机器学习-学习笔记(二) --> 模型评估与选择
----- ## 一、经验误差与过拟合 * **错误率**(error rate):$E={a \over m}$(m个样本中有a个样本分类错误)。 * **精度**(accuracy):$(1-{a \over m})×100\%$。(说白了就是正确率) * **误差**(error):(误差期望)学习器实际预测输出与样本的真实输出之间的差异。  * **过拟合**(overfitting):将训练样本不太一般的特性作为了潜在样本具有的一般性质,导致泛化性能下降。 * **欠拟合**(underfitting):对训练样本的一般性质尚未学好。 $$ 成因\left\{ \begin{matrix} 过拟合:学习能力过于强大(关键障碍 且 无法避免)\\ 欠拟合:学习能力低下(容易克服) \end{matrix} \right. $$ (学习能力是否强大,由 学习算法和数据内涵共同决定) * **证明过拟合不可避免**: (1) **P(polynominal)类问题**:能在多项式时间内解决的问题。(可以称之为,很短时间内可以将问题答案算出来的问题) (2) **NP(Non-deterministic Polynomially)类问题**:能在多项式时间验证答案正确与否的问题。(可以称之为,很短时间内验证答案是不是正确答案的问题)
- 多项式时间:问题的时间复杂度在多项式(\(ax^n+bx^{n-1}+...+cx+d\))可以表示的范围内。
- P类问题一定是NP类问题的子集。能多项式时间内解决的问题,必然能在多项式时间内验证其解。
(3) NPC(Non-determinism Polynomial Complete)类问题:存在一个NP问题,所有的NP问题都可以约化为它。即只要解决了这个NP问题,其他NP问题都可以解决。(问题A约化为问题B:用问题B的解法可以解决问题A)
(4) NP难(Non-determinism Polynomial Hard)问题:所有NP问题都可以约化为这个问题,但这个问题不一定是NP问题。
- NP难问题,其实就是比所有NP问题都难的问题。因为每一次问题的约化,都会使得问题的复杂度提高。即将所有NP问题都约化为NP难问题时,只要解决最难的NP难问题,那么其他NP问题都可以解决了。
- NPC问题其实就是限定NP难问题只能为NP问题的问题。NP难问题不一定是NP问题,但是NPC问题一定是NP问题。同时,解决了NPC问题,也就解决了所有约化为其的NP问题。
(5) “P=NP?”。只要任意一个NPC问题找到了一个多项式算法,那么所有的NP问题都可以在多项式时间内解决,则NP=P。然而,给一个NPC问题找一个多项式算法这个事情本身就难以置信,一般的NPC问题的时间复杂度都在指数级或者阶乘级,想要找到多项式级,绝对是质的飞跃。所以,人们普遍认为“NP≠P”
(6) 若过拟合可以避免,则一定可以通过经验误差最小化这种P类问题,实现验证是否过拟合这种NP类问题,而获得最优解,即典型的“NP=P”。所以,只要确定“NP≠P”,则过拟合就不可避免。
- 模型选择问题(model selection):
(1) 选择学习算法
(2) 选择参数配置
二、评估方法
对模型的评估,一般采用 “测试集”(testing set)测试学习器的 “测试误差”(testing error),用测试误差来近似泛化误差,进而来评估模型对新样本的泛化能力。
而对于固定数据集,如何从数据集中产生训练集\(S\)和测试集\(T\),就至关重要。书中介绍了3种方法,分别是:留出法、交叉验证法、自助法。
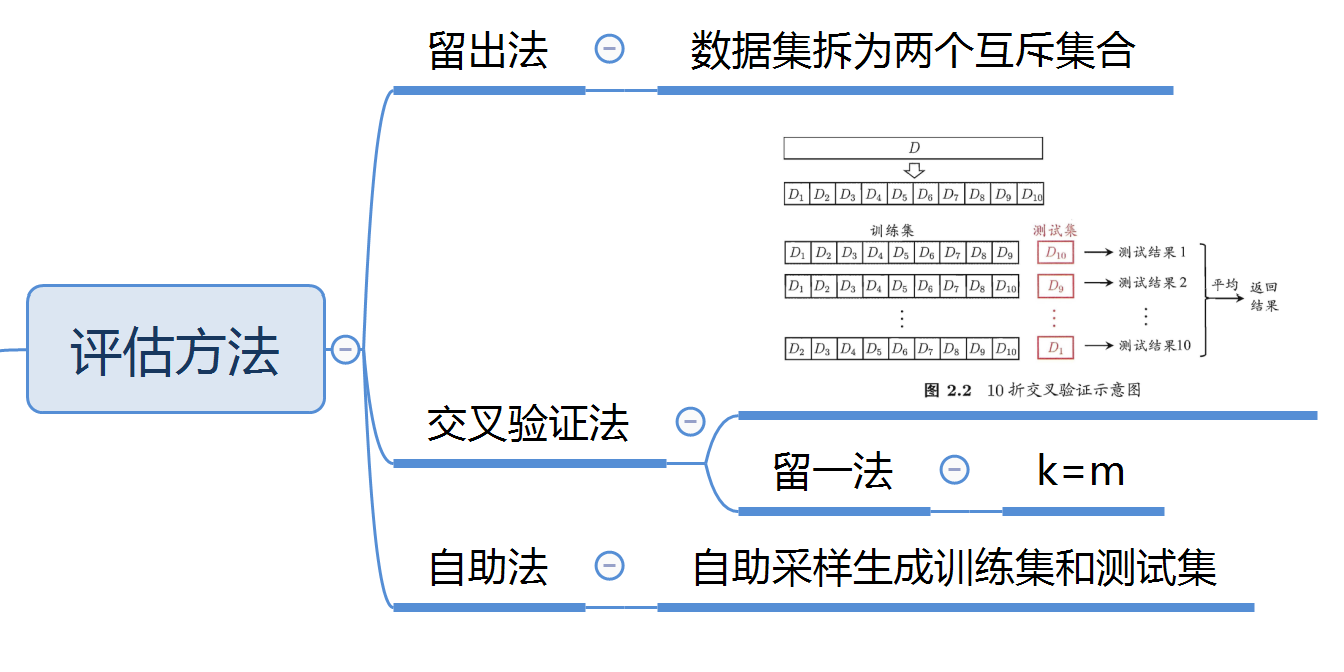
模型评估方法
1. 留出法(hold-out)
(1)直接将数据集D划分为两个互斥集合,一个集合作为训练集S,另一个为测试集T。
即
\(S ∩ T = \varnothing\)
(2)训练/测试集的划分要尽可能保持数据分布的一致性,避免因数据划分过程引入额外的偏差而对最终结果产生影响。(正反例在S和T中所占的比例基本一致)从采样(sampling)角度来看,保留类别比例的采样方式称为“分层采样”(stratified sampling)。
(3)在给定训练/测试集样本比例后,仍然存在多种划分方式对初始数据集D进行分割。(排列组合问题:从所有n个正例中,任取所占比例数m,即\(C_n^m\),从所有x个反例中,任取所占比例数y,即\(C_x^y\),最终共有\(C_n^m × C_x^y\)个划分方式)
在使用留出法时,单次结果不够稳定可靠,所以采用若干次随机划分、重复进行实验评估后取平均值作为评估结果。
(4)缺点:对固定数据集D划分,S和T的比例对评估结果的影响较大。
- S过多T过少,模型≈直接用D训练得出的模型,评估结果不够稳定准确(评估结果方差较大)
- S过少T过多,模型与D训练得出的模型差别较大(评估结果偏差较大),降低了评估结果的保真性(fidelity)
2. 交叉验证法(cross validation)
(1)将数据集D划分为k个互斥子集,即
\(D_i∩D_j=\varnothing(i≠j)\)
每个子\(D_i\)都保持数据分布一致性。
(2)每次利用\(k-1\)个子集的并集作为训练集,剩下一个作为测试集,共有\(k\)种训练/测试数据集,可进行\(k\)次训练和测试,最终将\(k\)个测试结果的均值作为结果。
(3)交叉验证法的评估结果的稳定性和保真性很大程度上取决于\(k\)的取值。(\(k\)常用取值为10)
(4)留一法(Leave-One-Out)--- 交叉验证法的特例
若数据集\(D\)含有\(m\)个样本,则令\(k=m\),只有唯一的划分方式(划分为\(m\)个子集,每个子集包含一个样本)。留一法将\(m-1\)个样本用于训练,与直接用\(D\)训练得出的模型基本一致,所以其评估结果较为准确。其缺点也很明显,训练\(m\)个模型计算开销不可估量。
3. 自助法(bootstrapping)
(1)每次随机从包含\(m\)个样本的数据集\(D\)中,抽取一个样本复制到数据集\(D'\),直到\(D'\)中包含\(m\)个样本。
(2)\(D\)中的某些样本会在\(D'\)中重复出现,而可能存在部分样本始终不出现,其概率为\((1-{1 \over m})^m\),当样本数量\(m\)取极限时,概率为\(\lim_{m \rightarrow+\infty}(1-{1 \over m})^m={1 \over e}≈0.368\),即\(D\)z中约有36.8%的样本不会出现在\(D'\)中。附极限的计算:
(3)\(D'\)作为训练集,而将\(D\)中和\(D'\)中不重复的部分(36.8%)作为测试集。这样的测试结果称为“包外估计”(out-of-bag estimate)。
(4)优点:在数据集较小、难以有效划分训练/测试集时很有用;训练样本规模同初始数据集\(D\)的训练样本规模一样;能从初始数据集中产生多个不同的训练集,对集成学习等方法有很大的好处。
(5)缺点:自助法产生的数据集改变了初始数据集的分布,会引入估计偏差。在初始数据量足够时,留出法和交叉验证法更常用。
调参(parameter tuning)和最终模型
调参和算法选择对模型的性能都有显著的影响,其本质皆为:不同参数/学习算法训练出模型,将最好的模型作为结果。
调参,若对每种参数进行训练,对每种训练的模型进行评估,那计算开销会特别大,甚至不可行。所以,调参要在选适当的范围和适当的步长,对个别参数进行训练评估,虽然不一定是最佳值,但是是计算的开销和性能评估的折中结果,也具有一定的代表性。
模型在评估过程中,一般都只用数据集中的部分数据来训练模型,在模型选择完成后,还应将整个数据集重新训练模型,这才是最终模型。
数据集(data set)

三、性能度量(performance measure)
性能度量主要用于衡量模型泛化能力,其反映了任务需求。
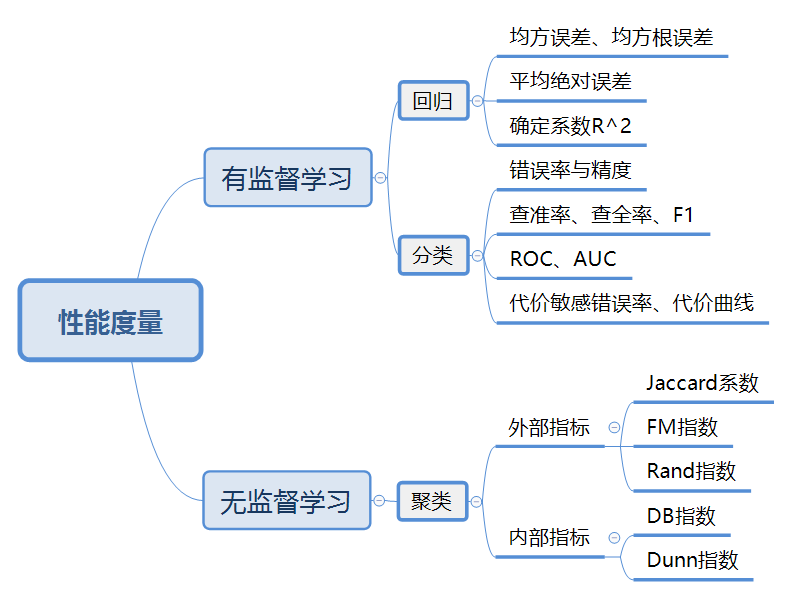
给定样例集\(D=\{(x_1,y_1),(x_2,y_2)...(x_m,y_m)\}\),其中\(y_i\)是\(x_i\)的真实标记,要评估学习器\(f\)的性能,要把学习器预测结果\(f(x)\)与真实标记\(y\)进行比较。
1. 回归任务的性能度量
1.1 均方误差、均方根误差
均方误差(Mean Squared Error):预测值与真实值差值的平方和的平均值。
均方根误差(Root Mean Squared Error):均方误差开根号。
取值范围均为0~1,值越接近于0,表明拟合度越好,泛化性能越好。
1.2 平方绝对误差
平方绝对误差(Mean Absolute Error):预测值与真实值差值的绝对值的平均值。
同样的,取值范围均为0~1,值越接近于0,表明拟合度越好,泛化性能越好。
1.3 确定系数\(R^2\)
残差平方和:预测值与真实值差值的平方和。
总离差平方和:真实值与真实值的平均值的差值的平方和。
确定系数\(R^2\)(R-Squared):由残差平方和(Sum of Squares due to Error)以及总离差平方和(Total Sum Of Squares)共同决定。
由公式可知,\(R^2\)的取值范围为0~1,值越接近1,表明拟合度越高,泛化性能越好。
2. 分类任务的性能度量
2.1 错误率、精度
错误率:分类错误的样本数占样本总数的比例。
(对于样例集\(D\))$$E(f;D)={1 \over m}\sum_{i=1}^mⅡ(f(x_i)≠y_i)$$
(对于数据分布\(D\)和概率密度函数\(p(x)\))$$E(f;D)=\int_{x \sim D}Ⅱ(f(x)≠y)p(x)dx$$
精度:分类正确的样本数占样本总数的比例。
(对于样例集\(D\))$$acc(f;D)={1 \over m}\sum_{i=1}^mⅡ(f(x_i)=y_i)=1-E(f;D)$$
(对于数据分布\(D\)和概率密度函数\(p(x)\))$$acc(f;D)=\int_{x \sim D}Ⅱ(f(x)=y)p(x)dx=1-E(f;D)$$
其中\(Ⅱ(f(x_i)≠y_i)\)为指示函数,\(f(x_i)≠y_i\)其值为1,否则为0。
2.2 查准率、查全率、F1
查准率(precision):检索出的信息中有多少比例是用户感兴趣的。(准不准)
查全率(recall):检索出多少用户感兴趣的信息。(全不全)
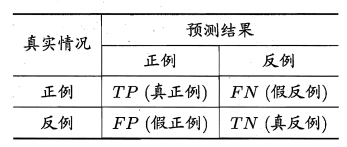
对于二分类问题,可将样例根据其真实类别与学习器预测类别的组合划分为真正例(TP,true positive) 、假正例 (FP,false positive) 、真反倒(TN,true negative)假反例 (FN,false negative) 四种。
查准率和查全率往往矛盾。查准率高,查全率往往偏低;查全率高,查准率往往偏低。(其实蛮好理解的,想要查的准,条件往往比较苛刻,难免会漏掉一些好的;若想要查的全,条件就相对宽松,也会混入一些差的,所以想要鱼和熊掌兼得,只可能在一些样例特征少的任务中实现。)
如何通过查准率和查全率判断模型性能?
(1)根据学习器预测结果对样例进行排序(最有可能的在最前)
(2)逐个将样本作为正例预测
(3)每次计算当前的查准率、查全率
(4)生成P-R曲线,通过曲线与x、y轴所围的面积来判断学习器性能
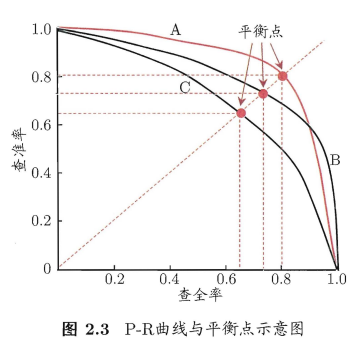
在P-R图中,曲线与x、y轴所围的面积越大,则表示学习器性能更好。但是,如果P-R曲线是平滑曲线,完全可以通过分段函数积分计算其面积来进行比较,但P-R曲线往往是非单调且不平滑的,计算其面积相对复杂,所以想要评判其性能,光靠面积(在这个问题上不太可能被量化)是完全不够的。“平衡点”就是用来解决这个问题的。
“平衡点”(BEP,Break-Event Point):“查准率=查全率”时的取值。基于BEP进行比较,BEP越大,其性能也就越好。但BEP还是过于简单。
F1度量:F1是基于查准率和查全率的调和平均定义的。
\(F_β\)度量:\(F_β\)相较于F1更能表达出对查准率/查全率的不同偏好。\(F_β\)是加权调和平均。
其中,
n个二分类混淆矩阵上综合考察查准率和查全率:
(1)生成n个二分类混淆矩阵
- 多次训练/测试,每次得到一个混淆矩阵
- 多个数据集上训练/测试
- 执行多分类任务,两两类别的组合对应一个混淆矩阵
(2)计算各混淆矩阵的查准率和查全率,记为(\(P_1\),\(R_1\))...(\(P_n\),\(R_n\))
(3)计算平均值
- 宏查准率(macro-P):\(macro-P={1\over n}\sum_{i=1}^nP_i\)
- 宏查全率(macro-R):\(macro-R={1\over n}\sum_{i=1}^nR_i\)
- 宏F1(macro-F1):\(macro-F1={{2\times macro-P \times macro-R}\over{macro-P + macro-R}}\)
(4)还可先平均,再计算
- 微查准率(micro-P):\(micro-P={{\overline{TP}}\over{\overline{TP}+\overline{FP}}}\)
- 微查全率(micro-R):\(micro-R={{\overline{TP}}\over{\overline{TP}+\overline{FN}}}\)
- 微F1(micro-F1):\(micro-F1={{2\times micro-P \times micro-R}\over{micro-P + micro-R}}\)
2.3 ROC、AUC
分类阈值(threshold):学习器为测试样本产生一个实值或概率预测,然后将这个预测值与一个“分类阈值”进行比较,大于阈值的、小于阈值的分别划分为一类。(这个实值或概率预测结果的好坏,直接决定了学习器的泛化能力)
截断点(cut point):根据实值或概率预测结果将测试样本排序,分类过程相当于在这个排序中以某个“截断点”将样本分为两部分。(排序本身的质量好坏,体现了“一般情况下”泛化性能的好坏。)
不同的应用任务中,可以根据任务需求采用不同的截断点,来体现对查准率和查全率的重视程度。
ROC(“受试者工作特征”,Receiver Operating Characteristic):纵轴为“真正例率”(TPR,True Positive Rate),横轴为“假正例率”(FPR,False Positive Rate)。

如下图所示(图片来自网络,在此借用),对角线对应于“随机猜测”模型,C'很明显是分类性能最好的。
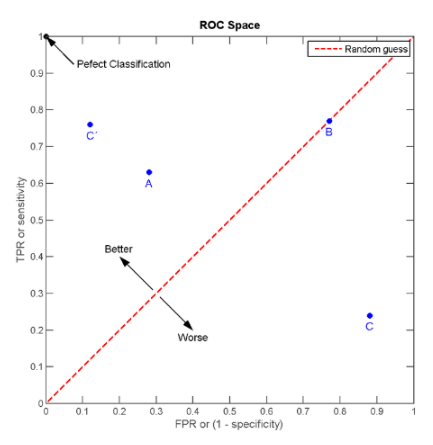
ROC曲线横纵坐标并不相关,所以ROC曲线并不应作为函数曲线来进行分析,而应该将其看作无数个点,每个点的横纵坐标表征其性能。
如何绘制ROC曲线?
(1)给定m个正例和n个反例
(2)根据学习器预测结果对样例进行排序
(3)将分类阈值从最大到最小,依次设为每个样例的预测值(依次将每个样例划分为正例)
(4)若前一个标记点坐标为\((x,y)\),若当前为真例,则坐标为\((x,y+{1\over m})\);若为反例,则坐标为\((x+{1\over n},y)\)。
(5)将相邻点用线段连接即得。
(*)我所理解的是,先将正例反例放在一起,按照预测结果进行排序,从\((0,0)\)点出发,依次按照序列向后读,如果是正例,则按\(y\)轴正方向向上移动\(1\over m\)个单位,若为反例,则按\(x\)轴正方向向左移动\(1\over n\)个单位,知道序列遍历结束。
举例:
正例预测结果集合为(0.8, 0.5, 0.4, 0.2, 0.05)
反例预测结果集合为(0.9, 0.7, 0.6, 0.2, 0.01)
将其排序得(0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.2, 0.05, 0.01)(其中红色标注的为正例,蓝色为正反例均有)
遍历序列。
第一个为0.9,为反例,反例共有5个,则向x轴正方向移动\(1\over 5\)个单位。

第二个为0.8,为正例,正例共5个,则向y轴正方向移动\(1\over 5\)个单位。
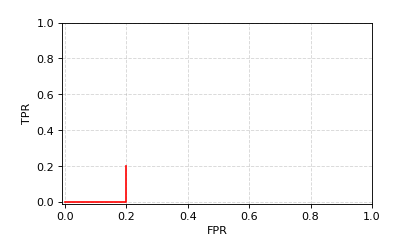
依次类推,将完整的画出。特别注意,当预测值为0.2时,正反例均有,则同时向x轴,y轴移动,则为斜线。

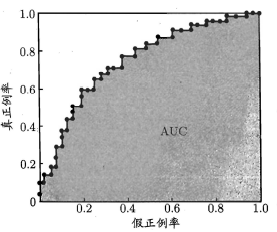
如何通过ROC比较学习器性能?
同P-R曲线一样,一定范围内,所包的面积越大,则其性能越好。
AUC(Area Under ROC Curve):ROC曲线下的面积。(其实就是各点之间形成的矩形面积求和)。AUC值越大的分类器,性能越好。
举例:
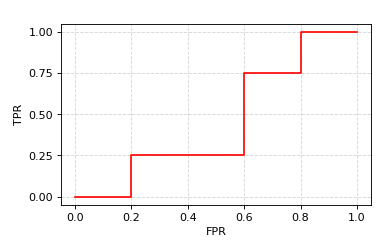
ROC曲线上各点坐标集为:\(\{(0,0), (0.2,0), (0.2,0.25), (0.4,0.25), (0.6,0.25), (0.6,0.5), (0.6,0.75), (0.8,0.75), (0.8,1), (1,1)\}\)
根据公式来计算:
根据ROC曲线所围面积计算:
每个小矩形面积为\(0.2\times 0.25=0.05\),
ROC所围面积总共占有9个矩形,故\(AUC=9\times 0.05=0.45\)
结果一致。
公式推导:
已知,\(AUC\)的值就是曲线与x轴所围成的面积。
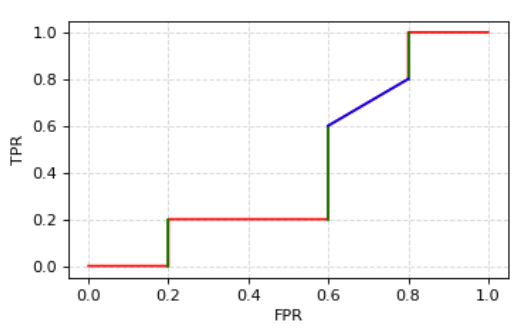
在上图中,曲线与x轴所围成的面就就是红线与蓝线与x轴所围成的面积。红线组成矩形,而蓝线组成梯形。矩形面积和梯形面积均可以用梯形面积公式,即
其实就是\(1\over 2\)高乘以上底加下底的和。其中,\((x_{i+1}-x_i)\)是高,\((y_i+y_{i+1})\)是上底加下底的和。
最终将所有面积求和即为\(AUC\)。
排序“损失”(loss):ROC曲线之上的面积。
其中,有\(m^+\)个正例,\(m^-\)个反例,\(D^+\)是正例的集合,\(D^-\)是反例的集合。该公式的含义是:若正例的预测值比反例小,则加1,若正例预测值和反例预测值相等则加\(1\over 2\)。
公式推导:
按照\(AUC\)的公式推导方法,\(l_{rank}\)同样是计算梯形面积,只不过为曲线上半部分面积。对应于图,则为计算绿线和蓝线与\(y\)轴所围成的面积。
因为每增加一个真正例,沿\(y\)轴增加\(1\over {m^+}\),故可设梯形高为\(1\over {m^+}\)。
计算梯形面积还需要“上底(较短的底)+下底(较长的底)”,而上底和下底均是绿色、蓝色线段两端点到\(y\)轴的距离。因为每增加一个假正例,沿\(x\)轴增加\(1\over {m^-}\),故其“上底”为\(1\over {m^-}\)乘以预测值大于\(f(x^+)\)的假正例的个数,即
其“下底”为\(1\over {m^-}\)乘以预测值大于等于\(f(x^+)\)的假正例的个数,即
则单个梯形面积为:
将所有梯形面积求和,则可得到\(l_{rank}\),即证。
这个不难理解,就是总面积1减去曲线上半部分面积,等于曲线下半部分面积。
2.4 代价敏感错误率、代价曲线
非均等代价(unequal cost):为权衡不同类型错误所造成的不同损失,将错误赋予“非均等代价”。(不同的错误所造成的后果不同)
代价矩阵(cost matrix):
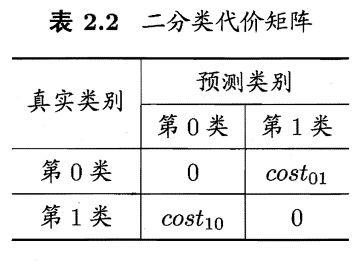
其中,\(cost_{ij}\)表示第\(i\)类样本预测为第\(j\)类样本的代价;\(cost_{ii}=0\)(因为结果正确,未造成错误而产生代价);损失程度相差越大,\(cost_{01}>cost_{10}\)的值的差别越大(更关注于代价间的比值,而非差值)。
若单纯将错误的代价作为均等代价(所有错误所造成的后果一致),则错误率可以直接以错误次数来进行衡量。但往往,错误有轻重,在非均等代价的前提下,仅仅最小化错误次数是远远不够的,只有最小化总体代价(total cost),才能使得错误造成的后果最小化。(我认为,这是一种对错误的赋权方式,也是对不同错误的偏好设置)
“代价敏感”错误率(cost-sensitive):
同之前均等代价错误率(\(E(f;D)={1\over m}\sum_{x_i∈D}Ⅱ(f(x_i)≠y_i)\))相比,将数据集中正反例错误进行赋权,计算得出其“代价敏感”错误率。
代价曲线(cost curve):\(ROC\)曲线在非均等代价下,不能直接反映出学习器的期望总体代价,而代价曲线可以实现。
- 横轴:正例概率代价,取值为\([0,1]\),$$P(+)cost={{p\times cost_{01}\over{p\times cost_{01}+(1-p)\times cost_{10}}}}$$(p为样例为正例的概率)
- 纵轴:归一化代价,取值为\([0,1]\),$$cost_{normal}={{FNR\times p\times cost_{01}+FPR\times(1-p)\times cost_{10}}\over{p\times cost_{01}+(1-p)\times cost_{10}}}$$(\(FNR={{FN}\over{TP+FN}}\),\(FPR={{FP}\over{TN+FP}}\))
将横轴的\(P(+)cost\)带入纵轴\(cost_{normal}\),得到$$cost_{normal}=FNR\times P(+)+FPR\times(1-P(+))$$
可以看作斜率为\(FNR-FPR\),截距为\(FPR\),范围均在\([0,1]\)上的一条线段。
其实从其定义易知代价曲线的画法。
连接\((0,FPR)\)与\((1,FNR)\)即可。
如何绘制代价曲线?
(1)\(ROC\)曲线上每一点对应了代价平面上的一条线段
(1.1)设\(ROC\)曲线上点的坐标为\((FPR,TPR)\)
(1.2)\(FNR=1-TPR\)
(1.3)绘制从\((0,FPR)\)到\((1,FNR)\)的线段,线段下的面积表示该条件下的期望的总体代价
(1.4)如此将\(ROC\)每个点都转化为代价平面上的一条线段
(1.5)取所有线段的下界,其所围成的面积就是所有条件下学习器的期望总体代价

3. 聚类任务的性能度量(第9章)
聚类的性能度量又称为聚类“有效性指标”(validity index)。
聚类结果好的标准:
- “簇内相似度”(intra-cluster similarity)高
- “簇间相似度”(inter-cluster similarity)低
3.1 外部指标(external index)
外部指标:将聚类结果与某个“参考模型”(reference model)进行比较。
对于数据集\(D=\{x_1,...,x_m\}\),聚类划分簇为\(C=\{C_1,...,C_k\}\),参考模型划分的簇为\(C^*=\{C_1^*,...,C_s^*\}\),\(\lambda,\lambda^*\)分别表示\(C,C^*\)对应的簇标记向量。
其中,集合\(SS\)表示样本对既在\(C\)中属于相同簇,又在\(C^*\)中属于相同簇;
集合\(SD\)表示样本对在\(C\)中属于相同簇,而在\(C^*\)中属于不同簇;
集合\(DS\)表示样本对在\(C\)中属于不同簇,在\(C^*\)中属于相同簇;
集合\(DD\)表示样本对既在\(C\)中属于不同簇,又在\(C^*\)中属于不同簇。
(很好理解,就是\(S\)表示样本对在一个簇中,\(D\)表示样本对不在同一个簇中,\(a、b、c、d\)则分别表示四个集合中样本对的个数。很明显,\(a\)和\(d\)所表示聚类结果和参考模型结果一致,而\(b\)和\(c\)则表示聚类结果和参考模型不一致,所以\(a\)和\(d\)越大的聚类算法,其性能也就越好。)
因为每个样本对\((x_i,x_j)(i<j)\)仅能出现于\(SS、SD、DS、DD\)其中之一,因此,\(a+b+c+d={{m(m-1)}\over2}\)。
(这里的原因是,因为\(SS、SD、DS、DD\)四个集合互斥,所以\(a+b+c+d\)则为样本对的总数,而样本对的总数就是数据集\(D=\{x_1,...,x_m\}\)中,\(m\)个数两两无序组合的个数,即为\(C_m^2={{m(m-1)}\over2}\),这里无序的原因是因为已经规定了\(i<j\),所以不存在\((x_j,x_i)\)的样本对,即为无序。)
3.1.1 Jaccard系数(JC,Jaccard Coefficient)
定义:Jaccard系数用来描述两个集合的相似程度。
Jaccard延申定义:
其中,\(M_{11}\)表示元素同时出现在\(A、B\)两个集合的元素个数;
\(M_{10}\)表示元素出现在\(A\),但不出现在\(B\)的元素个数;
\(M_{01}\)表示元素出现在\(B\),但不出现在\(A\)的元素个数;
\(M_{00}\)表示元素既不出现在\(A\)又不出现在\(B\)的元素个数。
显然,\(|A∩B|=M_{11} \quad |A-A∩B|=M_{10} \quad |B-A∩B|=M_{01}\)
所以,\(JC={{|A∩B|}\over{|A∪B|}}={{|SS|}\over{|SS∪SD∪DS|}}={{a}\over{a+b+c}}\)
3.1.2 FM指数(FMI,Fowlkes and Mallows Index)
其中,\(a+b\)表示样本对在聚类结果中属于同一类的数量,\(a+c\)表示样本对在参考模型中属于同一类的数量。
\({a}\over{a+b}\)与\({a}\over{a+c}\)代表样本对在聚类结果和参考模型中属于同一类的概率。这两个概率值往往不相等,故为不对称指标,通过对两个不对称指标求几何平均数转化为对称指标。
3.1.3 Rand指数(RI,Rand Index)
\(a、d\)表示聚类结果和参考模型一致,显然\(RI\)可以表示聚类结果与参考模型的一致性。
上述三个性能度量取值范围均在\([0,1]\),其值越大,说明聚类算法性能越好。
3.2 内部指标(internal index)
内部指标:直接考察聚类结果而不利用任何参考模型。
对于聚类结果的簇划分\(C=\{C_1,...,C_k\}\)
定义:
不难看出,\(\sum_{1≤i<j≤|C|}dist(x_i,x_j)\)表示样本对\((x_i,x_j)\)的距离之和,\({|C|(|C|-1)}\over{2}\)表示样本对总数,即\(avg(C)\)表示样本对间的平均距离。一个簇的平均距离可以很好反映这个簇的分散程度。
\(diam(C)\)则表示簇内样本间最远距离。
\(d_{min}(C_i,C_j)\)表示两簇\(C_i,C_j\)最近样本间的距离。
\(d_{cen}(C_i,C_j)\)表示两簇\(C_i,C_j\)中心点间的距离,\(\mu_i,\mu_j\)为两簇的中心点。两簇中心点的距离很好的表现了各个簇类之间的分离程度。
3.2.1 DB指数(DBI,Davies-Bouldin Index)
\(DBI\)主要表示簇之间的最大“相似度”的均值。很显然,\(DBI\)值越小,两簇相似度越低,则聚类效果越好。
3.2.2 Dunn指数(DI,Dunn Index)
\(DI\)值越大,簇与簇之间距离也就越远,“簇间相似度”就越低,聚类性能越好。
------ ## 四、比较检验 **性能比较涉及的因素**: * 泛化性能和测试集的性能未必相同 * 不同测试集其结果、性能不一定相同 * 学习算法具有随机性,每次结果不一定相同 ### 1. 假设检验 > 先对假设检验的概念进行理解:(具体参考浙江大学《概率论与数理统计(第四版)》第八章假设检验) > 我所理解的假设检验就是利用“小概率事件基本不会发生”的原理,对事件正反两个假设其中之一进行检验,若检验的假设成立的概率小于$α$(检验的显著性水平),假设不成立,则另一个假设一定成立。 > > 检验步骤: > 1. 提出假设$H_0,H_1$,设定检验水准$α$的值(通常取$0.1、0.05$)。 > 2. 选定统计检验方法(二项检验、t检验等),由样本观察值按公式计算出统计量的大小。 > 3. 确定检验假设成立的可能性$P$的大小,并与$α$比较判断结果。若$P>α$,则假设成立,否则不成立。 > > 假设检验最终结果是该假设是否成立
根据测试错误率\(\hat{\epsilon}\)估推出泛化错误率\(\epsilon\)的分布。
(泛化错误率\(\epsilon\):学习器在一个样本上犯错的概率;测试错误率\(\hat{\epsilon}\):\(m\)个测试样本有\(\hat{\epsilon}\times m\)个被错误分类)
泛化错误率\(\epsilon\)的学习器,将\(m\)个样本中的\(m'\)个样本分类错误,将\(m-m'\)个样本分类正确的概率为:
测试错误率\(\hat{\epsilon}\),将\(m\)个样本中\(\hat{\epsilon}\times m\)个错误分类,\(m-\hat{\epsilon}\times m\)正确分类的概率为:
很明显这是属于二项分布,对其求偏导易知在\(\epsilon=\hat\epsilon\),\(P(\hat\epsilon,\epsilon)\)取最大值。
二项分布的定义:
二项式定理:


“二项检验”(binomial test):已知一个分布服从二项分布,但未知这个分布的参数(这个参数在书中是 泛化错误率\(\epsilon\)),想要通过一批服从这个分布的一些样本(即 测试错误率\(\hat\epsilon\)),来对这个参数的取值范围的假设进行判断,若这个假设置信度超过了设定的置信度阈值,则假设成立。(这个解释些许有些牵强,仍需探讨并改进)
对西瓜书中“二项检验”的理解:
- 该“二项检验”要检验的假设:
要证明这个猜想是否成立,其实只需要知道泛化错误率\(\epsilon\)的值即可,但是泛化错误率往往不能预先得知,这也是此次“二项检验”的目的:在一定准确度上,对\(\epsilon\)的值进行猜测,其中\(\epsilon_0\)即是对\(\epsilon\)的猜测值。
预先可以得到的是测试错误率\(\hat\epsilon\),测试错误率可以在一定程度上反映出泛化错误率,书中给出两者的联合概率函数$$P({\hat{\epsilon}};{\epsilon})=(_{\hat{\epsilon}\times m}^m) {\epsilon}^{\hat{\epsilon}\times m}(1- \epsilon)^{m-\hat{\epsilon}\times m}$$
易知,\(\epsilon=\hat\epsilon\)的概率最大,这里解释基本合理,但是这里引用一下\(\hat\epsilon\)是\(\epsilon\)的无偏估计使其更为可靠。(无偏估计的意义是:在多次重复下,它们的平均数接近所估计的参数真值。)
- 若想使得\(\epsilon≤\epsilon_0\)假设成立,则要使得测试错误率\(\hat\epsilon<\)临界值\(\overline\epsilon\)(即泛化错误率\(\epsilon\)的最小值),使得\(\hat\epsilon<\overline\epsilon≤\epsilon≤\epsilon_0\)。
即\(\hat\epsilon<\overline\epsilon\)成立的概率\(≥1-α\)或\(\hat\epsilon≥\overline\epsilon\)成立的概率\(<α\)(反命题成立表示正命题不成立),则认为\(\epsilon≤\epsilon_0\)成立。
即,\(P\{\hat\epsilon≥\overline\epsilon |\epsilon≤\epsilon_0\}<α\)时,则假设\(\epsilon≤\epsilon_0\)成立。 - 在已知\(\hat\epsilon\)的前提下,只需要计算\(\overline\epsilon\)及\(α\)的值即可对假设做出检验。
如何计算假设的置信度\(1-α\)?
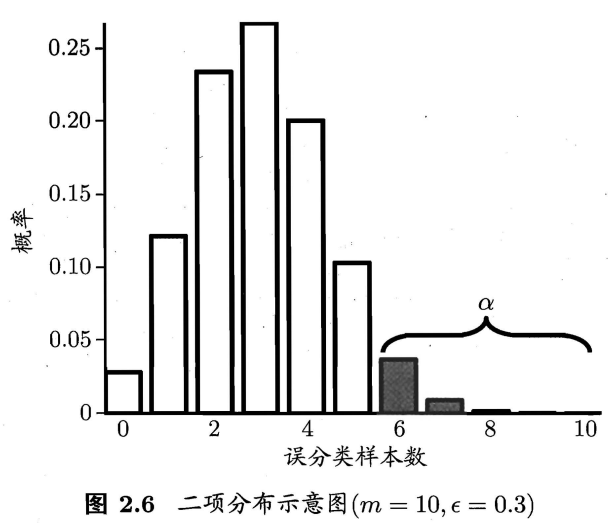
假设置信度就是假设在泛化错误率的取值范围的约束下,分布曲线下的面积和(对应于图2.6中的非阴影部分的面积和)。其中,\(α\)就是从\(\epsilon\times m+1\)个误分类样本数开始,一直到\(m\)个误分类样本数中,柱形面积之和(对应于图2.6中的阴影部分的面积和)。
而\(\overline\epsilon\)值便是满足阴影部分面积最大值小于\(α\)条件下,最小的\(\epsilon\)取值,即公式(这里公式已经更正为正确版本):
- 综上所述,若测试错误率\(\hat\epsilon\)小于临界值\(\overline\epsilon\),则表示\(\epsilon≤\epsilon_0\)假设成立。(希望各位对此公式的个人见解进行交流和指正)
t检验(t-test):
引用浙江大学概率论与数理统计(第四版)第八章第二节正态总体均值的假设检验中,关于t检验概念说明部分。

- 对于已知\(k\)个测试错误率\(\hat{\epsilon}_{1}, \hat{\epsilon}_{2}, \ldots, \hat{\epsilon}_{k}\)的学习器,猜测其泛化错误率\(\epsilon_0\),做出假设
- 计算平均错误率\(\mu\),方差\(\sigma^{2}\)
则检验统计量\(t\)为
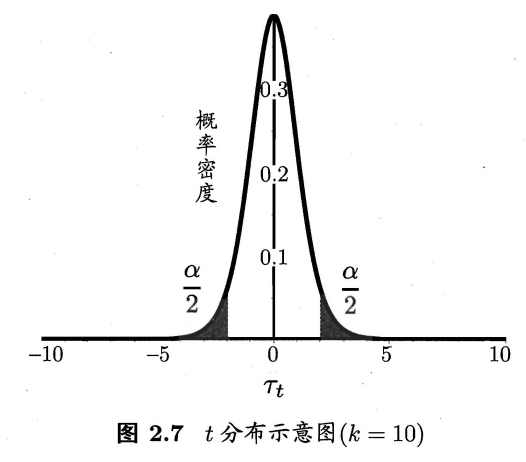
若\(t\)位于\([t_{{-α}\over{2}},t_{{α}\over{2}}]\)内,则假设\(H_0:\mu=\epsilon_0\)平均测试错误率等于泛化错误率成立。
2. 交叉验证\(t\)检验
其实就是对\(k\)折交叉验证法验证两个学习器\(A\)和\(B\),得到的测试错误率进行检验,猜测两个学习器泛化错误率是否相同。这里的比较检验方法是成对t检验(paired t-tests)。
基本思想就是两学习器性能相同,则两测试错误率也相同。
- 做出假设
- 计算两学习器测试错误率的差值,得到\(\Delta_1,\Delta_2,...,\Delta_k\)。
- 计算差值的均值\(\mu\)及方差\(\sigma^2\)。
- 计算t。
- 若\(t<t_{\frac{\alpha}{2},k-1}\),则表示假设\(H_0\)成立,两学习器性能相同,否则性能有差别,平均错误率较小的性能较优。
5×2交叉验证法:
目的是为了解决测试错误率不独立的问题,而提出的方法。测试错误率不独立的原因是:原数据固定,交叉验证时,不同轮的训练集可能会重叠。
该方法内容:
- 随机将原数据打乱,将原数据分为2个互斥子集\(D_1∩D_2=\empty\),\(D_1,D_2\)均作为测试集,进行测试,得到一对测试错误率\((\hat\epsilon_1^1,\hat\epsilon_1^2)\)。
- 将上述步骤重复5次,得到五对测试错误率\((\hat\epsilon_1^1,\hat\epsilon_1^2),...,(\hat\epsilon_5^1,\hat\epsilon_5^2)\)。对于两个学习器\(A,B\),分别得到其五对测试错误率\((\hat\epsilon_{A1}^1,\hat\epsilon_{A1}^2),...,(\hat\epsilon_{A5}^1,\hat\epsilon_{A5}^2)\),\((\hat\epsilon_{B1}^1,\hat\epsilon_{B1}^2),...,(\hat\epsilon_{B5}^1,\hat\epsilon_{B5}^2)\).
- 分别求1折和2折上的差值。
- 为了缓解测试错误率的非独立性,仅计算第一次交叉验证的均值\(\mu\),但方差依旧计算总体方差。
- 计算检验统计量\(t\),将\(t\)与临界值\(t_{\frac{\alpha}{2}}\)进行比较,确定假设是否成立。
因为这里共有5对测试错误率,故自由度为5(这里自由度是指取值不受限制的变量个数),查t检验临界值表可知,当\(\alpha=0.05\)时,\(t_{\frac{\alpha}{2}}=2.571\),当\(\alpha=0.1\)时,\(t_{\frac{\alpha}{2}}=2.015\)。
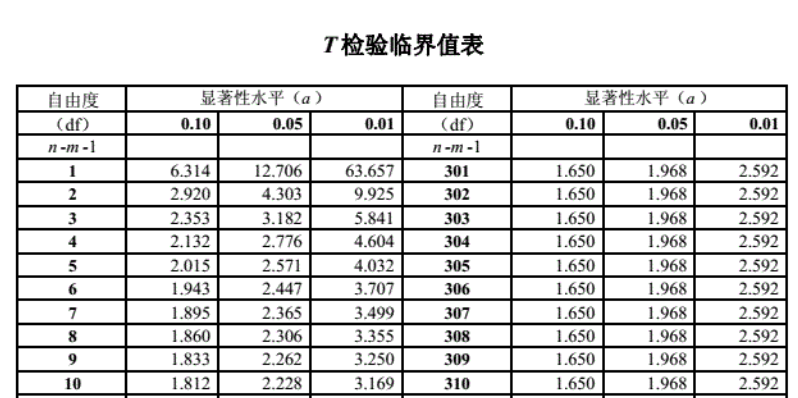
3. McNemar检验
McNemar检验,实现对于二分类多个学习器之间性能的检验。
列联表(contingency table):展示两个学习器分类结果的关系数量。(这里很容易联想到二分类代价矩阵)

若两学习器性能相同,则应有\(e_{01}=e_{10}\),则\(|e_{01}-e_{10}|\)服从正态分布。
(这里可以类比\(P-R\)曲线中的平衡点概念,平衡点在混淆矩阵中\(P=R\),也即\(\frac{TP}{TP+FP}=\frac{TP}{TP+FN}\),化简可知\(FP=FN\),即这里的列联表反对角线相等来评估两学习器性能相同。)
则定义检验统计量
通过连续性校正(因为这里是对二项分布进行正态分布的近似,故需要连续性校正),频率小的加0.5,频率大的减0.5,变形后即
服从自由度为1的\(\chi^2\)分布,当\(\tau_{\chi^{2}}<\chi_\alpha^2(临界值)\)时,则不能拒绝假设:“两学习器性能基本一致”,否则拒绝假设。
关于\(\chi^2\)检验(卡方检验)的检验过程,在习题2.9中已经给出。
4. Friedman检验与Nemenyi后续检验
一组数据集上多个算法比较的方法:
- 两两比较后排序,两两比较可使用t检验和McNemar检验
- 基于算法排序的Friedman检验
Friedman检验方法:
- 在每个数据集上对每个学习器/学习算法进行测试,得到其测试性能。
- 按照测试性能进行排序(升序1~n),若两学习器性能一样,则其排序序号为\(当前序值+\frac{1}{性能相同学习器的个数}\)(即平分序值),并计算每个算法的平均序值(若学习器性能相同,则其平均序值应该相同),得到算法比较序值表。

- 在N个数据集上比较k个算法,令\(r_i\)表示第\(i\)个算法的平均序值。
- \(r_i\)的均值$$\frac{k+1}{2}$$
推导过程:

- \(r_i\)的方差$$\frac{k^2-1}{12N}$$
推导过程:(方差的推导推到最后推不出来了,望各位指点)
定义检验统计量\(\tau_{\chi^2}\)为

当\(k\)和\(N\)较大时,服从自由度为\(k-1\)的\(\chi^2\)分布,这里显然对\(k\)和\(N\)的值有要求,较小时无显著区别,所以该检验方法过于保守,为了解决小数值\(k\)和\(N\)的检验问题,则使用\(\tau_F\)来进行检验。
这里\(\tau_F\)服从自由度为\(k-1\)和\((k-1)(N-1)\)的\(F\)分布。

这里仅给出了常用值,全部可用值在浙江大学概率论与数理统计(第四版)387页F分布表中给出。
Nemenyi后续检验(Nemenyi post-hoc test):
“Friedman”检验仅用于说明算法间性能是否相同,若要区分各算法,则需进行后续检验。
- 计算临界值域
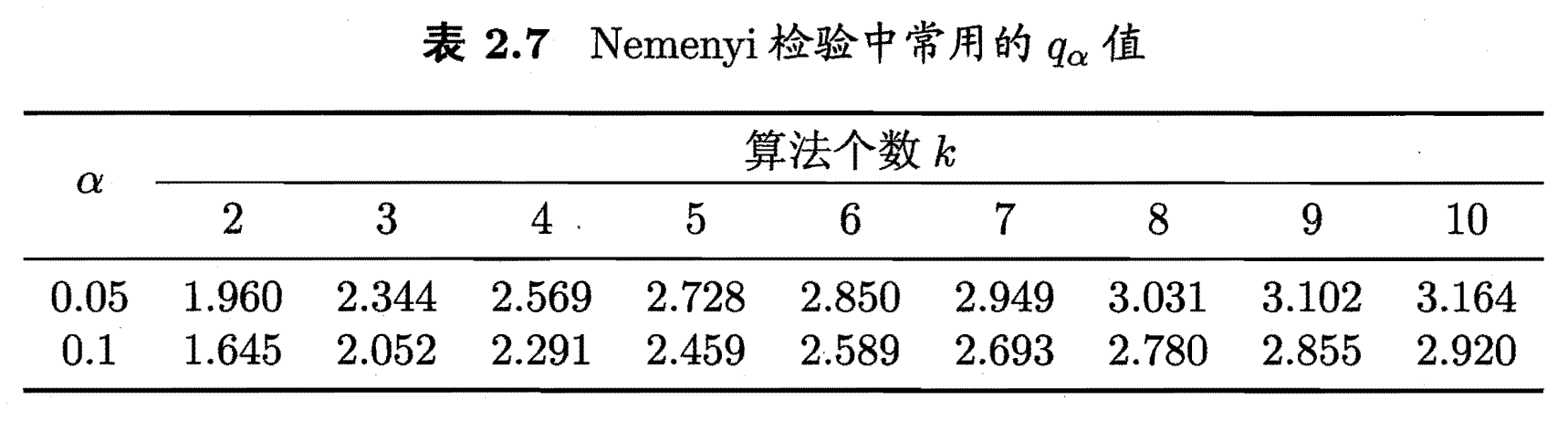
- 若两算法\(平均序值之差>临界值域CD\),则两算法性能不相同。
Friedman检验用来判断所有算法是否存在显著差异,若存在,则利用Nemenyi后续检验对算法进行两两比较,区分出哪几组算法性能存在差异。
就可从图中观察,若两个算法的横线段有交叠,则说明这两个算法没有显著差别,否则即说明有显著差别。有差别的两算法,平均序值越小,算法性能越优。

TODO:这里遗留一个问题“这几种检验方式的使用场景以及适用条件?”
2.5 偏差与方差
主要解决“学习算法为什么具有这样的泛化性能?”。
“偏差-方差分解”(bias-variance decomposition):对学习算法的期望泛化错误率进行拆解。(为了探究泛化错误率由哪几部分构成)
- 几个变量:
测试样本:\(x\)
\(x\)在数据集中的所有标记:\(y_D\)
\(x\)在数据集中的真实标记:\(y\)(常量)
(在有噪声的情况下,\(y_D\)≠\(y\),包含噪声的标记为\(y_D-y\))
训练集\(D\)上学得的模型\(f\)在\(x\)上的预测输出:\(f(x;D)\) - 公式推导:
学习算法的期望预测(均值):
使用样本数相同的不同训练集产生的方差:
噪声:(对噪声标记平方的期望)
期望输出与真实标记的差别称为偏差(bias), 即
为便于讨论, 假定噪声期望为零, 即 \(\mathbb{E}_{D}\left[y_{D}-y\right]=0\). 通过简单的多项式展开合 并, 可对算法的期望泛化误差进行分解:
对此公式的解析,在南瓜书中极为详细,这里引用其解析公式2.41的解析
于是,
泛化错误率/泛化误差 = 偏差(学习算法能力) + 方差(数据的充分性) + 噪声(问题本身难度)
偏差:度量了学习算法期望预测与真实结果的偏离程度,刻画了学习算法本身的拟合能力(偏差越大,拟合能力越差);
方差:度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响(方差越大,数据的变动影响越大);
噪声:表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度(噪声越大,问题越难)。
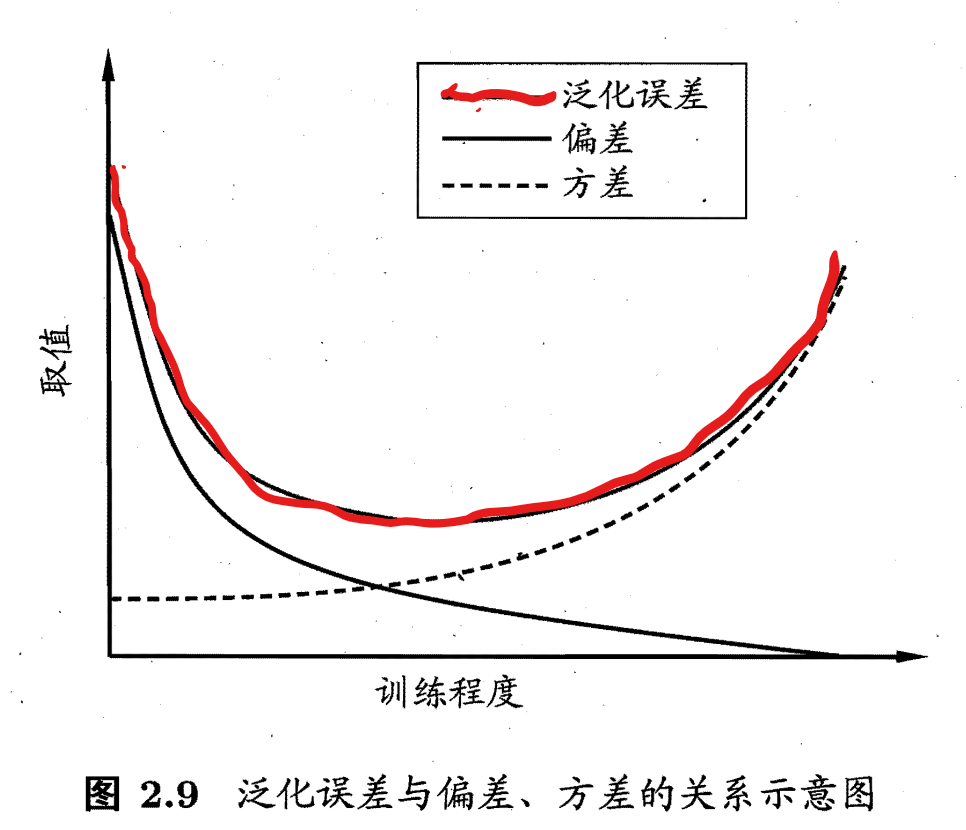
偏差-方差窘境(bias-variance):偏差与方差间的关系并非正相关,而是呈现一种近似负相关的关系,即两者存在冲突。在学习算法拟合不足时,数据的波动对学习器的影响很小;学习算法过拟合时,数据的波动又会产生过多的干扰。
第二章更新时隔了多日,主要还是对基础概率论和统计学知识的欠缺,重温了浙大概率论感觉好很多了,对第二章一些公式的推导相较于第一章明显欠缺了太多了,在之后的学习过程再补齐吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号