
聚簇索引和非聚簇索引
聚簇索引:将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据
非聚簇索引:将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置
在innodb中,在聚簇索引之上创建的索引称之为辅助索引,非聚簇索引都是辅助索引,像复合索引、前缀索引、唯一索引。辅助索引叶子节点存储的不再是行的物理位置,而是主键值,辅助索引访问数据总是需要二次查找。
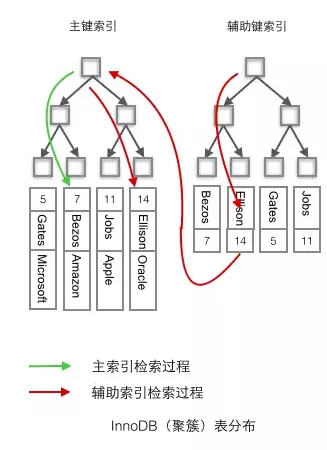
- InnoDB使用的是聚簇索引,将主键组织到一棵B+树中,而行数据就储存在叶子节点上,若使用"where id = 14"这样的条件查找主键,则按照B+树的检索算法即可查找到对应的叶节点,之后获得行数据。
- 若对Name列进行条件搜索,则需要两个步骤:第一步在辅助索引B+树中检索Name,到达其叶子节点获取对应的主键。第二步使用主键在主索引B+树种再执行一次B+树检索操作,最终到达叶子节点即可获取整行数据。(重点在于通过其他键需要建立辅助索引)
聚簇索引具有唯一性,由于聚簇索引是将数据跟索引结构放到一块,因此一个表仅有一个聚簇索引。
表中行的物理顺序和索引中行的物理顺序是相同的,在创建任何非聚簇索引之前创建聚簇索引,这是因为聚簇索引改变了表中行的物理顺序,数据行 按照一定的顺序排列,并且自动维护这个顺序;
聚簇索引默认是主键,如果表中没有定义主键,InnoDB 会选择一个唯一且非空的索引代替。如果没有这样的索引,InnoDB 会隐式定义一个主键(类似oracle中的RowId)来作为聚簇索引。如果已经设置了主键为聚簇索引又希望再单独设置聚簇索引,必须先删除主键,然后添加我们想要的聚簇索引,最后恢复设置主键即可。
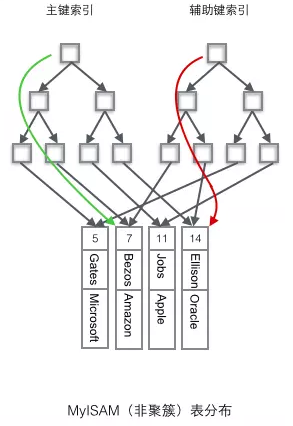
MyISAM使用的是非聚簇索引,非聚簇索引的两棵B+树看上去没什么不同,节点的结构完全一致只是存储的内容不同而已,主键索引B+树的节点存储了主键,辅助键索引B+树存储了辅助键。表数据存储在独立的地方,这两颗B+树的叶子节点都使用一个地址指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通过辅助键检索无需访问主键的索引树。
使用聚簇索引的优势:
1.由于行数据和聚簇索引的叶子节点存储在一起,同一页中会有多条行数据,访问同一数据页不同行记录时,已经把页加载到了Buffer中(缓存器),再次访问时,会在内存中完成访问,不必访问磁盘。这样主键和行数据是一起被载入内存的,找到叶子节点就可以立刻将行数据返回了,如果按照主键Id来组织数据,获得数据更快。
2.辅助索引的叶子节点,存储主键值,而不是数据的存放地址。好处是当行数据放生变化时,索引树的节点也需要分裂变化;或者是我们需要查找的数据,在上一次IO读写的缓存中没有,需要发生一次新的IO操作时,可以避免对辅助索引的维护工作,只需要维护聚簇索引树就好了。另一个好处是,因为辅助索引存放的是主键值,减少了辅助索引占用的存储空间大小。
注:我们知道一次io读写,可以获取到16K大小的资源,我们称之为读取到的数据区域为Page。而我们的B树,B+树的索引结构,叶子节点上存放好多个关键字(索引值)和对应的数据,都会在一次IO操作中被读取到缓存中,所以在访问同一个页中的不同记录时,会在内存里操作,而不用再次进行IO操作了。除非发生了页的分裂,即要查询的行数据不在上次IO操作的换村里,才会触发新的IO操作。
3.因为MyISAM的主索引并非聚簇索引,那么他的数据的物理地址必然是凌乱的,拿到这些物理地址,按照合适的算法进行I/O读取,于是开始不停的寻道不停的旋转。聚簇索引则只需一次I/O。(强烈的对比)
4.不过,如果涉及到大数据量的排序、全表扫描、count之类的操作的话,还是MyISAM占优势些,因为索引所占空间小,这些操作是需要在内存中完成的。
聚簇索引需要注意的地方:
当使用主键为聚簇索引时,主键最好不要使用uuid,因为uuid的值太过离散,不适合排序且可能出线新增加记录的uuid,会插入在索引树中间的位置,导致索引树调整复杂度变大,消耗更多的时间和资源。
建议使用int类型的自增,方便排序并且默认会在索引树的末尾增加主键值,对索引树的结构影响最小。而且,主键值占用的存储空间越大,辅助索引中保存的主键值也会跟着变大,占用存储空间,也会影响到IO操作读取到的数据量。
为什么主键通常建议使用自增id
聚簇索引的数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。如果主键不是自增id,那么可以想 象,它会干些什么,不断地调整数据的物理地址、分页,当然也有其他一些措施来减少这些操作,但却无法彻底避免。但,如果是自增的,那就简单了,它只需要一 页一页地写,索引结构相对紧凑,磁盘碎片少,效率也高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号