
集成PyTables + pandas + duckdb 进行数据查询
以前简单说明过PyTables,同时pandas 直接支持基于此包的hdf5操作,实际上我们可以将几个集成起来
参考玩法
如下图,基于PyTables的table 格式写入数据到hdf5中,然后通过pandas 加载为dataframes,之后通过duckdb 直接进行查询
可以实现灵活的数据写入,加载,查询,分析
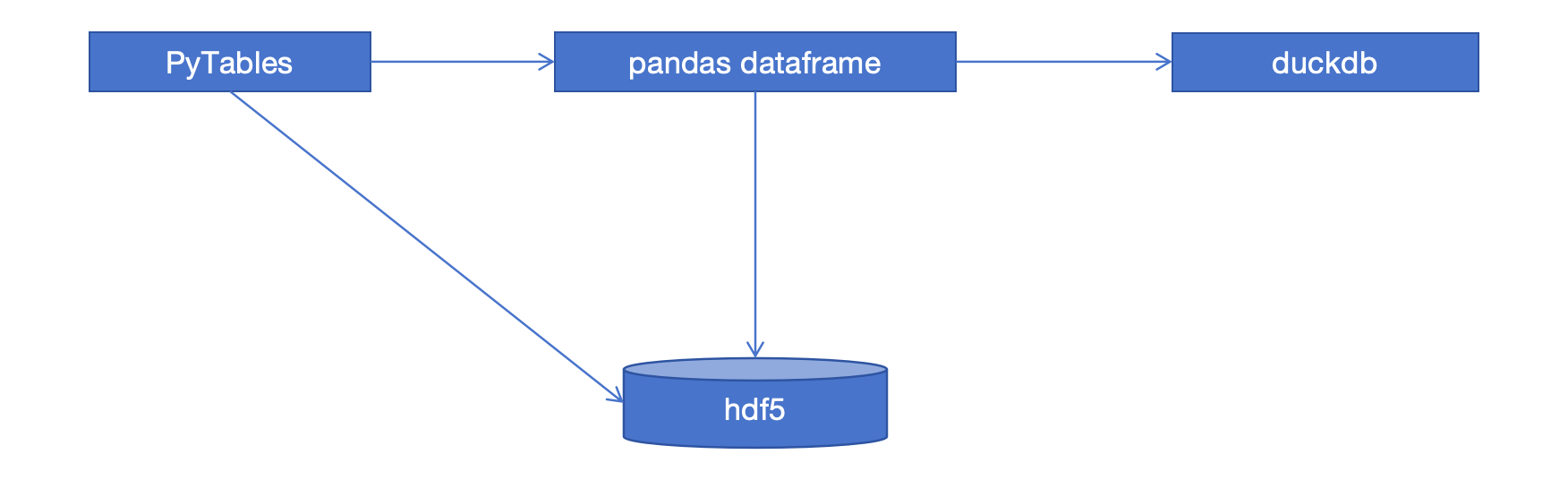
使用
- PyTables 写入
import tables as tb
class Particle(tb.IsDescription):
identity = tb.StringCol(itemsize=22, dflt=" ", pos=0) # character String
idnumber = tb.Int16Col(dflt=1, pos = 1) # short integer
speed = tb.Float32Col(dflt=1, pos = 2) # single-precision
# Open a file in "w"rite mode
fileh = tb.open_file("demo.h5", mode = "w")
# Get the HDF5 root group
root = fileh.root
# Create the groups
group1 = fileh.create_group(root, "group1")
group2 = fileh.create_group(root, "group2")
# Now, create an array in root group
array1 = fileh.create_array(root, "array1", ["string", "array"], "String array")
# Create 2 new tables in group1
table1 = fileh.create_table(group1, "table1", Particle)
table2 = fileh.create_table("/group2", "table2", Particle)
# Create the last table in group2
array2 = fileh.create_array("/group1", "array2", [1,2,3,4])
# Now, fill the tables
for table in (table1, table2):
# Get the record object associated with the table:
row = table.row
# Fill the table with 10 records
for i in range(10):
# First, assign the values to the Particle record
row['identity'] = f'This is particle: {i:2d}'
row['idnumber'] = i
row['speed'] = i * 2.
# This injects the Record values
row.append()
# Flush the table buffers
table.flush()
# Finally, close the file (this also will flush all the remaining buffers!)
fileh.close()
- pandas duckdb 查询
from pandas import HDFStore
import duckdb
h5 = HDFStore("demo.h5", mode="r")
users_df = h5.get("/group1/table1")
result = duckdb.sql("SELECT * FROM users_df where idnumber>5")
print(result.fetchall())
h5.close()
- 效果

说明
利用PyTables对于hdf5高性能的写入以及duckdb 的高效查询可以更好的进行数据存储以及分析,以上是一个集成,同时对于h5
文件的信息,可以通过h5web 这个vs code 插件查看
参考资料
https://www.pytables.org/usersguide/tutorials.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号