
西瓜书 第6章 支持向量机 读书笔记
第6章 支持向量机(Support Vector Machine, 简称SVM)
1.间隔与支持向量
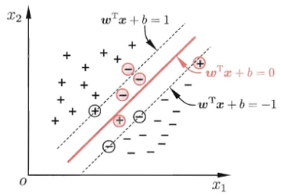
1.1 超平面(w, b)
- 存在多个划分超平面将两类训练样本分开
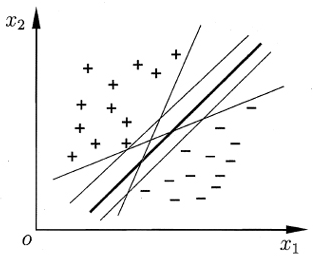
目标:粗线体那个划分超平面所产生的分类结果是最鲁棒的,对未见示例的泛化能力最强
- 线性方程
![]()
其中w为法向量,决定超平面的方向,b为位移项,决定超平面与原点之间的距离
- 样本空间中任意点到超平面的距离
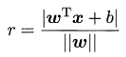
1.2 支持向量(super vector)
- 就是距离超平面最近的几个训练样本点
- 且使下边任一式子的等号成立
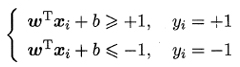
1.3 间隔(margin)
- 两个异类支持向量到超平面的距离之和
![]()
1.4 最大间隔(maximum margin)
- 对应的划分超平面
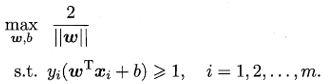
- 支持向量机的基本型
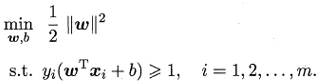
1.5 归纳支持向量机与间隔

2.对偶问题
2.1 凸二次规划(convex quadratic programming)问题
2.2 对偶问题(dual problem)
2.2.1 更高效求解参数w和b的方法:拉格朗日乘子法
- 对SVM基本型式子的每条约束添加大于等于零的拉格朗日乘子,得到该问题的拉格朗日函数
![]()
- 令L(ω,b,α)对ω和b的偏导为零
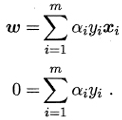
- 将L(ω,b,α)中的ω和b消去,得到SVM基本型式子的对偶问题
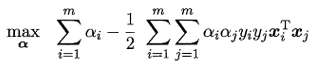
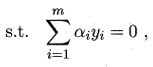
![]()
2.2.2 KKT(Karush-Kuhn-Tucker)条件
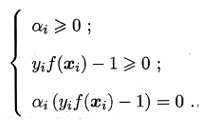
2.2.3 如何求解对偶问题中的α?
当做二次规划问题来解
1)算法:二次规划算法
- 缺点:问题的规模正比于训练样本数,这会在实际任务重造成很大的开销
2)算法:SMO(Sequential Minimal Optimization)算法
- 选取一对需更新的变量αi和αj
- 固定αi和αj以外的参数,求解对偶问题式中获得更新后的αi和αj
- 不断执行如上两个步骤直至收敛
![]()
其中,
![]()
2.2.4 如何确定偏移项b?
更鲁棒的做法:使用所有支持向量求解的平均值
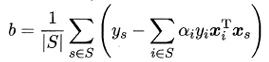
其中,
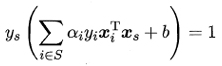
![]() 为所有支持向量的下表集
为所有支持向量的下表集
2.3 支持向量机的一个重要性质
训练完成后,大部分的训练样本都不需要保留,最终模型仅与支持向量有关
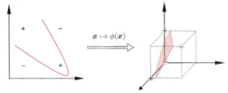
3.核函数
对非线性可分问题,可将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分
例如,异或问题与非线性映射
3.1 核函数(kernel function)
3.2.1 令Ф(x)表示将x映射后的特征向量
- 其对偶问题
![]()
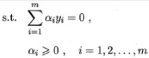
- 由于特征空间维数可能很高,甚至可能是无穷维,因此直接计算特征向量內积通常是困难的
- 设想这样一个函数
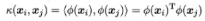
- 新式子
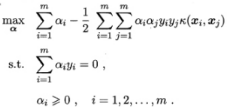
函数k(.,.)就是核函数
3.2.2 支持向量展式(support vector expansion)
- 模型最优解可通过训练样本的核函数展开
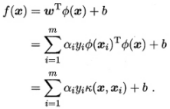
3.2.3 核函数定理
- 核矩阵(kernel martix)K总是半正定的
- 定理表明,只要一个对称函数所对应的核矩阵半正定,它就能作为核函数使用
- 事实上,对于一个半正定核矩阵,总能找到一个与之对应的映射
- 任何一个核函数都隐式地定义了一个称为“再生核希尔伯特空间”(Reproducing Kernel Hilbert Space, 简称RKHS)的特征空间
3.2.4 常用的核函数
- 线性核
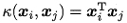
- 多项式核
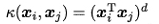
d=1时退化为线性核,d≥1为多项式的次数
- 高斯核,亦称RBF核
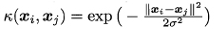
σ> 0为高斯核的带宽(width)
- 拉普拉斯核
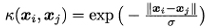
σ> 0
- Sigmoid核
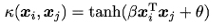
Tanh为双曲正切函数,β> 0,θ< 0
3.2 注意点
- 特征空间的好坏对支持向量机的性能至关重要
- “核函数选择”成为支持向量机的最大变数
4.软间隔与正则化
4.1 硬间隔(hard margin)
要求所有样本均满足约束,即所有样本都必须划分正确
4.2 软间隔(soft margin)
- 解决现实任务:很难确定合适的核函数使得训练样本在特征空间中线性可分,或者是否过拟合
- 缓解的一个办法:允许支持向量机在一些样本上出错
允许某些样本不满足约束
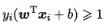
不满足约束的样本应尽可能少
- 新的优化目标函数为
![]()
其中,
C > 0是一个常数,当C为无穷大时,迫使所有样本均满足约束;当C取有限值时,允许一些样本不满足约束
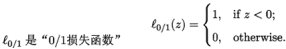
4.3 替代损失(surrogate loss)
4.3.1 替代损失函数比0/1损失函数一般具有较好的数学性质
- 凸的连续函数
- 0/1损失函数的上界
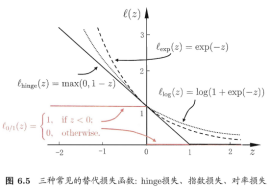
4.3.2 常用的替代损失函数
- hinge损失
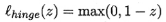
新的优化目标函数为
![]()
- 指数损失(exponential loss)
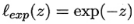
- 对率损失(logistic loss)
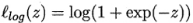
- 图6.5比较以上三种损失
4.4 松弛变量(slack variables)
新的优化目标函数为
![]()
其中,松弛变量![]()
![]()
4.5 正则化(regularization)
4.5.1 各种替代损失函数学习模型的共性
- 优化目标中的第一项用来描述划分超平面的“间隔”大小
结构风险(structural risk)
- 另一项用来表述训练集上的误差
经验风险(empirical risk)
- C用于对二者进行折中
- 表达式
![]()
4.5.2 可理解为一种“罚函数法”
即对不希望得到的结果施以惩罚,从而使得优化过程趋向于希望目标
4.5.3 正则化问题
Ω(f)称为正则化项 Lp范数(norm)是常用的正则化项
- Lo范数‖w‖o
- L1范数‖w‖1倾向于w的分量尽量稀疏,即非零分量个数尽量少
- L2范数‖w‖2倾向于w的分量取值尽量均衡,即非零分量个数尽量稠密
C则称为正则化常数
5.支持向量回归
5.1 容忍f(x)与y之间最多有E的偏差,即仅当f(x)与y之间的差别绝对值大于e时才计算损失。相当于以f(x)为中心构建了一个宽度为2e的间隔带,若训练样本落入此间隔带,则认为是被预测正确的
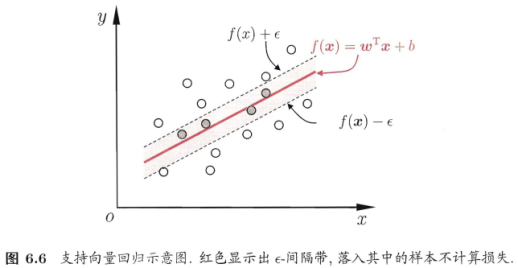
5.2 SVR问题形式
![]()
其中C为正则化常数,le是图6.7所示的e-不敏感损失(e-insensitive loss)函数
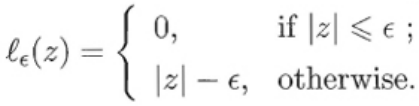
 因为间隔带两侧的松弛程度可以不同,引入2个松弛变量,可见SVR式子重写
因为间隔带两侧的松弛程度可以不同,引入2个松弛变量,可见SVR式子重写
![]()
引入拉格朗日乘子、偏导为零、对偶问题、KKT条件、求解w和b、特征映射、核函数
6.核方法
6.1 表示定理(representer theorem)

6.2 核函数的巨大威力
- 表示定理对损失函数没有限制
- 对正则化项Omega仅要求单调递增,不要求Omega是凸函数
6.3 核方法(kernel methods)的定义
- 基于核函数的学习方法
6.4 核方法的常见用法
- 通过“核化”(即引入核函数)来将线性学习器拓展为非线性学习器
核线性判别分析(Kernelized Linear Discriminant Analysis, 简称KLDA)
7. 阅读材料
7.1 线性核SVM迄今仍是本文分类的首选技术
7.2 支持向量机与统计学习
7.3 支持向量机的求解通常是借助于凸优化技术,如何提高效率?
7.3.1 线性核SVM
- 基于割平面法(cutting plane algorithm)的SVM Perf具有线性复杂度
- 基于随机梯度下降的Pegasos速度甚至更快
- 坐标下降法在稀疏数据上有很高的效率
7.3.2 非线性核SVM
- 基于采样的CVM
- 基于低秩逼近的Nystrom方法
- 基于随机傅里叶特征的方法
7.4 支持向量机是多面手
- 针对二分类任务设计的
- 对多分类任务要进行专门的推广
- 对带结构输出的任务也已有相应的算法
7.5 核函数
- 直接决定了支持向量机与核方法的最终性能
- 选择是一个未决问题
- 多核学习(multiple kernel learning)使用多个核函数通过学习获得其最优凸组合作为最终的核函数
7.6 替代损失的一致性(consistency)问题
7.7 SVM已有很多软件包
- LIBSVM
- LIBLINEAR
