
C++实现的huffman与canonical huffman的压缩解压缩系统,支持基于单词的压缩解压缩
我把它放在了google code上
11.30
完成了英文文本基于分词的范式huffman完全无损的压缩解压缩。
对于24M的一个测试英文文本用普通的基于字节的压缩可压缩到13M,
而基于分词的压缩当前测试是9.5M,gzip默认选项压缩到7.6M
如果改进分词或者是对于更大的英文文本(这个测试文本中符号比较多稍微影响效果)
基于词的压缩能取得更好的效果。
下一步,改进分词,改进速度,尝试中文分词压缩,或者混合文本...
current now is golden-huffman1.1
加入了基于查找表的快速范式解码。加入BitBuffer支持bit读操作。加入编码终止符号,方便算法实现。
golden-huffman - Project Hosting on Google Code
都是基于字节进行编码的,也就是编码的symbol不超过256个。
开启DEBUG2的话会打印huffman编码过程生成的二叉树图像。(利用boost.python,graphviz)
//普通的huffman 压缩解压缩
Compressor<> comperssor(infileName, outfileName);
compressor.compress()
Deompressor<> decomperssor(infileName, outfileName);
decompressor.decompress()
//范式huffman 压缩解压缩
Compressor<CanonicalHuffEncoder> comperssor(infileName, outfileName);
compressor.compress()
Deompressor<CanonicalHuffDecoder> decomperssor(infileName, outfileName);
decompressor.decompress()
实验结果,目前速度还可以,GCC的O3优化好强啊,如果是用最新的GCC可能性能还会提升:)
恩,我还和网上现有的huffman实现对比了一下在,
http://michael.dipperstein.com/huffman/
有一个C语言版本的也是基于字符编码的huffman,范式huffman的实现。
对于24M的文本我的程序压缩解压缩都有比它快1S左右:) C++基本上不会比C慢多少的,只要注意耗时间的地方如大循环,避免虚汗数调用等等即可。
allen:~/study/data_structure/golden-huffman/build/bin$ time ./utest
[==========] Running 2 tests from 1 test case.
[----------] Global test environment set-up.
[----------] 2 tests from canonical_huff_char
[ RUN ] canonical_huff_char.compress_perf
[ OK ] canonical_huff_char.compress_perf (1037 ms)
[ RUN ] canonical_huff_char.decomress_perf
[ OK ] canonical_huff_char.decomress_perf (912 ms)
[----------] 2 tests from canonical_huff_char (1950 ms total)
[----------] Global test environment tear-down
[==========] 2 tests from 1 test case ran. (1951 ms total)
[ PASSED ] 2 tests.
real 0m1.975s
user 0m1.280s
sys 0m0.676s
allen:~/study/data_structure/golden-huffman/build/bin$ du -h big.log
24M big.log
allen:~/study/data_structure/golden-huffman/build/bin$ du -h big.log.crs2
13M big.log.crs2
allen:~/study/data_structure/golden-huffman/build/bin$ du -h big.log.crs2.de
24M big.log.crs2.de
allen:~/study/data_structure/golden-huffman/build/bin$ diff big.log big.log.crs2.de
allen:~/study/data_structure/golden-huffman/build/bin$ time gzip big.log
real 0m3.607s
user 0m3.348s
sys 0m0.136s
allen:~/study/data_structure/golden-huffman/build/bin$ du -h big.log.gz
7.9M big.log.gz
allen:~/study/data_structure/golden-huffman/build/bin$ time gzip -d big.log.gz
real 0m0.742s
user 0m0.228s
sys 0m0.488s
simple.log
I love nba and cba
and ...
simple.log 普通huffman 编码图
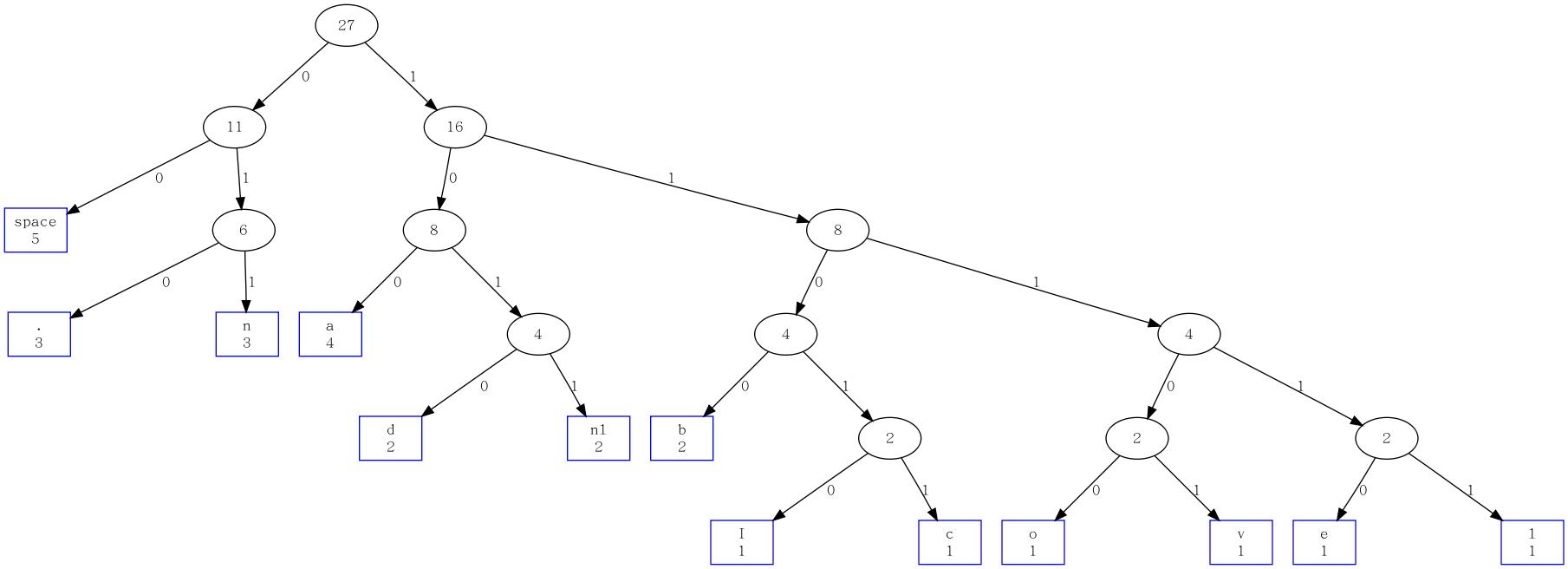
普通 huffman 编码
The input file is simple.log
The total bytes num is 27
The total number of different characters in the file is 13
The average encoding length per character is 3.48148
So not consider the header the approximate compressing ration should be 0.435185
The encoding map:
Character Times Frequence EncodeLength Encode
\n 2 0.0741 4 1011
space 5 0.185 2 00
. 3 0.111 3 010
I 1 0.037 5 11010
a 4 0.148 3 100
b 2 0.0741 4 1100
c 1 0.037 5 11011
d 2 0.0741 4 1010
e 1 0.037 5 11110
l 1 0.037 5 11111
n 3 0.111 3 011
o 1 0.037 5 11100
v 1 0.037 5 11101
范式huffman 编码
The canonical huffman encoding map:
Character Times EncodeLength encode_map_[i] Encode
space 5 2 3 11
. 3 3 3 011
a 4 3 4 100
n 3 3 5 101
\n 2 4 3 0011
b 2 4 4 0100
d 2 4 5 0101
I 1 5 0 00000
c 1 5 1 00001
e 1 5 2 00010
l 1 5 3 00011
o 1 5 4 00100
v 1 5 5 00101
TODO
1.下一步参考论文优化 范式 huffman解码过程,还有很大优化空间。
2. 在现有系统尽量少的改动情况下加入基于字典,单词编码的普通和范式huffman方法。
3.当前的范式huffman由于编码表小(256)没有过多考虑内存占用,基于单词的编码要
采用MG书上的算法。

