2019-02-08 Python学习之Scrapy的简单了解
今天遇到的问题和昨天差不多,一个Scrapy装了好久,anaconda卸了又装,pycharm卸了又装,环境变量配置一堆,依赖包下载一堆。查了一堆资料总算是搞好了。
Scripy:
先放个框架结构图(来自嵩天老师mooc)
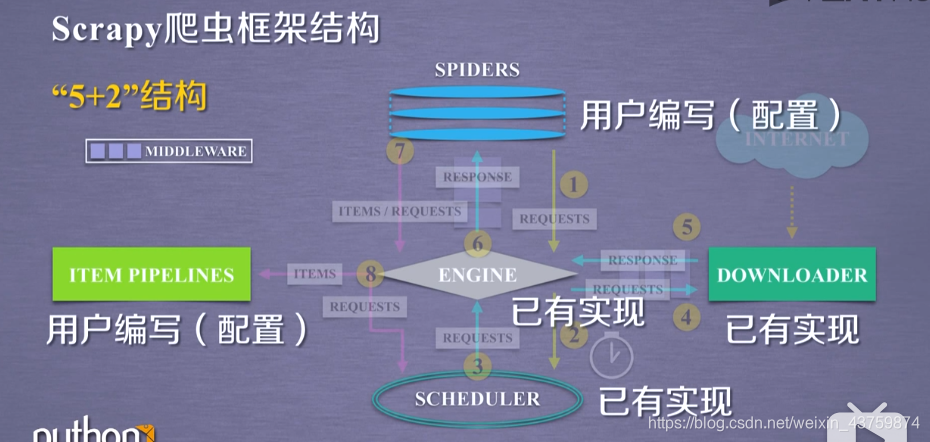
Scrapy 爬虫的使用步骤
- 创建一个工程和spider模板
- 编写spider
- 编写Item Pipeline
- 优化配置策略
两种风格的demospider写法:
class DemoSpider(scrapy.Spider):
name = 'demo'
#allowed_domains = ['python123.io']
start_urls = ['http://python123.io/ws/demo.html'] #启动时最开始的链接
def parse(self, response): #解析和操作的相关步骤
fname = response.url.split('/')[-1] #文件名叫demo.html(切片,得到最后一个)
with open(fname,'wb+') as f:
f.write(response.body)
self.log = ('saved file %s.'% fname)
class DemoSpider(scrapy.Spider):
name = "demo"
def start_requests(self):
urls = [
'http://python123.io/ws/demo.html'
]
for url in urls:
yield scrapy.Request(url=url,callback=self.parse)
def parse(self,response):
fname = response.url.split('/')[-1]
with open(fname,'wb') as f:
f.write(response.body)
self.log('Save file %s.' % fname)
几种类:
Request类
class scrapy.http.Request()
- Request对象生成一个HTTP请求
- 由Spider生成,由Downloader执行
属性和方法
.url 对应请求的url地址
.method 请求方法
.headers 字典类型风格的请求头
.body 请求内容主题
.meta 用户添加的扩展信息
.copy() 复制该响应
Response类
class scrapy.http.Request()
- Response对象表示一个http响应
- 由downloader生成,spider来处理
属性和方法
.urls Response对应的url地址
.status HTTP状态码
.headers Response对应的头部信息
.body Response对应的内容信息
.flags 一组标记
.request 产生Response类型对应的Request对象
.copy() 复制该响应
Item类
class scrapy.item.Item()
- Item对象表示一个从HTML页面中提取的信息内容
- 由Spider生成,由Item Pipeline进行处理
- Item类似字典类型,可以按照字典类型进行相关操作\
Scrapy爬虫提取信息的方法
BeautifulSoup
lxml
re
CSS selector
XPath selector

 浙公网安备 33010602011771号
浙公网安备 33010602011771号