hadoop balancer
语法:
To start:
start-balancer.sh
用默认的10%的阈值启动balancer
hfs dfs balancer -threshold 3
start-balancer.sh -threshold 3
指定3%的阈值启动balancer
To stop:
stop-balancer.sh
Threshold参数是1%~100%范围内的一个数,默认值是10%。Threshold参数为集群是否处于均衡状态设置了一个目标。
如果每一个datanode的利用率(已使用空间/节点总容量)和集群利用率(集群已使用空间/集群总容量)不超过Threshold参数值,则认为这个集群是均衡的。
Threshold参数值越小,集群会越均衡。但是以一个较小的threshold值运行balancer带到平衡时花费的时间会更长。同时,如果设置了一个较小的threshold,但是在线上环境中,hadoop集群在进行balance时,还在并发的进行数据的写入和删除,所以有可能无法到达设定的平衡参数值。
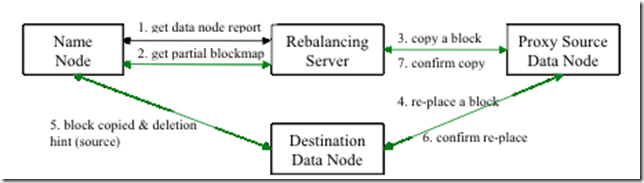
每次移动,一个datanode不会接受或移出少于10G的block或少于datanode总容量threshold百分比的block。每次移动不会运行超过20分钟。在每次移动结束,balancer会向namenode提交更新后的datanodes信息。
系统限制了balancer可以使用的带宽最大值,由如下参数设置:
dfs.balance.bandwidthPerSec
这个参数设置了一个数据块从一个datanode移到另一个时达到的最大速度。默认是1MB/s。该参数设置的越大,集群达到均衡的速度越快,但对应用进程带宽资源的竞争也就越大,会导致mapred应用运行缓慢。
❤该参数在集群重启后生效
❤该工具在一个hdfs集群中只能启动一个实例
❤balancer在如下5种情况下会自动退出:
①集群已达到均衡状态;
②没有block能被移动;
③连续5次迭代移动没有任何一个block被移动;
④当与namenode交互式出现了IOException;
⑤另一个balancer在运行中。
对应5个退出信息:
* The cluster is balanced. Exiting
* No block can be moved. Exiting...
* No block has been moved for 5 iterations. Exiting...
* Received an IO exception: failure reason. Exiting...
* Another balancer is running. Exiting...
二、下面是对Balancer类的分析:
首先看下主要的属性:
MAX_NUM_CONCURRENT_MOVES:允许同时并发复制的块数 默认为5
threshold:阈值 默认10%
支持的协议类型:NamenodeProtocol ClientProtocol
四个链表:
overUtilizedDatanodes:过载的datanode信息
aboveAvgUtilizedDatanodes:大于阈值的datanode信息
belowAvgUtilizedDatanodes:小于阈值的datanode信息
underUtilizedDatanodes:空载的datanode信息
两个集合:
sources:源地址集合
targets:目标地址集合
两个Map:
globalBlockList:记录balance过程中全部块和balance的块的对应信息
datanodes:记录datanode和balance的块的对应信息
两个线程池
moverExecutor:用于移动的线程池 默认1000
dispatcherExecutor:用于分发的线程池 默认200
首先看主要的概念类:
1、BalancerBlock类来跟踪Balancer过程中的块信息,其中包括块信息和所对应的datanode的列表信息
2、BytesMoved类记录移动的字节数
3、MovedBlocks类,这个类维护了两个窗口,一个是旧数据,一个是最近的数据,之所以说最近是为了区别最新,要保证窗口中存储1.5小时内被移动的块的信息,可以通过参数dfs.balancer.movedWinWidth来配置窗口时间,过期的块信息会被删除。
4、NodeTask类代表了一个需要复制byte的对象,这个对象存在于source节点,包含了目标节点和byte长度
5、BalancerDatanode类主要是在balance过程中跟踪datanode的信息,其中记录了datanode中多个PendingBlockMove
初始化的时候设置了节点的磁盘利用率、最大可以移动的块大小等等。
6、Source类继承了BalancerDatanode,继承了BalancerDatanode类中记录的节点信息,又新定义了几个特殊的针对源datanode的操作:
dispatchBlocks():分发线程的主方法,首先选择要移动的块,然后调用给代理源发送移动请求,当源节点的利用率小于阈值的时候,向请求namenode请求更多的块,当分发了足够的块或是接收到了namenode发出的足够块信息或是超过运行的限制时间时停止(默认20分钟)。
chooseNextBlockToMove():返回一个可以被立即分发的块的信息
7、内部类PendingBlockMove记录了块移动过程中的跟踪信息
包括要移动的块、源地址、目标地址、代理源,这里有必要说下代理源的原理,源node先把数据块拷贝给代理,然后由代理复制到目标节点,这么设计的好处我想应该是为了保证数据不丢失吧,但是也相当于多了一个中间环节,可以说有利有弊吧。
这个内部类提供了下面的方法:
chooseBlockAndProxy():为本次拷贝选择要拷贝的块和代理
markMovedIfGoodBlock(BalancerBlock block):如果块是可以移动的,那么标记并放到movedBlocks队列中
这里面所说的可以移动是指能马上移动,并且已经找到了一个不繁忙的代理
dispatch():把块分发给代理
sendRequest(DataOutputStream out):发出replace命令
receiveResponse(DataInputStream in):解析操作结果
下面分析Balancer类的主方法:
createNamenode(Configuration conf):和namenode创建一个基于NamenodeProtocol协议的连接
getUtilization(DatanodeInfo datanode):获得datanode的使用情况
checkAndMarkRunningBalancer():用标记文件的方法保证守护进程的唯一性
chooseSource(BalancerDatanode target,Iterator<Source> sourceCandidates, boolean onRackSource) 选择源节点,最后一个参数指出源和目标是不是同一rack,选择好更新源队列和目标队列
chooseTarget(Source source,Iterator<BalancerDatanode> targetCandidates, boolean onRackTarget)和选择源类似
dispatchBlockMoves():提交分发请求到分发线程池中,并等待复制结束
waitForMoveCompletion():通过检查target方法的pendingMove队列判断复制是否结束。
三、日志解读
①确认基本信息
2016-05-26 16:07:54,572 INFO org.apache.hadoop.hdfs.server.balancer.Balancer: Using a threshold of 3.0
2016-05-26 16:07:54,574 INFO org.apache.hadoop.hdfs.server.balancer.Balancer: namenodes = [hdfs://ochadoopcluster]
2016-05-26 16:07:54,575 INFO org.apache.hadoop.hdfs.server.balancer.Balancer: p = Balancer.Parameters[BalancingPolicy.Node, threshold=3.0]
②确认all data node lists
org.apache.hadoop.net.NetworkTopology: Adding a new node: /rack/rack7/IP:PORT
③搜集四个链表,确认需要移动block的节点,以及第一次iteration需要移动的数据量
overUtilizedDatanodes:过载的datanode信息
aboveAvgUtilizedDatanodes:大于阈值的datanode信息
belowAvgUtilizedDatanodes:小于阈值的datanode信息
underUtilizedDatanodes:空载的datanode信息
2016-05-26 16:07:57,665 INFO org.apache.hadoop.hdfs.server.balancer.Balancer: 0 over-utilized: []
2016-05-26 16:07:57,665 INFO org.apache.hadoop.hdfs.server.balancer.Balancer: 2 underutilized: [BalancerDatanode[A, utilization=70.97845296326437], BalancerDatanode[B, utilization=77.14335325387569]]
2016-05-26 16:07:57,668 INFO org.apache.hadoop.hdfs.server.balancer.Balancer: Need to move 2.22 TB to make the cluster balanced.
2016-05-26 16:07:57,669 INFO org.apache.hadoop.hdfs.server.balancer.Balancer: Decided to move 10 GB bytes from C to A:50011
2016-05-26 16:07:57,669 INFO org.apache.hadoop.hdfs.server.balancer.Balancer: Decided to move 10 GB bytes from D to B
2016-05-26 16:07:57,669 INFO org.apache.hadoop.hdfs.server.balancer.Balancer: Will move 20 GB in this iteration
其中A\C同机架,B\D同机架
④开始执行一次iteration
然后循环执行②-④直至集群均衡
目前可以确定的是,均衡原则,首先在同机架内均衡,
四、源码解读
均衡原则:从源节点列表和目标节点列表中各自选择节点组成一个个对,选择顺序优先为同节点组,同机架,然后是针对所有
// all data node lists 列出所有datanode节点
// compute average utilization 计算出平均利用率
// create network topology and classify utilization collections
// over-utilized, above-average, below-average and under-utilized. 创建network topology收集四个链表集合
// return number of bytes to be moved in order to make the cluster balanced 返回为达到集群平衡需要移动的bytes数
/* log the over utilized & under utilized nodes */ 记录the over utilized & under utilized
// First, match nodes on the same node group if cluster is node group aware 首先,如果集群有节点组则匹配同一组内节点
// Then, match nodes on the same rack 然后,匹配同机架内节点
// At last, match all remaining nodes 最后匹配所有剩余节点
/** Decide all pairs according to the matcher. */ 决定需要匹配的节点对
/* first step: match each overUtilized datanode (source) to one or more underUtilized datanodes (targets).*/ 匹配每个过载数据节点(src)转移到一个或多个空载的数据节点(targets)
/* match each remaining overutilized datanode (source) to below average utilized datanodes (targets). Note only overutilized datanodes that haven't had that max bytes to move satisfied in step 1 are selected*/ 匹配剩下的过载数据节点(source)转移到低于平均利用率的数据节点(tartget)。注意:这些数据节点为firststep中没有达到最大移动值的过载节点。
/* match each remaining underutilized datanode (target) to above average utilized datanodes (source). Note only underutilized datanodes that have not had that max bytes to move satisfied in step 1 are selected.*/ 匹配剩下的每个空载节点(target)和高于平均利用率的数据节点(source)。转移到低于平均利用率的数据节点(tartget)。注意:这些数据节点为firststep中没有达到最大移动值的过载节点。
/**For each datanode, choose matching nodes from the candidates. Either the datanodes or the candidates are source nodes with (utilization > Avg), and the others are target nodes with (utilization < Avg).*/ 对每个数据节点,从候选节点中选择匹配节点。所有高于平均利用率的节点(所有数据节点和候选节点)作为source节点,其他的低于平均率的节点作为target节点
/**For the given datanode, choose a candidate and then schedule it.@return true if a candidate is chosen; false if no candidates is chosen.*/
/** Choose a candidate for the given datanode. */
/* reset all fields in a balancer preparing for the next iteration */
/** Run an iteration for all datanodes. */
/* Decide all the nodes that will participate in the block move and the number of bytes that need to be moved from one node to another in this iteration. Maximum bytes to be moved per node is Min(1 Band worth of bytes, MAX_SIZE_TO_MOVE).*/
/* For each pair of , start a thread that repeatedly decide a block to be moved and its proxy source, then initiates the move until all bytes are moved or no more block available to move. Exit no byte has been moved for 5 consecutive iterations.*/
/** Balance all namenodes.For each iteration,for each namenode,execute a {@link Balancer} to work through all datanodes once. */
/* Given elaspedTime in ms, return a printable string */
// exclude the nodes in this set from balancing operations
//include only these nodes in balancing operations
总结:
1.balance的步骤:
1)从namenode获取datanode磁盘使用情况
2)计算哪些节点需要把哪些数据移动到哪里(是可以跨机架均衡的)
3)分别移动,完成后删除旧的block信息
4)循环执行,直到达到平衡标准
- 大于平均使用;
- 过度使用;
- 小于平均使用;
- 几乎没有被使用。
跨机架数据平衡步骤如下所示:
- 首先,数据从类型 2 机器移动到类型 4 机器;
- 其次,数据从类型 2 机器移动到类型 3 机器;
- 最后,数据从类型 1 机器移动到类型 3 机器。
以上步骤在负载没有达到指定阈值前会迭代式执行。
*满足了balancer的threshold百分比即haodop前台的|datanodes usages%(min)-datanodes usages%(median)|和|datanodes usages%(median)-datanodes usages%(median)|都<=threshold


 浙公网安备 33010602011771号
浙公网安备 33010602011771号