
Selenium库详解
自动化测试工具,支持多种浏览器,在爬虫中主要用来解决JavaSript渲染的问题。 (驱动浏览器,发送一些指令,让浏览器完成一些动作)
requests urllib这些库无法正常获取网页内容时,这些网页可能是后来javascript渲染过的,用selenium可以完成渲染,获取到网页渲染完后的源代码,这样就解决了javascript渲染的网页无法获取的问题
安装:
pip3 install selenium
用法讲解
基本使用
声明浏览器对象:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Chrome()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()
browser = webdriver.Safari()
访问页面:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://www.baidu.com')
print(browser.page_source)
browser.close()
查找元素:
(比如要找输入框输入信息,找到按钮进行点击)
查找单个元素
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://www.taobao.com')
input_first = browser.find_element_by_id('q')
input_second = browser.find_element_by_css_selector('#q')
input_third = browser.find_element_by_xpath('//*[@id="q"]')
print(input_first)
print(input_second)
print(input_third)
browser.close()
输出结果为:
<selenium.webdriver.remote.webelement.WebElement (session="5c077333f76c85be9bb897e4104fd04e", element="0.7841876974650306-1")>
<selenium.webdriver.remote.webelement.WebElement (session="5c077333f76c85be9bb897e4104fd04e", element="0.7841876974650306-1")>
<selenium.webdriver.remote.webelement.WebElement (session="5c077333f76c85be9bb897e4104fd04e", element="0.7841876974650306-1")>
运行结果为u<class 'selenium.webdriver.remote.webelement.WebElement'>类型,element有一个代号,input_first,input_second,input_third三个元素的代号相同,是完全等价的,也就是说找元素的方法是相同的,下面是一些常用的方法:
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
一种通用的查找方式:
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('http://www.taobao.com')
input_1 = browser.find_element(By.ID,'q')
print(input_1)
browser.close()
输出结果为:
<selenium.webdriver.remote.webelement.WebElement (session="9b780326594b2b8e699bd3b6f4955141", element="0.44836792421187854-1")>
查找多个元素:
把element改为elements
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('http://www.taobao.com')
input_1 = browser.find_elements(By.CSS_SELECTOR,'.service-bd li')
print(input_1)
browser.close()
输出结果为:
[<selenium.webdriver.remote.webelement.WebElement (session="270374ca380ccbd97758a1ee34663986", element="0.19502462209113514-1")>, <selenium.webdriver.remote.webelement.WebElement (session="270374ca380ccbd97758a1ee34663986", element="0.19502462209113514-2")>, <selenium.webdriver.remote.webelement.WebElement (session="270374ca380ccbd97758a1ee34663986", element="0.19502462209113514-3")>, <selenium.webdriver.remote.webelement.WebElement (session="270374ca380ccbd97758a1ee34663986", element="0.19502462209113514-4")>, <selenium.webdriver.remote.webelement.WebElement (session="270374ca380ccbd97758a1ee34663986", element="0.19502462209113514-5")>, <selenium.webdriver.remote.webelement.WebElement (session="270374ca380ccbd97758a1ee34663986", element="0.19502462209113514-6")>, <selenium.webdriver.remote.webelement.WebElement (session="270374ca380ccbd97758a1ee34663986", element="0.19502462209113514-7")>, <selenium.webdriver.remote.webelement.WebElement (session="270374ca380ccbd97758a1ee34663986", element="0.19502462209113514-8")>, <selenium.webdriver.remote.webelement.WebElement (session="270374ca380ccbd97758a1ee34663986", element="0.19502462209113514-9")>, <selenium.webdriver.remote.webelement.WebElement (session="270374ca380ccbd97758a1ee34663986", element="0.19502462209113514-10")>, <selenium.webdriver.remote.webelement.WebElement (session="270374ca380ccbd97758a1ee34663986", element="0.19502462209113514-11")>, <selenium.webdriver.remote.webelement.WebElement (session="270374ca380ccbd97758a1ee34663986", element="0.19502462209113514-12")>, <selenium.webdriver.remote.webelement.WebElement (session="270374ca380ccbd97758a1ee34663986", element="0.19502462209113514-13")>, <selenium.webdriver.remote.webelement.WebElement (session="270374ca380ccbd97758a1ee34663986", element="0.19502462209113514-14")>, <selenium.webdriver.remote.webelement.WebElement (session="270374ca380ccbd97758a1ee34663986", element="0.19502462209113514-15")>, <selenium.webdriver.remote.webelement.WebElement (session="270374ca380ccbd97758a1ee34663986", element="0.19502462209113514-16")>]
结果为一个列表
查找单个元素与查找多个元素一样,唯一的不同就是element改为elements
元素的交互操作:
对获取的元素调用交互方法(比如对输入框输入文字,对按钮进行点击等)
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input = browser.find_element_by_id('q')
input.send_keys('小米8')
time.sleep(1)
input.clear()
input.send_keys('华为pro')
button = browser.find_element_by_class_name('btn-search tb-bg')
button.click()
交互动作:
将动作附加到动作链(需要引入一个ActionChains)中串行执行
from selenium import webdriver
from selenium.webdriver import ActionChains
browser = webdriver.Chrome()
url ='http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
browser.get(url)
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable')
target = browser.find_element_by_css_selector('#droppable')
actions = ActionChains(browser)
actions.drag_and_drop(source,target)
actions.perform()
执行JavaScript(一个比较万能的方法)
在做一些元素交互动作的时候,可能有一些动作没有提供api,比如进度条下拉,直接用api实现有难度,可以通过实行js来实现
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://www.taobao.com')
browser.execute_script('js语句')
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://www.taobao.com')
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
browser.execute_script('alert("down")')
获取元素信息
获取属性
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://www.taobao.com')
ele1 = browser.find_element_by_class_name('btn-search')
print(ele1)
print(ele1.get_attribute('class'))
输出结果为:
<selenium.webdriver.remote.webelement.WebElement (session="a11d0c26dd60c650a15f84340c85bef4", element="0.1796961286323151-1")>
btn-search tb-bg
获取文本值
ele1.text
获取ID,位置,标签名,大小
ele1.id
ele1.location
ele1.tag_name
ele1.size
Frame
相当于独立的网页,在父级frame中查找子集frame中的元素,需要切换到子集中的frame,否则不能进行查找,同样在子frame中也不能查找父frame
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
browser = webdriver.Chrome()
browser.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable')
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable')
print(source)
try:
logo = browser.find_element_by_class_name('logo')
except NoSuchElementException:
print('NO LOGO')
browser.switch_to.parent_frame()
logo = browser.find_element_by_class_name('logo')
print(logo)
print(logo.text)
等待
在做爬去的时候,可能有一些ajax请求,它不会管selenium(只加载一些基本的框架)是否加载完成,这样操作的话可能会引发一些问题,所以需要加一些等待,确保元素加载完毕
隐式等待
当使用了隐式等待执行测试的时候,如果webdriver没有在DOM中找到元素,将继续等待,超出设定时间后抛出异常,也就是说当元素没有立即显现的时候,隐式等待将等待一段时间再查找DOM,默认的时间是0,在网速慢的情况下,可以加个等待
from selenium import webdriver
browser = webdriver.Chrome()
#设定隐式等待的时间
browser.implicitly_wait(10)
browser.get('http://www.baidu.com')
显式等待
指定一个等待条件,再指定一个最长等待时间

浏览器的前进后退
from selenium import webdriver
import time
browser = webdriver.Chrome()
browser.get('http://www.baidu.com')
browser.get('http://www.taobao.com')
browser.get('http://www.python.org')
browser.back()
time.sleep(1)
browser.forward()
browser.close()
cookies
在爬去过程比较有用,尤其是在做一些登陆之后的爬去时

选项卡管理
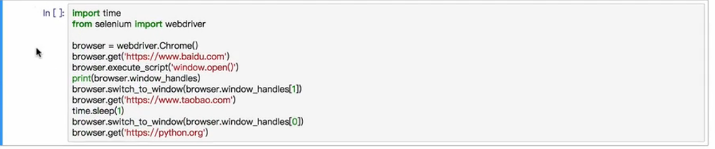
最好的方法就是通过执行js命令window.open()来打开一个新的选项卡
browser.execute_script('window.open()')
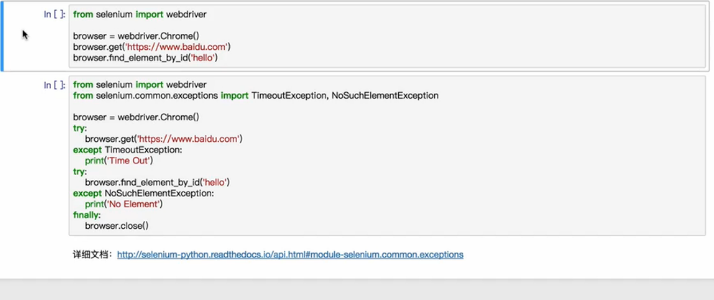
异常处理

 浙公网安备 33010602011771号
浙公网安备 33010602011771号