SQUAD的rnet复现踩坑记
在港科大rnet(https://github.com/HKUST-KnowComp/R-Net) 实现的基础上做了复现
采用melt框架训练,原因是港科大实现在工程上不是很完美,包括固定了batch size,固定了context 长度为400,过滤了超过长度的context,每个batch长度都固定到400。
melt框架支持dynamic batch size, dynamic batch length,多gpu,修复了bucket的问题,目前采用长度<=400 batch size 64 长度> 400 batch size 32
Dynamic batch可以比较准确的eval 因为样本数目不一定是64的倍数, dynamic batch length 可以一定程度提速 并且结合buket和不同的batch size来跑较长的文本,港科大去掉了部分长度>400的训练数据
港科大版README展示的效果(word+char)
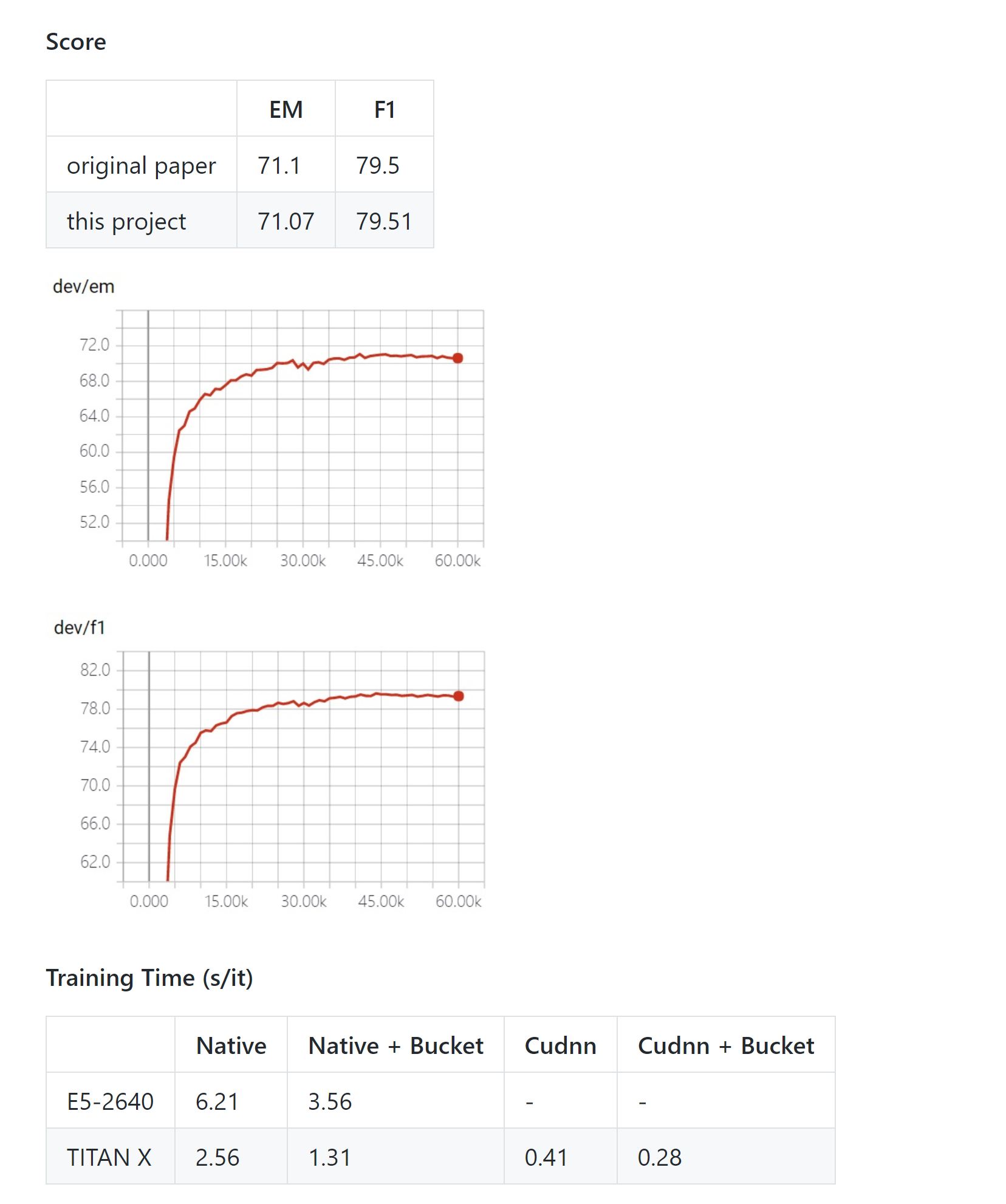
下载港科大代码修改hiden size 75->76 实际跑没有达到上面这么高的dev效果 实际效果如下
Word + char
Exact Match: 70.39735099337749, F1: 79.38397223161256
Word only
Exact Match: 69.59318826868495, F1: 78.64400408874889
港科大word only
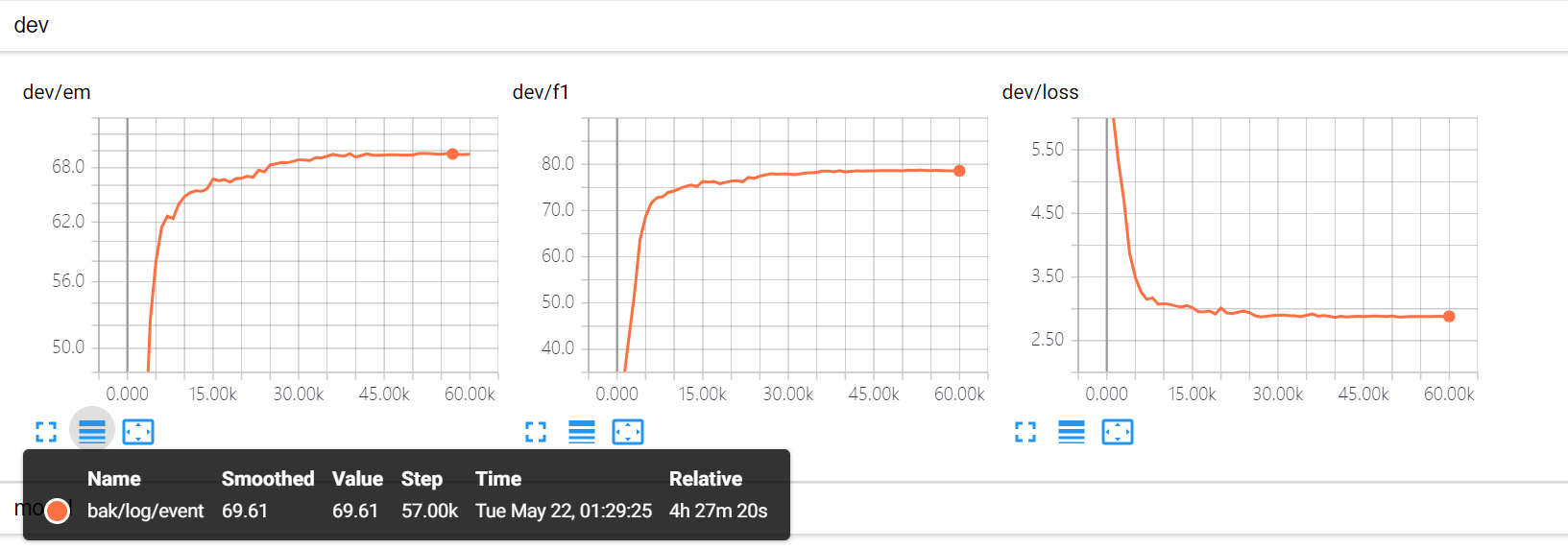
港科大 word + char hidden 76

Word + char hidden 75 (原始代码不做任何改动, python3 tensorflow_version: 1.8.0-dev20180330) 似乎还是没达到readme 给出的那么高效果 em 差不到0.6个点
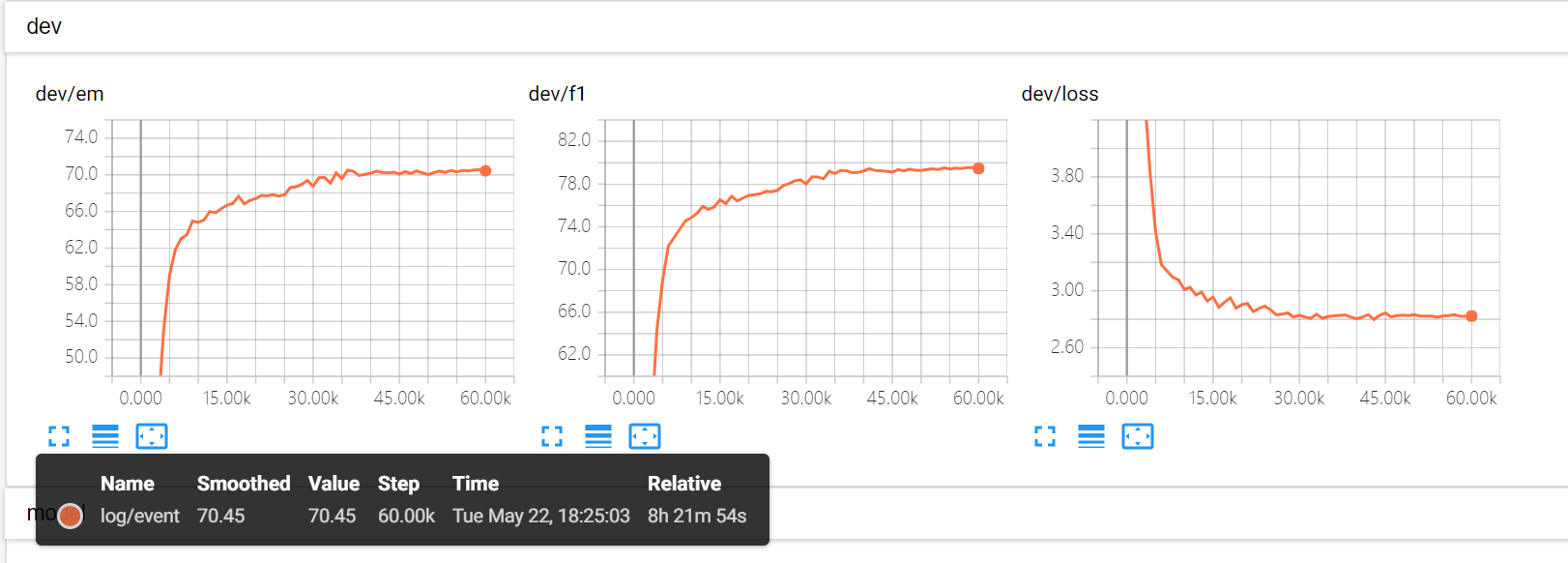
训练速度如下图 采用单gpu gtx1080ti训练 硬盘ssd,参考港科大我提的issue 改动港科大默认hidden size 75 -> 76 (4的倍数)否则速度比较慢, 不使用bucket

buckets按照 40,361 加速一点点

两个gpu加速效果甚小

四个gpu

单gpu word + char 训练 char embedding和港科大一样 设置为8

对应大概0.35s/it
在这个数据集 其它一些实验结果
adadelta 0.5 learning rate效果最好 > adam 0.001 > adagrad 0.01
按照dev loss动态减小learning rate有效 和港科大一样采用decay patience 3, decay factor 0.5 后面也可以考虑对比采用监控dev em或者f1来做lr decay
Glove word embedding 如果finetune 效果提升一点
context和question采用不同rnn encoder 效果变差。
4个gpu 64*4 batch size训练 由于batch size的增大 收敛加快,word only模型f1值 能达到0.783由于 单gpu batch size 64,但是比较奇怪是dev loss在30 epoch之后就呈现增长过拟合趋势 尽管dev em 和 f1指标没有过拟合倾向
后来我发现 始终和HKUST版本效果有差距 港科大代码实测 虽然em 70+ f1 78+ 如果只使用word em69.6 f1 78+, 差在哪里呢 只能说理解不深。。。 经过多次实验定位。。。
这里发现开始阶段表现更好的模型 一般来说最后效果也会好一些。


原因在于dropout。。
我改成了这个样子

而 港科大代码是dropout放在了类的初始化函数中 每个layer一个dropout
A Theoretically Grounded Application of Dropout in
Recurrent Neural Networks
The variant Gal and Ghahramani [6] proposed is to use the same dropout mask at each time step for both inputs, outputs, and recurrent layers.
来自 <https://becominghuman.ai/learning-note-dropout-in-recurrent-networks-part-1-57a9c19a2307>
- variational_recurrent: Python bool. If True, then the same dropout pattern is applied across all time steps per run call. If this parameter is set, input_size must be provided.
来自 <https://www.tensorflow.org/api_docs/python/tf/contrib/rnn/DropoutWrapper>
这里港科大采用的是variational_recurrent 也就是我的修改也没有改动这个事实 港科大为啥要放在init里面?
- noise_shape: 1D tensor of type int32 representing the shape of the binary dropout mask that will be multiplied with the input.
- For instance, if your inputs have shape (batch_size, timesteps, features), and you want the dropout mask to be the same for all timesteps, you can use noise_shape=[batch_size, 1, features].
来自 <https://www.tensorflow.org/api_docs/python/tf/layers/dropout>

我理解主要目的是为了context 和question在一次训练batch中 同一个context和question共享 相同的droput

不过港科大 处理char的时候 context question 的embedding用了不同droput。。 似乎用cudnn gru 也不太好share。。。因为是3纬度的 展开之后 batch size 不一样 对应不上去了 当然也可以实现share(title + reshape)
为啥港科大对单层 char 没有用cudnn gru 还是用普通gru 我理解一样的 我这里还是使用cudnn gru对char建模

Ok 最后是运行效果
对应squad 这个 HKUST只选了glove有预训练的词 并且不finetune,实测是否finetune word embedding针对这个应用效果差不多
特别需要注意是context 和 question需要共享相同的dropout否则效果变差

无一例外 不共享的.nsd效果差
实验了 模仿HKUST的gloveonly,选取训练集合中min_count>=10的作为vocab增加少量不在glove中的词(91590->91651不到100),选取glove+train全量
似乎min count10 效果好一点点
Word only采用了context和question共享droput之后 效果追上HKUST效果

比较明显的 貌似 gloveonly 还是 finetune效果比较好 说明基本都是训练中出现充分的词汇finetune效果会好一些 ?
但是rnet.fixebm效果好于rnet说明 可能 部分词汇finetune了 部分没训练到 用的初始随机变量 效果会稍微差一些?
Word only版本 min10.fixemb效果好 说明如果词汇出现足够 训练过程中参与rnn调整 对效果有一定提升 尽管随机的词向量不变化
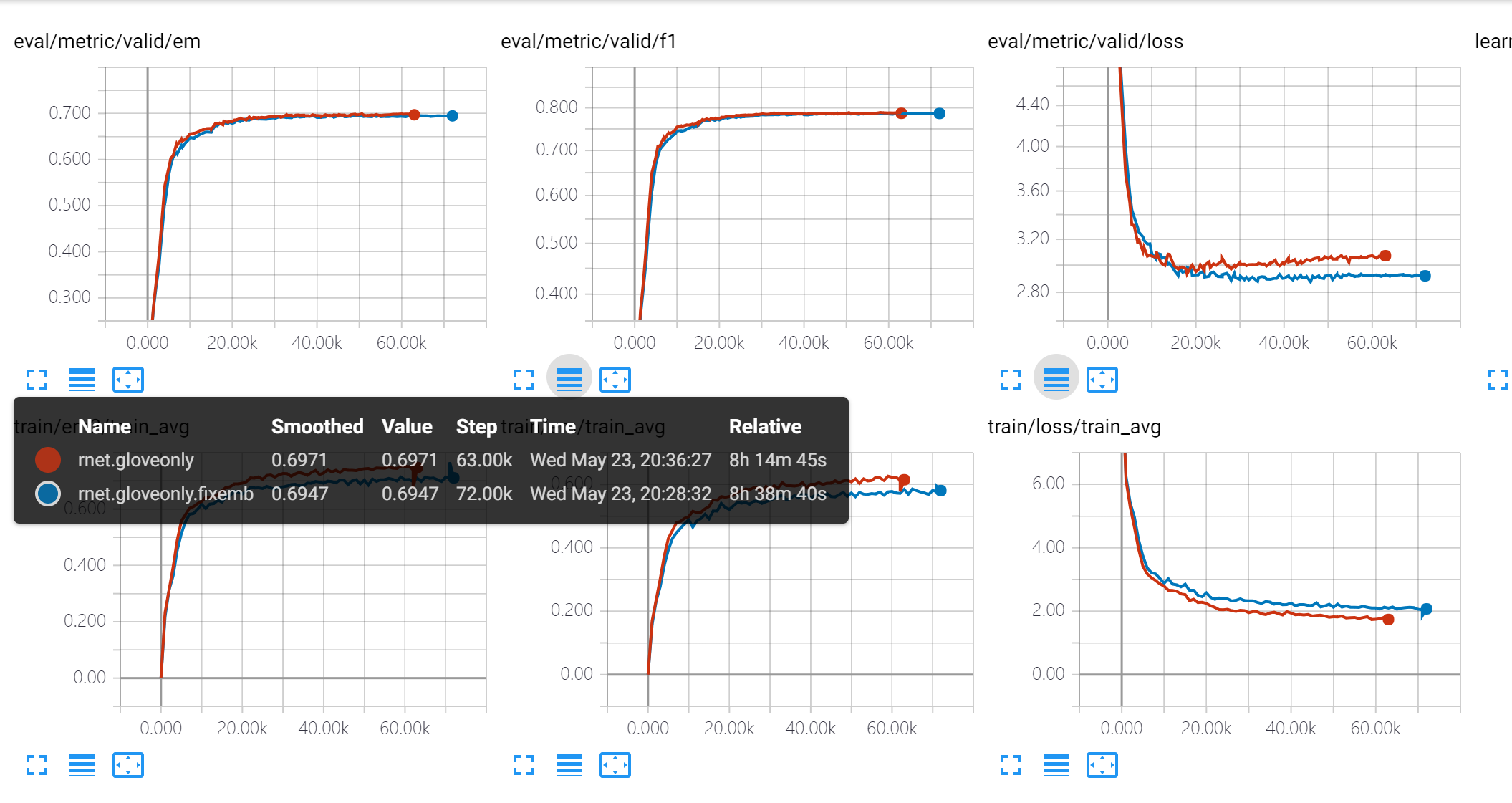
看dev指标提升一点 训练数据指标提升明显 包括loss 但是看dev loss已经有明显过拟合倾向 虽然dev指标还是稍好 安全起见squad可以不finetune word embedding, char embedding可以补充不常见词的知识。
TODO 可以尝试 ngram embedding 并且尝试不同组合方式 以及添加highway network 和 layer normalization.
下图是我对char 也采用了 droput share机制 类似word对应.chsd 不过看起来相比word的droput share 对结果影响不大。。 由于模型本身存在随机性 几个对比效果如下



不过感觉效果还是比HKUST的实现差一丢丢,尽快已经很少了,但是特别eval loss 还是明显比HKUST的高 word only 2.9+ word+char 2.88 大概 而 HKUST word only 2.88 word+char 2.85大概
又仔细看了下HKUST的预处理发现一个diff 我对于 unk的处理和HKUST不一样 HKUST使用的是全0向量作为unk向量 并且训练过程中不再变化。。
尽管直觉感觉这样不好。。 不过我还是实验了一下 设置 specail_as_zero == True(对应模型.hkust)

但是这组实验还是dev loss 不如HKUST。。这不是关键性的影响
最后考虑是否是bucket 400 影响了效果 尽管>400的文本不多 是我的的tf bucket代码使用 或是 tf bucket本身影响了随机性?
HKUST注意是去掉了所有>400长度的文章,这里我还是使用所有文章 但是不使用bucket(nobucket) bucket貌似有一点点影响 不大
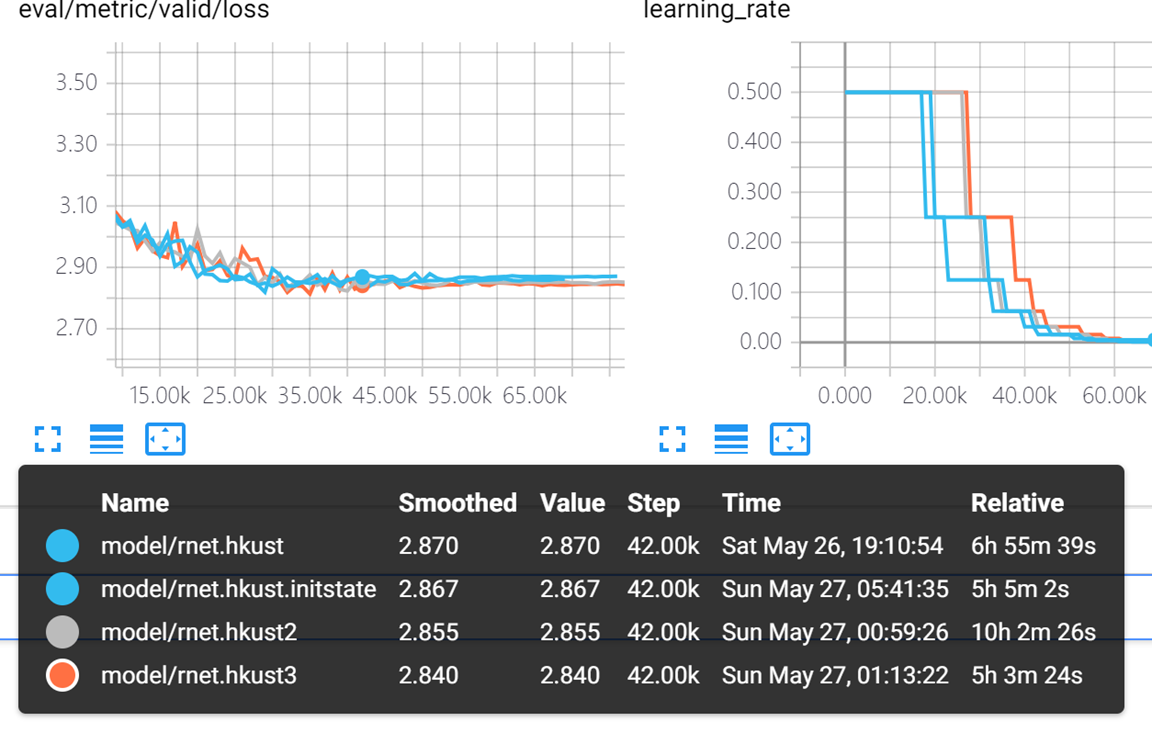
另外之前我使用了手工设定的按照特定epoch修改learning rate的方式,这里也改为使用HKUST的patience 3,decay 0.5的方式。
实验结果wordonly基本打平了HKUST的原版效果,尽管似乎dev loss后期不是如HKUST原版稳定但是数值基本一致,
这说明decay是非常重要的。。。 可能因为训练数据集合比较小,针对dev监控的动态学习率调整比较关键。 而bucket如果只是400这个影响不大。
另外语料不是太大 随机性也起到很大效果 可能陷入局部最优 不能找到全局最优




HKUST word only 最佳
Em 69.69 F1 78.69 dev loss 2.87

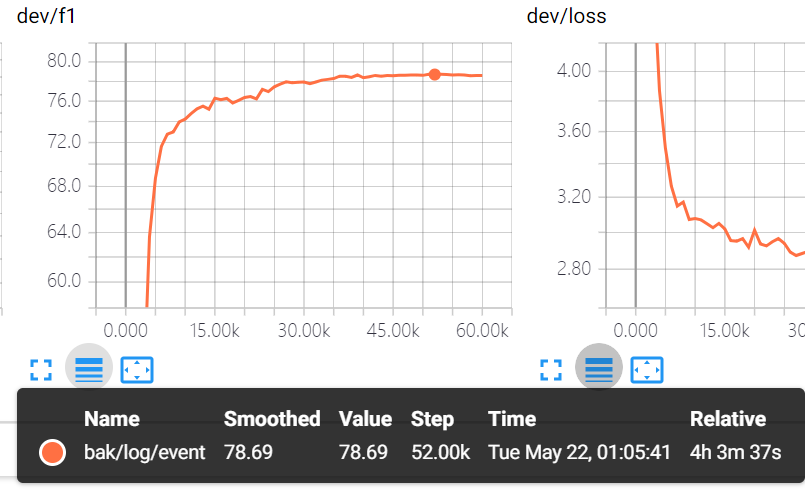
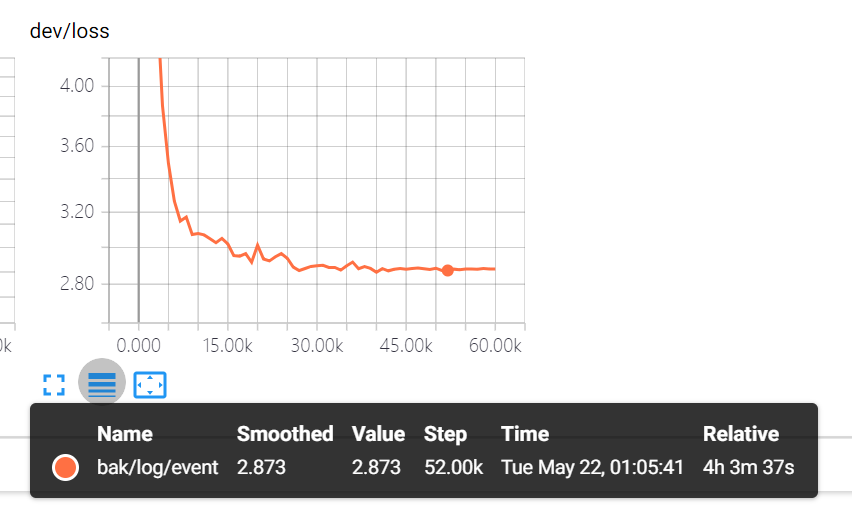
但是word_char效果还是明显比HKUST的差 , 定位问题应该出在char的处理上,注意HKUST的char的encoding是context和qustion 先走的recurrent droput 也就是说
noise_shape=[shape[0], 1, shape[-1]]情况下的droputout,于是改原来word和char都用cudnn gru同样encoding方式为HKUST原版的处理方式。
不过这里实际用cudnn效果差的原因是last state不对,因为cudnn不支持动态长度 所以padding 0也参与计算了 最后last state很可能是padding 0对应的 所以不准确。
实现效果 dev loss效果确实更贴近了2.85 但是f1值还是有差距79.1
HKUST word+char 最佳
Em 70.37 F1 79.34 dev loss 2.85 效果似乎还有一点点上升趋势
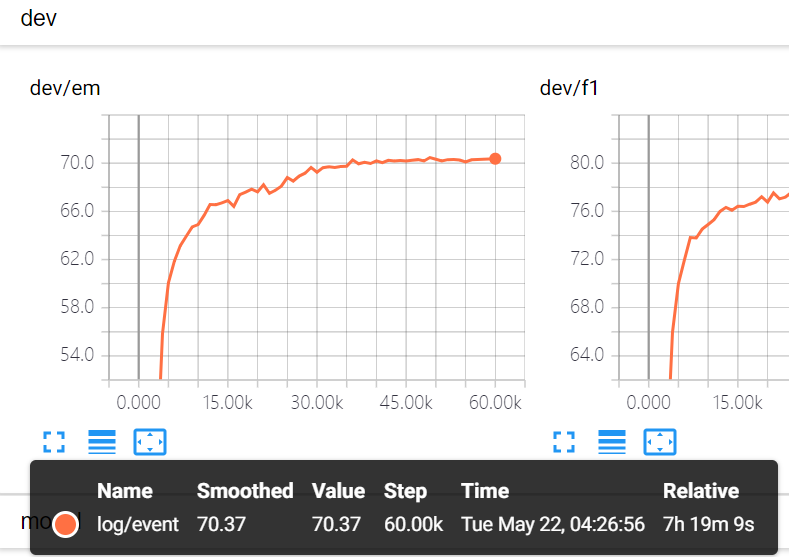

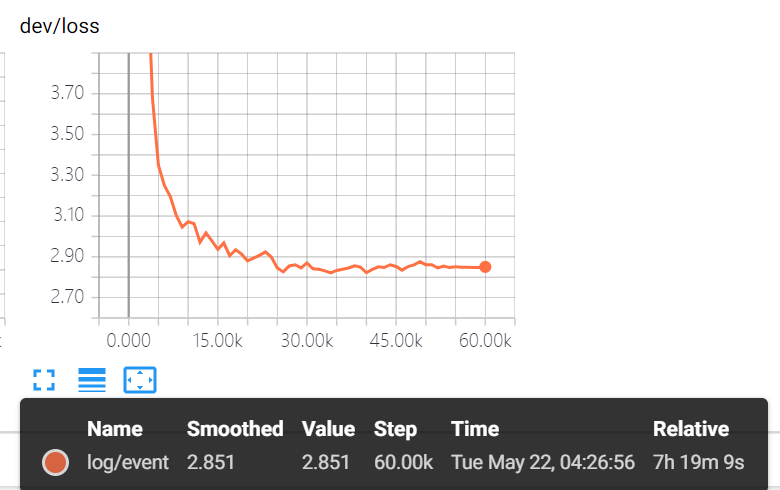
不过按照HKUST的issue
2.82 in dev, 1.32 in train
来自 <https://github.com/HKUST-KnowComp/R-Net/issues/6>
另外一个遗留的问题 cudnn gru HKUST的实现 我搬动到其它地方使用save模型 只有 cudnn_gru/opaque_kernel (DT_FLOAT) [87096]
但是原版代码 save之后都是带有

不知道是哪里影响的 我猜测这里不影响模型效果 opaque_kernel 应该存储了所有信息,下面的只是不知道什么开关影响的 存储了转换后的权重数据。
Finally 总结
- Word Share dropout 是最关键的 对应 一个context 和 question pair 需要相同的droput
- Char 的dropout也是很重要的
- Adadelta optimizer的默认参数 按照keras的 设置 很关键 已修改
- 按照dev loss的learning rate decay 很重要
- Finetune emb train拟合的更好 但是dev似乎容易过拟合 不要finetune emb 或者开始bufinetune 后期finetune可能有一点点提升效果 目前(70.53,79.12是这样 不过finetune带来的提升很少)
- Embedding 初始化影响一点效果 ? 我之前都是 random_uniform 而 HKUST使用random_normal 0.01 google transformer使用 random_normal dim ** -0.5 实验都还ok 影响不大
- 最后还是eval loss差一点 f1效果还是差 em 达到了, 但是HKUST训练过程中的dev loss计算也是过滤了长度>=400的 我这边实验了rain和dev都按照HKUST的做法 去掉长度>=400的(不过每个batch 长度还是按dynamic)
测试集合长度偏短 显然位置的softmax loss会低一点了 不过似乎去掉长文本之后效果还稳定了一些 而且提升了f1值。。 那么说明loss需要考虑下文本长度吗? TODO
Train 87599
Dev 10570
Filter context > 400 or qeustion > 100
Train 87391 99.7%
Dev 10483 99.1%
HKUST 60k step
Exact Match: 70.39735099337749, F1: 79.3839722316126
gezi@gezi:~/mine/hasky/deepiu/squad$ c0 sh ./train/evaulate.sh ./mount/temp/squad/model/rnet.hkust/epoch/model.ckpt-37.00-50505
Mine:
[('metric/valid/loss', 2.892608779740621), ('metric/valid/em', 0.7044465468306528), ('metric/valid/f1', 0.7919028182076531)]
epoch:37.3626/60 valid_step:51000 valid_metrics:['metric/valid/loss:2.87955', 'metric/valid/em:0.70466', 'metric/valid/f1:0.79236']
[('metric/valid/loss', 2.9003277952412523), ('metric/valid/em', 0.7048249763481551), ('metric/valid/f1', 0.7928490855150692)]
最高
./mount/temp/squad/model/rnet.hkust/epoch/model.ckpt-39.00-53235
[('metric/valid/loss', 2.890633753983371), ('metric/valid/em', 0.7052980132450332), ('metric/valid/f1', 0.7933954605863096)]
60k
[('metric/valid/loss', 2.887699271541044), ('metric/valid/em', 0.7054872280037843), ('metric/valid/f1', 0.7925004189917955)]

还是f1差一点点 那么 发现HKUST的init state是训练出来的 而不是使用它zero默认初始化的方式 修改按照HKUST的方式

Model增加变量。。
rnet/main/encoding/cudnn_gru/bw_0/init_state (DT_FLOAT) [1,1,76]
效果。。 就差在这个地方了 至少对应squad的应用 init state是非常影响效果的。。。 貌似之前各种应用场景都是用的zero作为init state 可以试一下对init state训练。
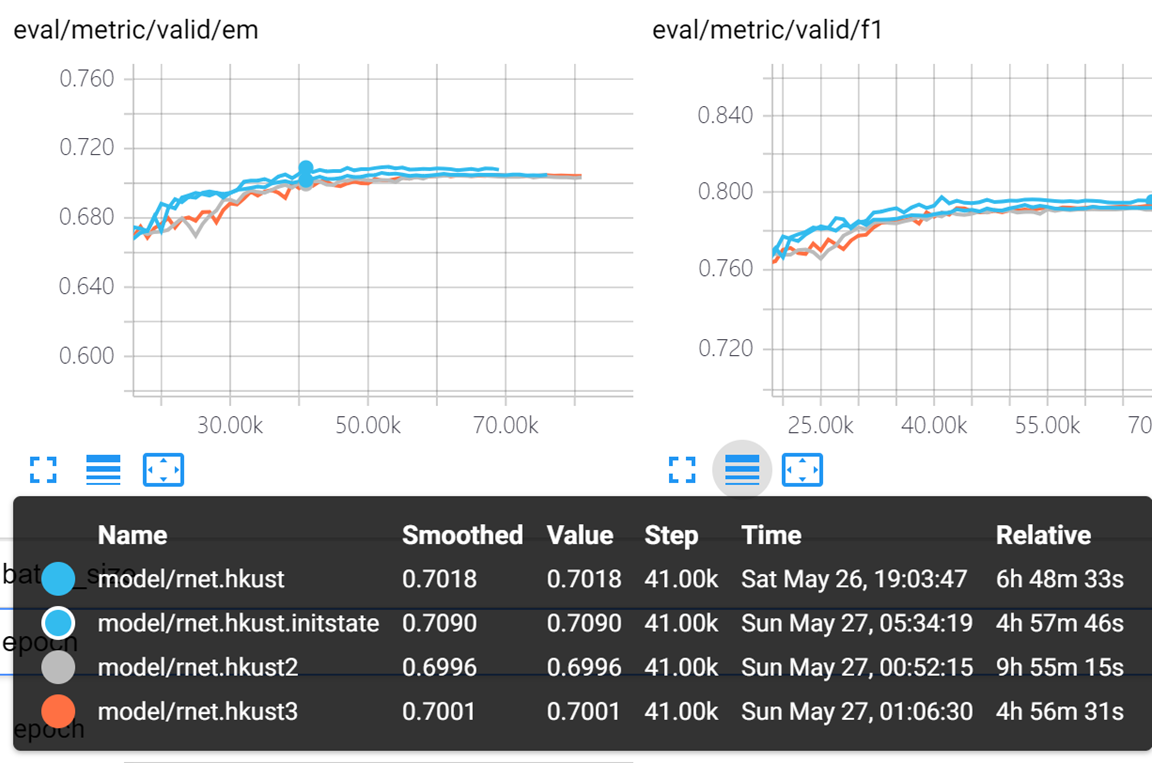
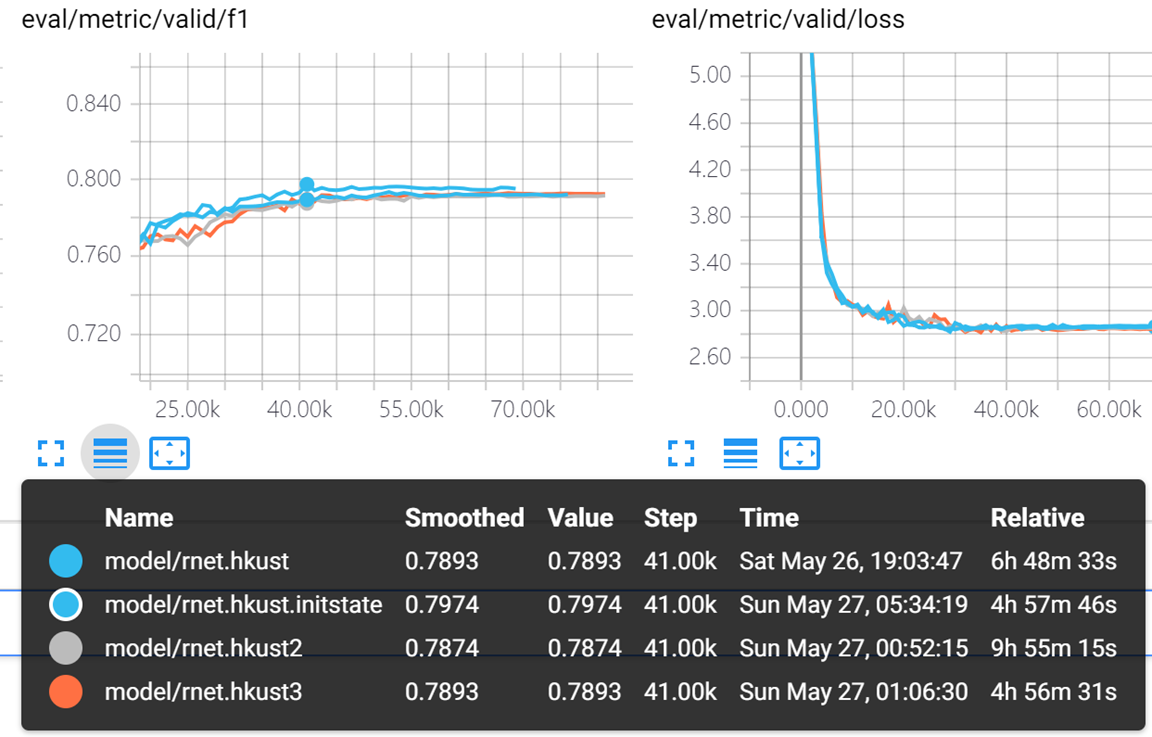
Rnet.hkust 表示char使用random uniform
rnet.hkust2 表示char使用random normal stddev 0.01
Rnet.hkust3 表示char使用类似google transofer的random normal , stddev dim ** -0.5
Rnet.hkust.initstate同rnet.hkust但是 使用了 训练 init state
貌似hkust3的初始化方式好一点 dev loss

由于测试数据少了一小部分 最终测试结果
[('metric/valid/loss', 2.871750499110624), ('metric/valid/em', 0.7094607379375591), ('metric/valid/f1', 0.7962988473545626)]
gezi@gezi:~/mine/hasky/deepiu/squad$ c3 sh ./train/evaulate.sh ~/temp/squad/model/rnet.hkust.initstate/epoch/model.ckpt-40.00-54600
HKUST 60k step
Exact Match: 70.39735099337749, F1: 79.3839722316126
基本完整复现了 HKUST RNET当然是在几乎完全copy的基础上 不过做了很多工程改进,有了这个baseline, 更加方便后续实验对比,有了这个baseline,后面可以尝试快速的conv seq2seq, transformer, qanet中的encoder用在文本分类和图文关系的效果。
最终定位了 影响最终效果的几个核心地方 感谢HKUST无私的代码开源! cudnn的使用 droput的使用 init state参与训练,太赞了
TODO:
Train init state的效果和 <S> </S> 相比呢 是否添加 <S>可以起到同样效果?
Random normal google transform效果不错的 特别是dev loss相对较低 但是随机性起到了更大的作用 也就是说相同配置 不同运行 结果可能会diff很大 特别是由于动态learning rate调整的不确定性造成 最终结果不确定性很大
最终目前跑出来的最佳结果 对应
使用random uniform embedding, char dim 8, glove only vocab, not finetune word embedding, char use share dropuout using cudnn gru with outpout max pooling, using all trainging data for train,dev data for evaluate, buckets [400] batchs size[64,32]
75k step EM 70.96 F1 79.86

 浙公网安备 33010602011771号
浙公网安备 33010602011771号