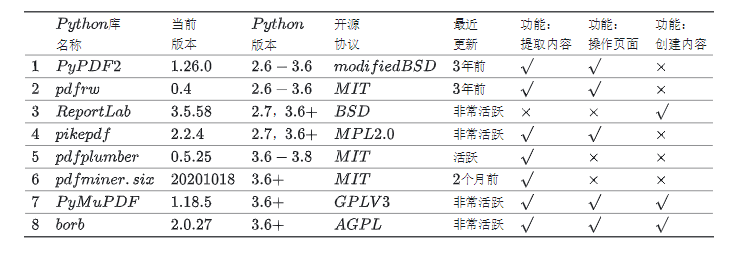
常用PDF库总结
本帖内容源自 , 在此仅做记录
PDF(Portable Document Format)是一种便携文档格式,便于跨操作系统传播文档。PDF文档遵循标准格式,因此存在很多可以操作PDF文档的工具,Python自然也不例外。本文从功能、开源协议及社区活跃度三方面对比7个常用的Python第三方库,以便根据具体需求选择合适的库。
常见PDF库
PyPDF2 (已不再维护,继任者PyPDF4)
由于PyPDF2似乎更知名,故本文以其作为条目列出。
PyPDF、PyPDF2及PyPDF4的渊源
pdfrw
自身不能创建新内容,但是集成了ReportLab,可以兼容ReportLab生成新页面。
ReportLab
商业版的开源版本,专业创建PDF内容如文本、图表等。
pikepdf
基于C++的QPDF,对标PyPDF2和pdfrw;偏向PDF底层。
pdfplumber
基于pdfminer.six,除了读取文本、形状(矩形、直线/曲线)外,还能解析表格。
几个提取PDF表格的Python库的对比。
pdfminer.six
pdfminer的社区维护版(pdfminer自2020年起不再积极维护)。
PyMuPDF
基于mupdf,功能全面,并以处理速度著称[3]。
borb
纯Python库,支持读、写、操作PDF文档,兼顾底层和高级应用。
对比
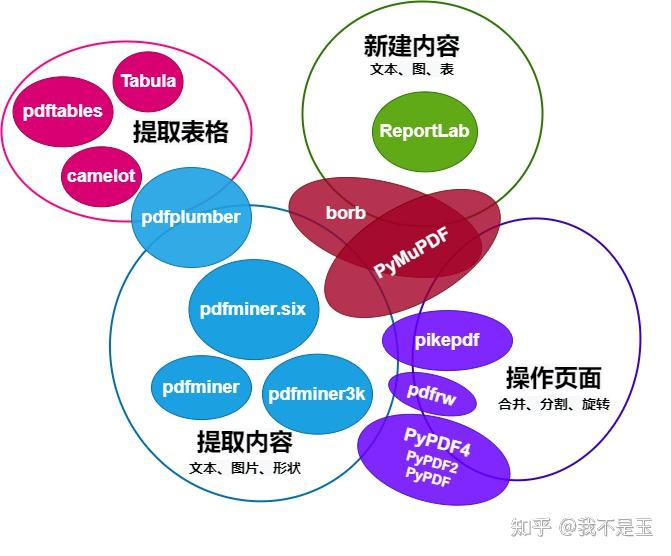
本文将Python操作PDF的能力从大粒度上分成提取内容、操作页面和创建内容三方面。前两者分别是针对已经存在的PDF文档的读和写操作,最后一项从内容上创建新文档。
提取内容如文本、图片、元信息
操作页面特指操作已经存在的页面,例如分割、合并、裁剪、旋转等
创建内容指创建或修改页面内容,例如文本、图片、形状
考虑到时效性,以下对比列出了撰写本文时(2021.01)相应的最新版本。修订:borb于 2022.06 新加入对比,时间点以此为准。
总结
PyPDF2系列、pdfrw及pikepdf专注对已经存在的PDF的操作(分割、合并、旋转等),前两者基本处于停止维护的状态。
pdfplumber及其依赖pdfminer.six专注PDF内容提取,例如文本(位置、字体及颜色等)和形状(矩形、直线、曲线),前者还有解析表格的功能。
ReportLab专注PDF页面内容(文本、图、表等)的创建。
PyMuPDF和borb同时支持读、写及PDF页面操作,功能最为全面。其中,PyMuPDF尤其以速度快著称,而borb是新开发并深得好评的库,潜力无穷。但是,二者同为GPL家族的开源协议,对商用不太友好。
对商用不太友好指的是支持免费使用,但是要求引用其的程序也必须遵守相应协议即开源。如果需要闭源使用的话,需要向作者申请付费的商用授权。
下面是openAI的回答:
- PyPDF2:用于处理PDF文件的开源库,可以读取、分割、合并、提取文本和元数据等操作。
- pdfminer:另一个处理PDF文件的开源库,可以提取文本、表格和图像。
- tabula:用于提取PDF表格的库,可以轻松地从PDF表格中读取数据。
- Camelot:用于从PDF中提取表格的库,可以自动检测表格的位置和结构,并可以以多种格式输出数据。
- pdftabextract:用于从PDF文件中提取表格的库,支持多种表格布局和格式,可以输出为CSV、JSON和Excel格式。
- pdf2image:用于将PDF文件转换为图像的库,可以将PDF文件转换为JPEG、PNG和TIFF等格式的图像。
最后以下图结束本文。
最近在使用pymupdf库将某个pdf文档里的某一页另存为png图片时,发现图片里的图表线条变得特别浅,你水印一样。大部分pdf文档是没这种问题的。
相关代码示例如下:
import pymupdf
doc = pymupdf.open(pdf_file)
doc[10].get_pixmap(dpi=500).save(png_file)
于是尝试换另一个库pdf2image, 虽然保存的图片线条仍然很浅,但是要比pymupdf好一些。
代码如下:
from pdf2image import convert_from_path
images = convert_from_path(
pdf_file,
dpi=500,
first_page=10,
last_page=10,
fmt="png"
)
images[0].save(png_file)
这两个库背后用了不同的渲染引擎。 分别是Poppler 和 MuPDF。 后者性能相对好一些。前者需要额外安装Poppler。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号