

Maintaining Long-Lived Connections with AMQProxy
In the AMQP protocol, if you open a connection the client and the server have to exchange 7 TCP packets. If you then want to publish a message you have to open a channel which requires 2 more, and then to do the publish you need at least one more, and then to gracefully close the connection you need 4 more packets. In total 15 TCP packets, or 18 if you use AMQPS (TLS). For clients that can't for whatever reason keep long-lived connections to the server this has a considerable latency impact.
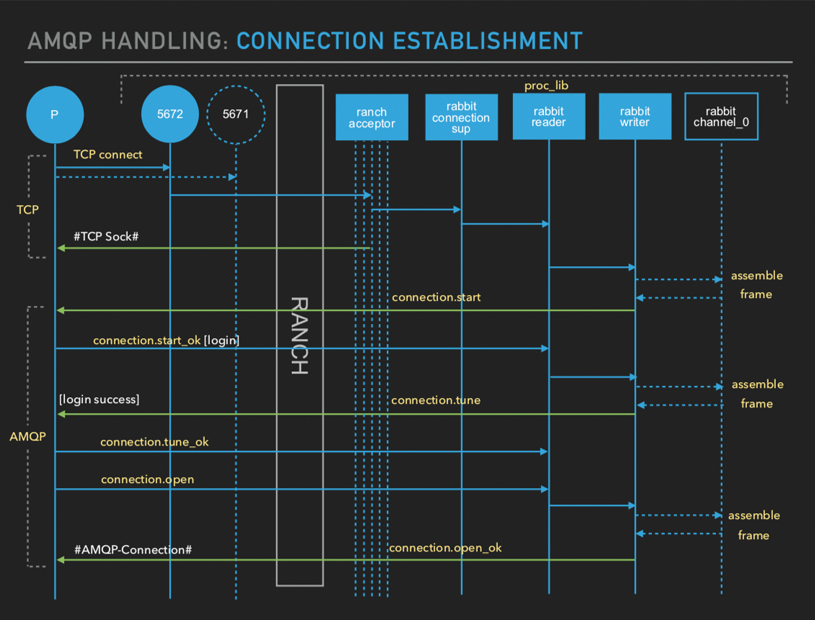
Fig 1. AMQP connection establishment. By Ayanda Dube, RabbitMQ Summit 2018
In our recent publishing benchmark comparing asynchronous to synchronous publishers, we also looked at publishers that open a new connection per message and saw orders of magnitude lower throughput and high CPU utilization on the RabbitMQ server.
We also saw that these publishers are extremely sensitive to network latency, due to the number of synchronous message passing required to send each message.
In addition to reduced throughput, we also see higher CPU utilization on RabbitMQ brokers due to the connection churn.
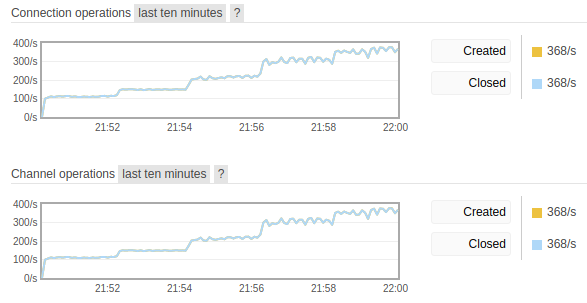
Fig 2. Connection and channel churn.
Introducing an Intelligent AMQP Proxy by CloudAMQP
The AMQProxy is a specialized AMQP proxy developed by CloudAMQP that uses connection and channel pooling/reuse in order to reduce connection churn on brokers. CloudAMQP hosts thousands of RabbitMQ clusters and the team have identified inefficient connection usage as one of the most common practices that lead to broker overload and poor throughput. That is why they decided to develop and open source a proxy specifically for AMQP.
When AMQProxy is run on the same machine as the client it can save all the extra latency that the connection establishment round-trips create when performed over the network. When a connection is made to the proxy, the proxy opens a connection to the upstream server, using the credentials the client provided. AMQP traffic is then forwarded between the client and the server but when the client disconnects the proxy intercepts the Channel Close command and instead keeps it open on the upstream server (if deemed safe). Next time a client connects (with the same credentials) the connection to the upstream server is reused so no TCP packets for opening and negotiating the AMQP connection or opening and waiting for the channel to be opened has to be made.
Only "safe" channels are reused, that is channels where only Basic Publish or Basic Get (with no_ack) has occurred. Any channels that have subscribed to a queue will be closed when the client disconnects. However, the connection to the upstream AMQP server is always kept open and can be reused.
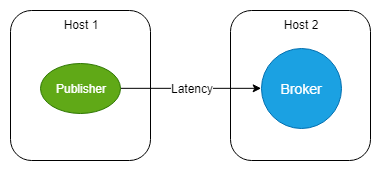
Fig 3. A publisher directly connects to the broker
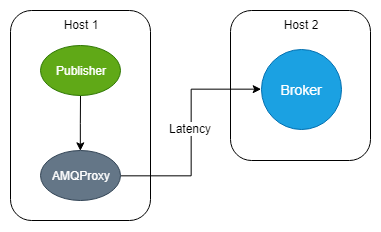
Fig 4. Publishers connect to localhost:5673 instead of connecting directly to the broker. Any connection establishment round trips occur over localhost rather than the network.
Benchmarks
In the charts below, we compare throughput with and without the AMQProxy, at different network latencies.
We are using the Python Pika library for this benchmark, opening and closing a new BlockingConnection for every message sent. The broker has 4 virtual CPUs with 16GB of RAM.
Publishing Without Confirms and Without AMQProxy
We see that even adding just 1ms of network latency drops throughput by 50%! At 50 ms and 100 ms, we see only 2-3 messages per second.
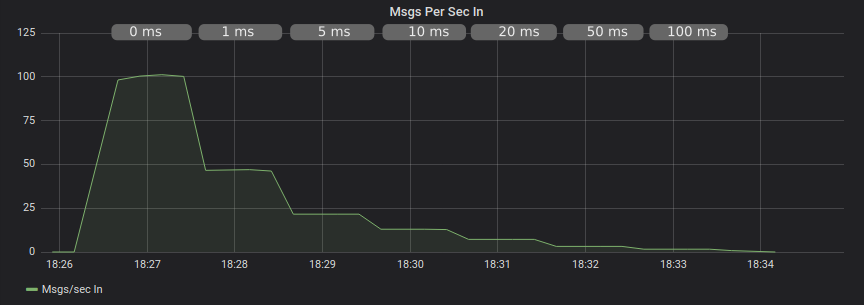
Publishing With Confirms and Without AMQProxy
With publisher confirms we see even more dismal performance.
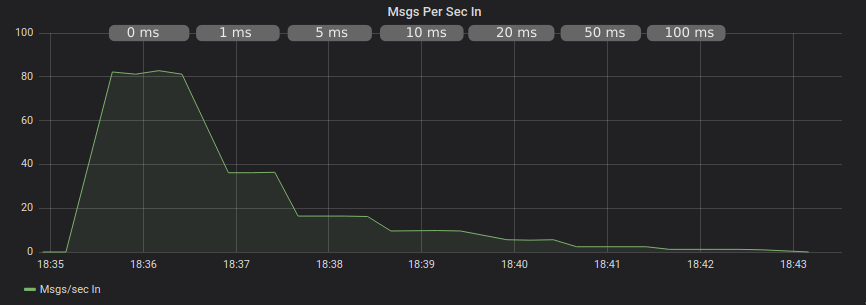
Publishing Without Confirms and With AMQProxy
We see a dramatic change when publishing to AMQProxy hosted locally, not only have we doubled our throughput, but it remains unaffected by network latency.
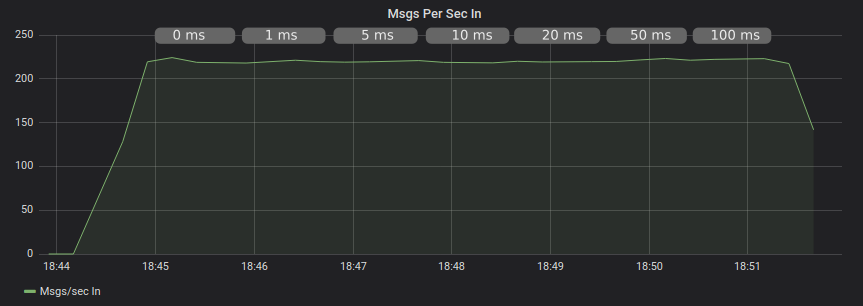
Publishing With Confirms and With AMQProxy
We have a different story when publishing synchronously using confirms, though this is expected as we are waiting synchronously for a confirm, with the extra latency.
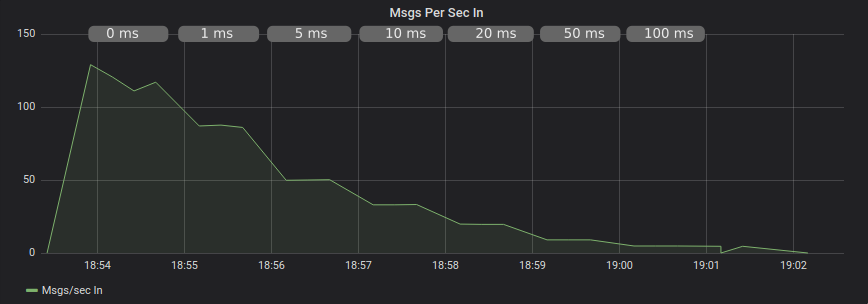
Comparing CPU Utilization
Let’s look at the impact on a BigBunny instance on CloudAMQP which has two CPU cores. The below graphs show the metrics with a single publisher both with and without AMQProxy.
Our RabbitMQ instance (BigBunny plan) named flashy-reindeer sees 35% CPU utilization with only single publisher. When the same publisher connects to the broker via a local AMQProxy we see average CPU utilization goes from 4% to 7%, just a 3% increase.
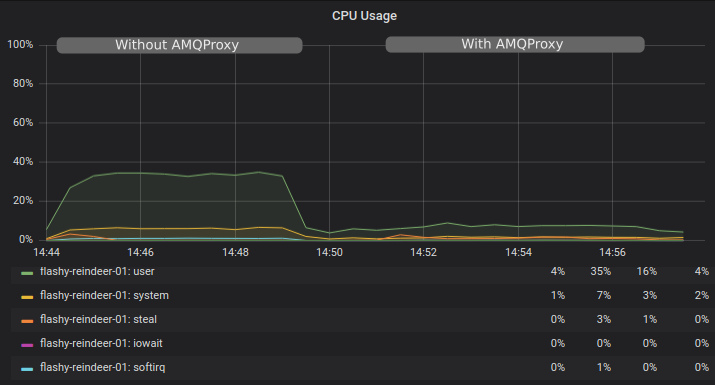
Now look at the message throughput. We see that with AMQProxy we achieve higher throughput and lower CPU utilization.
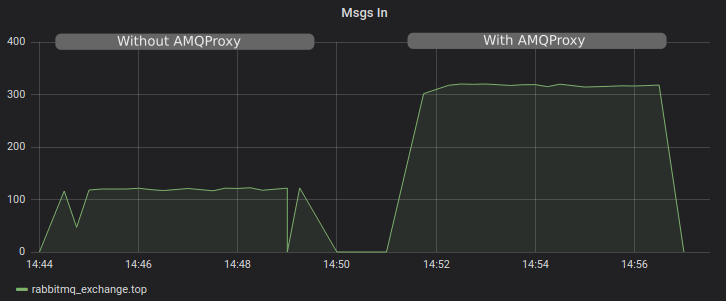
The CPU utilization cost per message without the proxy was 0.25%, or per 1% utilization, we can send 4 messages. When we use AMQProxy, the cost per message is 0.009%, or per 1% utilization we can send 106 messages.
Summary
The AMQProxy makes a dramatic difference to applications that are unable to maintain long-lived AMQP connections and must create a new connection per message. Not only does it increase throughput per publisher, but reduces overall load on the RabbitMQ broker by reducing connection churn.
Go check out the AMQProxy and try it for yourself! https://github.com/cloudamqp/amqproxy




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)
2019-07-01 GitLab : Omnibus Installer
2019-07-01 集成omnibus-ctl 开发一个专业的软件包管理工具
2019-07-01 Chocolatey 方便的windows 包管理工具
2018-07-01 consul 1.2 支持service mesh
2017-07-01 fabio