重试,让程序更健壮
任何通过网络与其它应用通讯地的程序,都应该有足够的灵活性,来应对短暂的临时性故障。因为这些故障很多时候是可以自恢复的。
例如,为了避免服务过载,很多应用会采取某些限流措施,在并发请求达到一定数量时,暂时性的拒绝新的请求加入。这种情况下,尝试使用该应用的程序,一开始可能会被拒绝连接,但下一刻就好了。
因此,在设计系统时,应该考虑到此种故障。并且在条件允许时,加入重试机制,自动再次发起相应的请求。在某些情况下,可能会显著的改善应用程序的用户体验。
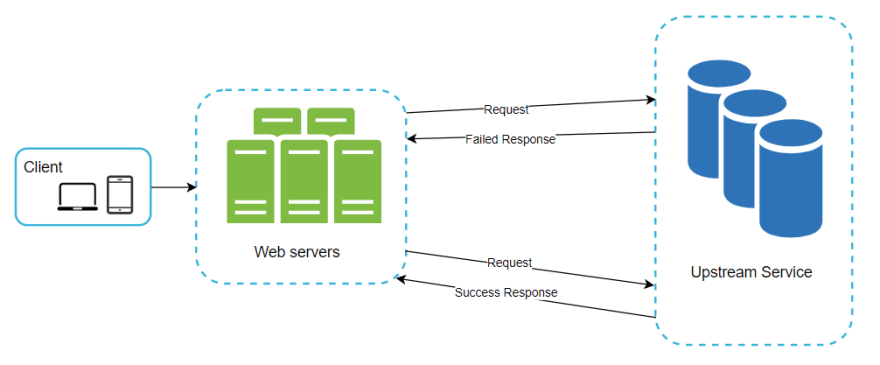
能否发起重试,最重要的前提之一是,对同一资源的发起多次相同的请求,能否得到相同的结果。即资源接口是否具有幂等性。
标准 REST API 中,GET/HEAD/OPTIONS 通常是不会更改服务器上的资源的,因此大多是可重试的。
换个说法就是,如果能够确定,下次请求有可能成功,那就可以尝试重试。否则的话,就不必浪费时间、精力以及系统资源了。
例如,在请求 HTTP 服务时,收到 503 或 408 这样的状态码,则重试可能会有效;但是如果收到了 401 或 403 之类的状态码,则简单的重试肯定不起作用。
确定了什么情况下发起重试后,还有另外一个问题值得考虑。即在什么时间、以什么样的频率发起重试。尽管可以,但通常并不会是请求失败后,立即发起重试,而是需要根据具体的场景,选择合适的重试
时机。
假如说我们请求失败的原因,是服务端请求过载。则立即发起重试,除了给服务端添乱外,不会有其它结果。严重情况下,可能会加剧服务器的负担,直到耗尽服务器资源。
为了避免上述问题,常见的做法是在重试之前增加一些延迟。但是如何增加这些延迟,又有多种策略,比较多使用的有两种:
- 固定间隔。即每次请求失败后,都等待固定的时间后,再次发起下次重试请求;
- 指数递增。即多次请求之间的延时,成倍增加;
如果失败是由服务端过载引起的,则后一种策略可能会更好。假如它的初始请求在 0ms 发出,则第二次请求在失败 200ms 后发出,第三次请求在失败 400ms 后发出,第四次在 800ms... 以此类推。这种分散的请求和重试机制,可能有助于减缓客户端及服务器的负载,提高我们最终获取到成功结果的机会。
但是假如所有的请求都从同一时刻发起,并按照同样的机制延时重试,则两种策略是一样的,并不会有所改进。这种情况下,可能需要加入一些随机因素。
扯的有点多,接下来搞些实际的,上一点儿代码。简单起见,这里演示一下在 JavaScript 中的实现,使用诸位都了解的 axios。Axios 提供了拦截器机制,用来处理通用的重试逻辑正合适。
const SLEEP_TIME = 200;
const RETRY_TIMES = 3;
const RETRY_STATUS = [408, 503, 504];
function getSleepTime(i = 0) {
const wTime = Math.min(SLEEP_TIME * 2 ** i);
return Math.random() * wTime;
}
async function fakeSleep(ms) {
await new Promise((resolve) => {
setTimeout(() => {
resolve();
}, ms);
});
}
async function onError(error) {
const { status } = error.response;
let { retryCount = 0 } = error.response.config;
if (RETRY_STATUS.includes(status) && retryCount < RETRY_TIMES) {
retryCount += 1;
sleep_ms = getSleepTime(retryCount);
await fakeSleep(sleep_ms);
error.config.retryCount = retryCount;
return await axios(error.config);
}
}
axios.interceptors.response.use(onError);
代码不多,应该不需要额外的解释。其它编程语言,实现思路大致也差不多。相信您肯定可以写出更好的。
欢迎批评指正。
原创文章,转载时请保留此声明,并给出原文连接。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号