DNN个性化推荐模型
1 推荐技术
1)协同过滤:
(1)基于user的协同过滤:根据历史日志中用户年龄,性别,行为,偏好等特征计算user之间的相似度,根据相似user对item的评分推荐item。缺点:新用户冷启动问题和数据稀疏不能找到置信的相似用户进行推荐。
(2)基于item的协同过滤:根据item维度的特征计算item之间的相似度,推荐user偏好item相似的item。
(3)基于社交网络:根据user社交网络亲密关系,推荐亲密的user偏好的item。
(4)基于模型:LR模型,user和item等维度特征输入给模型训练,label是show:clk,根据预估的pctr进行推荐。DNN模型:见下面。
2)基于内容的过滤:抽取item的有意义描述特征,推荐user偏好item相似度高的item,个人觉得像基于item的过滤。
3)组合推荐:根据具体问题,组合其它几种技术进行推荐。
2 DNN推荐模型
1)特征工程:
用户维度:用户id,性别,年龄和职业。
电影维度:电影id,类型和名称。
2)模型设计:
user和item维度特征embedding,各自的全连接网络结构,最顶层是两个维度网络结构的cosin距离代表相似度。所以为user推荐相似度高的item。
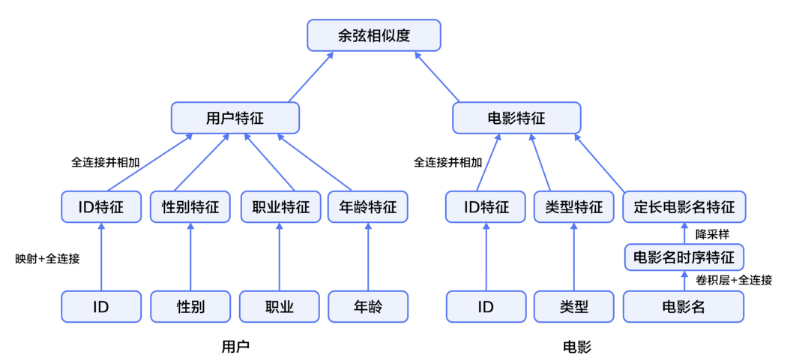
(1) user维度的网络结构,分别将四个特征embedding,并输入全连接层;再将四个全连接输入到全连接层,并定义激活函数为tanh(代码为paddle开源工具)。


(2)item维度网络结构,同user维度一样,分别将三个特征embedding后输入全连接层,再相加输入全连接层(注意title用了cnn)。
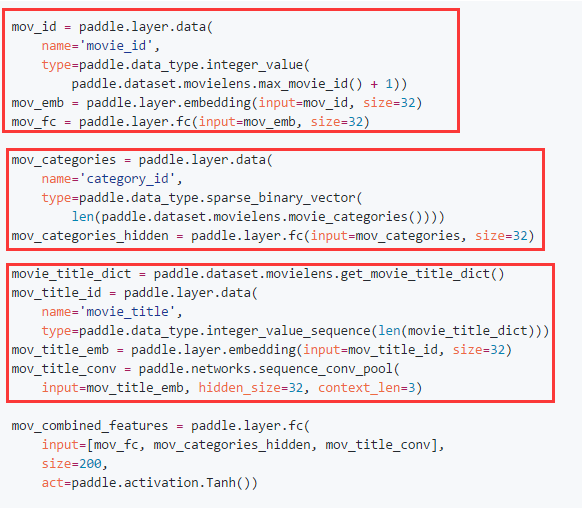
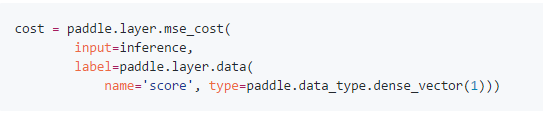
(3)最顶层将user和item连接,cosin距离代表了user和item的相似度,并且损失函数为mse。

(4)训练过程:数据通过provider读到模型,train的dnn网络结构在 trainer_config.py中配置。
![]()
![]()
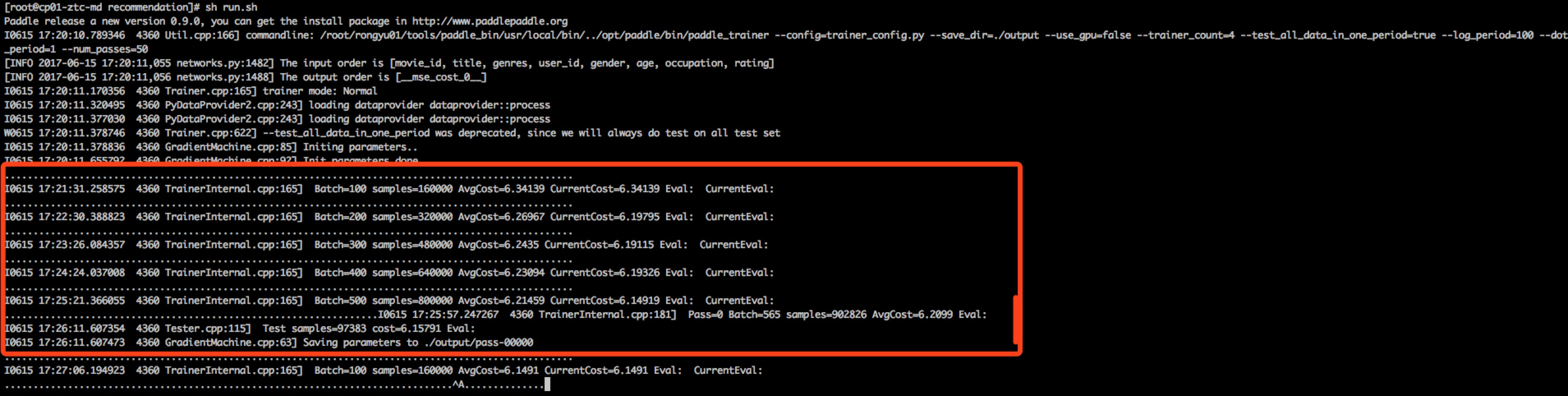
每轮的训练结果保存在output目录,pass-00000/ pass-00001/ pass-00002/ pass-00003/ pass-00004/ pass-00005/
选择损失最小的一轮part打开,每层权重参数和bias参数如下:

参数是压缩编码的格式,读取具体数值必须通过python工具包译码读取。
Code:
import paddle.v2 as paddle paddle.init(use_gpu=False) movie_info = paddle.dataset.movielens.movie_info() print movie_info.values()[0] user_info = paddle.dataset.movielens.user_info() print user_info.values()[0] uid = paddle.layer.data( name='user_id', type=paddle.data_type.integer_value( paddle.dataset.movielens.max_user_id() + 1)) usr_emb = paddle.layer.embedding(input=uid, size=32) usr_fc = paddle.layer.fc(input=usr_emb, size=32) usr_gender_id = paddle.layer.data( name='gender_id', type=paddle.data_type.integer_value(2)) usr_gender_emb = paddle.layer.embedding(input=usr_gender_id, size=16) usr_gender_fc = paddle.layer.fc(input=usr_gender_emb, size=16) usr_age_id = paddle.layer.data( name='age_id', type=paddle.data_type.integer_value( len(paddle.dataset.movielens.age_table))) usr_age_emb = paddle.layer.embedding(input=usr_age_id, size=16) usr_age_fc = paddle.layer.fc(input=usr_age_emb, size=16) usr_job_id = paddle.layer.data( name='job_id', type=paddle.data_type.integer_value( paddle.dataset.movielens.max_job_id() + 1)) usr_job_emb = paddle.layer.embedding(input=usr_job_id, size=16) usr_job_fc = paddle.layer.fc(input=usr_job_emb, size=16) usr_combined_features = paddle.layer.fc( input=[usr_fc, usr_gender_fc, usr_age_fc, usr_job_fc], size=200, act=paddle.activation.Tanh()) mov_id = paddle.layer.data( name='movie_id', type=paddle.data_type.integer_value( paddle.dataset.movielens.max_movie_id() + 1)) mov_emb = paddle.layer.embedding(input=mov_id, size=32) mov_fc = paddle.layer.fc(input=mov_emb, size=32) mov_categories = paddle.layer.data( name='category_id', type=paddle.data_type.sparse_binary_vector( len(paddle.dataset.movielens.movie_categories()))) mov_categories_hidden = paddle.layer.fc(input=mov_categories, size=32) movie_title_dict = paddle.dataset.movielens.get_movie_title_dict() mov_title_id = paddle.layer.data( name='movie_title', type=paddle.data_type.integer_value_sequence(len(movie_title_dict))) mov_title_emb = paddle.layer.embedding(input=mov_title_id, size=32) mov_title_conv = paddle.networks.sequence_conv_pool( input=mov_title_emb, hidden_size=32, context_len=3) mov_combined_features = paddle.layer.fc( input=[mov_fc, mov_categories_hidden, mov_title_conv], size=200, act=paddle.activation.Tanh()) inference = paddle.layer.cos_sim(a=usr_combined_features, b=mov_combined_features, size=1, scale=5) cost = paddle.layer.mse_cost( input=inference, label=paddle.layer.data( name='score', type=paddle.data_type.dense_vector(1))) parameters = paddle.parameters.create(cost) trainer = paddle.trainer.SGD(cost=cost, parameters=parameters, update_equation=paddle.optimizer.Adam(learning_rate=1e-4)) feeding = { 'user_id': 0, 'gender_id': 1, 'age_id': 2, 'job_id': 3, 'movie_id': 4, 'category_id': 5, 'movie_title': 6, 'score': 7 } def event_handler(event): if isinstance(event, paddle.event.EndIteration): if event.batch_id % 100 == 0: print "Pass %d Batch %d Cost %.2f" % ( event.pass_id, event.batch_id, event.cost) trainer.train( reader=paddle.batch( paddle.reader.shuffle( paddle.dataset.movielens.train(), buf_size=8192), batch_size=256), event_handler=event_handler_plot, feeding=feeding, num_passes=2) import copy user_id = 234 movie_id = 345 user = user_info[user_id] movie = movie_info[movie_id] feature = user.value() + movie.value() infer_dict = copy.copy(feeding) del infer_dict['score'] prediction = paddle.infer(inference, parameters=parameters, input=[feature], feeding=infer_dict) score = (prediction[0][0] + 5.0) / 2 print "[Predict] User %d Rating Movie %d With Score %.2f"%(user_id, movie_id, score)
备注 youtube推荐模型
1)大规模推荐的系统由于数据量太大,不能直接进行全连接的排序,所以一般大致分为两个阶段:百万级到百级的触发过滤出一部分,再进行细致排序截断阶段。
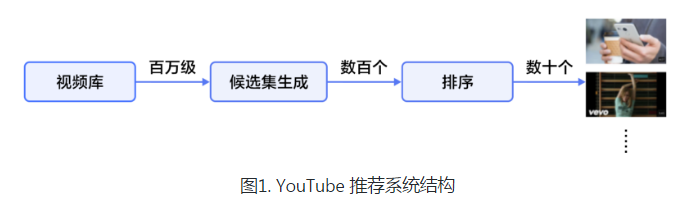
2)百万级到百级的触发过滤,模型采用MLP,训练时softmax做多分类,预测时计算与所有视频的相似度,取top K个视频。我认为label可以是show:clk,类似于LR进行模型推荐。
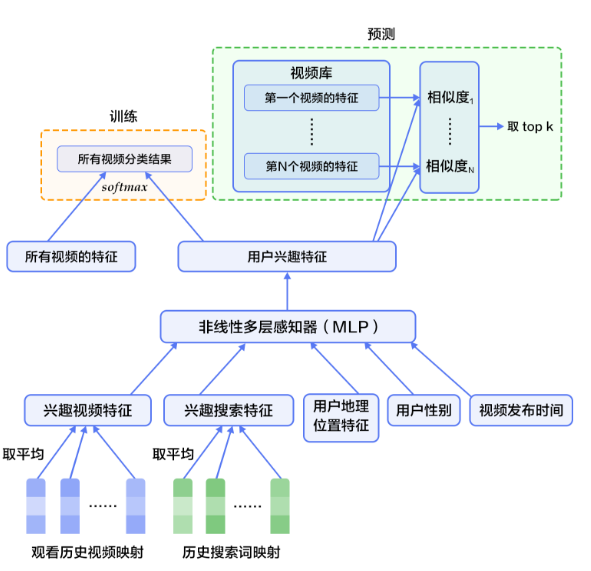
3)排序截断阶段:网络结构与触发阶段一样,只是最顶层是LR,做排序;特征工程方面可以更细致,比如视频ID,上次点击时间等等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号