论文精读:Swarm Learning for decentralized and confidential clinical machine learning
Swarm Learning for decentralized and confidential clinical machine learning
群体学习:用于去中心化和隐私加密的临床机器学习
基本信息
- 期刊 / 会议:Nature
- 作者:Stefanie Warnat-Herresthal, Hartmut Schultze...
- 发表年月:2021.5.26
- 关键词:群体学习、边缘计算、区块链、联邦学习、分布式机器学习
- 引用:Warnat-Herresthal, S., Schultze, H., Shastry, K.L. et al. Swarm Learning for decentralized and confidential clinical machine learning. Nature 594, 265–270 (2021).
论文概述
1. 解决了什么问题?
-
to facilitate the integration of any medical data from any data owner worldwide without violating privacy laws
不违反隐私法的前提下,方便整合全球的医疗数据
-
SL would be an ideal strategy for independent producer of medical data to quickly team up to increase the power to generate robust and reliable machine learning-based disease or outcome prediction classifier without the need to share data or relocate data to central cloud storages
SL将是医疗数据独立生产者的理想策略,可以快速合作,以增强生成稳健可靠的基于机器学习的疾病或结果预测分类器的能力,而无需共享数据或将数据重新定位到中央云存储
-
SL together with transcriptomics but also other medical data is a very promising approach to democratize the use of AI among the many stakeholders in the domain of medicine while at the same time resulting in more data confidentiality, privacy, data protection and less data traffic.
SL利用血液转录组数据对疾病做出预测
2. 为什么研究这个问题?
-
there is an increasing divide between what is technically possible and what is allowed, because of privacy legislation
技术可能性 & 数据隐私法
-
As medicine is inherently decentral, the volume of local data is often insufficient to train reliable classifiers
个体数据量太少,需要全局化数据
-
Furthermore, such star-shaped architectures(federated learning) decrease fault tolerance.
联邦学习的中心化服务器仍存在风险
-
Considering the difficulty to quickly negotiate data sharing protocols or contracts during an epidemic or pandemic outbreak
在疫情或大流行爆发期间,快速协商数据共享协议或合同存在困难
3. 如何解决这个问题?
群体学习:分布式机器学习+区块链,安全加入参与者,动态选择模型参数合并者
- 数据拥有者在本地存储数据
- 不交换原始数据
- 保证数据隐私
- 去中心化
- 参与者拥有同等权限的参数合并
- 保护机器学习模型免受攻击
论文结构
- Abstract
- Concept of Swarm Learning
- Swarm Learning predicts leukaemias(白血病)
- Swarm Learning to identify tuberculosis(肺结核)
- Identification of COVID-19(新冠肺炎)
- Discussion
- Methods
- Pre-processing
- PBMC transcriptome dataset (dataset A)
- Whole-blood-derived transcriptome datasets (datasets B, D and E)
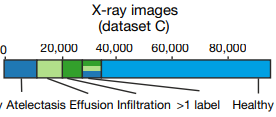
- X-ray dataset (dataset C)
- The Swarm Learning framework
- Hardware architecture used for simulations
- Computation and algorithms
- Neural network algorithm
- Least absolute shrinkage and selection operator (LASSO)
- Parameter tuning
- Parameter merging
- Quantification and statistical analysis
- Reporting summary
- Pre-processing
- Data availability
- Code availability
- Acknowledgements
- Extended data figures and tables
- Supplementary information
背景知识
1. 前述知识
-
临床试验去中心化:借助智能化临床试验管理平台及远程通讯技术,以受试者为中心开展临床试验
De Brouwer, W., Patel, C.J., Manrai, A.K. et al. Empowering clinical research in a decentralized world. npj Digit. Med. 4, 102 (2021). https://doi.org/10.1038/s41746-021-00473-w
阐述了边缘计算、零信任架构、联邦学习等技术在去中心化临床试验中的价值和应用前景
-
联邦学习
-
分布式机器学习
-
区块链
-
概念:区块链技术是利用块链式数据结构验证与存储数据,利用分布式节点共识算法生成和更新数据,利用密码学的方式保证数据传输和访问的安全、利用由自动化脚本代码组成的智能合约,编程和操作数据的全新的分布式基础架构与计算范式。
-
类型:
- 公有区块链(Public Block Chains)
- 行业区块链(Consortium Block Chains)
- 私有区块链(Private Block Chains)
-
特征:
- 去中心化
- 数据难以篡改
-
架构:
-
关键技术:
- 分布式账本
- 非对称加密
- 共识机制
- 智能合约
-
-
区块链智能合约
- 概念:智能合约是能够自动执行合约条款的计算机程序,智能合约由代码进行定义,并有代码强制执行,完全自动且无法干预。智能合约事前执行,不像传统合约一样事后执行。
- 创建合约步骤:
- 多方用户共同参与制定一份智能合约
- 合约通过P2P网络扩散并存入区块链
- 区块链构建的智能合约自动执行
-
敏感性(sensitivity):在患有疾病的所有人中,诊断正确的人有多少?
特异性(specificity):在未患疾病的所有人中,诊断正确的人有多少?

2. 相关工作
- 本地学习(Local Learning)
- 中心化学习(Central Learning)
- 联邦学习(Federated Learning)
3. 对比性分析
-
相较于本地学习,结合各方数据,训练共同模型,性能要比每个节点本地训练效果要好
-
相较于中心化学习,数据不集中,保护数据隐私
-
相较于联邦学习
- 不需要中心协调服务器,提高弹性和容错性
- 联邦学习仅支持星型拓扑结构,SL支持全连接、网格、星形、树和混合拓扑
结论
SL的性能要比单个节点本地训练效果要好,且更稳定,并且性能相近于中心化学习。
具体方法
1. 架构(framework)
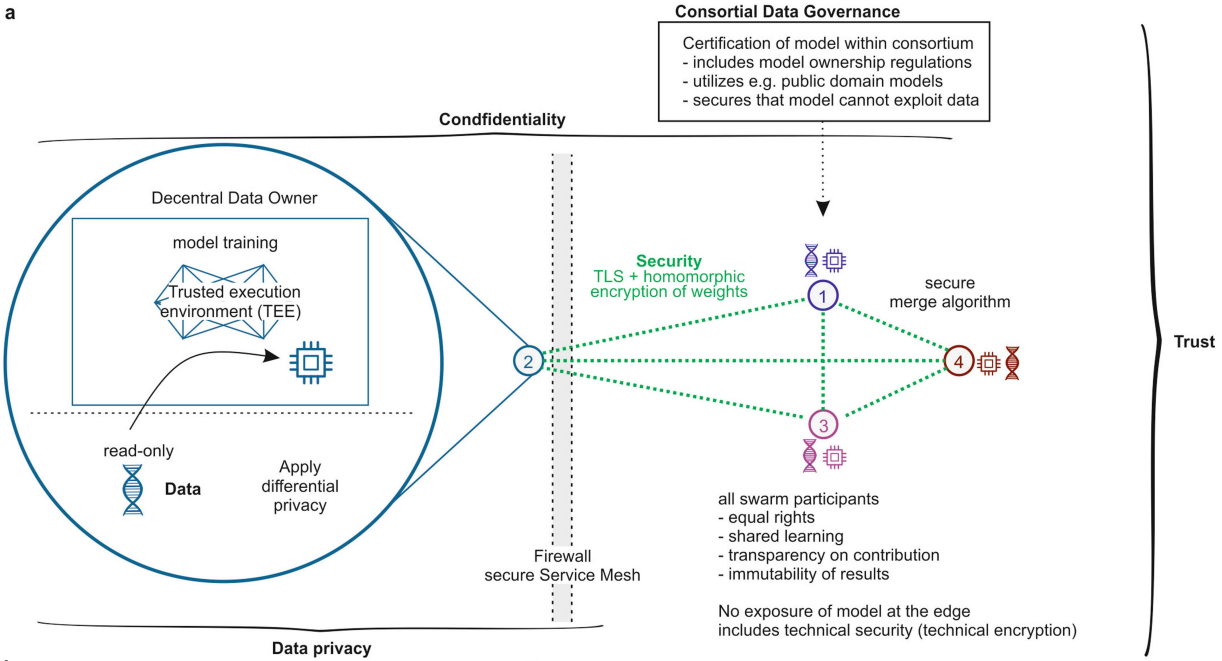
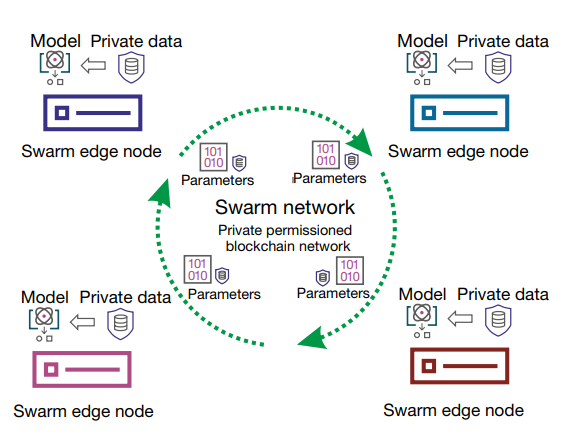
SL framework:
-
Swarm ML:分布式机器学习:多节点训练公共模型
- 提供API,实现本地训练
- 调用API,会自动插入SL hooks,以此来与SL交换参数和合并参数
-
Swarm Network:区块链:去中心化控制、可伸缩性、容错功能
-
维护全局模型状态信息
-
跟踪训练进程
-
协调SL工作,保持去中心化的SL全局一致的状态,保证所有的操作和相应的状态转换同步进行(区块链智能合约)
-
选举参数合并的领导(每一次同步),以实现容错率和自我修复机制(不至于导致中央服务器炸了,没办法合并参数)
Only metadata is written to the blockchain. The model itself is not stored in the blockchain.
Swarm Learning uses a blockchain network primarily to provide a consistent system state to all the nodes without requiring any central coordinator.
-
SL framework可以在异构设备上进行

整个过程:
-
node通过区块链智能合约加入SL
-
本地训练模型
-
到达合并模型参数的时间节点后,导出模型参数
-
通过Swarm API发给动态选择的聚合节点(每次第一个加入聚合的节点)
-
聚合节点聚合模型参数
-
通过Swarm API获取聚合后的参数
-
更新本地模型参数,并计算性能指标
-
如果达到停止标准(可以在callback API中设置),则停止,否则继续迭代
合并参数算法、leader选举规则由区块链智能合约来定义
SL Library(Swarm API)
-
Swarm Network container
- software to setup and initialize the Swarm Network(设置、初始化)
- management commands to control the Swarm Network(管理)
- start/stop SL tasks(启停任务)
- This container also encapsulates the blockchain software(区块链)
-
Swarm ML container
- decentralized training(去中心化训练)
- integration with ML frameworks(集成ML框架)
- it exposes APIs for ML models to interact with SL(提供ML与SL交互的API)
-
Swarm callback API:(ML model --> SL)
callback:callback是一个对象,它可以在训练的各个阶段(例如,在一个时期的开始或结束,单个批次之前或之后等)执行操作
Keras callback API:(tensorflow)
1、BaseLogger 回调:会积累训练轮平均评估的回调函数。 2、TerminateOnNaN 回调:如果损失值为非数字(NaN),则训练过程停止。 3、ProgbarLogger 回调:用于确定在 Keras 进度条中打印到标准输出的内容。 4、History 回调: 5、ModelCheckpoint 回调:可用于在每个 epoch 后自动保存一个模型,或者只保存最好的一个。 6、EarlyStopping 回调:确保在损失值不再提高时停止训练过程。 7、RemoteMonitor 回调:将 TensorFlow 训练事件发送到远程监视器,例如日志系统。 8、LearningRateScheduler 回调:基于一个scheduler函数在一个 epoch 开始之前更新学习率。 9、TensorBoard 回调:允许我们使用TensorBoard实时监控训练过程。 10、ReduceLROnPlateau 回调:如果损失值不再提高,则降低学习率。 11、CSVLogger 回调:将 epoch 的结果流式传输到 CSV 文件。 12、LambdaCallback:允许我们定义可以作为回调执行的简单函数。SwarmCallback is a custom callback class that is built on the Keras Callback class
SwarmCallback provides options to control the SL processes
- Import the SwarmCallback class from the Swarm Library(导包)
- Instantiate an object of the SwarmCallback class(实例化callback对象)
- Pass the object to the list of callbacks in Keras training code(在模型训练的时候,将对象传递给Keras回调列表)
2. 算法(Computation and algorithms)
- Neural network algorithm(神经网络)
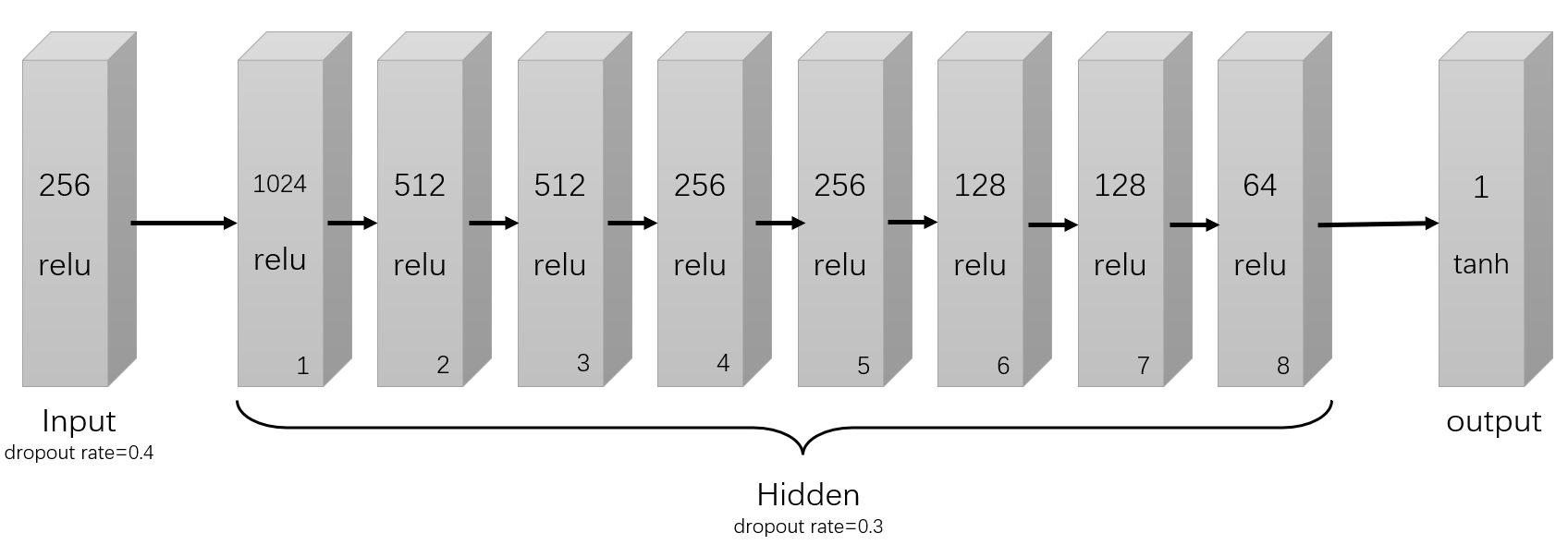
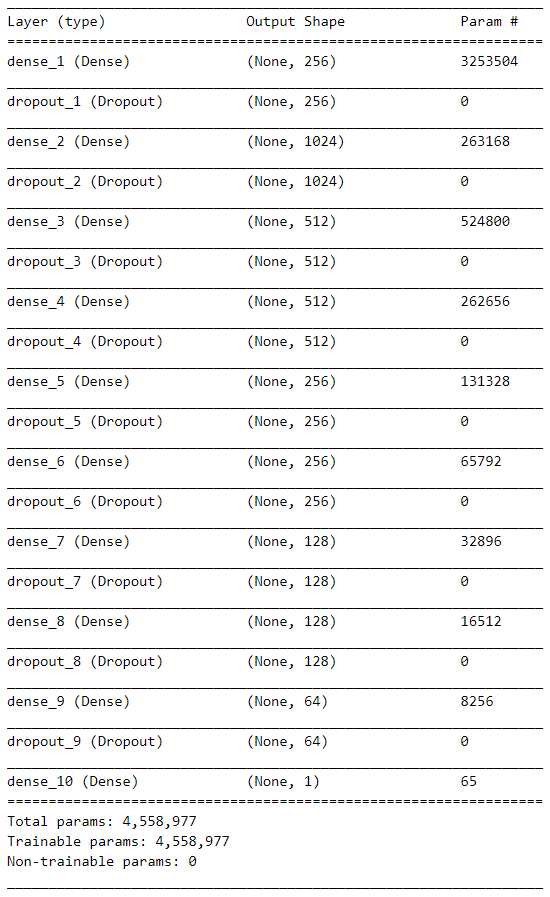
优化器:Adam
损失函数:binary_crossentropy(二分类交叉熵)
-
Least absolute shrinkage and selection operator (LASSO)
仅有一层模型(1个神经网络节点),激活函数是linear
优化器:随机梯度下降SGD
损失函数:均方误差
-
Parameter tuning(参数调优)
-
利用SL API中的adaptive_rv参数在模型收敛的基础上动态调整合并频率
-
对于结核病和COVID-19,所有情况下的测试退出率都降至10%
-
对于TB场景,使用SL callback API的node_weight参数为拥有更多案例样本的节点赋予更多权重
-
-
Parameter merging(参数合并)
-
参数合并在每个同步间隔时进行合并
-
采用加权平均的参数合并方式
\[P_M=\frac{\sum_{k=1}^{n}(W_k\times P_k)}{n\times\sum_{k=1}^{n}W_k} \]\(P_M\):合并后的参数
\(W_k\):第k个节点的权重
\(P_k\):第k个节点的参数
\(n\):参与合并的节点数量
-
用不带权值的平均值来合并神经网络和LASSO算法的参数
-
3. SL实现(The Swarm Learning implementation)
SL(Swarm Learning) Node: the core of Swarm Learning(执行ML)
- collaboration with all the other SL nodes in the network(与其他节点协作)
- regularly shares its learnings with the other nodes and incorporates their insights(共享知识并融入见解)
- act as an interface between the user model application and other Swarm Learning components(用户模型应用和其他SL组件的接口)
- distributing and merging model weights in a secured way using the Swarm Learning file server(使用SL文件服务器,安全的分发和合并参数)
SN(Swarm Network) Node: form the blockchain network(组建区块链)
- uses Ethereum as the underlying blockchain platform(使用以太坊作为底层区块链平台)
- maintain and track progress(维护并跟踪进程)
- use this state and progress information to co-ordinate the working of the other swarm learning components(使用状态和进程信息来协调其他组件)
- Sentinel node is responsible for initializing the blockchain network, the first node to start(哨兵节点率先启动,初始化区块链网络)
ML Node:
- train and iteratively update the model(训练和更新模型)
- For each ML node, there is a corresponding SL node in the Swarm Learning framework, which performs the Swarm training(每一个ML节点对应一个SL节点,ML本地训练,SL点对点训练)
SWOP(Swarm Operator) Node:
- managing Swarm Learning operations
- manage hundreds of Swarm Learning nodes(对SL节点的动态启停)
- execute task(执行task,ML)
SWCI(Swarm Learning Command Interface) Node:
connect to any of the SN nodes in a given Swarm Learning framework to manage the framework(管理framework)
manage task & taskrunner(管理task,对task的调度)
registers the specified Swarm Learning training contract into the Swarm Learning network(注册智能合约)
License Server:
- installs and manages the license that is required to run the Swarm Learning framework(安装、管理许可证)
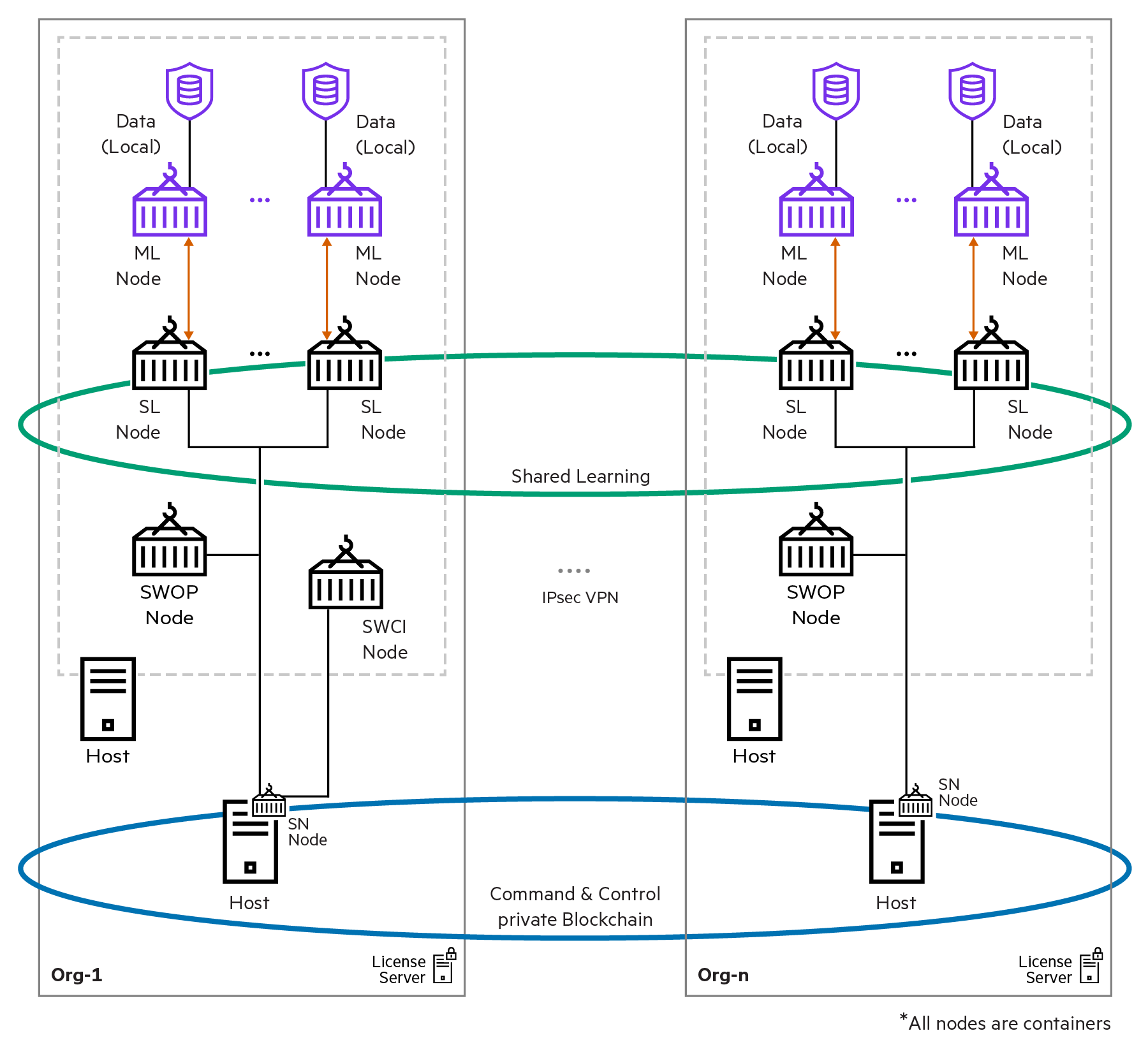
-
Initialization and onboarding(初始化和加入集群)
- 主要就是协商SL的一些公共配置
- 参数共享协议
- 保证各个组织间节点可见
- 模型训练的预期结果
- 可配置的一些超参数
- 节点间同步频率
- 共同训练的模型
- 激励制度
- 主要就是协商SL的一些公共配置
-
Installation and configuration(安装和配置)
-
下载并安装SL平台,在SL平台完成对之前协商结果的配置
-
SL平台启动,将节点连接到Swarm Network(节点底层的IP网络连接覆盖上区块链网络)
-
节点启动过程有序:对等发现节点先启动,其他节点后启动
对等体发现(peer-discovery)是在对等体(P2P)网络中定位节点或对等体进行数据通信的过程。它由P2P客户端执行,它使用协议和其他网络通信技术在本地和远程网络中寻找对等体。
-
-
Integration and training(集成和训练)
- Enrollment(注册)
- Swarm smart contract
- records its relevant attributes in the contract
- Local model training(本地模型训练)
- train the local model iteratively
- exports the parameter values
- shares them to the other nodes
- signals the other nodes that it is ready for parameter-sharing
- Parameter sharing(共享参数)
- 开始标志: the number of nodes that are ready for parameter sharing reaches a certain minimum threshold value specified during initialization(参与节点数量达到阈值)
- The leader uses the URI information of all the participants, to retrieve the parameters from each node to merge the parameters(leader利用URI来获取节点参数并合并参数)
- Parameter merging and update(参数合并和更新)
- merges the parameters according to the configured merging algorithm
- signals to the other nodes that new parameters are available
- downloads the new parameters
- updates its local model
- Stopping criterion check(停止准则检查)
- the nodes evaluate the model with the updated parameter values using their local data to calculate the validation metrics
- When it discovers that all merge participants have signaled completion, the leader merges the local validation metric numbers to calculate the global metric numbers and marks the synchronization complete(合并本地性能度量,形成全局性能值)
- Testing(测试)
4. 统计分析(Quantification and statistical analysis)
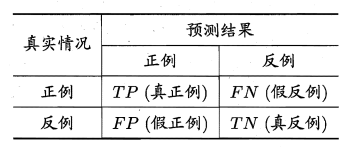
- sensitivity(敏感性):\(\frac{TP}{TP+FN}\)
- specificity(特异性):\(\frac{TN}{TN+FP}\)
- accuracy(准确性):\(\frac{TP+TN}{TP+FP+TN+FN}\)
- F1-score:\(\frac{2TP}{FP+FN+2TP}\)
- AUC:ROC曲线面积
实验
1. 数据集
包含两种类型的数据:血液转录组数据、X射线图像数据
-
PBMC transcriptome dataset (dataset A):GSE122517(含有重复样本)
datasetA1:GSE122505
datasetA2:GSE122511
datasetA3:GSE122515

- Whole-blood-derived transcriptome datasets (datasets B, D and E)
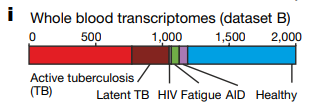
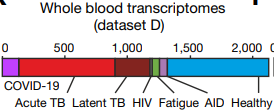
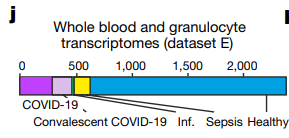
(datasetE由8个独立的子数据集共同构成,E7:恢复期的新冠肺炎病例,E8:富含粒细胞的新冠肺炎病例)
2. 实验环境
For all simulations provided in this project we used two HPE Apollo 6500 Gen 10 servers, each with four Intel(R) Xeon(R) CPU E5-2698 v4 @ 2.20 GHz, a 3.2-terabyte hard disk drive, 256 GB RAM, eight Tesla P100 GPUs, a 1-GB network interface card for LAN access and an InfiniBand FDR for high speed interconnection and networked storage access.
2台HPE Apollo 6500 Gen 10 server:
- 4个Intel(R) Xeon(R) CPU E5-2698 v4 @ 2.20 GHz
- 3.2TB hard disk drive
- 256 GB RAM
- 8个Tesla P100 GPU
- LAN:1-GB network interface card
- InfiniBand FDR
each node is a docker container with access to GPU resources
16,694次实验
26个AML(急性髓细胞白血病)场景、4个ALL(急性淋巴细胞白血病)场景、13个TB(肺结核)场景、1个胸片检测肺不张、积液和/或浸润场景,18个COVID-19场景
每个场景中执行5-100次实验
每次实验大约花费30分钟
总共8347个计算机小时
Python :3.6.9
Keras :2.3.1
TensorFlow:2.2.0-rc2
scikit-learn library:0.23.1
R:3.5.2
3. 实验过程&结果
实验评估指标:accuracy, sensitivity, specificity and F1 scores
-
Swarm Learning predicts leukaemias
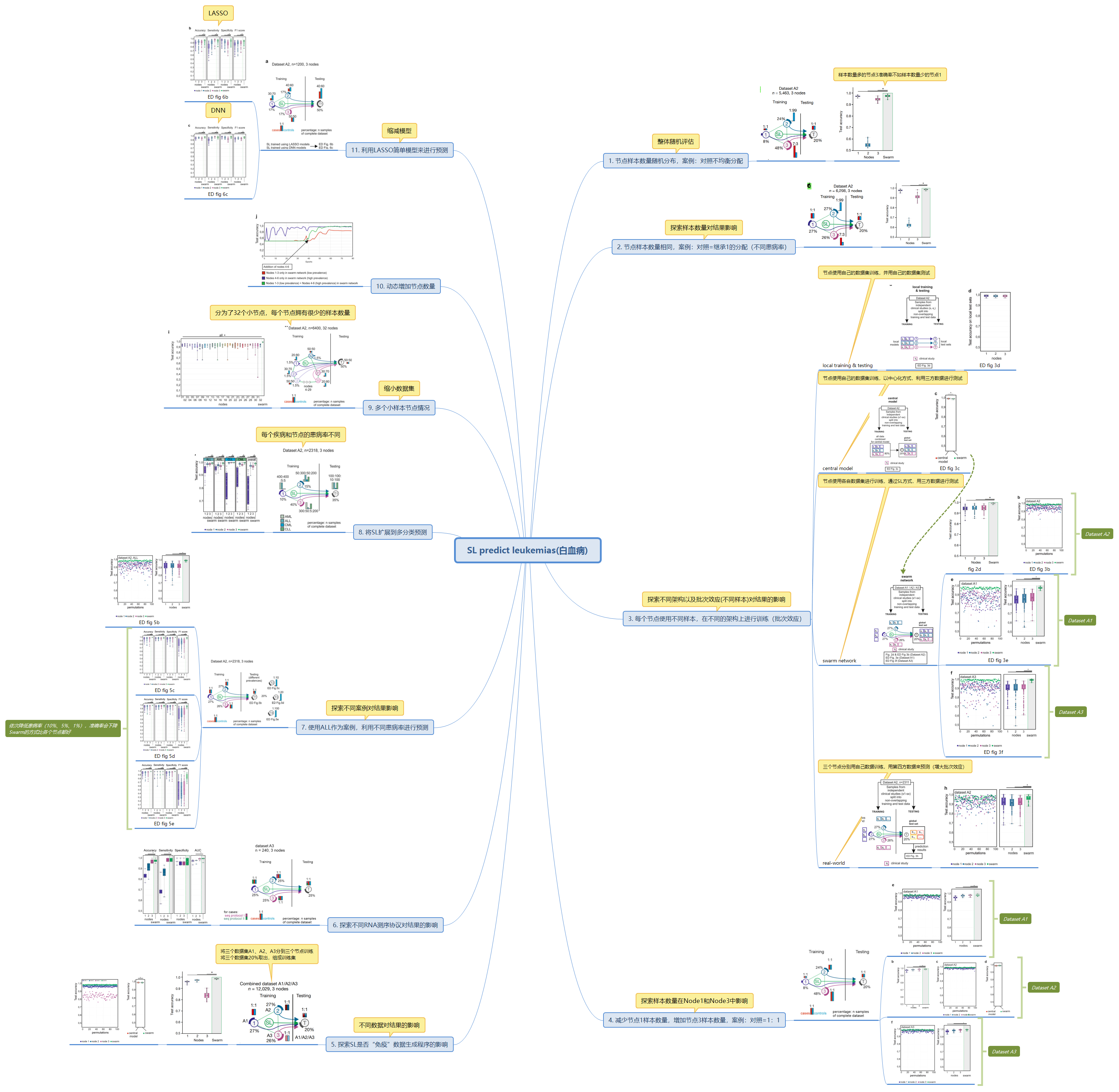
-
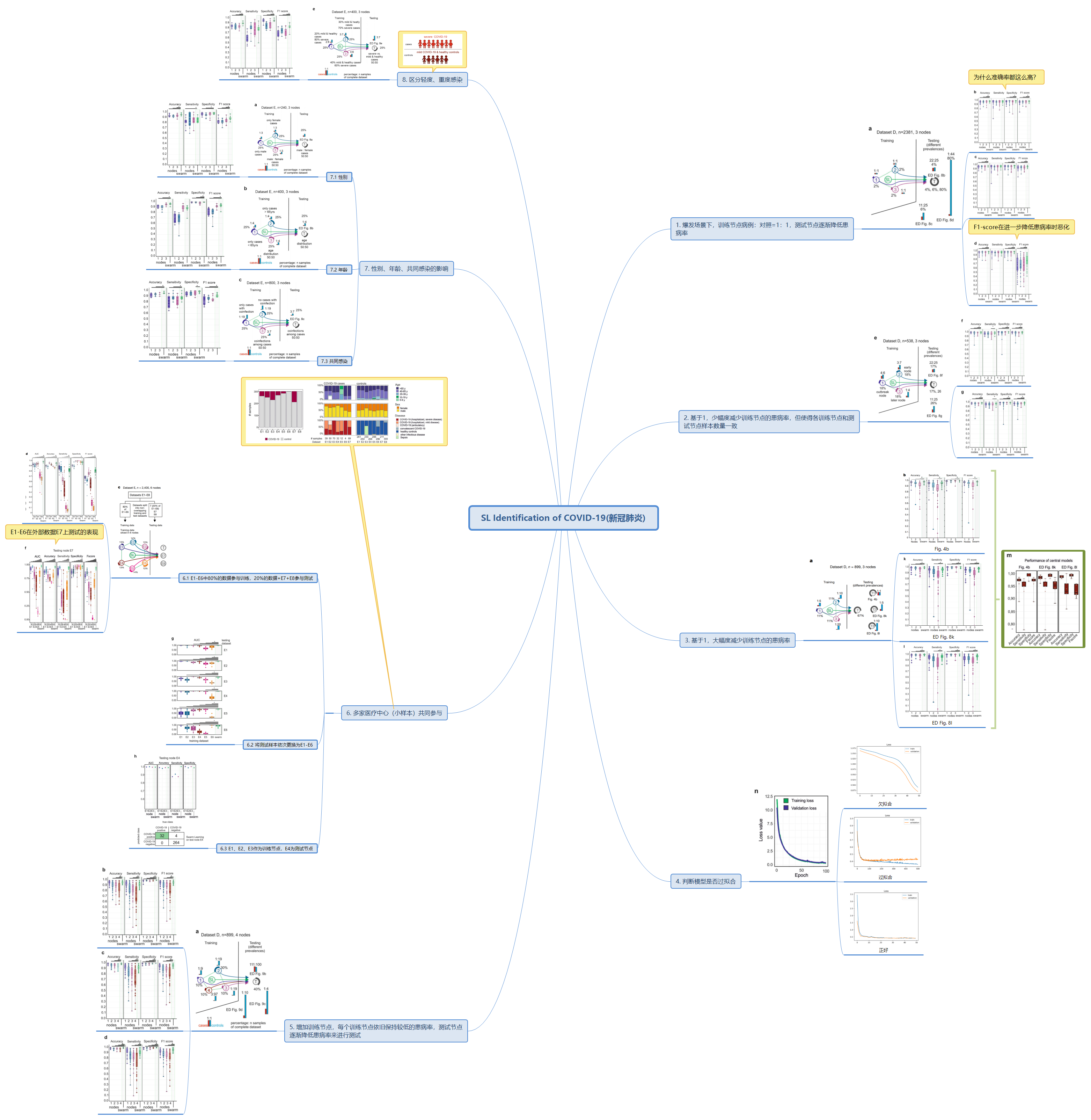
Swarm Learning to identify tuberculosis

-
Identification of COVID-19
4. 实验源码
-
Neural network algorithm(Keras):
Keras is a deep learning API written in Python, running on top of the machine learning platform TensorFlow. It was developed with a focus on enabling fast experimentation. Being able to go from idea to result as fast as possible is key to doing good research.
''' Defining some parameters ''' r = X_train.shape[0] # number of rows c = X_train.shape[1] # number of columns epochs = 100 batch_size = 512 num_nodes = 1024 dropout_rate = 0.3 l1_v = 0.0 l2_v = 0.005 ''' NN (fit2 in Paper) ''' model = Sequential() # 顺序神经网络模型,Dense:全连接层 # activation:激活函数 # kernel_regularizer:施加在权重w上的正则项 # input_dim:张量的维度 #input layer model.add(Dense(256, activation='relu', kernel_regularizer = l1_l2(l1=0.0, l2=0.0), input_dim=c)) model.add(Dropout(0.4)) # first layer model.add(Dense(num_nodes, activation='relu', kernel_regularizer = l1_l2(l1=l1_v, l2=l2_v), input_dim=c)) model.add(Dropout(dropout_rate)) # second layer model.add(Dense(int(num_nodes / 2), activation='relu', kernel_regularizer = l1_l2(l1=l1_v, l2=l2_v), input_dim=c)) model.add(Dropout(dropout_rate)) # third layer model.add(Dense(int(num_nodes / 2), activation='relu', kernel_regularizer = l1_l2(l1=l1_v, l2=l2_v), input_dim=c)) model.add(Dropout(dropout_rate)) # fourth layer model.add(Dense(int(num_nodes / 4), activation='relu', kernel_regularizer = l1_l2(l1=l1_v, l2=l2_v), input_dim=c)) model.add(Dropout(dropout_rate)) # fifth layer model.add(Dense(int(num_nodes / 4), activation='relu', kernel_regularizer = l1_l2(l1=l1_v, l2=l2_v), input_dim=c)) model.add(Dropout(dropout_rate)) # sixth layer model.add(Dense(int(num_nodes / 8), activation='relu', kernel_regularizer = l1_l2(l1=l1_v, l2=l2_v), input_dim=c)) model.add(Dropout(dropout_rate)) # seventh layer model.add(Dense(int(num_nodes / 8), activation='relu', kernel_regularizer = l1_l2(l1=l1_v, l2=l2_v), input_dim=c)) model.add(Dropout(dropout_rate)) # eighth layer model.add(Dense(int(num_nodes / 16), activation='relu', kernel_regularizer = l1_l2(l1=l1_v, l2=l2_v), input_dim=c)) model.add(Dropout(dropout_rate)) # output layer model.add(Dense(units = 1, activation = "tanh")) # optimizer, loss model.compile(optimizer='adam',loss='binary_crossentropy', metrics=['accuracy']) model.summary() ''' callback Creating a callback that implements early stopping if the loss function decreases and saves the best model based on the loss function in the h5 format in the mounted drive. Alternatively best model can also be saved locally by specifying local file path ''' # EarlyStopping:用于提前停止训练 # patience:能够容忍多少个epoch内都没有improvement callbacks = [EarlyStopping(monitor='loss', patience=25), ModelCheckpoint(filepath='/content/drive/My Drive/TranscriptomicData/best_model_fit2.h5', monitor='loss', save_best_only=True)] ''' Training the model ''' model.fit(X_train, y_train, epochs=epochs, batch_size=batch_size, callbacks=callbacks) ''' Evaluating the score the of the model against unseen data ''' score = model.evaluate(X_test, y_test, verbose = 0) print('Test loss:', score[0]) print('Test accuracy:', score[1])Adam优化器:(一种梯度下降的优化方式)
Adam吸收了Adagrad(自适应学习率的梯度下降算法)和动量梯度下降算法的优点,既能适应稀疏梯度(即自然语言和计算机视觉问题),又能缓解梯度震荡的问题
对梯度的一阶矩估计(First Moment Estimation,即梯度的均值)和二阶矩估计(Second Moment Estimation,即梯度的未中心化的方差)进行综合考虑,计算出更新步长。
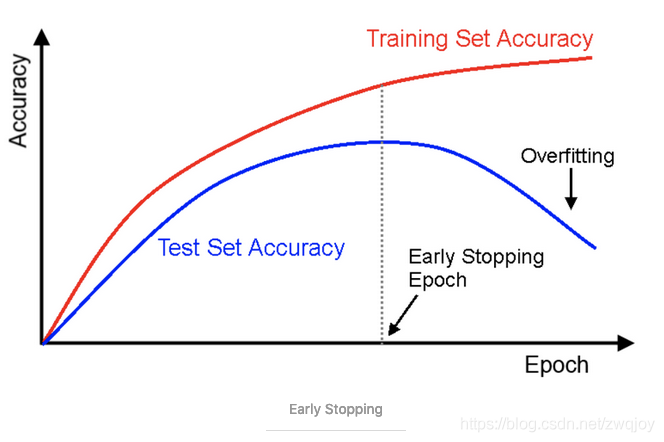
Early Stopping:达到一定精度阈值后,精度不再提高,仅会增加训练时间,甚至可能过拟合,不如早点停止
-
Least absolute shrinkage and selection operator (LASSO)
LASSO:
\[Q(β)=||y−Xβ||^2+λ||β||_1⟺ argmin||y−Xβ||^2 \quad s.t. ∑|β_j|≤s \]LASSO的复杂程度由λ来控制,λ越大对变量较多的线性模型的惩罚力度就越大,从而最终获得一个变量较少的模型,从而避免过度拟合
LASSO可以有效的避免过拟合,是一种有偏估计,对变量进行选择
# Create model model = create_model(rows, columns, float(lasso_lamda)) # Create callbacks # Early stopping callback if the loss function decreases esCallback = EarlyStopping(monitor='loss', min_delta=0.01, patience=20, verbose=2, mode='min') callbacks = [esCallback] # Starting training the model model.fit(X_train, y_train, epochs=epochs,batch_size=batch_size, callbacks=callbacks) # Create model # Simple Lasso LR model def create_model(r, c, lam=0.01): # Note : r (rows) is not used # model is linear # ypred = W1*i1 + W2*i2 + ... Wn*in + b # A single unit dense layer, with linear activation will do. # for LASSO LR, idea is to compute cost as # C = Reduced_Sum_of_Squares(W) + Lamda * L1(W) # however keras does not have RSS function instead it has # mean_Squared_error which is 1/N * RSS(W) , N: is batch size # this is a fairly good approximation of a Textbook LASSO LR # C = mean_Squared_error(W) + Lamda * L1(W) model = Sequential() model.add(Dense(1, activation='linear', kernel_regularizer=l1(lam), input_dim=c)) model.add(BatchNormalization()) opt = keras.optimizers.SGD(learning_rate=0.01) model.compile(optimizer=opt, loss='mean_squared_error', metrics=['accuracy']) model.summary() return model -
SwarmCallback:
''' sync_interval:同步时间间隔 min_peers:最小参与节点数(达到此阈值,就可以开始合并参数) val_data:验证集 val_batch_size:验证集批次大小 node_weightage:该节点模型权重的相对权重(合并参数采用加权平均) ''' swCallback = SwarmCallback(sync_interval = <number of training batches between syncs>, min_peers = <minimum peers>, val_data = <validation dataset>, val_batch_size = <validation batch size>, node_weightage = <relative weightage of node’s model weights>)
综述
1. 优点(创新点)
-
During iterations of SL, one of the nodes is chosen to lead the iteration, which does not require a central parameter server anymore thereby restricting centralization of learned knowledge and at the same time increasing resiliency and fault tolerance.(最重要的改进)
(去中心化,选择其中一个节点做参数合并,不需要中心服务器,可以限制学习知识中心化,同时提高弹性和容错率)
-
private permissioned blockchain technology, harboring all rules of interaction between the nodes, is Swarm Learning’s inherent confidentiality-enabling strategy
(隐私加密,区块链--包含所有节点间的交互规则,是SL固有的保密支持策略)
2. 缺点(局限性)
- 一个Swarm中的所有节点都使用相同的模型(模型不能个性化)
- 每个节点都需要使用相同的ML平台
- SL只适用于可以参数化的模型
- 通信代价大(O(KMN))
3. 哪里存在问题?
-
对于新冠肺炎,现有的PCR技术,可以通过咽拭子、鼻拭子进行检测,利用CT可以区分轻重病,为什么还要利用血液转录组来检测???而且,血液转录组为什么会有更好的效果???
-
对比性实验仅仅对比了本地学习和中心化学习,缺乏与联邦学习的对比性实验
-
差分隐私算法的应用未在本研究中得到正式测试
-
本文中未对区块链做过多解释,区块链怎么用的,还存在问题
4. 哪里可以改进?
- 未来的研究将探讨 结合更好的模型和对扩大数据集的访问是否可以进一步改善SL???
这里其实应该再加一个,到底是扩大数据集对SL性能提升更高,还是改善AI模型对SL性能提升更高? - SL对于网络上的节点的操作和状态转换同步进行,是否可以异步??动态对节点进行控制,异步调整,省去同步所耽搁的时间间隙
(以上为本人的一点愚见,如有错误,还请谅解,我尽快更正)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号