
自己动手轻松解决复杂算法问题
放一篇之前没开放出来博客,博客中的时间是2019年,并不是当前。先介绍下本篇分享的背景:上周三上午很久不联系的以前关系很好的前同事突然跟我说有个项目,让我入伙,我问他具体的内容,他就说是关于刷单平台的项目,然后具体的太复杂,晚上下班过来我公司附近请我吃饭再详细说。然后这次是吃太二酸菜鱼,吃完后就找了个地方喝东西,才知道他们项目周五就要给客户演示了,还有一个最核心的功能没开始做,托不住了要找我救火(刚开始咋不找我,都快结束了才想到我,果然是关系很好的前同事)。打开电脑给我介绍了下,功能原型图如下:
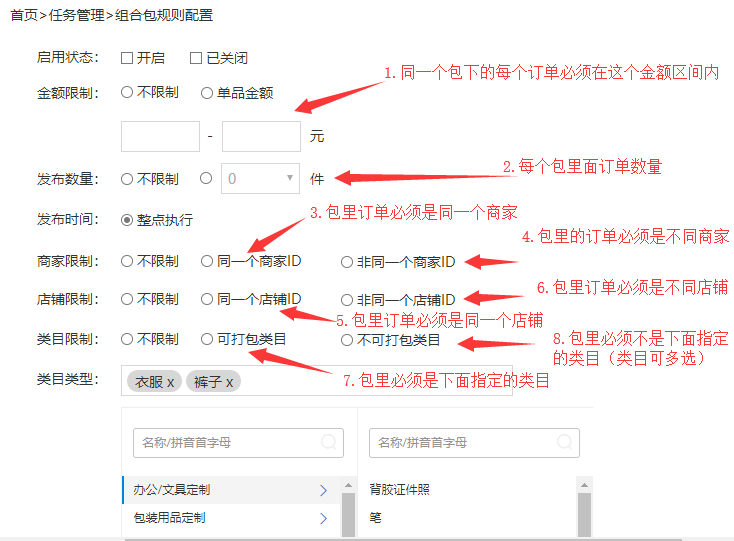
从功能看,其实就是有一堆订单,然后根据这个打包规则(多个规则可以同时存在)把不同的订单组合成一个包,简单来说就是给每个订单按照打包规则更新订单里面的一个包ID的字段。咋一听,太简单了,当时想想就说如果顺利周五能搞定(因为平时工作中根本没遇到过什么我解决不了的问题,哈哈,吹个牛B)。回去之后噩梦才开始了,这个问题没有那么简单,虽然说结果很简单就是把一堆订单按照规则更新一下包ID的字段而已,但是请朋友们想想,里面的每个选项组合起来有多少种情况,按照长期进行数据库增删改查的我来说,第一反应就是使用SQl了,这是很自然的最简单的反应。然后就看出来不对劲了,妈蛋,情况真的有点多,如图上
问题1:可以通过判断是否控制金额,通过sql过滤出符合条件的订单
问题2:先不管
问题3:同一个包下必须是同一个商家,这个很easy,直接通过sql对商家ID来个group by,然后就没有然后了,group by之后相同ID只会出来一条,哈哈
问题4:包里必须是不同的商家的订单,这个才是对商家ID来个group by出来的都是不同的商家ID的数据了,但是同样的问题,那些相同商家ID的订单都只出来一条,请问这一堆订单怎么能分组完全呢?如下简易订单数据,分组后出来的数据假如订单ID和商家ID数据分别为1,1和3,2。那2,1和4,2其实也符合要求,你准备何时去组成一个包呢?
订单ID,商家ID
1,1
2,1
3,2
4,2
问题5和6:同上问题3和4
问题7:包里必须是下面指定的类目,很简单直接用in
问题8:暴力必须不是下面指定的类目,同样简单直接用not in
通过上面的分析问题1,7,8很容易通过sql解决,3,4,5和6似乎不是那么容易了,现在假如上面8个问题都可以通过sql解决,但是上面一共组成了2*2*3*3*3=108种情况,你想怎么死?然后当天我就失眠了,失眠的原因有几个,首先平时工作中算法接触的比较少,没有这方面的经验,其次产生了思维定势,只想到了用数据库解决这种问题。我想大部分java开发人员都是这种情况,不信你可以先停下来先想想上面的题到底要怎么解决,想不到一个可行的办法,请不要看下面的方案,这样估计你能有更深的体会,甚至可以使自己平时解决问题的思维方式像好的方向进化。
经过一夜的失眠,期间知道了通过sql的方案是行不通的,然后想着只能通过代码解决问题了,其实那时已经知道1,7,8不管是sql还是代码都很好解决,基本没考虑这三个问题了。主要是考虑3,4,5,6问题,都知道jdk8的stream api可以模拟数据库sql的大部分操作,当然分组也是可以的,不过如果对一堆订单进行分组,结果是一个按照分组字段的一个map,map的key是分组字段,值就是一个具有相同分组字段值的结果集,如上订单数据按照商家ID分组后结果如下
key value
1=[{订单ID:1,商家ID:1},{订单ID:2,商家ID:1}]
2=[{订单ID:3,商家ID:2},{订单ID:4,商家ID:2}]
假如要解决问题3和5,只需要分别在不同的value里找数据就可以了,但是要解决4和6就尴尬了,就变成每次组包要从一个value里取一个和其余的若干value里各取出一个,一共取多少个还得看问题2中限制的一个包有多少个订单。这个算法应该不是每个人都能写出来吧。
看到这里估计有人会觉得这篇文章不会就是写怎么写如何用代码实现上面分析出来的算法吧,如果是这么low,就不会有这篇文章了。其实前面都是过渡,下面才真正进入正题,相信广大群众的眼睛是雪亮的,后面好不好你们说了算。
再捋一捋,问题其实可以抽象成将M个订单,分割成N组,每组S个,有点不同的是需要按照上述3456限制条件进行分组,当然最后不够S个的可以忽略不管。乍一看还是很复杂,那我们是不是可以遵从大事化小的原则,先分一组试试看,分完一组看情况来个递归或者循环是不是就分完了。
相信大家都听过,一个程序员的代码能力很大程度上取决于他的抽象能力。下面我们对上面问题进行抽象,对各个规则的配置项进行分类抽象如下:
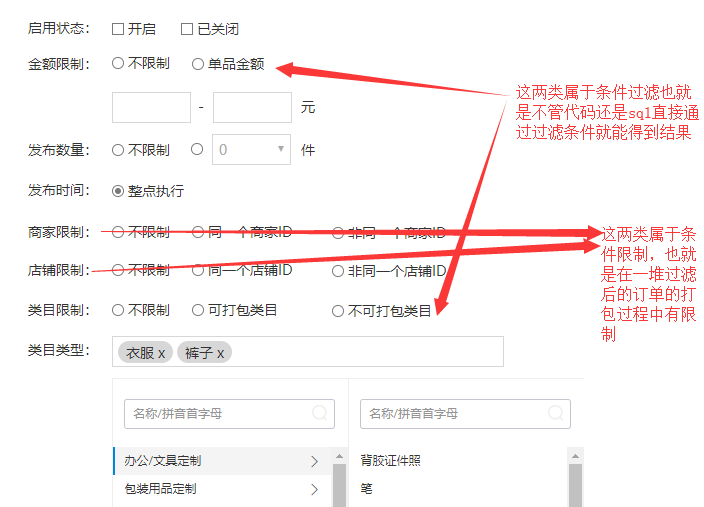
然后我们可以抽象出两个接口或者抽象类,一个条件过滤和一个条件限制类。首先从数据库查询出来一堆需要现在打包的数据,也就是根据当前时间和订单的发布时间类似的东西比较一下符合就查出来。然后经过由该打包规则的条件过滤的两个配置项生成的过滤器链,出来的订单数据就是符合了条件过滤的订单,接着每次随便取出一个订单,然后循环其他订单,对每个订单使用打包规则创建的一堆条件限制器链判断是否能够打包到一起,如果可以打包成功,就删除成功的订单,继续递归或者循环上述动作。详细代码如下:
任务类如下:
package com.xiaotmall.schedule.packtask.scheduler; import com.xiaotmall.repository.module.ts.entity.Order; import com.xiaotmall.repository.module.ts.entity.Package; import com.xiaotmall.repository.module.ts.entity.PackageRule; import com.xiaotmall.repository.module.ts.mapper.OrderMapper; import com.xiaotmall.repository.module.ts.mapper.PackageMapper; import com.xiaotmall.repository.module.ts.mapper.PackageRuleMapper; import com.xiaotmall.repository.module.ts.vo.ROrder; import com.xiaotmall.repository.module.ts.vo.SPackageRule; import com.xiaotmall.schedule.packtask.oper.filters.DataFilter; import com.xiaotmall.schedule.packtask.oper.filters.FilterableList; import com.xiaotmall.schedule.packtask.oper.limits.ConditionLimiter; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.scheduling.annotation.EnableScheduling; import org.springframework.scheduling.annotation.SchedulingConfigurer; import org.springframework.scheduling.config.ScheduledTaskRegistrar; import org.springframework.scheduling.support.CronTrigger; import org.springframework.stereotype.Component; import java.text.SimpleDateFormat; import java.util.ArrayList; import java.util.Arrays; import java.util.Collections; import java.util.Date; import java.util.Iterator; import java.util.List; import java.util.concurrent.ExecutorService; import java.util.concurrent.SynchronousQueue; import java.util.concurrent.ThreadPoolExecutor; import java.util.concurrent.TimeUnit; /** * 打包调度器 */ @Component @EnableScheduling public class PackScheduler implements SchedulingConfigurer { /** * 定义一个最大线程10个的cached线程池 */ private static ExecutorService excutorService = new ThreadPoolExecutor(0, 10, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); /** * 默认整点执行,可以通过调用本类的setCron方法修改这个执行周期,比如需要的时候可以 * 通过读取数据库更新这个cron表达式 */ private static final String DEFAULT_CRON = "0 0 * * * ?"; private String cron = DEFAULT_CRON; @Autowired private PackageMapper packageMapper; @Autowired private PackageRuleMapper packageRuleMapper; @Autowired private OrderMapper orderMapper; public void init() { //测试先初始化若干订单 // addSameOrder(); excutorService.execute(new Boss()); } @Override public void configureTasks(ScheduledTaskRegistrar scheduledTaskRegistrar) { scheduledTaskRegistrar.addTriggerTask(() -> { // 执行定时任务 init(); }, (triggerContext) -> { CronTrigger trigger = new CronTrigger(cron); Date nextExecDate = trigger.nextExecutionTime(triggerContext); return nextExecDate; }); } /** * 可需要的时候动态设置cron表达式的值实现动态更新调度的周期 * @param cron */ public void setCron(String cron) { this.cron = cron; } public class Boss implements Runnable { @Override public void run() { /** * 查出所有启用的打包规则 */ SPackageRule packageRule = new SPackageRule(); packageRule.setDisabled(false); List<PackageRule> rules = packageRuleMapper.findAll(packageRule); if(rules == null || rules.isEmpty()) { return; } /** * 根据启用的规则数量初始化vorders大小 */ List<ROrder> vorders = orderMapper.findUnPackSimpleOrders(rules.size() * 10000); if(vorders == null || vorders.isEmpty()) { return; } /** * 循环每个启用的规则,将所有查出的订单按照切分成规则数量个,并交给worker线程执行 */ for(int i = 0;i < rules.size();i++) { PackageRule rule = rules.get(i); /** * 根据规则初始化过滤器 */ DataFilter<ROrder> filter = DataFilter.createDataFilter(rule); /** * 将订单数据切分成多块,分别交给不同的线程执行,消除多个线程消费同一个订单的情况,减少锁竞争 */ List<ROrder> currOrders = null; if(rules.size() == 1 || i < rules.size() - 1) { currOrders = vorders.subList(i * vorders.size() / rules.size(), (i + 1) * vorders.size() / rules.size()); } else { currOrders = vorders.subList((i + 1) * vorders.size() / rules.size(),vorders.size()); } if(currOrders == null || currOrders.isEmpty()) { continue; } excutorService.execute(new Worker(rule,currOrders,filter)); } } } class Worker implements Runnable { private PackageRule rule; private List<ROrder> currOrders; private DataFilter<ROrder> filter; public Worker(PackageRule rule,List<ROrder> currOrders,DataFilter<ROrder> filter) { this.rule = rule; this.currOrders = currOrders; this.filter = filter; } @Override public void run() { /** * 实例化一个可以过滤的集合 */ FilterableList<ROrder> flist = new FilterableList<>(); /** * 初始化数据 */ flist.init(currOrders); /** * 执行集合过滤,找到根据各种条件过滤器过滤后剩下的订单 */ flist.doFilter(filter); /** * 打乱集合数据顺序造成随机组包的效果,被打乱可能数据库相邻的很可能就会在一个包 */ Collections.shuffle(flist); /** * 递归执行打包 */ doPack(flist, rule); } } private void doPack(List<ROrder> orders, PackageRule rule) { //如果集合空了则退出递归 if(orders.isEmpty()) { return; } int pubNum = rule.getPublishNumber(); List<ROrder> currPackOrders = new ArrayList<>(); /** * 新增一个包 */ Package p = new Package(); p.setPackageName(createPackageName(rule.getRuleName())); p.setPackageCode(createPackageCode(rule.getId())); p.setDisabled(false); p.setDeleted(false); packageMapper.insert(p); /** * 缓缓1ms,太快会导致包编号重复,可以使用redis等共享空间维护一个全局序号 */ try { Thread.sleep(1); } catch(Exception e) { } //随便取第一个为包的第一个订单 ROrder firstOrder = orders.remove(0); firstOrder.setPackageId(p.getId()); firstOrder.setRuleId(rule.getId()); /** * 使用乐观锁更新,关键是package_id is null和n > 0,成功则加入当前包集合,这里使用乐观锁 * 更新是为了防止其他节点也在对当前订单分包,避免进行重复分包导致数据不一致的情况, * 当前时刻多个节点更新订单的package_id时要么更新成功package_id不为空,要么package_id * 不为空更新失败 */ long n = orderMapper.updateByOptimisticLock(firstOrder); if(n > 0) { currPackOrders.add(firstOrder); } else { /** * 一言不合就递归,递归有出口的精髓在于上面每次都remove(0) */ doPack(orders, rule); } for(int i = 0;i < orders.size();i ++) { ROrder currOrder = orders.get(i); /** * 根据各种参数创建一个条件限制器 */ ConditionLimiter limiter = ConditionLimiter.create(currPackOrders,firstOrder,currOrder,rule); /** * 所有限制条件则使用乐观锁更新一下订单的包ID和规则ID,如果成功 */ if(limiter.doLimit()) { /** * 更新订单的包ID和规则ID */ currOrder.setPackageId(p.getId()); currOrder.setRuleId(rule.getId()); /** * 同本方法最上面的逻辑 */ long n1 = orderMapper.updateByOptimisticLock(currOrder); if(n1 > 0) { currPackOrders.add(currOrder); } /** * 当集合满了pubNum个后,递归执行本方法,寻找下一个分组 */ if(currPackOrders.size() == pubNum) { /** * 先删除orders中已经打包好的订单,为后续递归减负 */ deleteBy(orders,currPackOrders); /** * 一如既往的递归 */ doPack(orders, rule); } } } /** * 如果一轮循环下来分组包还是没满,则递归执行,寻找下一个分组 */ if(currPackOrders.size() < pubNum) { /** * 先删除已经无用的包 */ packageMapper.delete(Arrays.asList(p.getId())); /** * 再还原当前不满的包里的包id和规则id为null */ for(ROrder order:currPackOrders) { orderMapper.resetByOptimisticLock(order); } /** * 一如既往的递归打包 */ doPack(orders, rule); } } /** * 删除一个集合中的一个子集合 * @param orders * @param targets */ private void deleteBy(List<ROrder> orders,List<ROrder> targets) { /** * 优化删除由于orders中不可能存在重复order,所以只要删除的order个数等于 * targets的元素个数实际上就表示已经删完了 */ int i = 0; for(Iterator<ROrder> iter = orders.iterator();iter.hasNext();) { ROrder currOrder = iter.next(); if(targets.stream().anyMatch(o -> o.getId().equals(currOrder.getId()))) { iter.remove(); i ++; if(i == targets.size()) { break; } } } } /** * 如果部署多个节点,这里需要使用redis等内存数据库维护一个全局的序号,不然可能重复 * @param ruleId * @return */ private String createPackageCode(Long ruleId) { SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMddhhmmssSSS"); StringBuilder code = new StringBuilder(); code.append("pg_auto_").append(ruleId).append(sdf.format(new Date())); return code.toString(); } /** * 如果部署多个节点,这里需要使用redis等内存数据库维护一个全局的序号,不然可能重复 * @param ruleName * @return */ private String createPackageName(String ruleName) { SimpleDateFormat sdf = new SimpleDateFormat("hhmmssSSS"); StringBuilder name = new StringBuilder(); name.append(ruleName).append(sdf.format(new Date())); return name.toString(); } /** * 使用id为2-5的任务数据测试 */ private void addSameOrder() { for(int i = 0;i < 80;i++) { Order o = new Order(); o.setCreateTime(new Date()); o.setDeleted(false); o.setDisabled(false); o.setUserId(0L); o.setTaskId(2L); o.setCreator("autopack"); orderMapper.insert(o); } for(int i = 0;i < 80;i++) { Order o = new Order(); o.setCreateTime(new Date()); o.setDeleted(false); o.setDisabled(false); o.setUserId(0L); o.setTaskId(3L); o.setCreator("autopack"); orderMapper.insert(o); } for(int i = 0;i < 80;i++) { Order o = new Order(); o.setCreateTime(new Date()); o.setDeleted(false); o.setDisabled(false); o.setUserId(0L); o.setTaskId(4L); o.setCreator("autopack"); orderMapper.insert(o); } for(int i = 0;i < 80;i++) { Order o = new Order(); o.setCreateTime(new Date()); o.setDeleted(false); o.setDisabled(false); o.setUserId(0L); o.setTaskId(5L); o.setCreator("autopack"); orderMapper.insert(o); } } }
条件过滤器类如下:
package com.xiaotmall.schedule.packtask.oper.filters; import com.xiaotmall.repository.module.ts.entity.PackageRule; import com.xiaotmall.repository.module.ts.vo.ROrder; import java.util.Arrays; import java.util.function.Predicate; /** * 数据过滤器,这里实际上是根据规则生成了一个过滤器链,这里使用根据规则使用链表方式 * 制造过滤器链 * @author: rongdi * @date: 2019-10-16 21:30 */ public class DataFilter<T> { DataFilter after; Predicate<T> filter; public DataFilter() { } public DataFilter(Predicate<T> filter) { this.filter = filter; } /** * 根据打包规则构造数据过滤器 * @param rule * @return */ public static DataFilter createDataFilter(PackageRule rule) { DataFilter<ROrder> filter = new DataFilter<>(); //就像where里的1=1一样 filter.setFilter(o -> 1 == 1); //假如限制金额,则需要加入对应金额过滤器 if("SINGLE_AMOUNT".equalsIgnoreCase(rule.getAmountCode())) { filter.next(o -> o.getRealprice().compareTo(rule.getAmountStart()) > 0 && rule.getAmountEnd().compareTo(o.getRealprice() ) > 0); } String cCodes = rule.getCatagoryCode(); String[] codeArr = cCodes.split(","); //假如限制可打包类目 if(codeArr.length > 0 && "PACK_CATEGORY".equalsIgnoreCase(rule.getPackCode())) { filter.next(o -> Arrays.asList(codeArr).contains(o.getGoodtypeCode())); } else if(codeArr.length > 0 && "NO_PACK_CATEGORY".equalsIgnoreCase(rule.getPackCode())) { //假如限制不可打包类目 filter.next(o -> !Arrays.asList(codeArr).contains(o.getGoodtypeCode())); } return filter; } public void setFilter(Predicate<T> filter) { this.filter = filter; } public DataFilter<T> next(Predicate<T> filter) { this.after = new DataFilter(filter); return this.after; } public boolean filter(T t) { /** * 先执行自己的判断 */ boolean flag = filter.test(t); /** * 然后循环判断是否有下一个过滤器,有就执行,只有都满足最终结果才满足 * 这里使用循环的方式完成链的调用 */ DataFilter next = after; while (next != null) { flag &= next.filter(t); next = next.after; } return flag; } }
为了方便配合过滤器链做的一个可过滤集合
package com.xiaotmall.schedule.packtask.oper.filters; import java.util.ArrayList; import java.util.Iterator; import java.util.List; /** * 可过滤集合,为了方便配套过滤器链 * @author: rongdi * @date: 2019-10-16 21:30 */ public class FilterableList<T> extends ArrayList<T> { public void init(List<T> datas) { this.addAll(datas); } public void doFilter(DataFilter<T> filter) { for (Iterator<T> iter = iterator(); iter.hasNext(); ) { T t = iter.next(); boolean flag = filter.filter(t); if (!flag) { iter.remove(); } } } }
条件限制抽象类如下:
package com.xiaotmall.schedule.packtask.oper.limits; import com.xiaotmall.repository.module.ts.entity.PackageRule; import com.xiaotmall.repository.module.ts.vo.ROrder; import java.util.List; /** * 条件限制器 * @author: rongdi * @date: 2019-10-18 20:32 */ public abstract class ConditionLimiter<T> { protected ConditionLimiter parent; public abstract boolean doLimit(); public static ConditionLimiter create(List<ROrder> currPackOrders,ROrder firstOrder,ROrder currOrder, PackageRule rule) { ConditionLimiter currLimiter = null; /** * 使用限制策略分割过滤偶的集合数据 * 如果是店铺限制:不同店铺ID,则更新结果 */ if("NON_SHOP".equalsIgnoreCase(rule.getShopCode())) { currLimiter = new NotContainsConditionLimiter(null,o -> o.getShopId() != null && o.getShopId().equals(currOrder.getShopId()),currPackOrders,currOrder); } /** * 如果商家限制:同一商家, */ if("SAME_BUSINESS".equalsIgnoreCase(rule.getBusinessCode())) { if(currLimiter != null) { ConditionLimiter cl = currLimiter; currLimiter = new EqualConditionLimiter(cl,o -> o.getPubId() != null && o.getPubId().equals(currOrder.getPubId()),firstOrder,currOrder); } else { currLimiter = new EqualConditionLimiter(null,o -> o.getPubId() != null && o.getPubId().equals(currOrder.getPubId()),firstOrder,currOrder); } } else if("NON_BUSINESS".equalsIgnoreCase(rule.getBusinessCode())) { //如果是不同商家 if(currLimiter != null) { ConditionLimiter cl = currLimiter; currLimiter = new NotContainsConditionLimiter(cl,o -> o.getPubId() != null && o.getPubId().equals(currOrder.getPubId()),currPackOrders,currOrder); } else { currLimiter = new NotContainsConditionLimiter(null,o -> o.getPubId() != null && o.getPubId().equals(currOrder.getPubId()),currPackOrders,currOrder); } } return currLimiter; } }
条件限制实现类如下:
package com.xiaotmall.schedule.packtask.oper.limits; import com.xiaotmall.repository.module.ts.vo.ROrder; import java.util.function.Predicate; /** * 相等条件限制器,这里使用类似类加载的委派模式,parent先执行再执行自己的方式形成链 * @author: rongdi * @date: 2019-10-18 20:32 */ public class EqualConditionLimiter extends ConditionLimiter<ROrder> { private Predicate<ROrder> condition; private ROrder firstOrder; private ROrder currOrder; public EqualConditionLimiter(ConditionLimiter parent,Predicate<ROrder> condition,ROrder firstOrder,ROrder currOrder) { this.parent = parent; this.condition = condition; this.firstOrder = firstOrder; this.currOrder = currOrder; } @Override public boolean doLimit() { boolean flag = true; /** * 如果有parent先执行parent并保存判断结果 */ if(parent != null) { flag &= parent.doLimit(); } /** * 如果parent判断成功,则判断自己,如果不成功直接返回false,表示不符合条件限制 */ if(flag) { return condition.test(firstOrder); } else { return false; } } }
package com.xiaotmall.schedule.packtask.oper.limits; import com.xiaotmall.repository.module.ts.vo.ROrder; import java.util.List; import java.util.function.Predicate; /** * 不包含条件限制器 * @author: rongdi * @date: 2019-10-18 20:32 */ public class NotContainsConditionLimiter extends ConditionLimiter<List<ROrder>> { private Predicate<ROrder> condition; private List<ROrder> currPackOrders; private ROrder currOrder; public NotContainsConditionLimiter(ConditionLimiter parent,Predicate<ROrder> condition,List<ROrder> currPackOrders,ROrder currOrder) { this.parent = parent; this.condition = condition; this.currPackOrders = currPackOrders; this.currOrder = currOrder; } @Override public boolean doLimit() { boolean flag = true; if(parent != null) { flag &= parent.doLimit(); } if(flag) { return !currPackOrders.stream().anyMatch(condition); } else { return false; } } }
然后就没有然后了,先申明以上实现有一些小问题,比如生成包的id,名称直接使用了取巧的方式,因为当时redis,另外判断单选框类型那么奇怪用的字符串判断,是因为前同事做的项目数据库就是这么定义的,还有就是打包订单可以改成每次去消息队列去取一批订单进行打包,这些都由于我当时的环境限制没有考虑,但是这些都不是本章的核心,本章的核心是关注在算法层面。
最后进行一下总结:本章的算法基本可以从Worker 类的run方法里面看到,先让数据库查出的订单集合经过过滤器链进行删选,然后打乱顺序,最后再进行打包。打包的过程就是先分一组然后分完看情况进行递归,这里其实完全可以改成循环,只是个人觉得递归看起来更清晰,但是递归深度太深可能导致栈溢出,最好改成循环,针对本例代码改成循环很简单,先把递归改成尾递归,也就是让每次递归的代码都放在方法执行的的每个分支的最后,然后把递归退出条件放在while的条件里。个人觉得本例的打包过程如果非要归类到一种算法思想来看:
1) 从思路上来看,需要把订单分成很多个固定大小的包,这里先分一个,然后递归直到分完,每次递归的小任务合在一起最终解决了整个大问题,这是属于分治的思想
2) 从实现手段来看,每次递归里循环的订单数都比前面的少,因为前面没打包成功一个就从集合里删掉了成功的订单,这是属于减治的思想
3) 从策略上来看,每次递归由于之前已经在集合删除了已打包的订单(也相当于标记了已打包的订单),从而后续每次递归都避免再次使用已经打包的订单,这属于动态规划的思想
哈哈,所以这三种思想或者说算法,让人傻傻认不清,书本上网上资源说的都太官方,我也不懂到底是给谁去看的,个人的理解就像上面那样分不清,如果有大神觉得不对,欢迎指正!个人感觉算法思想只是借鉴,如果生搬硬套,死记硬背没啥鬼用。详细代码直接上百度云吧,毕竟不是完整的项目:https://pan.baidu.com/s/1ouDE8lgFPAZCJBWm7fjcUg

 浙公网安备 33010602011771号
浙公网安备 33010602011771号