
flume快速入门及应用
Flume 简介
Flume 的安装与配置
Fumne 部署
Flume 是 Cloudera 提供的一个高可用、 高可靠、 分布式的海量日志采集、 聚合和传输的系统。 Flume 支持定制各类数据源如 Avro、 Thrift、 Spooling 等。 同时 Flume提供对数据的简单处理, 并将数据处理结果写入各种数据接收方, 如将数据写入到 HDFS文件系统中。Flume 作为 Cloudera 开发的实时日志收集系统, 受到了业界的认可与广泛应用。2010 年 11 月 Cloudera 开源了 Flume 的第一个可用版本 0.9.2, 这个系列版本被统称为 Flume-OG(Original Generation) 。 随着 Flume 功能的扩展, Flume-OG 代码开始
臃肿、 核心组件设计不合理、 核心配置不标准等缺点暴露出来, 尤其是在 Flume-OG 的最后一个发行版本 0.94.0 中, 日志传输不稳定的现象尤为严重。 为了解决这些问题,2011 年 10 月 Cloudera 重构了核心组件、 核心配置和代码架构, 重构后的版本统称为Flume-NG( Next Generation) 。 改动的另一原因是将 Flume 纳入 Apache 旗下,Cloudera Flume 改名为 Apache Flume。Flume 的数据流由事件(Event)贯穿始终。 事件是 Flume 的基本数据单位, 它携带日志数据(字节数组形式)并且携带有头信息, 这些 Event 由 Agent 外部的 Source 生成,当 Source 捕获事件后会进行特定的格式化, 然后 Source 会把事件推入(单个或多个)Channel 中。 你可以把 Channel 看作是一个缓冲区, 它将保存事件直到 Sink 处理完该事件。 Sink 负责持久化日志或者把事件推向另一个 Source。Flume 以 agent 为最小的独立运行单位。 一个 agent 就是一个 JVM。
单 agent 由Source、 Sink 和 Channel 三大组件构成, 如图 11.1 所示。
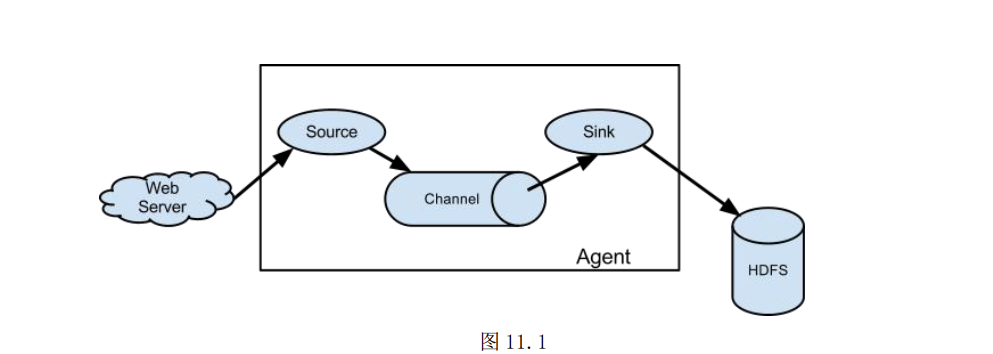
值得注意的是, Flume 提供了大量内置的 Source、 Channel 和 Sink。 不同类型的Source,Channel 和 Sink 可以自由组合。 组合方式基于用户的配置文件, 非常灵活。 比如: Channel 可以把事件暂存在内存里, 也可以持久化到本地硬盘上。 Sink 可以把日志写入 HDFS, HBase, 甚至是另外一个 Source 等。 Flume 支持用户建立多级流, 也就是说, 多个 agent 可以协同工作, 并且支持 Fan-in(扇入)、 Fan-out(扇出)、 ContextualRouting、 Backup Routes。 如图 11.2 所示。
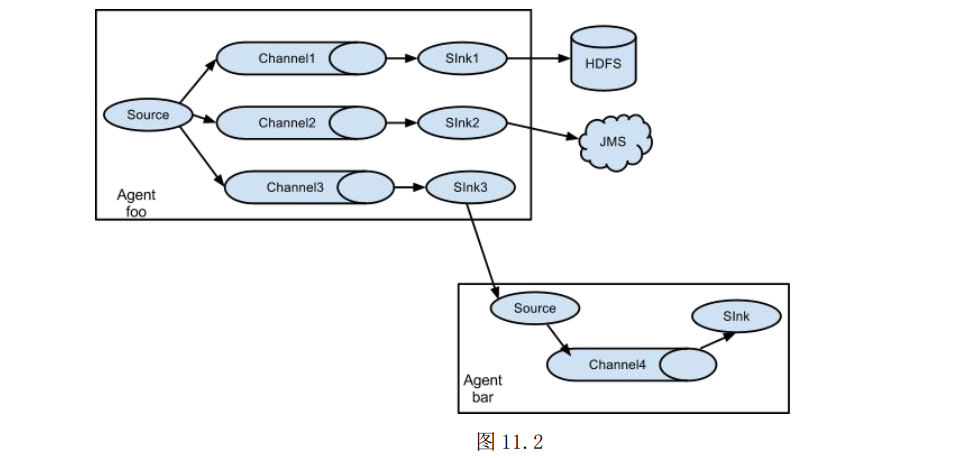
Flume 的一些核心概念:
Agent 使用 JVM 运行 Flume。 每台机器运行一个 agent, 但是可以在一个 agent 中包含多个 Sources 和 Sinks。Source 从 Client 收集数据, 传递给 Channel。 Source 从 Client 收集数据, 传递给 Channel。 Channel 连接 sources 和 sinks , Channel 缓存从 Source 收集来的数据。Sink 从 Channel 收集数据, 并将数据写到目标文件系统中。
Flume 的安装与配置
在安装 Flume 之前, 请确认已经安装了 JDK 并正确配置了环境变量。
步 1: 下载并解压 Flume
下载地址:
http://www.apache.org/dyn/closer.lua/flume/1.7.0/apache-flume-1.7.0-bin.tar.gz。 将 flume 解压到/weric 目录下。 /weric 是之前安装 hadoop 等等其他软件的目录。
$ tar -zxvf ~/apache-flume-1.7.0-bin.tar.gz -C /weric
步 2: 配置 flume 的环境变量
我个人比较喜欢创建一个独立的环境变量配置文件, 所以使用 sudo 创建
$ sudo vim /etc/profile.d/flume.sh
在配置文件中, 添加以下内容
#!/bin/sh
export FLUME_HOME=/weric/apache-flume-1.7.0-bin
export PATH=$PATH:$FLUME_HOME/bin
环境变量生效
$ source /etc/profile
现在可以使用 version 测试 flume 的版本
$ flume-ng version
Flume 1.7.0
步 3: 配置 flume-env.sh 文件
在 flume-env.sh 文件中配置 JAVA_HOME 环境变量。
$ cp flume-env.sh.template flume-env.sh
$ vim flume-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_131
至此为止, flume 安装与配置已经完成。 是不是非常的简单。 以下是将部署两个基本的 flume agent 测试 flume。
部署 Flume agent
部署 flume 就是配置和启动一个 agent。 flume 允许配置多个 agent, 它们之间可 以没有关系, 也可以组成一个数据链。
1. Avro
Flume 可以通过 Avro 监听某个端口并捕获传输的数据。 现在我们配置一个 Source用于监听某个端口的数据, 并将它写出到 flume 的 log 中。
创建一个配置文件,这个配置文件可以是任意的名称:
$vim netcat.conf
添加以下内容:
#配置三个组件
a1.sources=r1
a1.sinks=k1
a1.channels=c1
#配置 source
a1.sources.r1.type=netcat
a1.sources.r1.bind=weric22
a1.sources.r1.port=4444
#配置 sink
a1.sinks.k1.type=logger
#配置 channel
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#绑定 source,sink 和 channel
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
现在启动 Flume Agent
$ flume-ng agent -c conf -f netcat.conf -n a1 -Dflume.root.logger=INFO,console
-c conf 是指使用指定的配置文件。 -f netcat.conf 是使用的配置文件。 -n a1为 agent 的名称。 -Dflume.root.logger=INFO,console 即为输出的日志级别和目标。
启动以后显示为 :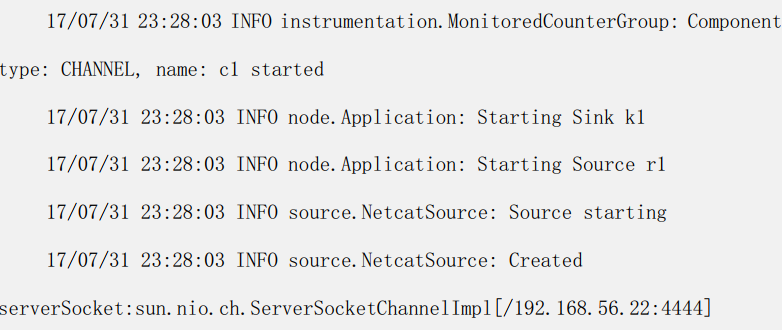
可见, 已经开始监听 4444 端口。
现在打开另一个终端, 使用 telnet 登录 4444 端口, 并发送数据:


然后检查 flume 端接收到的信息
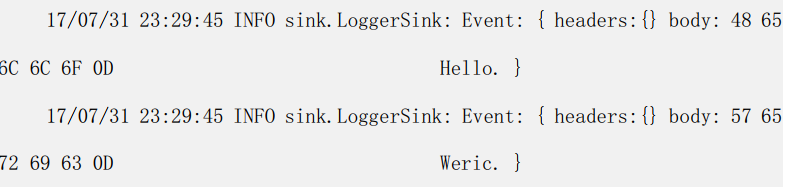
通过上面的配置可以发现在 telent 端输出的数据, 都已经被 flume 接收并输出到控制台。 即实现了第一个 flume 的部署。
以下配置是将从端口接收到的数据, 保存到 hdfs。
#定义三个组件
a1.sources=r1
a1.channels=c1
a1.sinks=k1
#定义 r1, 即定义数据来源
a1.sources.r1.type=netcat
a1.sources.r1.bind=weric22
a1.sources.r1.port=4444
#配置 sink,即输出的目标
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=hdfs://weric22:8020/flume/avro_to_hdfs
a1.sinks.k1.hdfs.writeFormat=Text
a1.sinks.k1.hdfs.fileType=DataStream
#配置中间的缓存
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
#将这三个组件组成一块
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1
现在启动 flume agent:
$ flume-ng agent -n a1 -c config -f 03_avro_to_hdfs.conf
-Dflume.root.logger=DEBUG,Console
使用 telent 登录 weric22 主机的 4444 端口, 然后输入若干数据, 如下:
$ telnet weric22 4444
Jack <ENTER>
OK
....
现在可以查看 hdfs 上的数据:
$ hdfs dfs -ls /flume/avro_to_hdfs
Found 4 items
-rw-r--r-- /flume/avro_to_hdfs/FlumeData.1501858294240
-rw-r--r-- /flume/avro_to_hdfs/FlumeData.1501858327295
-rw-r--r-- /flume/avro_to_hdfs/FlumeData.1501858480559
-rw-r--r-- /flume/avro_to_hdfs/FlumeData.1501859145948
更可以查看里面保存的数据:
$ hdfs dfs -cat /flume/avro_to_hdfs/*
Mary
Alex
Jerry b
2. Spool
Spool 用于监测配置的目录下新增的文件, 并将文件中的数据读取出来。 需要注 意两点: 拷贝到 spool 目录下的文件不可以再打开编辑、 spool 目录下不可包含相应的 子目录。 现在创建 flume 的一个配置文件 spool.conf:
$ vim spool.conf
并添加以下配置信息:
#声明三个组件的名称
a2.sources=r1
a2.channels=c1
a2.sinks=k1
#声明 r1 即 source
a2.sources.r1.type=spooldir
a2.sources.r1.spoolDir=/weric/log
#声明 channel 即 c1
a2.channels.c1.type=memory
a2.channels.c1.capacity=1000
#声明 sinks 之 k1
a2.sinks.k1.type=hdfs
a2.sinks.k1.hdfs.path=hdfs://weric22:8020/flume/%Y%m%d%H
a2.sinks.k1.hdfs.writeFormat=Text
a2.sinks.k1.hdfs.fileType=DataStream
#由于上面使用了时间对象所以必须要设置为 true
a2.sinks.k1.hdfs.useLocalTimeStamp=true
#设置文件的前缀, 默认值为 FlumeData.
a2.sinks.k1.hdfs.filePrefix=weric
#组合起来
a2.sources.r1.channels=c1
a2.sinks.k1.channel=c1
上例中%Y%m%d%H 是指输出年月日小时的格式的目录。 fileType 的选项有三个, 分 另是: DataStream( 原始数据流) 、 SequenceFile、 CompressedStream。 默认值为 SequenceFile。 hdfs.filePrefix 默认值为 FlumeData, 可以修改成任意的值。 由于在配置中使用了%Y 等时间表达式, 所以必须要设置 useLocalTimeStamp=true, 否则会出
现异常。 现在启动这个 agent:
$ flume-ng agent -c apache-flume-1.7.0-bin/conf/ -f flume_config/spool.conf -n a2 -Dflume.root.logger=DEBUG,console
现在可以将文件直接拷贝到/weric/log 目录下了:
$ cp ~/note.txt /weric/log/notes.txt
flume 在完成上传以后, 会修改文件名, 默认的添加扩展为.COMPLETED:
$ ls
notes.txt.COMPLETED
检查 hdfs 上的文件:
$ hdfs dfs -ls /flume/2017080122
-rw-r--r-- ... /flume/2017080122/weric.1501579397641
上面略去了部分内容, 其中 weric.1501579397641 即是采集完成放到 hdfs 上的
文件。
