
音视频中的一些基本概念
1、YUV
YUV是一种颜色编码方法,Y表示明亮度(Luminance、Luma),U和V表示色度、浓度(Chrominance、Chroma)
Y表示亮度分量,也就是灰度图
U(Cb)表示色度分量,是照片蓝色部分去掉亮度
V(Cr)表示色度分量,是照片红色部分去掉亮度
1.1、YUV的采样格式
采集图像视频时是如何获取每个像素的YUV分量的,常见采样格式有:
YUV444:表示完全采样,每个Y对应一组UV分量
YUV422:表示2:1的水平采样,垂直完全采样,每两个Y共用一组UV分量
YUV420:表示2:1的水平采样,2:1的垂直采样,每四个Y共用一组UV分量
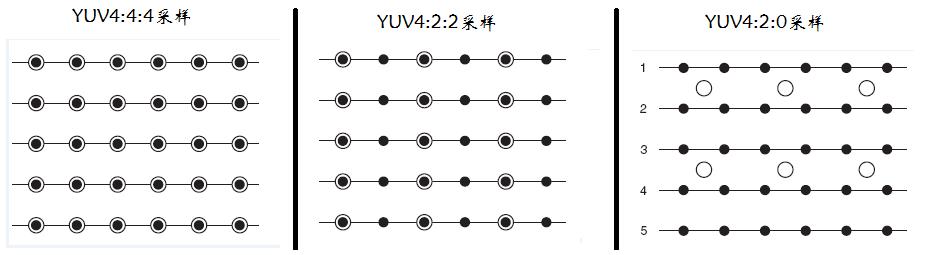
以上是UV分量的共享方式
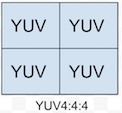
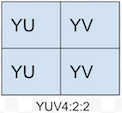
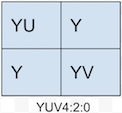
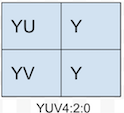
上面四幅图是实际的UV分量的采样方式
1.2、YUV的存储格式
YUV分量在内存中存储的顺序
紧缩格式(packed formats):将Y、U、V存储为Macro Pixels阵列,和RGB类似,分量是混合在一起的,适用于YUV444
平面格式(planar formats):将Y、U、V三个分量分别存放在不同的阵列当中
1.2.1、YUV422的三种存储方式
YUVY

UYVY

YUV422P

1.2.2、YUV420的四种存储方式
YV12、YU12

NV12、NV21
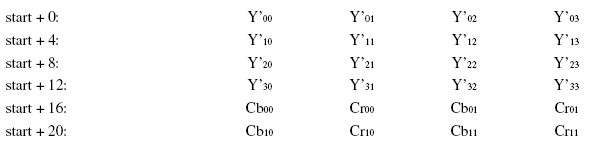
NV12是UV交替存储,NV21是VU交替存储
参考:YUV详解数据和格式_Alex_designer的博客-CSDN博客_yuv数据
1.3、YUV内存对齐
为了实现内存对齐,每一行像素在内存中占用的空间并不是图像的宽度
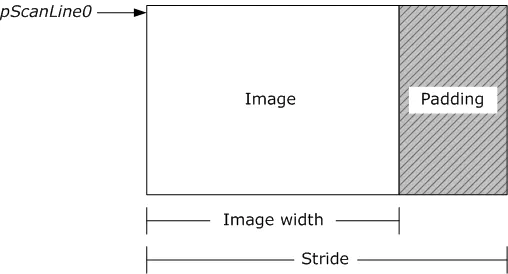
上图中的stride是内存对齐之后的长度,有很多别名,比如pitch、linesize,它的出现主要是为了提升数据读取的速率。
如果图像的宽度是内存对齐长度的整数倍,那么间距就会等于宽度;如果宽度不等于内存对齐的整数倍,那么间距就是大于宽度的最小内存对齐数。
在做数据拷贝时需要一行一行复制,下一行的数据的起始位置是上一行的起始位置加上stride,如果是YV12或者是YU12,拷贝UV通道时需要将stride除以2。
参考:YUV格式解释,步长(间距)解释 - 简书 (jianshu.com)
为什么解码失败显示绿屏?解码出了YUV数据之后需要转化为RGB输出,如果解码失败则YUV值都为0,根据转化公式转化出的RGB颜色就为0
2、分辨率、帧率、码率
分辨率指图像大小
帧率FPS每秒显示帧数量(frames per second)
码率Bps(bits per second)单位时间播放连续媒体的比特数量,文件大小 = bps * time
采样率:每秒采样点个数
3、I P B帧
I帧:关键帧,采用帧内压缩技术,解码时只需要本帧数据就可以完成
P帧:向前参考帧,采用帧间压缩技术,P帧表示这一帧跟之前的关键帧或者P帧的差别
B帧:双向参考帧,采用帧间压缩技术,通过前后画面与本帧数据的叠加取得最终画面,压缩率最高
H264 IDR帧:Instance Decode Refresh,IDR帧是I帧,但I帧不一定是IDR帧;IDR帧是为了解码的重同步,解码器解码到IDR图像时,立即将参考帧队列清空,重新查找参数集,开始新的序列;IDR之后的图像不能引用IDR帧之前的内容,这样就可以获得重同步的机会。IDR帧是一个GOP的首个I帧,重新开始一个序列,可以提供随机访问能力,所以在H264中必须要有IDR
H264 GOP:group of picture,序列,一个序列就是一段内容差异不太大的图像编码后生成的一串数据流,运动变化少时,一个序列可以很长;运动变化多时一个序列可能就会比较短
H264 SPS:Sequence Parameter Set 序列参数集,保存了一组编码视频序列的全局参数,包括帧数、参考帧数据、解码图像尺寸等信息,
H264 PPS:Picture Parameter Set 图像参数集,存放熵编码模式选择标识、片组数目等内容。SPS和PPS通常保存在H264流的前两个NALU中,一组帧之前首先要收到SPS和PPS;如果码流中参数发生变化,那么变化会反映在SPS和PPS中,否则解码会出错。
参考:H264的基本原理(一)------视频的基本知识_Paul_0920的博客-CSDN博客_h264基本原理
H264码流结构
参考:H264的基本原理(三)------ H264结构与码流_Paul_0920的博客-CSDN博客_h264原理
参考:《Android音视频开发》Page 397
看看avc_utils.cpp中是如何解析H264码流的

status_t getNextNALUnit( const uint8_t **_data, size_t *_size, const uint8_t **nalStart, size_t *nalSize, bool startCodeFollows) { const uint8_t *data = *_data; size_t size = *_size; // 传入参数size是当前ESQueue中的buffer大小 *nalStart = NULL; *nalSize = 0; if (size < 3) { return -EAGAIN; } size_t offset = 0; // A valid startcode consists of at least two 0x00 bytes followed by 0x01. // 先查找start code 0x000001 for (; offset + 2 < size; ++offset) { if (data[offset + 2] == 0x01 && data[offset] == 0x00 && data[offset + 1] == 0x00) { break; } } if (offset + 2 >= size) { *_data = &data[offset]; *_size = 2; return -EAGAIN; } offset += 3; // 确定起始数据位置 size_t startOffset = offset; // 以下部分是查找下一个NALU的start code for (;;) { // 先确定start code中的0x01 while (offset < size && data[offset] != 0x01) { ++offset; } if (offset == size) { if (startCodeFollows) { offset = size + 2; break; } return -EAGAIN; } // 找到0x01之后检查前两位是否为0x0000 if (data[offset - 1] == 0x00 && data[offset - 2] == 0x00) { break; } ++offset; } // 这样就找到了当前NALU的末尾位置 size_t endOffset = offset - 2; // 由于RBSP中包含有用于字节对齐的填充数据0x01 和 n位0x00,向前搜索 while (endOffset > startOffset + 1 && data[endOffset - 1] == 0x00) { --endOffset; } // 这样就找到了SODB的起始数据位置和数据大小,这时候的endOffset位置是0x01,我们在copy时并不会copy到decoder中 *nalStart = &data[startOffset]; *nalSize = endOffset - startOffset; if (offset + 2 < size) { *_data = &data[offset - 2]; *_size = size - offset + 2; } else { *_data = NULL; *_size = 0; } return OK; }
看看ESQueue中的对H264码流的处理方法
sp<ABuffer> ElementaryStreamQueue::dequeueAccessUnitH264() { const uint8_t *data = mBuffer->data(); size_t size = mBuffer->size(); Vector<NALPosition> nals; size_t totalSize = 0; size_t seiCount = 0; status_t err; const uint8_t *nalStart; size_t nalSize; bool foundSlice = false; bool foundIDR = false; ALOGV("dequeueAccessUnit_H264[%d] %p/%zu", mAUIndex, data, size); // 找到 NALU while ((err = getNextNALUnit(&data, &size, &nalStart, &nalSize)) == OK) { if (nalSize == 0) continue; // 判断NALU type,第一个字节的后5位为type unsigned nalType = nalStart[0] & 0x1f; bool flush = false; // NAL type为1或者5说明当前NALU中的数据为片数据 if (nalType == 1 || nalType == 5) { // NAL type为5,代表当前为IDR中的片 if (nalType == 5) { foundIDR = true; } if (foundSlice) { //TODO: Shouldn't this have been called with nalSize-1? // 这里涉及到Slice Data,跳过了slice header ABitReader br(nalStart + 1, nalSize); // parseUE方法是在找当前片中的第一个宏块的序列号,如果序列号为0,说明当前NALU为一个新的帧 unsigned first_mb_in_slice = parseUE(&br); // 如果序列号为0说明为新的帧,那么就将之前的数据拷贝到decoder中 if (first_mb_in_slice == 0) { // This slice starts a new frame. flush = true; } } // 将找到片flag置为true foundSlice = true; } else if ((nalType == 9 || nalType == 7) && foundSlice) { // 如果nal type 为 9 说明序列结束,如果nal type为9说明来了一个SPS,这都说明之前的帧已经结束了,我们需要将该帧拷贝到decoder中 // Access unit delimiter and SPS will be associated with the // next frame. flush = true; } else if (nalType == 6 && nalSize > 0) { // found non-zero sized SEI // 如果nal type为6,说明当前NALU为SEI ++seiCount; } if (flush) { // The access unit will contain all nal units up to, but excluding // the current one, separated by 0x00 0x00 0x00 0x01 startcodes. size_t auSize = 4 * nals.size() + totalSize; sp<ABuffer> accessUnit = new ABuffer(auSize); sp<ABuffer> sei; if (seiCount > 0) { sei = new ABuffer(seiCount * sizeof(NALPosition)); accessUnit->meta()->setBuffer("sei", sei); } #if !LOG_NDEBUG AString out; #endif size_t dstOffset = 0; size_t seiIndex = 0; size_t shrunkBytes = 0; for (size_t i = 0; i < nals.size(); ++i) { const NALPosition &pos = nals.itemAt(i); unsigned nalType = mBuffer->data()[pos.nalOffset] & 0x1f; if (nalType == 6 && pos.nalSize > 0) { if (seiIndex >= sei->size() / sizeof(NALPosition)) { ALOGE("Wrong seiIndex"); return NULL; } NALPosition &seiPos = ((NALPosition *)sei->data())[seiIndex++]; seiPos.nalOffset = dstOffset + 4; seiPos.nalSize = pos.nalSize; } // 拷贝数据前加上 start code memcpy(accessUnit->data() + dstOffset, "\x00\x00\x00\x01", 4); if (mSampleDecryptor != NULL && (nalType == 1 || nalType == 5)) { uint8_t *nalData = mBuffer->data() + pos.nalOffset; size_t newSize = mSampleDecryptor->processNal(nalData, pos.nalSize); // Note: the data can shrink due to unescaping, but it can never grow if (newSize > pos.nalSize) { // don't log unless verbose, since this can get called a lot if // the caller is trying to resynchronize ALOGV("expected sample size < %u, got %zu", pos.nalSize, newSize); return NULL; } memcpy(accessUnit->data() + dstOffset + 4, nalData, newSize); dstOffset += newSize + 4; size_t thisShrunkBytes = pos.nalSize - newSize; //ALOGV("dequeueAccessUnitH264[%d]: nalType: %d -> %zu (%zu)", // nalType, (int)pos.nalSize, newSize, thisShrunkBytes); shrunkBytes += thisShrunkBytes; } else { memcpy(accessUnit->data() + dstOffset + 4, mBuffer->data() + pos.nalOffset, pos.nalSize); dstOffset += pos.nalSize + 4; //ALOGV("dequeueAccessUnitH264 [%d] %d @%d", // nalType, (int)pos.nalSize, (int)pos.nalOffset); } } #if !LOG_NDEBUG ALOGV("accessUnit contains nal types %s", out.c_str()); #endif const NALPosition &pos = nals.itemAt(nals.size() - 1); size_t nextScan = pos.nalOffset + pos.nalSize; // 删除已拷贝的buffer memmove(mBuffer->data(), mBuffer->data() + nextScan, mBuffer->size() - nextScan); mBuffer->setRange(0, mBuffer->size() - nextScan); // 为帧加上pts int64_t timeUs = fetchTimestamp(nextScan); if (timeUs < 0LL) { ALOGE("Negative timeUs"); return NULL; } accessUnit->meta()->setInt64("timeUs", timeUs); // 将IDR帧作为syncpoint if (foundIDR) { accessUnit->meta()->setInt32("isSync", 1); } if (mFormat == NULL) { mFormat = new MetaData; if (!MakeAVCCodecSpecificData(*mFormat, accessUnit->data(), accessUnit->size())) { mFormat.clear(); } } if (mSampleDecryptor != NULL && shrunkBytes > 0) { size_t adjustedSize = accessUnit->size() - shrunkBytes; ALOGV("dequeueAccessUnitH264[%d]: AU size adjusted %zu -> %zu", mAUIndex, accessUnit->size(), adjustedSize); accessUnit->setRange(0, adjustedSize); } ALOGV("dequeueAccessUnitH264[%d]: AU %p(%zu) dstOffset:%zu, nals:%zu, totalSize:%zu ", mAUIndex, accessUnit->data(), accessUnit->size(), dstOffset, nals.size(), totalSize); mAUIndex++; return accessUnit; } // 将当前NALU中的SODB数据位置记录下来 NALPosition pos; pos.nalOffset = nalStart - mBuffer->data(); pos.nalSize = nalSize; nals.push(pos); totalSize += nalSize; } if (err != (status_t)-EAGAIN) { ALOGE("Unexpeted err"); return NULL; } return NULL; }
H265码流
H265码流和H264比较类似,H264的NALU header为一个字节,而H265的NALU header为两个字节
- forbidden_zero_bit = 0:占1个bit,与H.264相同,禁止位,用以检查传输过程中是否发生错误,0表示正常,1表示违反语法;
- nal_unit_type = 32:占6个bit,用来用以指定NALU类型
- nuh_reserved_zero_6bits = 0:占6位,预留位,要求为0,用于未来扩展或3D视频编码
- nuh_temporal_id_plus1 = 1:占3个bit,表示NAL所在的时间层ID
参考:H.264/H265码流解析_460833359的博客-CSDN博客_h265码流格式
参考:音视频基础:H265/HEVC&码流结构 - 知乎 (zhihu.com)
Audio
android中可以利用AudioRecord录制声音,录制的声音为模拟电信号,需要数字化,最常见的方法为脉冲编码调制PCM(Pluse Code Modulation),需要经历三个步骤,抽样、量化、编码,对应三个参数采样频率、采样位数、声道数。
采样率:即取样频率,每秒钟取得声音样本的次数,采样频率越高,声音的质量越好,常用采样频率不超过48KHz
采样位数:采样值或取样值,即采样样本幅度量化,用来衡量声音波动变化的参数,数值越大分辨率越高
声道数:单声道和立体声
比特率 (bit rate)= 采样率(sample rate) * 位深(Bit depth) * 声道数
duration = 文件大小 / 比特率


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术