
Webpack v4编译速度优化实践
当我们的应用还处于小规模的时候,或者只是写个Demo做个技术预研,我们可能不会在乎Webpack的编译速度,无论使用3.X还是4.X版本,它都足够快,或者说至少没让你等得不耐烦。但随着业务的增多,嗖嗖嗖一下项目就有上百个组件甚至几万行代码,这也是件很容易发生的事情。这时候在独立编前端模块的生产包时,或者在CI工具中编整个项目的生产包时,如果Webpackp配置没经过优化,那编译速度都会慢得一塌糊涂。在日常开发中,如果编译慢,在修改代码以后也要过很久才能看到通过HMR带来的变化。编译耗时长短带来的体验是迥然不同的。从开发期间的初次启动的效率、代码修改到呈现的效率、做临时部署时的效率以及CI的整体效率等方面出发,我们都有必要去加快前端项目的编译速度,这是对前端开发工作效率上的提升。
本文基于笔者在月初对项目编译速度的优化实践,从工具链配置和使用的角度(轮子是现成的)介绍下基于Webpack的项目可做编译速度优化的地方。文中所有的可配置项和工具都由Webpack平台或者社区的工具提供,笔者对它们API的使用上不会做太多讲解,需要的同学可以直接翻看对应的文档。笔者的Webpack版本为4.29.6,后文中的内容都基于这个版本。
一、已存在的针对编译速度的优化
笔者这套Webpack架子是eject CRA种子脚手架并且改进而来的,基于Webpack4.x,选择CRA的原因在于其本身在对不同资源模块的处理上已是最佳实践的方案,在这方面基本上无需改动什么。对于小微项目来说CRA可以直接零配置使用,无需eject出工程化配置,但在编译速度优化上较弱,而且在项目规模扩大后,劣势非常明显,所以我们需要对其工程化流程进行优化。
除了code split分chunk、common chunk、include、exclude等等外,其原有的针对编译速度的优化配置主要还有这三处:
1. 通过terser-webpack-plugin的parallel和cache配置来并行处理并缓存之前的编译结果。terser-webpack-plugin是之前UglifyPlugin的一个替代品,因为UglifyPlugin已经没有继续维护了,从Webpack4.x起,已经推荐使用terser-webpack-plugin来进行代码压缩、混淆,以及Dead Code Elimination以实现Tree Shaking。对于parallel从整个设置的名称大家就会知道它有什么用,没错,就是并行,而cache也就是缓存该插件的处理结果,在下一次的编译中对于内容未改变的文件可以直接复用上一次编译的结果。
2. 通过babel-loader的cache配置来缓存babel的编译结果。
3. 通过IgnorePlugin设置对moment的整个locale本地化文件夹导入的正则匹配,来防止将所有的本地化文件进行打包。如果你确实需要某国语言,仅手动导入那国的语言包即可。
在项目逐渐变大的过程中,生产包的编译时间也从十几秒增长到了一分多钟,这是让人受不了的,这就迫使着笔者必须进行额外的优化以加快编译速度,为编包节省时间。
下面的段落就讲解下笔者做的几个额外优化。总体思路就是:开多线程,尽可能地做增量编译,通过加缓存来用空间换时间。
二、多线程(多进程模拟)支持
从上个段落的terser-webpack-plugin的parallel设置中,我们可以得到这个启发:启用多进程来模拟多线程(因为一个Node.js进程是单线程的),并行处理资源的编译。于是笔者引入了HappyPack,笔者之前的那套老架子也用了它,但之前没写东西来介绍那套架子,这里就一并说了。关于HappyPack,经常玩Webpack的同学应该不会陌生,网上也有一些关于其实现原理与使用的介绍文章,也写得很不错。HappyPack的工作原理大致就是在Webpack和Loader之间多加了一层,改成了Webpack并不是直接去和某个Loader进行工作,而是Webpack test到了需要编译的某个类型的资源模块后,将该资源的处理任务交给了HappyPack,由HappyPack在内部线程池中进行任务调度,分配一个线程调用处理该类型资源的Loader来处理这个资源,完成后上报处理结果,最后HappyPack把处理结果返回给Webpack,最后由Webpack输出到目的路径。通过这一系列操作,将原本都在一个Node.js线程内的工作,分配到了不同的线程(进程)中并行处理。
使用方法如下:
首先引入HappyPack并创建线程池:
const HappyPack = require('happypack');
const happyThreadPool = HappyPack.ThreadPool({size: require('os').cpus().length - 1});
替换之前的Loader为HappyPack的插件:
{ test: /\.(js|mjs|jsx|ts|tsx)$/, include: paths.appSrc, use: ['happypack/loader?id=babel-application-js'], },
将原Loader中的配置,移动到对应插件中:
new HappyPack({ id: 'babel-application-js', threadPool: happyThreadPool, verbose: true, loaders: [ { loader: require.resolve('babel-loader'), options: { ...省略 }, }, ], }),
大致使用方式如上所示,HappyPack的配置讲解文章有很多,不会配的同学可以自己搜索,本文这里只是顺带说说而已。
HappyPack老早也没有维护了,它对url-loader的处理是有问题的,会导致经过url-loader处理的图片都无效,笔者之前也去提过一个Issue,有别的开发者也发现过这个问题。总之,用的时候一定要测试一下。
对于多线程的优势,我们举个例子:
比如我们有四个任务,命名为A、B、C、D。
任务A:耗时5秒
任务B:耗时7秒
任务C:耗时4秒
任务D:耗时6秒
单线程串行处理的总耗时大约在22秒:

改成多线程并行处理后,总耗时大约在7秒,也就是那个最耗时的任务B的执行时长:

仅仅通过配置多线程处理我们就能得到大幅的编译速度提升。
写到这里,大家是不是觉得编译速度优化就可以到此结束了?哈哈,当然不是,上面这个例子在实际的项目中根本不具有广泛的代表性,笔者项目的实际情况是这样的:
依然是四个任务,命名为A、B、C、D。
任务A:耗时5秒
任务B:耗时60秒
任务C:耗时4秒
任务D:耗时6秒
PS:任务B通常是压缩、混淆、语言转换等loader或插件的耗时。
单线程串行处理的总耗时大约在75秒
改成多线程并行处理后,总耗时大约在60秒:
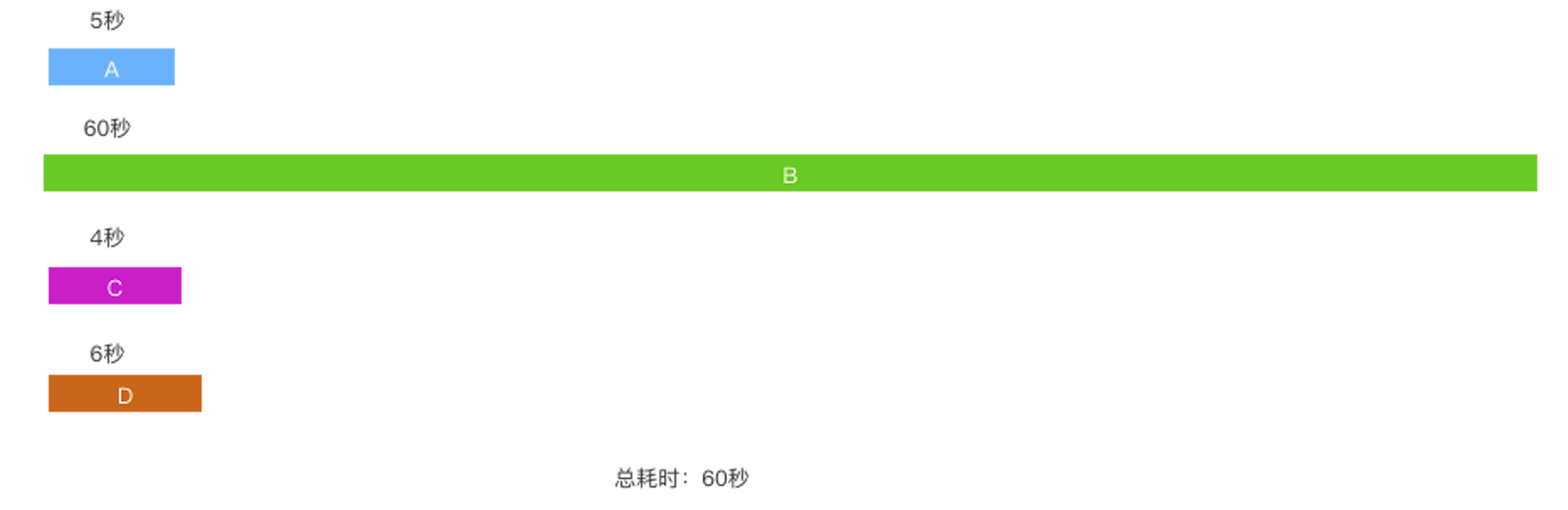
从75秒优化到60秒,确实有一定速度上的提升,但是因为任务B的耗时太长了,导致整个项目的编译速度并没有发生本质上的变化。事实上笔者之前那套Webpack3.X的架子就是因为这个问题导致编译速度慢,在大多数项目中也都是这个情况,处理某种资源类型的Loader的执行时间非常长,远远超过了其他Loader的执行时间,它成为了一个速度瓶颈的,在真实项目中最明显的就是项目规模起来以后,对JS的处理上,先babel再terser,非常慢。所以,只靠引入多线程编译就想解决规模化项目在生产环境下编译速度慢的问题是不现实的。

那我们还有什么办法吗?当然有,我们还是可以从TerserPlugin得到灵感,那就是依靠缓存:在下一次的编译中能够复用上一次的结果而不执行编译永远是最快的。
至少存在有这三种方式,可以让我们在执行构建时不进行某些文件的编译,从最本质上提升前端项目整体的构建速度:
1. 类似于terser-webpack-plugin的cache那种方式,这个插件的cache默认生成在node_modules/.cache/terser-plugin文件下,通过SHA或者base64编码之前的文件处理结果,并保存文件映射关系,方便下一次处理文件时可以查看之前同文件(同内容)是否有可用缓存。其他Webpack平台的工具也有类似功能,但缓存方式不一定相同。
2. 通过externals配置在编译的时候直接忽略掉某些稳定的库的依赖,不对它们进行编译,而是在运行的时候,通过<script>标签直接从CDN服务器下载这些库的生产环境文件。
3. 将某些稳定的库文件编译以后保存起来,每次编译的时候直接跳过它们,但在最终编译后的代码中能够引用到它们,这就是Webpack DLLPlugin所做的工作,DLL借鉴至Windows动态链接库的概念。
后面的段落将针对这几种方式做讲解。
三、Loader的Cache
除了段落一中提到的terser-webpack-plugin和babel-loader支持cache外,Webpack还直接另外提供了一种可以用来缓存前序Loader处理结果的Loader,它就是cache-loader。通常我们可以将耗时的Loader都通过cache-laoder来缓存编译结果。比如我们打生产环境的包,对于Less文件的缓存你可以这样使用它:
{ test: /\.less$/, use: [ { loader: MiniCssExtractPlugin.loader, options: { ...省略 }, }, { loader: 'cache-loader', options: { cacheDirectory: paths.appPackCacheCSS, } }, { loader: require.resolve('css-loader'), options: { ...省略 }, }, { loader: require.resolve('postcss-loader'), options: { ...省略 } } ] }
Loader的执行顺序是从下至上,因此通过上述配置,我们可以通过cache-laoder缓存postcss-loader和css-loader的编译结果。
但我们不能用cache-loader去缓存mini-css-extract-plugin的结果,因为它的作用是要从前序Loader编译成的含有样式字符串的JS文件中把样式字符串单独抽出来打成独立的CSS文件,而缓存这些独立CSS文件并不是cache-loader的工作。
但如果是要缓存开发环境的Less编译结果,cache-loader可以缓存style-loader的结果,因为style-loader并没有从JS文件中单独抽出样式代码,只是在编译后的代码中添加了一些额外代码,让编译后的代码在运行时,能够创建包含样式的<style>标签并放入<head>标签内,这样的性能不是太好,所以基本上只有开发环境采用这种方式。
在对样式文件配置cache-loader的时候,一定要记住上述这两点,要不然会出现样式无法正确编译的问题。
除了对样式文件的编译结果进行缓存外,对其他类型的文件(除了会打包成独立的文件外)的编译结果进行缓存也是可以的。比如url-laoder,只要大小没有达到limitation的图片都会被打成base64,大于limitation的文件会打成单独的图片类文件,就不能被cache-loader缓存了,如果遇到了这种情况,资源请求会404,这是在使用cache-loader时需要注意的。
当然,通过使用缓存能得到显著编译速度提升的,依旧是那些耗时的Loader,如果对某些类型的文件编译并不耗时,或者说文件本身数量太少,都可以先不必做缓存,因为即便做了缓存,编译速度的提升也不明显。
最后笔者将所有Loader和Plugin的cache默认目录从node_modules/.cache/移到了项目根目录的build_pack_cache/目录(生产环境)和dev_pack_cache目录(开发环境),通过NODE_ENV自动区分。这么做是因为笔者目前项目的CI工程每次会删除之前的node_modules文件夹,并从node_modules.tar.gz解压一个新的node_modules文件夹,所以将缓存放在node_modules/.cache/目录里面会无效,CI的这套逻辑对于前段项目来说是比较坑的,笔者也不想去动CI的代码,这不是我维护的,是DevOps侧在整体负责。经过过这个改动后,对cache文件的管理更直观一些,也能避免node_modules的体积一直增大的问题。如果想清除缓存,直接删掉对应目录即可。当然了,这两个目录是不需要被Git跟踪的,所以需要在.gitignore中添加上。CI环境中如果没有对应的缓存目录,相关Loader会自动创建。这样做还考虑到这个原因:因为开发环境和生产环境编译出的资源是不同的,在开发环境下对资源的编译往往都没有做压缩和混淆处理等,因此即使某个源文件的源码没变,其在开发环境下和生产环境下的缓存也是不能通用的,而且还会相互覆盖。所以为了有效地缓存不同环境下的编译结果,是有必要区分开不同编译环境下的缓存目录的。
除了cache-loader外,还有hard-source-webpack-plugin插件也是不错的,不仅能缓存编译后的静态资源(loader的输出结果),编译过程中产生的一些中间数据:模块、模块关系、模块Resolve结果、Chunks、Assets等,这些都有助于加快下一次增量编译的速度。后面有时间的话,笔者会试试这个插件,做个对比。
四、外部扩展externals
按照Webpack官方的说法:我们的项目如果想用一个库,但我们又不想Webpack对它进行编译(因为它的源码很可能已是经过编译和优化的生产包,可以直接使用)。并且我们可能通过window全局方式来访问它,或者通过各种模块化的方式来访问它,那么我们就可以把它配置进extenals里。
比如我要使用jquery可以这样配置:
externals: { jquery: 'jQuery' }
我就可以这样使用了,就像我们直接引入一个在node_modules中的包一样:
import $ from 'jquery';
$('.div').hide();
这样做能有效的前提就是我们在HTML文件中在上述代码执行以前就已经通过了<script>标签从CDN下载了我们需要的依赖库了,externals配置会自动在承载我们应用的html文件中加入:
<script src="https://code.jquery.com/jquery-1.1.14.js">
externals还支持其他灵活的配置语法,比如我只想访问库中的某些方法,我们甚至可以把这些方法附加到window对象上:
externals : { subtract : { root: ["math", "subtract"] } }
我就可以通过 window.math.subtract 来访问subtract方法了。
对于其他配置方式如果有兴趣的话可以自行查看文档。
但是,笔者的项目并没有这么做,因为在它最终交付给客户后,应该是处于一个内网环境(或者一个被防火墙严重限制的环境)中,极大可能无法访问任何互联网资源,用户也不会为我们产品专门搭建一个内网CDN服务器。因此通过<script>脚本请求CDN资源的方式将失效,前置依赖无法正常下载就会导致整个应用无法正确加载。
五、DllPlugin
在上个段落中的结尾处,提到了笔者的项目在交付用户后会面临的网络困境,所以笔者必须选择另外一个方式来实现类似于externals配置能够提供的功能。那就是Webpack DLLPlugin以及它的好搭档DLLReferencePlugin。笔者有关DLLPlugin的使用都是在构建生产包的时候使用。打包出来的DLL文件相当于我们项目的工程基础包。
要使用DLLPlugiin,我们需要单独开一个webpack配置,暂且将其命名为webpack.dll.config.js,以便和主Webpack的配置文件webpack.config.js进行区分。内容如下:
'use strict';
process.env.NODE_ENV = 'production'; const webpack = require('webpack'); const path = require('path'); const {dll} = require('./dll'); const DllPlugin = require('webpack/lib/DllPlugin'); const TerserPlugin = require('terser-webpack-plugin'); const getClientEnvironment = require('./env'); const paths = require('./paths'); const shouldUseSourceMap = process.env.GENERATE_SOURCEMAP !== 'false'; module.exports = function (webpackEnv = 'production') { const isEnvDevelopment = webpackEnv === 'development'; const isEnvProduction = webpackEnv === 'production'; const publicPath = isEnvProduction ? paths.servedPath : isEnvDevelopment && '/'; const publicUrl = isEnvProduction ? publicPath.slice(0, -1) : isEnvDevelopment && ''; const env = getClientEnvironment(publicUrl); return { mode: isEnvProduction ? 'production' : isEnvDevelopment && 'development', devtool: isEnvProduction ? 'source-map' : isEnvDevelopment && 'cheap-module-source-map', entry: dll, output: { path: isEnvProduction ? paths.appBuildDll : undefined, filename: '[name].dll.js', library: '[name]_dll_[hash]' }, optimization: { minimize: isEnvProduction, minimizer: [ ...省略 ] }, plugins: [ new webpack.DefinePlugin(env.stringified), new DllPlugin({ context: path.resolve(__dirname), path: path.resolve(paths.appBuildDll, '[name].manifest.json'), name: '[name]_dll_[hash]', }), ], }; };
为了方便DLL的管理,我们还单独开了个dll.js文件来管理webpack.dll.config.js的入口entry,我们把所有需要DLLPlugin处理的库都记录在这个文件中:
const dll = { core: [ 'react','react-router-dom', 'prop-types', ... ], tool: [ 'js-cookie', 'crypto-js/md5', 'ramda/src/curry', 'ramda/src/equals', ], polyfill: [ 'whatwg-fetch', 'ric-shim' ], widget: [ 'cecharts', ], }; module.exports = { dll, dllNames: Object.keys(dll), };
对于要把哪些库放入DLL中,请根据自己项目的情况来定,对于一些特别大的库,又没法做模块分割和不支持Tree Shaking的,比如Echarts,建议先去官网按项目所需功能定制一套,不要直接使用整个Echarts库,否则会白白消耗许多的下载时间和流量,JS预处理的时间也会增长,减弱首屏性能。
另外需要注意一点的就是,进DLL的库,不要有重复的依赖。比如core这个DLL里面的,已经有react了,就不能再出现另外一个会依赖react的库,否则最后生成的core.dll.js会含有两个react库,在启动react应用的时候会报错。
然后我们在webpack.config.js的plugins配置中加入DLLReferencePlguin来对DLLPlugin处理的库进行映射,好让编译后的代码能够从window对象中找到它们所依赖的库:
{ ...省略 plugins: [ ...省略 // 这里的...用于延展开数组,因为我们的DLL有多个,每个单独的DLL输出都需要有一个DLLReferencePlguin与之对应,去获取DLLPlugin输出的manifest.json库映射文件。
// dev环境下暂不采用DLLPlugin优化。 ...(isEnvProduction ? dllNames.map(dllName => new DllReferencePlugin({ context: path.resolve(__dirname), manifest: path.resolve(__dirname, '..', `build/static/dll/${dllName}.manifest.json`) })) : [] ), ...省略 ] ... }
我们还需要在承载我们应用的index.html模板中加入<script>,从webpack.dll.config.js里配置的output输出文件夹中前置引用这些DLL库。对于这个工作DLLPlguin和它的搭档不会帮我们做这件事情,而已有的html-webpack-plugin也不能帮助我们去做这件事情,因为我们没法通过它往index.html模板加入特定内容,但它有个增强版的兄弟script-ext-html-webpack-plugin可以帮我们做这件事情,笔者之前也用过这个插件内联JS到index.html中。但笔者懒得再往node_modules中加依赖包了,另辟了一个蹊径:
CRA这套架子已经使用了DefinePlugin来在编译时创建全局变量,最常用的就是创建process环境变量,让我们的代码可以分辨是开发还是生产环境,既然已有这样的设计,何不继续使用,让DLLPlugn编译的独立JS文件名暴露在某个全局变量下,并在index.html模板中循环这个变量数组,循环创建<script>标签不就行了,html-webpack-plugin自带ejs模板,我们循环语句符合ejs模板语法即可(说明:因为我这里基本DLL是不会改变的,所以也不需要输出带hash的文件名,如果你需要的,可以用add-asset-html-webpack-plugin插件来给html模板注入DLL脚本标签,而不是使用写死的DLL名)。在上面提到的dll.js文件中最后导出的 dllNames 就是这个数组。
然后我们按照ejs模板语法改造一下index.html:
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title></title> <% if (process.env.NODE_ENV === "production") { %> <% process.env.DLL_NAMES.forEach(function (dllName){ %> <script src="/static/dll/<%= dllName %>.dll.js"></script> <% }) %> <% } %> </head> <body> <noscript>Please allow your browser to run JavaScript scripts.</noscript> <div id="root"></div> </body> </html>
最后我们改造一下build.js脚本,加入打包DLL的步骤:
function buildDll (previousFileSizes){ let allDllExisted = dllNames.every(dllName => fs.existsSync(path.resolve(paths.appBuildDll, `${dllName}.dll.js`)) && fs.existsSync(path.resolve(paths.appBuildDll, `${dllName}.manifest.json`)) ); if (allDllExisted){ console.log(chalk.cyan('Dll is already existed, will run production build directly...\n')); return Promise.resolve(); } else { console.log(chalk.cyan('Dll missing or incomplete, first starts compiling dll...\n')); const dllCompiler = webpack(dllConfig); return new Promise((resolve, reject) => { dllCompiler.run((err, stats) => { ...省略 }) }); } }
checkBrowsers(paths.appPath, isInteractive) .then(() => { // Start dll webpack build. return buildDll(); }) .then(() => { // First, read the current file sizes in build directory. // This lets us display how much they changed later. return measureFileSizesBeforeBuild(paths.appBuild); }) .then(previousFileSizes => { // Remove folders contains hash files, but leave static/dll folder. fs.emptyDirSync(paths.appBuildCSS); fs.emptyDirSync(paths.appBuildJS); fs.emptyDirSync(paths.appBuildMedia); // Merge with the public folder copyPublicFolder(); // Start the primary webpack build return build(previousFileSizes); }) .then(({stats, previousFileSizes, warnings}) => { ... 省略 }) ... 省略
大致逻辑就是如果xxx.dll.js文件存在且对应的xxx.manifest.json也存在,那么就不重新编译DLL,如果缺失任意一个,就重新编译。DLL的编译过程走完后再进行主包的编译。由于我们将DLLPlugin编译出的文件也放入build文件夹中,所以之前每次开始编译主包都需要清空整个build文件夹的操作也修改为了仅仅清空除了放置有dll.js和manifest.json的目录。
如果我们的底层依赖库确实发生了变化,需要我们更新DLL,按照之前的检测逻辑,我们只需要删除整个某个dll.js文件即可,或者直接删除掉整个build文件夹。或者增加对webpack.dll.js配置文件进行去注释和压缩操作,再进行MD5检测即可,如果文件MD5值发生了变化,说明依赖的DLL发生了变化,那么就需要重新编译DLL了,并保存本次的MD5结果,用于下一次打包时的比较。
到此所有的有关DLL的配置就完成了,大功告成。
PS:如果说你的DLL配置里,出现有相同依赖项的包,需要再进行一层DLL打包,否则该包可能被构建多次,可能会造成报错(比如多个react,在运行的时候就会报错)。举个例子:假设有C包作为A包和B包共同的依赖项,那么最好就不要将C写进DLL了,在打包A和B的时候会自动包含进去,但依然有重复打包C的可能。此时建议将C包单独再做一次DLL,然后在打包A和B的时候通过Refence引用到C包,相当于在DLL这里,针对A、B、C三个包也进行了依赖分层,将C当做了DLL的DLL。
本段落开始时有提到过DLLPlugin的使用都是在生产环境下。因为开发环境下的打包情况很特殊而且复杂,这里简单讲一下:
在开发环境下整个应用是通过webpack-dev-server来打包并起一个Express服务来serve的。Express服务在内部挂载了webpack-dev-middleware作为中间件,webpack-dev-middleware可以实现serve由Webpack compiler编译出的所有资源、将所有的资源打入内存文件系统中的功能,并能结合dev-sever实现监听源文件改动并提供HRM。webpack-dev-server接收了一个Webpack compiler和一个有关HTTP配置的config作为实例化时的参数。这个compiler会在webpack-dev-middleware中执行,用监听方式启动compiler后,compiler的outputFileSystem会被webpack-dev-middleware替换成内存文件系统,其执行后打包出来的东西都没有实际落盘,而是存放在了这个内存文件系统中,而ouputFileSystem本身是在Node.js的fs模块基础上封装的。将编译结果存放进内存中是webpack-dev-middleware内部最奇妙的地方。事实上就算将文件资源落盘,也必须先把文件从磁盘读到内存中,再以流的形式返回给客户端,这样一来会多一个从磁盘中将文件读进内存的步骤,反而还没有直接操作内存快。内存文件系统在npm start命令起的进程被干掉后,就被回收了,下一次再起进程的时候,会创建一个全新的内存文件系统。
这里顺带再说下webppack-dev-middleware源码中的处理流程:
首先在执行wdm这个入口文件导出的方法中,通过setFs方法将原本的Node.js的fs给替换为memory-fs内存文件系统,所以下面提到的文件系统都是指这个内存文件系统。
按照Express的流程,所有请求都会依次进入Express挂载的中间件中,在webppack-dev-middle中间件中,会先通过getFilenameFromUrl方法根据传入的这次请求的url,compiler和webpack的publicPath等有关配置,确定一个filename的URI,这个URI最终会返回3种结果,这三种结果将走三种不同的处理流程:
结果1:一个布尔值false
结果2:一个HTTP API的请求路径
结果3:一个静态文件资源的请求路径
对结果1的处理:表示请求url带有hostname等特征,也就确定这个发给dev-server的请求并不是需要webpack-dev-middle处理的,将执行goNext(),根据是否是serverSideRender,在goNext方法中的处理过程会有所不同,但最终都会调用Express应用的next()进入下一个中间件。
对结果2的处理:通过文件系统的statSync方法会判断这个路径并不是一个文件资源的路径,再根据isDirectory方法判断它是否是一个目录的路径,如果是的话,再看看该目录下是否有一个index.html的文件,有就返回。在开发的时候我们在浏览器地址栏输入"localhost:3000"就是走的这个流程,会返回承载前端应用的那个入口index.html文件。
对结果3的处理:通过文件系统的statSync方法会判断出这个路径就是一个文件资源的路径,会通过文件系统的readFileSync方法从内存中读取到该文件内容,再拿到该资源对应的MIME类型,设置好response的header返回给浏览器,浏览器就能正确解析返回的文件资源流了。我们在开发环境下,所有对js、js.map、图片资源等除了index.html外的请求都是走的这个流程。
回到正题,从上面的描述可以看出由于开发环境打包的特殊性,在开发环境下将编译DLL的compiler的和主compiler结合起来还需要再深入了解下,因此怎么在开发环境使用DLLPlugin还需要等有时间的时候再研究下,大概率感觉是用不上,也不需要用。所以笔者只是在开发环境使用了多线程和各种缓存。由于在开发环境下不需要压缩也不需要混淆,编译的工作量少于生产环境,并且对所有资源的读写都是走内存的,因此速度很快,每次检测到源文件变动并进行重编译的过程也会很快。所以开发环境的编译速度在目前来看还可以接受,暂时不需要优化。
这里顺带说一句,笔者之前在看有关DLLPlugin的文档和文章时,也注意到了一个现象,就是很多人都说DLLPlugin过时了,而externals使用起来更方便,配置更简单,甚至在CRA、vue-cli这些最佳实践的脚手架中都已经没再继续使用DLLPlugin了,因为Webpack4.x的编译速度已经足够快了。这里笔者客观地说下自己的感受:我这个项目就是基于Webpack4.X的,项目规模变大以后,没有觉得4.X有多么地快。笔者的项目所属的产品在交付客户后也极大可能不能访问互联网,都是内网部署,客户群体又是B端的传统软件的客户群体,所以通过配置externals将资源请求导向CDN的方式对笔者的项目来说没有用,只能通过使用DLLPlugin提高生产包的编译速度。我想这也是为什么Webpack到了4.X版本依然没有去掉DLLPlugin的原因,因为不是所有的前端项目都一定是互联网web项目,都能访问互联网,都需要按照互联网web项目的方式去做,有些项目的部署环境只有内部局域网,也不可能就为了externals,因为在内网专门部署一个前端资源分发的server,多一个server多一个ip和端口占用,这点你很难给用户讲清楚的,他们大概率连互联网应用都不了解,大多数还停留在”web页面?我知道啊,html嘛,我也会的。“这个层面。当然,也可以不走CDN这个方式,直接把externals涉及到的库放到public目录下,但这个总觉得很奇葩,而且需要手动处理,有这时间还不如去配DLL,走自动化了。所以我的这个实践也证明了:不是所有的web应用都是互联网应用,在非互联网项目上,DLLPlugin是完全可以适用于生产的,并且可能是做为webpack体系下在某些项目情况下处理工程基础包(稳定的库)的优先(大胆点说,就是唯一)选择。
六、编译速度提升了多少?
笔者开发机是公司的2015 Macbook Pro 15' Haswell i7-4770HQ 4核8线程,单核基础频率2.2GHz。Node.js版本为10.15.3。所有测试都基于已对Echarts进行功能定制的前提下(移除不需要的功能带来的额外大小)。
1. 最原始的CRA脚手架编译笔者这个项目的速度。
初次编译,无任何CRA原始配置的缓存,这和最初在CI上进行编译的情况完全一样,每次差不多都是这个耗时。
因为CI的脚本原因,每次构建,node_moduels都要被删除掉,无法缓存任何之前的编译结果:

大概1分10多秒。CI上的话,大概会稍微快点,因为硬件性能好些。
改掉CI脚本,并将有关loader和plugin的缓存目录放到了node_modules外面,有缓存以后:

如果不定制Echarts的话,直接引入整个Echarts,在没缓存的时候大概会多5秒耗时。
2. 引入dll后。
初次打包,并且无任何DLL文件和CRA原始配置的缓存:

先编译DLL,再编译主包,整个过程耗时直接变成了57秒。
有DLL文件和缓存后:
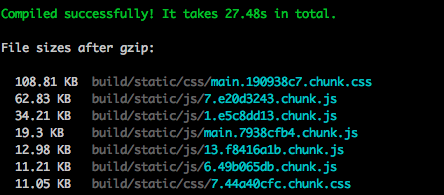
降到27秒多了。
3.最后我们把多线程和cache-loader上了:
无任何DLL文件、CRA原始配置的缓存以及cache-loader的缓存时:
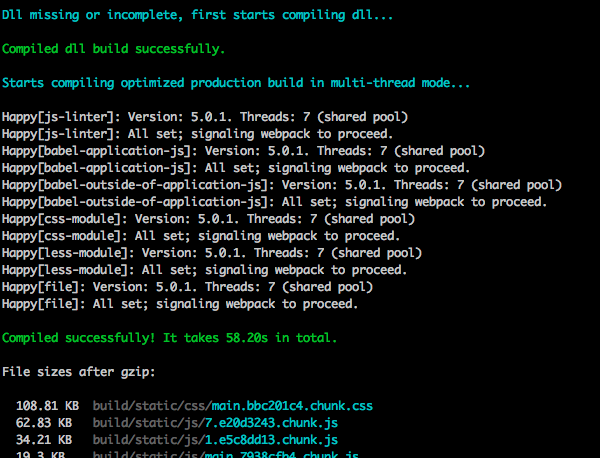
在首次无DLL文件和缓存的情况下,耗时大概在60秒左右。
有DLL文件和所有缓存后:

最终,耗时已经下降至17秒左右了。
编译速度受硬件性能、以及运行编译时的计算机CPU、内存、硬盘等资源使用率有着很大的关系,会有着正负几秒的差距。笔者后面在自己的2016 Macbook Pro 15' Skylake i7-6920HQ 单核基础频率2.9GHz(单核Boost 3.8GHz)运行编译时,耗时只有13秒多。同时在也同事的3.4GHz(i5 7500)的台式机上执行了一下,速度还会更快些,CPU的架构和制程都差不多,应该是频率高些,带来的性能提升,在同事机器上测了几次下来,平均耗时只要10秒多一点点。往后升级更高的Node.js版本也会有性能的提升。更强的硬件性能、内存资源、Node.js版本、硬盘速度会使编译的耗时进一步减小。
至此,相比最原始的啥优化也没有的1分10多秒耗时已经有本质上的提升了,优化后的编译耗时只有之前的零头那么多了。
这才是我们想要优化到的速度!
使用合理的工具并进行最优化的配置对工作效率的提升是很有帮助的,用空间换时间是最直接的方式。
Happiness in the form of faster webpack build times. -- HappyPack
七、总结
至此,我们已经将所有的底层依赖DLL化了,把几乎所有能缓存的东西都缓存了,并支持多线程(多进程模拟)编译。当项目稳定后,无论项目规模多大,小幅度的修改将始终保持在这个编译速度,耗时不会有太大的变化,可能后期模块数量增大很多倍以后,对比原始文件的哈希可能会多花一些时间。因为所有的源代码已被缓存,工程基础包已经DLL化,除初次编译是全量编译外,后续的编译仅仅需要增量编译那些有变化的源码而已。
如果后续组件随B端业务的完善可能达到几百个组件的规模时,会考虑将此单SPA项目改为微前端架构,因为不同的模块组可能会用不同的框架来做(看到时候的情况,多技术栈同时存在带来的问题也多),但每个子应用无论基于何种框架也还是可以基于本文的方法来优化编译速度。
据说在Webpack5.X带来了全新的编译性能体验,很期待使用它的时候。谈及到此,笔者只觉得有淡淡的忧伤,那就是前端技术、工具链、框架、开发理念这些的更新速度实在是太快了,前端的学习是永无止尽的,不可能学一套东西能用整个职业生涯,连HTML、CSS、JavaScript都是在不停地变的,注定不只挣扎于业务代码中,还会挣扎于各种工具、框架、轮子中。就拿Webpack这套构建平台来说,当Webpack5.X普及后,Webpack4.X这套优化可能也就过时了,整套工具链又需要重新学习,并用新的配置和优化选项来做工具链的构建。而且当后面非Node.js的编译工具普及后,我们可能连Webpack都会放弃了,迎接一种比Node.js运行更高效的语言来提高编译效率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号