号
浙公网安备 33010602011771号