
树上前缀和与差分
树上前缀和
设 \(sum_i\) 表示根节点到节点 \(i\) 的权值总和。
则有:
- 对于点权,\(x,y\) 路径上的和为 \(sum_x + sum_y - sum_{lca} - sum_{fa_{lca}}\)。
- 对于边权,\(x,y\) 路径上的和为 \(sum_x + sum_y - 2 \times sum_{lca}\)。
例题:P2420 让我们异或吧
给出一棵带权树,要求求出任意两点 \(u,v\) 之间路径上所有边权的异或和。
利用异或运算的一个核心性质:\(x \oplus x = 0\)(即一个数异或它自己等于 \(0\))。
可以定义一个数组 \(s_i\) 表示从根节点到节点 \(i\) 的路径上所有边权的异或和。
对于任意两点 \(u,v\),它们之间的简单路径异或和实际上就等于 \(s_u \oplus s_v\)。
原理推导
设 \(\text{LCA}(u,v)\) 为 \(u\) 和 \(v\) 的最近公共祖先,树上从 \(u\) 到 \(v\) 的唯一路径可以看作是从 \(u\) 走到 \(\text{LCA}(u,v)\),再从 \(\text{LCA}(u,v)\) 走到 \(v\)。
考虑 \(s_u \oplus s_v\) 的组成:
- \(s_u\) 包含了从 \(\text{root}\) 到 \(\text{LCA}(u,v)\) 的路径异或值,记为 \(P\),以及从 \(\text{LCA}(u,v)\) 到 \(u\) 的路径异或值,记为 \(P_u\),即 \(s_u = P \oplus P_u\)。
- \(s_v\) 包含了从 \(\text{root}\) 到 \(\text{LCA}(u,v)\) 的路径异或值 \(P\),以及从 \(\text{LCA}(u,v)\) 到 \(v\) 的路径异或值,记为 \(P_v\),即 \(s_v = P \oplus P_v\)。
当计算 \(s_u \oplus s_v\) 时,\(s_u \oplus s_v = (P \oplus P_u) \oplus (P \oplus P_v) = (P \oplus P) \oplus (P_u \oplus P_v) = 0 \oplus (P_u \oplus P_v) = P_u \oplus P_v\)。\(P\) 的部分因为异或了两次而被抵消(变成 \(0\)),剩下的正是从 \(u\) 到 \(v\) 的路径上所有边权的异或和。
因此,不需要复杂的 LCA 算法,只需要一次 DFS 预处理即可。
总时间复杂度为 \(O(N + M)\)。
参考代码
#include <cstdio>
#include <vector>
using namespace std;
const int N = 100005;
// 存储边信息的结构体
struct Edge {
int to, w;
};
// 邻接表存储树的结构
vector<Edge> tr[N];
// s[i] 存储从根节点(节点1)到节点 i 的路径异或和
int s[N];
/**
* 深度优先遍历预处理从根节点到每个节点的异或路径长度
* @param u 当前节点
* @param val 从根到父节点的异或和
* @param pre 父节点,用于避免反向遍历
*/
void dfs(int u, int val, int pre) {
s[u] = val;
for (const Edge& e : tr[u]) {
if (e.to != pre) {
dfs(e.to, val ^ e.w, u);
}
}
}
int main()
{
int n;
if (scanf("%d", &n) != 1) return 0;
// 读取 n-1 条边构建树
for (int i = 1; i < n; i++) {
int u, v, w;
scanf("%d%d%d", &u, &v, &w);
tr[u].push_back({v, w});
tr[v].push_back({u, w});
}
// 以 1 为根节点进行 DFS 预处理
dfs(1, 0, 0);
int m;
scanf("%d", &m);
while (m--) {
int u, v;
scanf("%d%d", &u, &v);
// 两点间路径的异或和等于它们到根节点异或和的异或
// 原理:root 到 LCA(u,v) 的路径被异或了两次,自动抵消
printf("%d\n", s[u] ^ s[v]);
}
return 0;
}
例题:P4427 [BJOI2018] 求和
分析:因为 \(k\) 不大,可以把 \(k\) 作为一维信息。预处理出 \(sum_{i,k}\) 表示根节点到节点 \(i\) 的深度的 \(k\) 次方和,这个过程的时间复杂度为 \(O(nk)\)。
要维护的是求和,其具备逆运算,也就是减法,可以把 \((u,v)\) 拆成 \((root, u)\) 和 \((root, v)\) 去掉 \((root, lca)\)。这里因为是对点的计算而不是对边的,因此答案的计算方法是 \(sum_{u,k} + sum_{v, k} - sum_{lca, k} - sum_{fa_{lca},k}\)。
参考代码
#include <cstdio>
#include <vector>
#include <algorithm>
using std::swap;
using std::vector;
const int N = 3e5 + 5;
const int K = 55;
const int LOG = 19;
const int MOD = 998244353;
vector<int> tree[N];
int fa[N][LOG], depth[N], sum[N][K];
void dfs(int u, int pre) {
depth[u] = depth[pre] + 1;
int d = 1;
for (int i = 0; i < K; i++) {
sum[u][i] = (sum[pre][i] + d) % MOD;
d = 1ll * d * depth[u] % MOD;
}
fa[u][0] = pre;
for (int v : tree[u]) {
if (v == pre) continue;
dfs(v, u);
}
}
int lca(int x, int y) {
if (depth[x] < depth[y]) swap(x, y);
int delta = depth[x] - depth[y];
for (int i = LOG - 1; i >= 0; i--)
if (delta & (1 << i)) x = fa[x][i];
if (x == y) return x;
for (int i = LOG - 1; i >= 0; i--) {
if (fa[x][i] != fa[y][i]) {
x = fa[x][i]; y = fa[y][i];
}
}
return fa[x][0];
}
int main()
{
int n; scanf("%d", &n);
for (int i = 1; i < n; i++) {
int x, y; scanf("%d%d", &x, &y);
tree[x].push_back(y);
tree[y].push_back(x);
}
depth[0] = -1;
dfs(1, 0);
for (int i = 1; i < LOG; i++) {
for (int j = 1; j <= n; j++) fa[j][i] = fa[fa[j][i - 1]][i - 1];
}
int m; scanf("%d", &m);
while (m--) {
int i, j, k; scanf("%d%d%d", &i, &j, &k);
int lca_ij = lca(i, j), f = fa[lca_ij][0];
int ans1 = (sum[i][k] + MOD - sum[f][k]) % MOD;
int ans2 = (sum[j][k] + MOD - sum[lca_ij][k]) % MOD;
printf("%d\n", (ans1 + ans2) % MOD);
}
return 0;
}
树上差分
树上差分可以理解为对树上的某一段路径进行差分操作,这里的路径可以类比一维数组的区间进行理解。例如在对树上的一些路径进行频繁操作,并且询问某条边或者某个点在经过操作后的值的时候,就可以运用树上差分思想。
树上差分可以用于快速统计有多少条路径经过每个点或每条边。
点差分
例题:P3128 [USACO15DEC] Max Flow P
问题描述:有 \(n\) 个节点,用 \(n-1\) 条边连接,所有节点都连通。给出 \(k\) 条路径,第 \(i\) 条路径为节点 \(s_i\) 到 \(t_i\)。每给出一条路径,路径上所有节点的权值加 \(1\)。输出最大权值点的权值。
数据范围:\(2 \le n \le 50000, 1 \le k \le 100000\)
分析:树上两点 \(u,v\) 的路径指的是最短路径。可以把 \(u \rightarrow v\) 的路径分为两个部分:\(u \rightarrow LCA(u,v)\) 和 \(LCA(u,v) \rightarrow v\)。
先考虑简单的思路。首先对每条路径求 LCA,分别以 \(u\) 和 \(v\) 为起点到 LCA,把路径上每个节点的权值加 \(1\);然后对所有路径进行类似操作。把路径上每个节点加 \(1\) 的操作的复杂度为 \(O(n)\),共 \(k\) 次操作,会超时。
本题的关键是如何记录路径上每个节点的修改。显然,如果真的对每个节点都记录修改,肯定会超时。我们可以利用差分,因为差分的用途是“把区间问题转换为端点问题”,适用这种情况。
给定数组 \(a\),定义差分数组 \(D[k]=a[k]-a[k-1]\),即数组相邻元素的差。
从差分数组的定义可以推出:\(a[k]=D[1]+D[2]+ \cdots + D[k] = \sum\limits_{i=1}^{k} D[i]\)
这个式子描述了 \(a\) 和 \(D\) 的关系,即“差分是前缀和的逆运算” ,它把求 \(a[k]\) 转换为求 \(D\) 的前缀和。
对于区间 \([L,R]\) 的修改问题,比如把区间内每个元素都加上 \(d\),则可以对区间的两个端点 \(L\) 和 \(R+1\) 做以下操作:
- 把 \(D[L]\) 加上 \(d\);
- 把 \(D[R+1]\) 减去 \(d\)。

对 \(D\) 求前缀和,则可得到 \(a\) 数组,以上的更新相当于:
- \(1 \le x < L\),\(a[x]\) 不变;
- \(L \le x \le R\),\(a[x]\) 增加了 \(d\);
- \(R < x \le N\),\(a[x]\) 不变,因为被 \(D[R+1]\) 中减去的 \(d\) 抵消了。
利用差分能够把区间修改问题转换为只用端点做记录。如果不用差分数组,区间内每个元素都需要修改,时间复杂度为 \(O(n)\);转换为只修改两个端点后,时间复杂度降到 \(O(1)\),这就是差分的重要作用。
把差分思想用到树上,只需要把树上路径转换为区间即可。把一条路径 \(u \rightarrow v\) 分为两部分:\(u \rightarrow LCA(u,v)\) 和 \(LCA(u,v) \rightarrow v\),这样每条路径都可以当成一个区间处理。
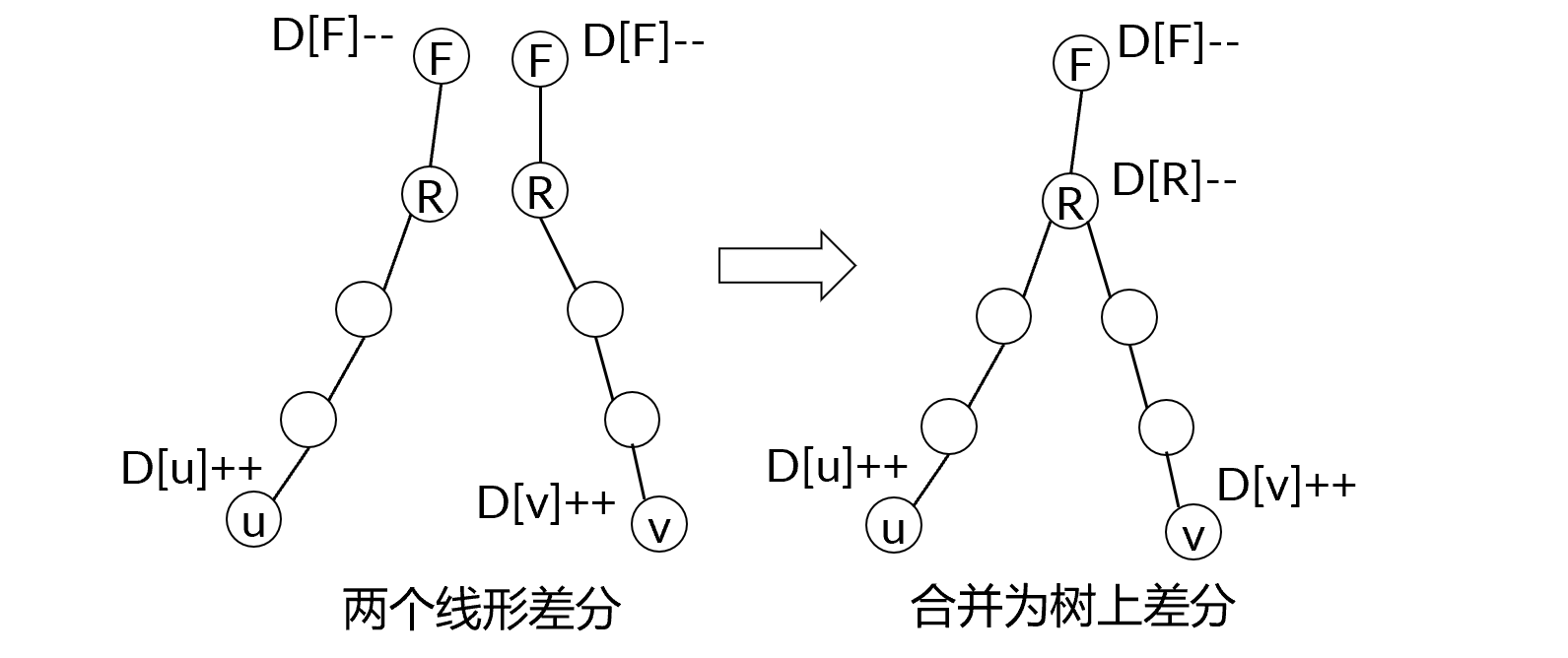
记 \(LCA(u,v)=R\),并记 \(R\) 的父节点为 \(F=fa[R]\),要把路径上每个节点权值加 \(1\),有:
- 路径 \(u \rightarrow R\) 这个区间上,\(D[u]++\),\(D[F]--\);
- 路径 \(v \rightarrow R\) 这个区间上,\(D[v]++\),\(D[F]--\)。
经过以上操作,能通过 \(D\) 计算出 \(u \rightarrow v\) 上每个节点的权值。不过,由于两条路径在 \(R\) 和 \(F\) 这里重合了,这两个步骤把 \(D[R]\) 加了两次,把 \(D[F]\) 减了两次,需要调整为 \(D[R]--\) 和 \(D[F]--\)。
在本题中,对每条路径都用倍增法求一次 LCA,并做一次差分操作。当对于所有路径都操作完成后,再做一次 DFS,求出每个节点的权值,所有权值中的最大值即为答案。
\(k\) 次 LCA 的时间复杂度为 \(O(n \log n + k \log n)\);最后做一次 DFS,时间复杂度为 \(O(n)\);总的时间复杂度为 \(O((n+k) \log n)\)。
参考代码
#include <cstdio>
#include <vector>
#include <algorithm>
using namespace std;
const int N = 50005;
const int LOG = 16;
vector<int> tree[N];
int d[N], fa[N][LOG], a[N], ans;
void dfs(int cur, int pre) {
d[cur] = d[pre] + 1;
fa[cur][0] = pre;
for (int i = 1; i < LOG; i++) fa[cur][i] = fa[fa[cur][i - 1]][i - 1];
for (int nxt : tree[cur])
if (nxt != pre) dfs(nxt, cur);
}
int lca(int x, int y) {
if (d[x] < d[y]) swap(x, y);
int len = d[x] - d[y];
for (int i = LOG - 1; i >= 0; i--)
if (1 << i <= len) {
x = fa[x][i]; len -= 1 << i;
}
if (x == y) return x;
for (int i = LOG - 1; i >= 0; i--)
if (fa[x][i] != fa[y][i]) {
x = fa[x][i]; y = fa[y][i];
}
return fa[x][0];
}
void calc(int cur, int pre) {
for (int nxt : tree[cur])
if (nxt != pre) {
calc(nxt, cur);
a[cur] += a[nxt];
}
ans = max(ans, a[cur]);
}
int main()
{
int n, k;
scanf("%d%d", &n, &k);
for (int i = 1; i < n; i++) {
int x, y;
scanf("%d%d", &x, &y);
tree[x].push_back(y); tree[y].push_back(x);
}
dfs(1, 0); // 计算每个节点的深度并预处理fa数组
while (k--) {
int s, t;
scanf("%d%d", &s, &t);
int r = lca(s, t);
a[s]++; a[t]++; a[r]--; a[fa[r][0]]--; // 树上差分
}
calc(1, 0); // 用差分数组求每个节点的权值
printf("%d\n", ans);
return 0;
}
边差分
例题:P6869 [COCI2019-2020#5] Putovanje
显然针对每一条边只会考虑购买单程票和多程票的一种,这取决于该条边被经过的次数 \(k\),这样一来这条边上的最少花费是 \(\min (k c_1, c_2)\)。
这里需要根据若干条路径计算出每条边经过的次数,可以借助差分思想,注意它和点差分不同。对于边相关的问题,一般我们会将每个点与它父亲节点相连的边与该点绑定,从而将边上信息的维护转化为对点的信息的维护。

参考代码
#include <cstdio>
#include <vector>
#include <algorithm>
using namespace std;
typedef long long LL;
const int N = 200005;
const int LOG = 19;
vector<int> tree[N];
int d[N], fa[N][LOG], cnt[N], a[N], b[N], c1[N], c2[N];
void dfs(int cur, int pre) {
d[cur] = d[pre] + 1;
fa[cur][0] = pre;
for (int i = 1; i < LOG; i++) fa[cur][i] = fa[fa[cur][i - 1]][i - 1];
for (int nxt : tree[cur])
if (nxt != pre) dfs(nxt, cur);
}
int lca(int x, int y) {
if (d[x] < d[y]) swap(x, y);
int len = d[x] - d[y];
for (int i = LOG - 1; i >= 0; i--)
if ((1 << i) <= len) {
x = fa[x][i]; len -= 1 << i;
}
if (x == y) return x;
for (int i = LOG - 1; i >= 0; i--)
if (fa[x][i] != fa[y][i]) {
x = fa[x][i]; y = fa[y][i];
}
return fa[x][0];
}
void calc(int cur, int pre) {
for (int nxt : tree[cur])
if (nxt != pre) {
calc(nxt, cur);
cnt[cur] += cnt[nxt];
}
}
int main()
{
int n;
scanf("%d", &n);
for (int i = 1; i < n; i++) {
scanf("%d%d%d%d", &a[i], &b[i], &c1[i], &c2[i]);
tree[a[i]].push_back(b[i]);
tree[b[i]].push_back(a[i]);
}
dfs(1, 0);
for (int i = 1; i < n; i++) {
int r = lca(i, i + 1);
cnt[i]++; cnt[i + 1]++; cnt[r] -= 2;
}
calc(1, 0);
LL ans = 0;
for (int i = 1; i < n; i++) {
if (d[a[i]] > d[b[i]]) ans += min(1ll * c1[i] * cnt[a[i]], 1ll * c2[i]);
else ans += min(1ll * c1[i] * cnt[b[i]], 1ll * c2[i]);
}
printf("%lld\n", ans);
return 0;
}
例题:P2680 [NOIP2015 提高组] 运输计划
分析:题目的意思是求将一条边边权修改为 \(0\) 后,\(m\) 条路径的最大边权和最小是多少。
最大值最小、最小值最大这类问题往往和二分答案有关。
设当前判断的答案是 \(x\),则路径长度大于 \(x\) 的需要有一条边被改造,但是全局上只能改一条边,所以必须改这些路径的公共边。
可以用树上边差分统计每条边的经过次数,只有经过次数等于要改的路径条数的边是有效的,显然应该改这样的边中边权最大的,求出这个值。
最后检查所有要改的路径,看减去这个值能否使边权和小于等于 \(x\),如果都能做到那么这个答案就可行。
参考代码
#include <cstdio>
#include <utility>
#include <vector>
#include <algorithm>
using std::swap;
using std::max;
using std::vector;
using std::pair;
using edge = pair<int, int>; // (点,边权)
const int N = 300005;
const int LOG = 19;
int n, m, d[N], f[N][LOG], sum[N], cnt[N], a[N], b[N], dis[N], lca[N];
vector<edge> tree[N];
void dfs(int u, int fa) {
for (edge e : tree[u]) {
int v = e.first, w = e.second;
if (v == fa) continue;
d[v] = d[u] + 1; f[v][0] = u;
sum[v] = sum[u] + w;
dfs(v, u);
}
}
int query(int x, int y) {
if (d[x] < d[y]) swap(x, y);
int delta = d[x] - d[y];
for (int i = LOG - 1; i >= 0; i--)
if (delta & (1 << i)) x = f[x][i];
if (x == y) return x;
for (int i = LOG - 1; i >= 0; i--)
if (f[x][i] != f[y][i]) {
x = f[x][i]; y = f[y][i];
}
return f[x][0];
}
void calc(int u, int fa) { // 差分之后计算每条边经过次数
for (edge e : tree[u]) {
int v = e.first;
if (v == fa) continue;
calc(v, u);
cnt[u] += cnt[v];
}
}
bool check(int x) {
for (int i = 1; i <= n; i++) cnt[i] = 0;
int c = 0; // 需要改变多少个运输计划
for (int i = 1; i <= m; i++) {
if (dis[i] > x) {
c++; cnt[a[i]]++; cnt[b[i]]++; cnt[lca[i]] -= 2;
}
}
calc(1, 0);
int maxw = 0;
for (int i = 1; i <= n; i++) {
// f[i][0]->i
int fa = f[i][0], w = sum[i] - sum[fa];
if (cnt[i] == c && w > maxw) maxw = w;
}
for (int i = 1; i <= m; i++)
if (dis[i] - maxw > x) return false;
return true;
}
int main()
{
scanf("%d%d", &n, &m);
int maxw = 0;
for (int i = 1; i < n; i++) {
int u, v, w; scanf("%d%d%d", &u, &v, &w);
if (w > maxw) maxw = w;
tree[u].push_back({v, w});
tree[v].push_back({u, w});
}
dfs(1, 0);
for (int j = 1; j < LOG; j++)
for (int i = 1; i <= n; i++)
f[i][j] = f[f[i][j - 1]][j - 1];
int r = 0;
for (int i = 1; i <= m; i++) {
scanf("%d%d", &a[i], &b[i]);
// 预处理每个运输计划的lca和完成时长
lca[i] = query(a[i], b[i]);
dis[i] = sum[a[i]] + sum[b[i]] - 2 * sum[lca[i]];
if (dis[i] > r) r = dis[i];
}
// 控制二分上下界可提高效率
int ans = r, l = max(r - maxw, 0);
while (l <= r) {
int mid = (l + r) / 2;
if (check(mid)) {
r = mid - 1; ans = mid;
} else {
l = mid + 1;
}
}
printf("%d\n", ans);
return 0;
}
子树差分
例题:P3605 [USACO17JAN] Promotion Counting P
给定一棵 \(n\) 个点的树,每个点有点权,求每个点子树内点权大于自身的点的数量,\(n \le 10^5\)。
解题思路
大于某个数值的点的数量显然可以通过树状数组维护,关键是怎么精准地计算到单棵子树内。
如果在 DFS 过程中更新树状数组,这样维护的是 DFS 过程中到目前这个点为止各个数值出现的次数,不一定是单棵子树。
考虑 DFS 的过程中一个点会进出(递归与回溯)各一次,实际上进入这个点时,该点的子树信息还没更新到树状数组中,而出这个点时,该点的子树信息已经都加入到树状数组中,因此这两个时间点查询的差值就是该子树的贡献。这种思想被称为子树差分。
参考代码
#include <cstdio>
#include <vector>
#include <algorithm>
const int N = 100005;
int n, p[N], ans[N], c[N];
std::vector<int> tr[N], num;
int lowbit(int x) {
return x & -x;
}
void add(int x) {
while (x <= n) {
c[x]++; x += lowbit(x);
}
}
int query(int x) {
int res = 0;
while (x > 0) {
res += c[x]; x -= lowbit(x);
}
return res;
}
int discretize(int x) {
return std::lower_bound(num.begin(), num.end(), x) - num.begin() + 1;
}
void dfs(int u) {
int tmp = query(n) - query(p[u]);
add(p[u]);
for (int v : tr[u]) {
dfs(v);
}
ans[u] = query(n) - query(p[u]) - tmp;
}
int main()
{
scanf("%d", &n);
for (int i = 1; i <= n; i++) {
scanf("%d", &p[i]);
num.push_back(p[i]);
}
std::sort(num.begin(), num.end());
num.erase(std::unique(num.begin(), num.end()), num.end());
for (int i = 1; i <= n; i++) p[i] = discretize(p[i]);
for (int i = 2; i <= n; i++) {
int boss; scanf("%d", &boss);
tr[boss].push_back(i);
}
dfs(1);
for (int i = 1; i <= n; i++) printf("%d\n", ans[i]);
return 0;
}
例题:P1600 [NOIP2016 提高组] 天天爱跑步
解题思路
测试点 \(1 \sim 5\)
暴力做法是对于每条路径,模拟 \(s \rightarrow lca\) 和 \(t \rightarrow lca\) 的爬升过程,看到达时间是否正好是 \(w_x\),统计结果。时间复杂度为 \(O(nm)\)。
测试点 \(6 \sim 8\)
当树退化成一条链时,对于每个观察员 \(x\) 而言,相当于询问有多少条 \(s = x - w_x\) 并且 \(t \ge x\) 的路径,以及有多少条 \(s = x + w_x\) 并且 \(t \le x\) 的路径。因此可以记录每个起点对应哪些终点,排序后二分即可计算出终点大于等于或小于等于 \(x\) 的数量。
注意,当 \(w_x = 0\) 时,观察员 \(x\) 能观察到的就是以 \(x\) 为起点的路径数量。
测试点 \(9 \sim 12\)
相当于所有路径的起点都是根节点。此时只有深度与 \(w\) 相等的观察员能观察到运动员,数量则是看其子树内有多少可能的终点。
测试点 \(13 \sim 16\)
相当于所有路径的终点都是根节点。若观察员 \(x\) 的深度为 \(d_x\),则他能观察到的是起点 \(s\) 在 \(x\) 的子树内并且满足 \(d_s - d_x = w_x\) 的运动员。\(d_s - d_x = w_x\) 相当于 \(d_s = d_x + w_x\),可利用桶的思想和子树差分求出满足条件的数量。
参考代码
#include <cstdio>
#include <vector>
#include <algorithm>
using std::swap;
using std::vector;
using std::sort;
using std::lower_bound;
using std::upper_bound;
const int N = 300005;
const int LOG = 19;
vector<int> tree[N];
int n, m, w[N],lca[N], d[N], s[N], t[N], ans[N];
namespace Chain {
void solve() {
vector<vector<int>> v; // v[i]表示以i为起点的路径有哪些终点
v.resize(n + 1);
for (int i = 1; i <= m; i++) {
v[s[i]].push_back(t[i]);
}
for (int i = 1; i <= n; i++)
sort(v[i].begin(), v[i].end());
for (int i = 1; i <= n; i++) {
if (w[i] == 0) {
ans[i] = v[i].size(); continue;
}
int st = i - w[i];
if (st >= 1) { // 起点等于i-w[i],终点大于等于i的数量
ans[i] += v[st].size() - (lower_bound(v[st].begin(), v[st].end(), i) - v[st].begin());
}
st = i + w[i];
if (st <= n) { // 起点等于i+w[i],终点小于等于i的数量
ans[i] += (upper_bound(v[st].begin(), v[st].end(), i) - v[st].begin());
}
}
}
};
namespace S1 {
int cnt[N]; // cnt[i]表示以i为根的子树内有多少个终点
void dfs(int u, int fa) {
for (int v : tree[u]) {
if (v == fa) continue;
d[v] = d[u] + 1;
dfs(v, u);
cnt[u] += cnt[v];
}
if (d[u] == w[u]) ans[u] = cnt[u];
}
void solve() {
for (int i = 1; i <= m; i++) cnt[t[i]]++;
dfs(1, 0);
}
};
namespace T1 {
int cnt[N * 2]; // cnt[i]作为d[起点]的计数桶
vector<int> bg[N]; // bg[i]表示以i为起点的路径有哪些
void dfs(int u, int fa) {
int tmp = cnt[w[u] + d[u]];
for (int v : tree[u]) {
if (v == fa) continue;
d[v] = d[u] + 1;
dfs(v, u);
}
for (int i : bg[u]) cnt[d[s[i]]]++;
ans[u] = cnt[w[u] + d[u]] - tmp;
}
void solve() {
for (int i = 1; i <= m; i++) bg[s[i]].push_back(i);
dfs(1, 0);
}
};
namespace BF {
int f[N][LOG];
void dfs(int u, int fa) {
for (int v : tree[u]) {
if (v == fa) continue;
f[v][0] = u; d[v] = d[u] + 1;
dfs(v, u);
}
}
int query(int x, int y) {
if (d[x] < d[y]) swap(x, y);
int delta = d[x] - d[y];
for (int i = LOG - 1; i >= 0; i--)
if (delta & (1 << i)) x = f[x][i];
if (x == y) return x;
for (int i = LOG - 1; i >= 0; i--)
if (f[x][i] != f[y][i]) {
x = f[x][i]; y = f[y][i];
}
return f[x][0];
}
void solve() {
dfs(1, 0);
for (int j = 1; j < LOG; j++)
for (int i = 1; i <= n; i++)
f[i][j] = f[f[i][j - 1]][j - 1];
for (int i = 1; i <= m; i++) {
int l = query(s[i], t[i]);
int tm = 0, u = s[i];
while (u != l) {
if (tm == w[u]) ans[u]++;
u = f[u][0];
tm++;
}
if (tm == w[u]) ans[u]++;
u = t[i]; tm = d[s[i]] + d[t[i]] - 2 * d[l];
while (u != l) {
if (tm == w[u]) ans[u]++;
u = f[u][0];
tm--;
}
}
}
};
int main()
{
scanf("%d%d", &n, &m);
for (int i = 1; i < n; i++) {
int s, t; scanf("%d%d", &s, &t);
tree[s].push_back(t);
tree[t].push_back(s);
}
for (int i = 1; i <= n; i++) scanf("%d", &w[i]);
for (int i = 1; i <= m; i++) scanf("%d%d", &s[i], &t[i]);
if (n == 99994) { // 链
Chain::solve();
} else if (n == 99995) { // s=1
S1::solve();
} else if (n == 99996) { // t=1
T1::solve();
} else { // 暴力
BF::solve();
}
for (int i = 1; i <= n; i++) printf("%d ", ans[i]);
return 0;
}
测试点 \(17 \sim 20\)
考虑每条路径,分析路径对观察员的贡献。
一条路径可以分为上行部分和下行部分。设 \(d_i\) 表示点 \(i\) 在树上的深度。
对于路径的上行部分,\(d_s - d_x = w_x\) 的点会对观察员 \(x\) 产生贡献,即 \(d_s = w_x + d_x\),并且这样的起点要在 \(x\) 的子树内。
对于路径的下行部分,\(d_s - d_{lca} + d_x - d_{lca} = w_x\) 的点会对观察员 \(x\) 产生贡献,即 \(d_s - 2 \times d_{lca} = w_x - d_x\),并且这样的终点 \(t\) 要在 \(x\) 的子树内。
统计答案时就是统计满足上述表达式的路径数,所以可以用一个桶来统计相应的式子的每种取值有多少个,到达一个点时,把它作为起点和终点时相应式子取值的结果统计进桶里。
注意此时桶里并不是子树中的统计结果,而是 DFS 过程中之前经过的所有的点的,而此时想要求的是子树内的,这可以用回溯时的结果减去刚进入这个点时的结果,这个操作就是子树差分:在进入的时候先减,要回溯的时候再加回来即可。
另外,一条路径的贡献会在 \(s\) 和 \(t\) 的 \(lca\) 处消除,所以在回溯时还要把 \(lca\) 是这个点的路径的起点和终点相应的式子取值在桶里的计数减 \(1\)。
最后还有一点特殊情况,一条路径正好在其 \(lca\) 处产生了贡献,此时该路径的贡献会被算 \(2\) 次,因为它同时符合上行路径和下行路径的那个等式,所以如果对于某条路径而言 \(d_{s} - d_{lca} = w_{lca}\),那就是在 \(lca\) 上有贡献,要减去其中 \(1\) 次重复的贡献。
可以用动态数组(STL vector)存储一个点会作为哪些路径的 \(s, t, lca\)。
参考代码
#include <cstdio>
#include <vector>
#include <algorithm>
using std::swap;
using std::vector;
const int N = 300005;
const int LOG = 19;
vector<int> tree[N], bg[N], ed[N], as_lca[N];
// d: 节点深度
int n, m, w[N], d[N], f[N][LOG], s[N], t[N], lca[N], ans[N];
// 上行、下行路径的贡献,w-d可能为负数,可以+n将其偏移,因此数组开两倍空间
int cnt_up[N * 2], cnt_down[N * 2];
void dfs(int u, int fa) {
for (int v : tree[u]) {
if (v == fa) continue;
f[v][0] = u; d[v] = d[u] + 1;
dfs(v, u);
}
}
int query(int x, int y) {
if (d[x] < d[y]) swap(x, y);
int delta = d[x] - d[y];
for (int i = LOG - 1; i >= 0; i--)
if (delta & (1 << i)) x = f[x][i];
if (x == y) return x;
for (int i = LOG - 1; i >= 0; i--)
if (f[x][i] != f[y][i]) {
x = f[x][i]; y = f[y][i];
}
return f[x][0];
}
void calc(int u, int fa) {
// 子树差分:进入的时候先减
int tmp_up = cnt_up[w[u] + d[u]];
int tmp_down = cnt_down[w[u] - d[u] + n];
cnt_up[w[u] + d[u]] = cnt_down[w[u] - d[u] + n] = 0;
for (int v : tree[u]) {
if (v == fa) continue;
calc(v, u);
}
for (int i : bg[u]) cnt_up[d[s[i]]]++;
for (int i : ed[u]) cnt_down[d[s[i]] - 2 * d[lca[i]] + n]++;
ans[u] = cnt_up[w[u] + d[u]] + cnt_down[w[u] - d[u] + n];
// 一条路径的贡献会在lca处消除
for (int i : as_lca[u]) {
cnt_up[d[s[i]]]--;
cnt_down[d[s[i]] - 2 * d[lca[i]] + n]--;
}
// 子树差分:回溯的时候加回来
cnt_up[w[u] + d[u]] += tmp_up;
cnt_down[w[u] - d[u] + n] += tmp_down;
}
int main()
{
scanf("%d%d", &n, &m);
for (int i = 1; i < n; i++) {
int s, t; scanf("%d%d", &s, &t);
tree[s].push_back(t);
tree[t].push_back(s);
}
dfs(1, 0);
for (int j = 1; j < LOG; j++)
for (int i = 1; i <= n; i++)
f[i][j] = f[f[i][j - 1]][j - 1];
for (int i = 1; i <= n; i++) scanf("%d", &w[i]);
for (int i = 1; i <= m; i++) {
scanf("%d%d", &s[i], &t[i]);
lca[i] = query(s[i], t[i]);
bg[s[i]].push_back(i);
ed[t[i]].push_back(i);
as_lca[lca[i]].push_back(i);
}
calc(1, 0);
for (int i = 1; i <= m; i++) {
// 上行路径和下行路径在lca处产生了重复贡献,减去一次
if (d[s[i]] - d[lca[i]] == w[lca[i]]) ans[lca[i]]--;
}
for (int i = 1; i <= n; i++) printf("%d ", ans[i]);
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号