CNN初步-2
Pooling
为了解决convolved之后输出维度太大的问题
在convolved的特征基础上采用的不是相交的区域处理

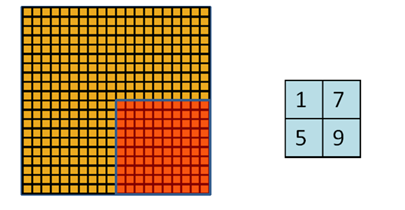
http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/
这里有一个cnn较好的介绍
Pooling also reduces the output dimensionality but (hopefully) keeps the most salient information.
By performing the max operation you are keeping information about whether or not the feature appeared in the sentence, but you are losing information about where exactly it appeared.
You are losing global information about locality (where in a sentence something happens), but you are keeping local information captured by your filters, like "not amazing" being very different from "amazing not".
局部信息能够学到 "not amaziing" "amzaing not"这样 bag of word 不行的顺序信息(知道他们是不一样的),然后max pooling仍然能够保留这一信息 只是丢失了这个信息的具体位置
There are two aspects of this computation worth paying attention to: Location Invarianceand Compositionality. Let's say you want to classify whether or not there's an elephant in an image. Because you are sliding your filters over the whole image you don't really care wherethe elephant occurs. In practice, pooling also gives you invariance to translation, rotation and scaling, but more on that later. The second key aspect is (local) compositionality. Each filter composes a local patch of lower-level features into higher-level representation. That's why CNNs are so powerful in Computer Vision. It makes intuitive sense that you build edges from pixels, shapes from edges, and more complex objects from shapes.
来自 <http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/>
关于conv和pooling可选的参数 PADDING

You can see how wide convolution is useful, or even necessary, when you have a large filter relative to the input size. In the above, the narrow convolution yields an output of size
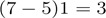
, and a wide convolution an output of size
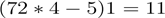
. More generally, the formula for the output size is
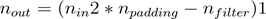
.
来自 <http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/>
narrow对应 tensorflow提供的VALID padding
wide对应tensorflow提供其中特定一种 SAME padding(zero padding)通过补齐0 来保持输出不变 下面有详细解释
STRIDE
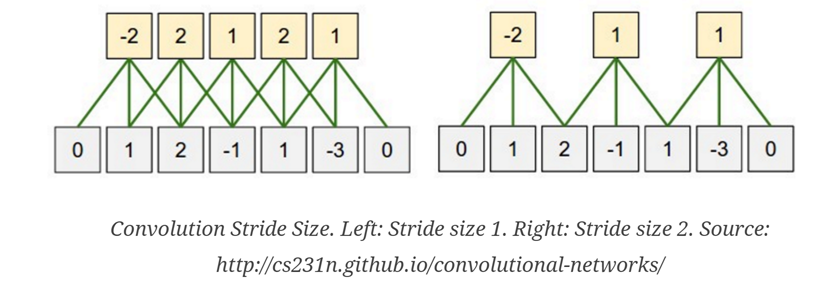
这个比较好理解 每次移动的距离,对应pooling, filter size是多少 一般 stride是多少
down vote
| tensorflow里面提供SAME,VALID两种padding的选择 关于padding, conv和pool用的padding都是同一个padding算法
The TensorFlow Convolution example gives an overview about the difference between SAME and VALID :
And
|
示例
In [2]:
import
tensorflow
as
tf
x = tf.constant([[1., 2., 3.],
[4., 5., 6.]])
x = tf.reshape(x, [1, 2, 3, 1]) # give a shape accepted by tf.nn.max_pool
valid_pad = tf.nn.max_pool(x, [1, 2, 2, 1], [1, 2, 2, 1], padding='VALID')
same_pad = tf.nn.max_pool(x, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
print valid_pad.get_shape() == [1, 1, 1, 1] # valid_pad is [5.]
print same_pad.get_shape() == [1, 1, 2, 1] # same_pad is [5., 6.]
sess = tf.InteractiveSession()
sess.run(tf.initialize_all_variables())
print valid_pad.eval()
print same_pad.eval()
True
True
[[[[ 5.]]]]
[[[[ 5.]
[ 6.]]]]
In [7]:
x = tf.constant([[1., 2., 3., 4.],
[4., 5., 6., 7.],
[8., 9., 10., 11.],
[12.,13.,14.,15.]])
x = tf.reshape(x, [1, 4, 4, 1]) # give a shape accepted by tf.nn.max_pool
valid_pad = tf.nn.max_pool(x, [1, 2, 2, 1], [1, 2, 2, 1], padding='VALID')
same_pad = tf.nn.max_pool(x, [1, 2, 2, 1], [1, 2, 2, 1], padding='SAME')
print valid_pad.get_shape() # valid_pad is [5.]
print same_pad.get_shape() # same_pad is [5., 6.]
#ess = tf.InteractiveSession()
#ess.run(tf.initialize_all_variables())
print valid_pad.eval()
print same_pad.eval()
(1, 2, 2, 1)
(1, 2, 2, 1)
[[[[ 5.]
[ 7.]]
[[ 13.]
[ 15.]]]]
[[[[ 5.]
[ 7.]]
[[ 13.]
[ 15.]]]]
In [8]:
x = tf.constant([[1., 2., 3., 4.],
[4., 5., 6., 7.],
[8., 9., 10., 11.],
[12.,13.,14.,15.]])
x = tf.reshape(x, [1, 4, 4, 1]) # give a shape accepted by tf.nn.max_pool
W = tf.constant([[1., 0.],
[0., 1.]])
W = tf.reshape(W, [2, 2, 1, 1])
valid_pad = tf.nn.conv2d(x, W, strides = [1, 1, 1, 1], padding='VALID')
same_pad = tf.nn.conv2d(x, W, strides = [1, 1, 1, 1],padding='SAME')
print valid_pad.get_shape()
print same_pad.get_shape()
#ess = tf.InteractiveSession()
#ess.run(tf.initialize_all_variables())
print valid_pad.eval()
print same_pad.eval()
(1, 3, 3, 1)
(1, 4, 4, 1)
[[[[ 6.]
[ 8.]
[ 10.]]
[[ 13.]
[ 15.]
[ 17.]]
[[ 21.]
[ 23.]
[ 25.]]]]
[[[[ 6.]
[ 8.]
[ 10.]
[ 4.]]
[[ 13.]
[ 15.]
[ 17.]
[ 7.]]
[[ 21.]
[ 23.]
[ 25.]
[ 11.]]
[[ 12.]
[ 13.]
[ 14.]
[ 15.]]]]
In [9]:
x = tf.constant([[1., 2., 3.],
[4., 5., 6.]])
x = tf.reshape(x, [1, 2, 3, 1]) # give a shape accepted by tf.nn.max_pool
W = tf.constant([[1., 0.],
[0., 1.]])
W = tf.reshape(W, [2, 2, 1, 1])
valid_pad = tf.nn.conv2d(x, W, strides = [1, 1, 1, 1], padding='VALID')
same_pad = tf.nn.conv2d(x, W, strides = [1, 1, 1, 1],padding='SAME')
print valid_pad.get_shape()
print same_pad.get_shape()
#ess = tf.InteractiveSession()
#ess.run(tf.initialize_all_variables())
print valid_pad.eval()
print same_pad.eval()
(1, 1, 2, 1)
(1, 2, 3, 1)
[[[[ 6.]
[ 8.]]]]
[[[[ 6.]
[ 8.]
[ 3.]]
[[ 4.]
[ 5.]
[ 6.]]]]
In [ ]:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号