Android OpenGLES3绘图:ransform-Feedback变换反馈粒子系统
https://www.jianshu.com/p/0b66c00d7073
iOS 计算和读取的例子
https://wiki.jikexueyuan.com/project/modern-opengl-tutorial/tutorial28.html
PC上解释比较清晰的粒子系统
https://mathweb.ucsd.edu/~sbuss/MathCG2/OpenGLsoft/ParticlesTransformFeedback/PTFexplain.html
PC上极简的粒子系统,有win可执行文件
https://github.com/pwambach/webgl2-particles
WebGL的极简粒子系统,展示效果不错,项目完整
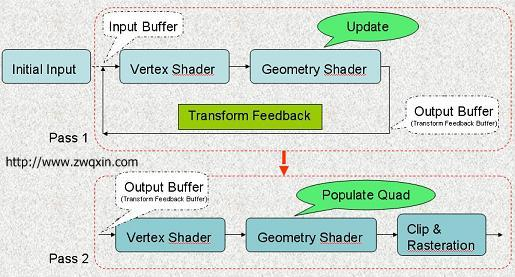
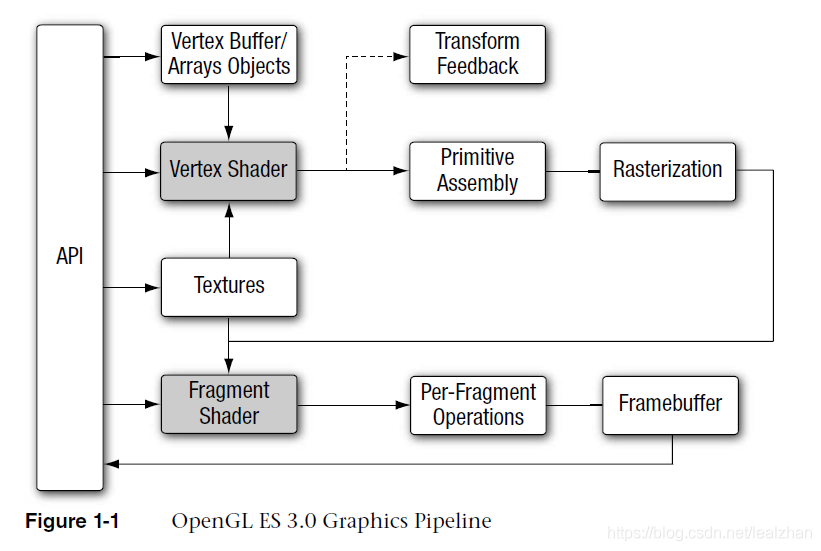
Transform Feedback变换反馈是将顶点着色器的计算结果输出到GPU的缓存中,然后下一次绘制可以直接将这个缓存输入到顶点着色器。这个过程使用GPU内存,不需要CPU去复制或读取数据。
下面用变换反馈实现一个简单的粒子系统。
1 粒子系统
先实现一个粒子系统,不用变换反馈。创建很多点,设置随机的位置和速度,用glDrawArrays(GL_POINTS, 0, MAX_COUNT)画点,在着色器里根据传入的时间计算点的位置并更新。
public class TransformFeedbackRenderer extends BaseRender {
int program;
int[] vao;
int[] vbo;
static int MAX_COUNT = 100000;
float[] pos = new float[MAX_COUNT * 4]; // x,y,vx,vy
Random r = new Random();
float[] time = {0f, 0f, 0f}; // time,centerX,centerY
@Override
public void onSurfaceCreated(GL10 gl, EGLConfig config) {
initAll();
program = ShaderUtils.loadProgramTransformFeedback();
// 分配内存空间,每个浮点型占4字节空间
ByteBuffer posBuffer = ByteBuffer
.allocateDirect(pos.length * 4)
.order(ByteOrder.nativeOrder());
posBuffer.position(0);
posBuffer.asFloatBuffer().put(pos);
vao = new int[1];
glGenVertexArrays(1, vao, 0);
glBindVertexArray(vao[0]);
vbo = new int[1];
glGenBuffers(1, vbo, 0);
glBindBuffer(GL_ARRAY_BUFFER, vbo[0]);
glBufferData(GL_ARRAY_BUFFER, MAX_COUNT * 4 * 4, posBuffer, GL_STATIC_DRAW);
// Load the vertex data
glVertexAttribPointer(0, 2, GL_FLOAT, false, 2 * 4, 0);
glEnableVertexAttribArray(0);
glVertexAttribPointer(1, 2, GL_FLOAT, false, 2 * 4, 2 * 4);
glEnableVertexAttribArray(1);
glBindBuffer(GL_ARRAY_BUFFER, 0);
glBindVertexArray(0);
glClearColor(0.0f, 0.0f, 0.0f, 1.0f);
}
@Override
public void onSurfaceChanged(GL10 gl, int width, int height) {
glViewport(0, 0, width, height);
// glViewport(-(height - width) / 2, 0, height, height);
this.width = width;
this.height = height;
}
int width, height;
@Override
public void onDrawFrame(GL10 gl) {
super.onDrawFrame(gl);
// Clear the color buffer
glClear(GL_COLOR_BUFFER_BIT);
// Use the program object
glUseProgram(program);
time[0] += 0.01;
int loc = glGetUniformLocation(program, "time");
glUniform3fv(loc, 1, time, 0);
glBindVertexArray(vao[0]);
glDrawArrays(GL_POINTS, 0, MAX_COUNT);
}
void initAll() {
for (int i = 0; i < pos.length; i++) {
pos[i] = (float)r.nextInt(1000) / 1000;
if (i % 4 < 2) {
pos[i] = (pos[i] - 0.5f) * 2;
} else {
pos[i] = pos[i] - 0.5f;
}
}
}
}
transform_feedback_v.glsl
#version 300 es
layout (location = 0) in vec2 vPosition;
layout (location = 1) in vec2 vVelocity;
uniform vec3 time;
uniform vec2 center;
out vec2 vPos;
out vec2 vVel;
void main() {
vPos = vPosition;
vVel = vVelocity;
gl_PointSize = 5.0;
float cx = time.g;
float cy = time.b;
float dx = (cx - vPos.x) * time.r;
float dy = (cy - vPos.y) * time.r;
float x = vPos.x + vVel.x * time.r + dx;
float y = vPos.y + vVel.y * time.r + dy;
gl_Position = vec4(x, y, 0.0, 1.0);
}

效果如图,这个极简的粒子系统性能很不错。一百万个粒子在我的骁龙865手机上能够满帧运行。
如此流畅的原因是数据是一次性发送到GPU,后续的计算都在GPU。这样有一个缺点,就是每次计算用的都是顶点数据的初始值,没法在上一次的计算结果的基础上计算,就会有局限,不能实现复杂的过程。如果想利用计算结果,可以用内存映射把GPU数据复制出来,再输入给vbo进行下一次绘制,这样性能肯定会有损耗。想要无损使用GPU数据缓存,就得用变换反馈了。
2 添加变换反馈
为了添加变换反馈,这几天我在网上搜索了大量的资料,包括各种各样的Demo,它们实现的方式千奇百怪:有C++的、WebGL的、iOS的、PC的、不用vao的、不用tfo(变换反馈对象)的、不交替变换只打印数据的、禁止光栅化的、加fence同步屏障的。
在这些资料基础上我总结出了最简单的实现方式。
2.1 编译Shader
在顶点着色器中加入输出变量vPos,在glLinkProgram之前用glTransformFeedbackVaryings设置这个变量字符串。
#version 300 es
layout (location = 0) in vec2 vPosition;
layout (location = 1) in vec2 vVelocity;
out vec2 vPos;
...
public static int loadProgramTransformFeedback() {
int vShader = ShaderUtils.loadShader(GL_VERTEX_SHADER, loadAssets("transform_feedback_v.glsl"));
int fShader = ShaderUtils.loadShader(GL_FRAGMENT_SHADER, loadAssets("transform_feedback_f.glsl"));
// return linkProgram(vShader, fShader, new String[]{"vPos", "vVel"});
return linkProgram(vShader, fShader, new String[]{"vPos"});
}
private static int linkProgram(int vShader, int fShader, String[] transformFeedbackVaryings) {
int program = glCreateProgram();
if (program == 0) {
Log.e("chao", "program == 0");
return 0;
}
glAttachShader(program, vShader);
glAttachShader(program, fShader);
if (transformFeedbackVaryings != null) {
glTransformFeedbackVaryings(program, transformFeedbackVaryings, GL_INTERLEAVED_ATTRIBS);
}
glLinkProgram(program);
int[] linkStatus = new int[1];
glGetProgramiv(program, GL_LINK_STATUS, linkStatus, 0);
if (linkStatus[0] == 0) {
String log = glGetProgramInfoLog(program);
Log.e("chao", "linkProgram fail " + log);
glDeleteProgram(program);
return 0;
}
return program;
}
2.1 添加tfo变换反馈对象
用glGenTransformFeedbacks创建两个tfo,然后用glBindBufferBase方法分别绑定一个vbo(原来的vao、vbo初始化都不用修改)。
注意:变换反馈对象的本质是绑定一块内存,让计算结果输出到这块内存。它可以直接绑定vbo。这跟vbo原来绑定的vao完全不冲突。也就是说,一个vbo可以同时跟vao和tfo绑定。这让下一步交替切换很方便。
tfo = new int[2];
glGenTransformFeedbacks(2, tfo, 0);
for (int i = 0; i < 2; i++) {
glBindVertexArray(vao[i]);
glBindBuffer(GL_ARRAY_BUFFER, vbo[i]);
glBufferData(GL_ARRAY_BUFFER, MAX_COUNT * 4 * 2, buffer, GL_DYNAMIC_DRAW);
// Load the vertex data
glVertexAttribPointer(0, 2, GL_FLOAT, false, 2 * 4, 0);
glEnableVertexAttribArray(0);
// glVertexAttribPointer(1, 2, GL_FLOAT, false, 2 * 4, 2 * 4);
// glEnableVertexAttribArray(1);
glBindTransformFeedback(GL_TRANSFORM_FEEDBACK, tfo[i]);
glBindBufferBase(GL_TRANSFORM_FEEDBACK_BUFFER, 0, vbo[i]);
}
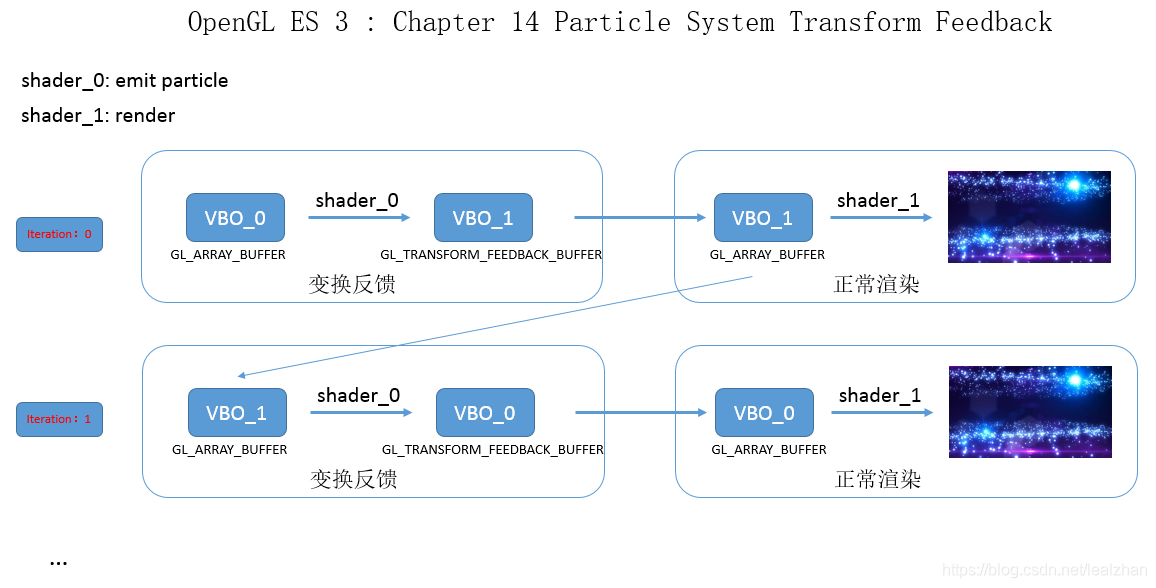
2.2 交替切换tfo
用i0表示当前序号,它在0和1之间变换。
首先绑定tfo[0],接收输出的顶点数据,因为tfo[0]绑定了vbo[0],vao[0]也绑定了vbo[0],相当于数据输出到vao[0]了。用glBeginTransformFeedback开启变换反馈,绑定vao[1]画点,然后用glEndTransformFeedback结束变换反馈。为什么绑定vao[1]画点呢,因为vao[1]绑定了vbo[1],在开启了变换反馈下画点就相当于把vbo[1]的数据传给了tfo[0],tfo[0]经过计算,把数据输出到vbo[0]。数据流是这样的:vbo[1] -> tfo[0] -> vbo[0]。
i0变换后,把tfo和vao序号同时改变即可,数据流是:vbo[0] -> tfo[1] -> vbo[1]。
这样数据就在vbo[0]和vbo[1]之间交替流动,不需要经过CPU,相当于在GPU里直接使用缓存。在顶点着色器里就可以直接使用上一步的计算结果了。
int i0 = 0;
@Override
public void onDrawFrame(GL10 gl) {
super.onDrawFrame(gl);
// Clear the color buffer
glClear(GL_COLOR_BUFFER_BIT);
// Use the program object
glUseProgram(program);
time[0] += 0.01;
int loc = glGetUniformLocation(program, "time");
glUniform3fv(loc, 1, time, 0);
if (i0 == 0) {
// 绑定tfo[0],接收输出的顶点数据,数据相当于输出到vao[0]了
glBindTransformFeedback(GL_TRANSFORM_FEEDBACK, tfo[0]);
glBeginTransformFeedback(GL_POINTS);
// 绑定vao[1],输入顶点数据
glBindVertexArray(vao[1]);
glDrawArrays(GL_POINTS, 0, MAX_COUNT);
glEndTransformFeedback();
} else {
// 绑定tfo[1],接收输出的顶点数据,数据相当于输出到vao[1]了
glBindTransformFeedback(GL_TRANSFORM_FEEDBACK, tfo[1]);
glBeginTransformFeedback(GL_POINTS);
// 绑定vao[0],输入顶点数据
glBindVertexArray(vao[0]);
glDrawArrays(GL_POINTS, 0, MAX_COUNT);
glEndTransformFeedback();
}
// 交换
i0 = 1 - i0;
}
2.3 输出多变量问题
一开始我准备用tfo输出vPos和vVel两个vec2类型的变量,但是输出结果一直错乱, 找了很多地方也没解决问题。但是当我把输出变量改成只有一个vPos,问题就莫名其妙地解决了,变换反馈能正常运行了,这就说明主要流程没有问题。只是使用多个输出变量时,顶点数据在某一步写入或读取时出了问题。这个问题我还在查找,如果有大佬知道原因,请赐教一下。
3 变换反馈粒子系统
在Github上看到这个WebGL实现的粒子系统,它还有演示的网站Live Demo,效果不错。同事说有点水墨中国风的样子。那么我把它搬到手机上来。
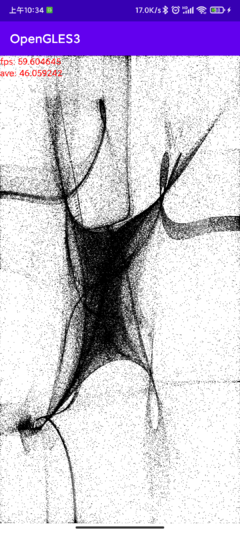
该项目绘制的核心代码在calc_vertex.js文件里,稍微修改就能使用了。它的逻辑是:取屏幕上一个点作为中心,所有的点受到这个中心的引力,向它加速移动。引力转换为加速度,加速度转换为速度,根据当前点的速度和位置算出下个时间点的速度和位置,输出到vec4 vPos里面(由于我前面遇到的问题,这里使用一个vec4打包位置和速度)。
变换反馈的部分在前面基础上不用修改。
#version 300 es
layout (location = 0) in vec4 aPos;
//layout (location = 1) in vec2 vVelocity;
out vec4 vPos;
//out vec2 vVel;
uniform vec3 time;
float PARTICLE_MASS = 1.0;
float GRAVITY_CENTER_MASS = 100.0;
float DAMPING = 2e-6;
void main() {
vec2 gravityCenter = time.gb;
float r = distance(aPos.xy, gravityCenter);
vec2 direction = gravityCenter - aPos.xy;
float force = PARTICLE_MASS * GRAVITY_CENTER_MASS / (r * r) * DAMPING;
float maxForce = min(force, DAMPING * 10.0);
vec2 acceleration = force / PARTICLE_MASS * direction;
vec2 newVelocity = aPos.zw + acceleration;
vec2 newPosition = aPos.xy + newVelocity;
vec2 v_velocity = newVelocity * 0.99;
vec2 v_position = newPosition;
// bounce at borders
if (v_position.x > 1.0 || v_position.x < -1.0) {
v_velocity.x *= -0.5;
}
if (v_position.y > 1.0 || v_position.y < -1.0) {
v_velocity.y *= -0.5;
}
vPos = vec4(v_position, v_velocity * 0.99);
gl_Position = vec4(v_position, 0.0, 1.0);
gl_PointSize = 2.0;
}
中心点可以根据屏幕触摸位置更新。
glSurfaceView.setOnTouchListener(new View.OnTouchListener() {
@Override
public boolean onTouch(View v, MotionEvent event) {
if (render instanceof TransformFeedbackRenderer) {
((TransformFeedbackRenderer) render).updateCenter(event.getX(), event.getY());
}
return true;
}
});
float[] time = {0f, 0f, 0f}; // time,centerX,centerY
public void updateCenter(float x, float y) {
time[1] = (x / width - 0.5f) * 2;
time[2] = -(y / height - 0.5f) * 2;
}
int loc = glGetUniformLocation(program, "time");
glUniform3fv(loc, 1, time, 0);
4 一些注意点
禁用光栅化和计算绘制分离
有的Demo提到做变换反馈时用glEnable(GL_RASTERIZER_DISCARD)来禁用光栅化。一开始我以为必须这样,其实这并不是必要的过程。也就是说,变换反馈不影响正常绘制,变换反馈的计算结果可以同时输出到缓存和绘制到屏幕;顶点着色器可以同时输出结果到变换反馈的缓存和片段着色器。如果做简单的Demo,没有必要禁止光栅化,也没有必要为变换反馈使用一套单独的着色器和program。
禁用光栅化的使用场景是将变换反馈顶点计算与最终绘制分离,需要使用两套着色器程序,一套用来做变换反馈计算顶点数据,一套用来真正绘制。
大致过程如下,我没有真正实现,有兴趣可以实现一下。
int program, tfProgram;
int vao,vbo,tfo;
int vao1,vbo1,tfo1;
// 禁用光栅化,使用变换反馈程序tfProgram,绑定vao输入,输出到tfo1(绑定了vao1)
glUseProgram(tfProgram);
glEnable(GL_RASTERIZER_DISCARD);
glBindTransformFeedback(GL_TRANSFORM_FEEDBACK, tfo1);
glBeginTransformFeedback(GL_POINTS);
glBindVertexArray(vao);
glDrawArrays(GL_POINTS, 0, particles);
glEndTransformFeedback();
// 开启光栅化,使用绘图程序program,绑定vao1输入(tfo1的计算结果),绘制到屏幕
glDisable(GL_RASTERIZER_DISCARD);
glUseProgram(program);
glBindVertexArray(vao1);
glDrawArrays(GL_POINTS, 0, particles);
fence同步
有的Demo提到用fence同步来防止绘制不完整,这个应该是在多线程或更复杂的场景中使用,先插入一个fence,在其他线程等待,完成后删除它:
fenceSyncObject = GLES30.glFenceSync(GLES30.GL_SYNC_GPU_COMMANDS_COMPLETE, 0)
GLES30.glWaitSync(fenceSyncObject, 0, GLES30.GL_TIMEOUT_IGNORED)
GLES30.glDeleteSync(fenceSyncObject)
glDrawTransformFeedback
有的Demo在变换反馈时用glDrawTransformFeedback方法绘制,OpenGL ES3应该没有这个方法,用普通的glDrawArrays方法即可。
我的思考
变换反馈用一种特殊的方式实现了GPU缓存,相比普通的GPU缓存来说它没那么直观好理解。它的优点在于把缓存用GPU并行机制分配给顶点着色器,省去了从数组里遍历或者用下标“找点”的过程,有比较好的性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号