
mysql hive sql 进阶
场景:

说明.1.上面的数据是经过规整的数据,step是连续的,这个可以通过row_number实现.连续是必要的一个条件因为在计算第二个查询条件时依赖这个顺序,如果step不是数字字段可以截取然后转为数字
1、查询每一步骤相对于路径起点人数的比例
2、查询每一步骤相对于上一步骤的漏出率
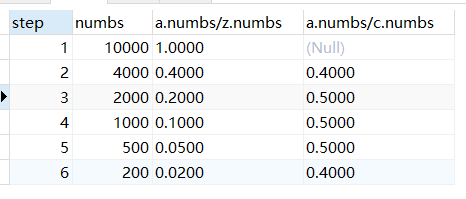
说明1.step=1时为起点.
2.以上需求是要在hive中实现的,但是么有数据就就再mysql中实现,sql大致一样
3.sql在mysql下测试都是通过的
| CREATE TABLE `step1` ( `id` int(11) DEFAULT NULL, `numbs` int(11) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
select a.id,a.numbs ,a.numbs/(select c.numbs from step1 c where c.id = (select min(id) from step1 b) ),a.numbs/d.numbs from step1 a left join step1 d on d.id = a.id -1 order by a.id asc
思路:1.求出第一步
select c.numbs from step1 c where c.id = (select min(id) from step1 b),
2求出上一步
left join step1 d on d.id = a.id -1 order by a.id asc
第二种实现
select a.id as step,a.numbs ,a.numbs/z.numbs , a.numbs/c.numbs from step1 a inner join (select y.minid, x.numbs from (select min(id) minid from step1 b) y join step1 x on x.id = y.minid) z left join step1 c on a.id-1 = c.id group by a.id asc;
由"查询每一步骤相对于路径起点人数的比例"可知,每一行的数据都要和起点行的数据相除.那么,就是每一行都要有起点行的数据,此时当数据表有多行,起始数据只有一行时,他们再inner join一下,就达到目的了

之后再进行相除就很简单了
场景2 : 求每月的访问量,截止到当月的每个用户的总访问量
可能适用的一个场景,之前在工作中遇到需求,就是要对一个数据进行累加,累加是按月的,比如,1月31日统计之后1月就停止统计,然后将1月31日的值继续计算2月的.这样一直计算,到每个月的最后一天这个月的统计就结束.
解决方法,级联求和,二次求和,第一次已经聚合了,第二次聚合时使用max函数,或者min函数对上次的数据进行一次"聚合"因为第一次已经聚合过了,这一列只有一个值,所以聚合之后还是一样的结果.
数据
A 2015-01 5 A 2015-01 15 B 2015-01 5 A 2015-01 8 B 2015-01 25 A 2015-01 5 A 2015-02 4 A 2015-02 6 B 2015-02 10 B 2015-02 5
CREATE TABLE `t_access` ( `vistor` varchar(255) DEFAULT NULL, `ymonth` varchar(255) DEFAULT NULL, `vistTimes` int(11) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
结果:
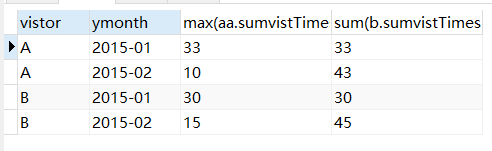
select A.vistor,A.ymonth,max(A.vistTimes) as vistTimes,sum(B.vistTimes) as accumulate from (select vistor,ymonth,sum(vistTimes) as vistTimes from t_access group by vistor,ymonth) A inner join (select vistor,ymonth,sum(vistTimes) as vistTimes from t_access group by vistor,ymonth) B on A.vistor=B.vistor where B.ymonth <= A.ymonth group by A.vistor,A.ymonth order by A.vistor,A.ymonth; select * from t_access;
select aa.vistor,aa.ymonth ,max(aa.sumvistTimes),sum(b.sumvistTimes) from (select a.vistor,a.ymonth ,SUM(a.vistTimes) as sumvistTimes from t_access a group by a.vistor,a.ymonth ) aa left join (select m.vistor,m.ymonth ,SUM(m.vistTimes) as sumvistTimes from t_access m group by m.vistor,m.ymonth ) b on b.vistor = aa.vistor where aa.ymonth >= b.ymonth GROUP BY aa.vistor,aa.ymonth
总结,上面的两个场景都用到了inner join ,尤其在第一种实现时,感觉提高了查询性能,(没有测试过).hive只支持等值的join
学好计算机,走遍天下都不怕

