GBDT与LR融合提升广告点击率预估模型
1GBDT和LR融合
LR模型是线性的,处理能力有限,所以要想处理大规模问题,需要大量人力进行特征工程,组合相似的特征,例如user和Ad维度的特征进行组合。
GDBT天然适合做特征提取,因为GBDT由回归树组成所以, 每棵回归树就是天然的有区分性的特征及组合特征,然后给LR模型训练,提高点击率预估模型(很多公司技术发展应用过,本人认为dnn才是趋势)。
例如,输入样本x,GBDT模型得到两颗树tree1和tree2,遍历两颗树,每个叶子节点都是LR模型的一个维度特征,在求和每个叶子*权重及时LR模型的分类结果。
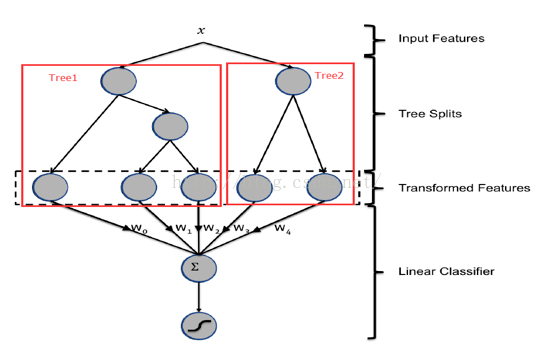
2广告长尾性
1)gbdt和随机森林rf的对比:
rf主要选择对大多数样本有区分度的特征;gbdt的过程,前面树针对大多数样本有区分 ,后面树针对残差依然较大的样本,即针少数的对长尾样本。更适合ctr模型预估。
2)针对广告的长尾性,广告id这个特征就很重要,比如:某少量长尾用户就喜欢点某类广告主的广告。
方案:分别针对ID类和非ID类建树,ID类树:用于发现曝光充分的ID对应的有区分性的特征及组合特征;非ID类树:用于曝光较少的广告。
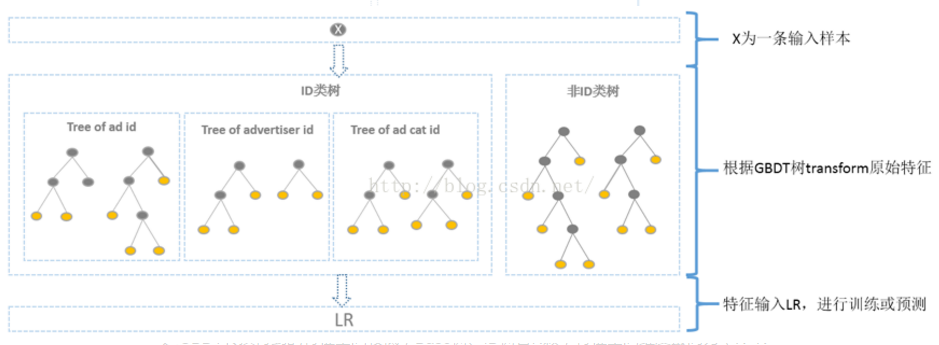
3gbdt得到的特征维度
维度会降低,总维度是所有叶子节点数之和。
4gdbt模型原理
1)BT回归树
年龄预测:简单起见训练集只有4个人,A,B,C,D,他们的年龄分别是14,16,24,26。其中A、B分别是高一和高三学生;C,D分别是应届毕业生和工作两年的员工。
1BT回归树:显然容易过拟合,特征太细了,只要叶子允许够多可以达到百分百的准确率,但性能并不好。
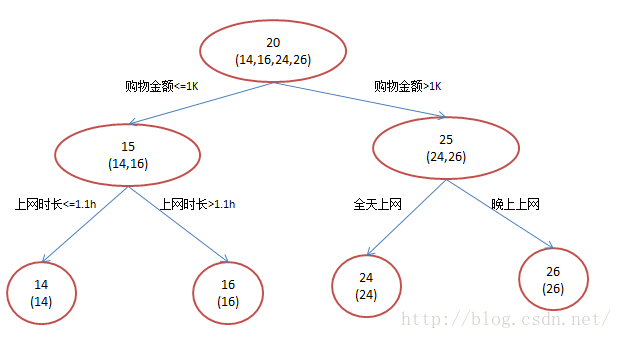
2)GDBT模型
(1)最小化均方误差特,确定特征:购物金额的分割点:
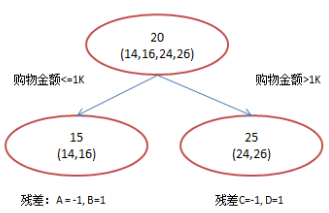
(2)计算残差=预测值-真实值,真实值是叶子节点均值,特征:百度知道提问:
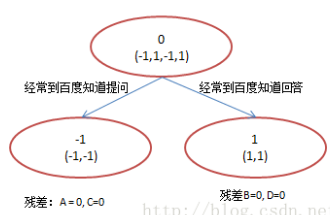
(3)残差为0,停止迭代,输出预测结果,真实值=初始值+残差之和
A: 14岁高一学生,购物较少,经常问学长问题;预测年龄A = 15 – 1 = 14
B: 16岁高三学生;购物较少,经常被学弟问问题;预测年龄B = 15 + 1 = 16
C: 24岁应届毕业生;购物较多,经常问师兄问题;预测年龄C = 25 – 1 = 24
D: 26岁工作两年员工;购物较多,经常被师弟问问题;预测年龄D = 25 + 1 = 26
5 GDBT和Adaboost公式算法层级的解释
Ada boost是根据分错的样本
GDBT是拟合梯度(残差)
(1)梯度下降和梯度提升的区别联系
梯度下降:参数=迭代的增量累加和,特征维度
梯度提升:参数=迭代的函数增量累加和,分类器(回归树or罗辑回归)维度
所以boosting就是一个加法模型![]()


(2) gradient boosting tree (Gradient Boosting = Gradient Descent + Boosting)
目标函数:![]()

梯度:对分类器求导数

eg:
1 m个样本集:![]() ,label改写为残差
,label改写为残差![]() (残差就是目标函数最小化1/2*
(残差就是目标函数最小化1/2*![]() 的梯度)
的梯度)
 ,label改写为残差
,label改写为残差 (残差就是目标函数最小化1/2*
(残差就是目标函数最小化1/2* 的梯度)
的梯度) 2 训练,相当于回归树拟合梯度,最后模型一个函数加法模型
(3) Adaboost
CART回归树分类器对样本训练分类,等到分类器误差
1根据分类器误差计算每个分类器对权重
2根据分类器误差计算每个样本的权重
输出加法模型,累加每个分类器权重*分类器函数

总结:
原则1:没有免费的午餐,没有一个模型在所有数据集上优于另一个模型。
原则2:剃姆刀原则,效果一样的情况下选择简单的模型。eg LR和GDBT效果一样的情况下,尽量选择LR。
参考

 浙公网安备 33010602011771号
浙公网安备 33010602011771号