
初识AI大模型,ollama使用,llama factory大模型微调,lama.cpp模型转换guff
最近了解了下生成式AI对话,下面是自己的一些尝试记录。
- ollama 安装及使用
1、安装
我是在windows环境下安装的,很简单,访问:https://ollama.com/ ,下载windows安装包,打开安装就行了。
cmd输入ollama -v检验是否安装成功。
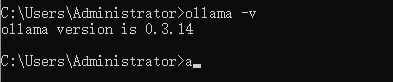
2、配置
在环境变量的用户变量中加入如下几个:

OLLAMA_HOST ollma服务启动的端口。
OLLAMA_MODELS 模型下载保存的位置。
OLLAMA_ORIGINS 绑定访问的ip。这里*号就是整个局域网都可以访问。
3、使用
下面是api的调用,model就是要使用的模型名字,prompt就是输入指令。ollama提供很多接口,有兴趣查官网查查询。
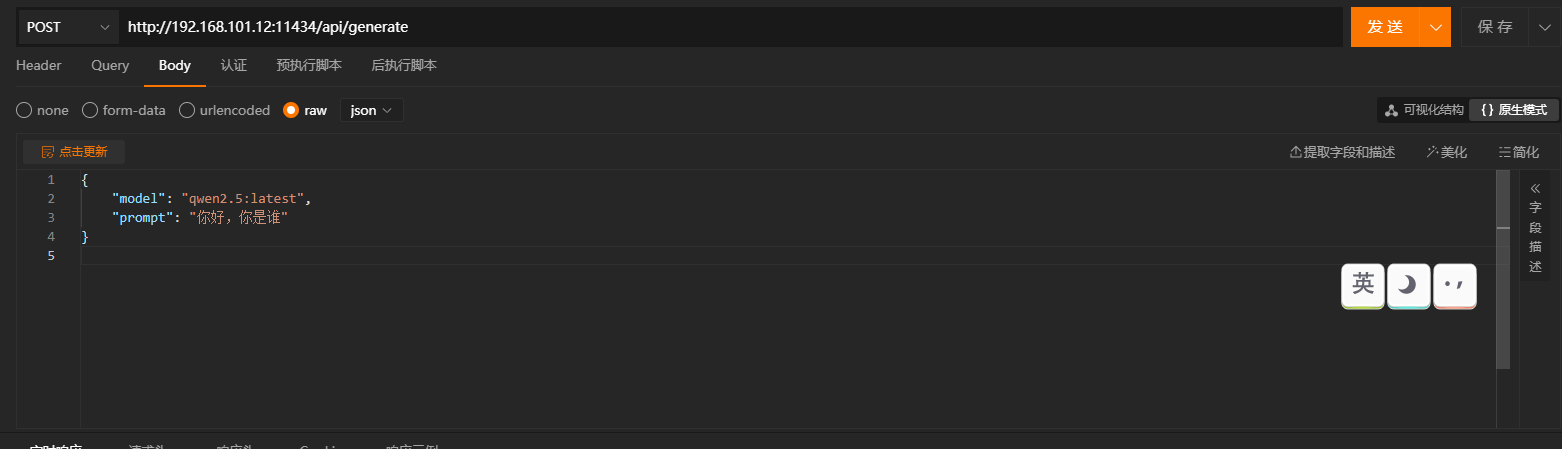
接下来说下常见的命令行指令
ollama list 查询已安装的模型。
ollama run xxx 启动模型,如果模型没安装会自动下载,模型下载地址:library (ollama.com)
ollama rm xx 删除已安装的模型
- llama factory 使用
1、下载
访问 GitHub - hiyouga/LLaMA-Factory: Unified Efficient Fine-Tuning of 100+ LLMs (ACL 2024) 下载源码,当然也可以通过docker等方式,我这里使用源码启动。请保证本地有python环境。
下载解压后在项目目录执行如下命令:
pip install -e ".[torch,metrics]"
2、启动
执行 llamafactory-cli webui。会自动打开浏览器,就进入了微调训练的web界面。
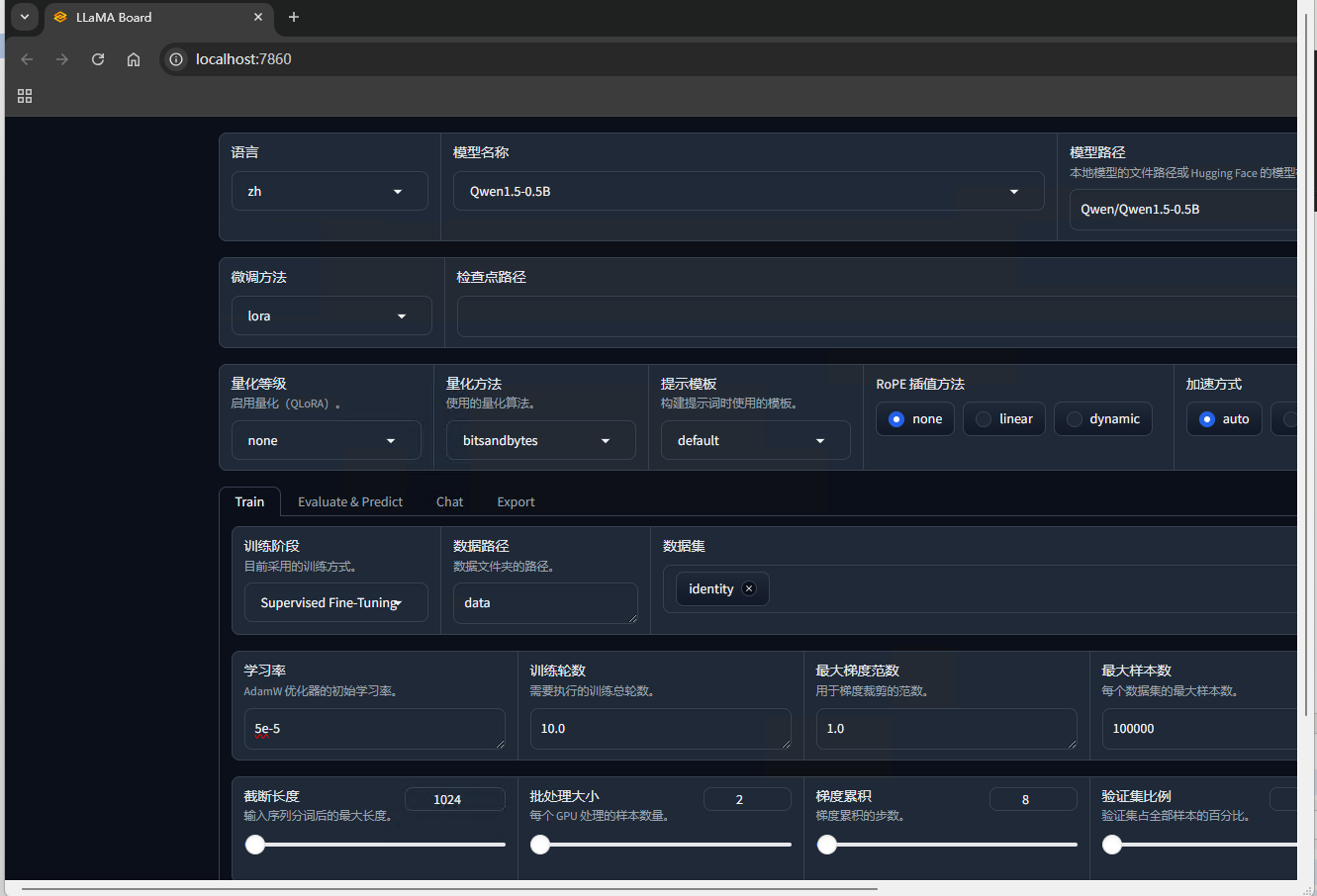
3、训练数据集准备
在data目录下新建一个自定义文件,格式参考identity.json,这里的训练数据非常重要,在最近的学习中了解到数据会影响后续的训练结果,并且这个数据阶段还有很重要的岗位。
自定义数据准备好后,在dataset_info.json文件中增加对应的描述,还是参考identity部分的数据。
4、模型微调训练
在web界面选择训练的基座模型,因为我电脑没有显卡,这里选择的最小的通义千问1.5版本的0.5B模型。然后训练方式选择lora模型,数据集选择你新增的数据。点击开始训练就可以开始了。
我这里训练了50个数据参数,因为没有显卡的原因,所以很慢。
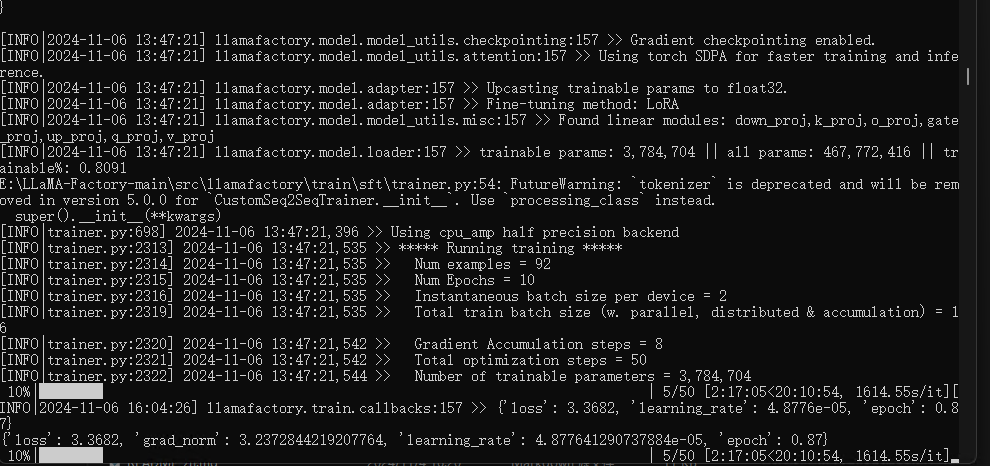
- 模型合并
微调训练完成后,在目录的saves文件夹下就有你训练的结果,以基座模型/自定义的输出目录命名。因为我们使用的lora方式训练,需要把基座模型和我们训练的结果合并。至于啥是lora模式,感兴趣的可以网上搜下。
在examples/merge_lora目录下新建自己的yaml配置文件。
model_name_or_path 基座模型地址,如果不知道去哪里下,搜索魔塔社区。
adapter_name_or_path 微调训练模型地址,就是上面说的训练输出的目录。
export_dir 合并后导出的目录。
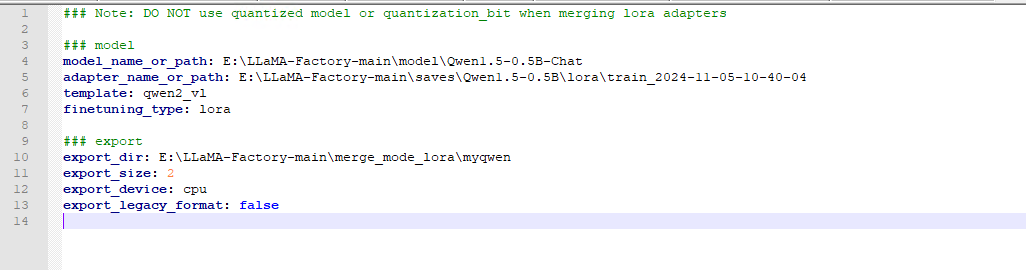
文件创建后,在项目目录执行如下命令合并。
llamafactory-cli export examples/merge_lora/myqwen_merge.yaml
- 模型转换
1、编写配置文件
在合并后导出的目录新建一个Modelfile文件,注意没有文件格式,文件内容:FROM E:\LLaMA-Factory-main\merge_mode_lora\myqwen\my_qwen.gguf

2、llama.cpp下载
下载地址:GitHub - ggerganov/llama.cpp: LLM inference in C/C++
解压后cmd进入目录,执行:
python convert_lora_to_gguf.py E:\LLaMA-Factory-main\merge_mode_lora\myqwen --outtype f16 --vocab-type bpe --outfile E:\LLaMA-Factory-main\merge_mode_lora\myqwen\my_qwen.gguf
E:\LLaMA-Factory-main\merge_mode_lora\myqwen 就是合并的模型目录,E:\LLaMA-Factory-main\merge_mode_lora\myqwen\my_qwen.gguf就是模型转换的路径和模型名称。
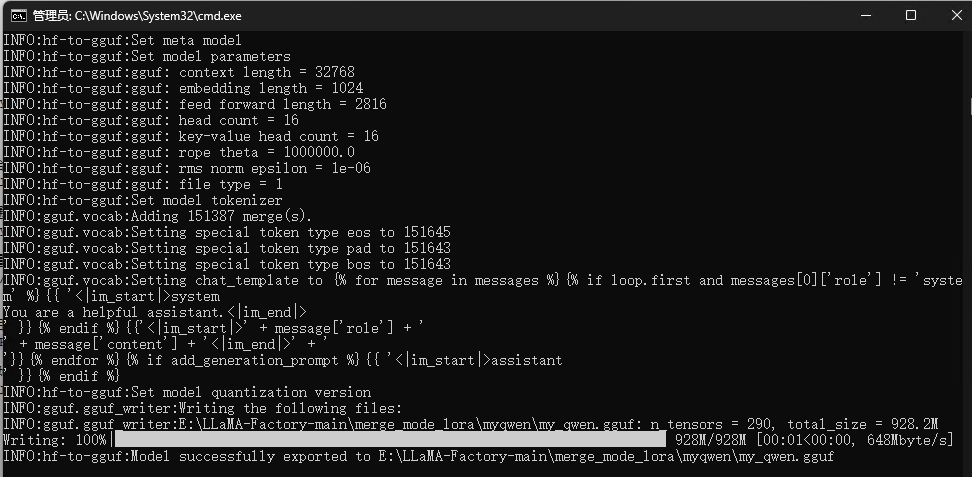
- 导入模型
cmd进入模型转换的输出目录,执行 ollama create my_qwen -f Modelfile 开始导入模型。
然后使用ollama list查看是否导入成功,使用ollama run my_qwen 就可以使用我们新的模型了。
总得来说,有很多包都需要自己想办法,不然要么就下载很慢,要么根据就不能下载。想要自己的微调模型在垂直领域的问答有一定效果,首先得要硬件支持,其次得要海量的有效数据支持,目前我这两都达不到,就当学习了。
本文来自博客园,作者:Rolay,转载请注明原文链接:https://www.cnblogs.com/rolayblog/p/18530365



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步