

Hive优化
一、join优化
1. 使用相同的连接键
当对3个或者更多个表进行join连接时,如果每个on子句都使用相同的连接键的话,那么只会产生一个MapReduce job。
2. 尽量尽早地过滤数据
减少每个阶段的数据量,对于分区表要加分区,同时只选择需要使用到的字段。
3. 尽量原子化操作
尽量避免一个SQL包含复杂逻辑,可以使用中间表来完成复杂的逻辑。
二、小文件优化
1.小文件过多产生的影响
首先对底层存储HDFS来说,HDFS本身就不适合存储大量小文件,小文件过多会导致namenode元数据特别大, 占用太多内存,严重影响HDFS的性能
对 Hive 来说,在进行查询时,每个小文件都会当成一个块,启动一个Map任务来完成,而一个Map任务启动和初始化的时间远远大于逻辑处理的时间,就会造成很大的资源浪费。而且,同时可执行的Map数量是受限的
2.怎么解决小文件过多
1)使用 hive 自带的 concatenate 命令,自动合并小文件
#对于非分区表
alter table A concatenate;
#对于分区表
alter table B partition(day=20201224) concatenate;2)调整参数减少Map数量
#执行Map前进行小文件合并
#CombineHiveInputFormat底层是 Hadoop的 CombineFileInputFormat 方法
#此方法是在mapper中将多个文件合成一个split作为输入
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; -- 默认
#每个Map最大输入大小(这个值决定了合并后文件的数量)
set mapred.max.split.size=256000000; -- 256M
#一个节点上split的至少的大小(这个值决定了多个DataNode上的文件是否需要合并)
set mapred.min.split.size.per.node=100000000; -- 100M
#一个交换机下split的至少的大小(这个值决定了多个交换机上的文件是否需要合并)
set mapred.min.split.size.per.rack=100000000; -- 100M
#增大文件大小为2G,减少map个数
set mapreduce.input.fileinputformat.split.maxsize=2048000000;设置map输出和reduce输出进行合并的相关参数:
#设置map端输出进行合并,默认为true
set hive.merge.mapfiles = true;
#设置reduce端输出进行合并,默认为false
set hive.merge.mapredfiles = true;
#设置合并文件的大小
set hive.merge.size.per.task = 256*1000*1000; -- 256M
#当输出文件的平均大小小于该值时,启动一个独立的MapReduce任务进行文件merge
set hive.merge.smallfiles.avgsize=16000000; -- 16M 启用压缩
# hive的查询结果输出是否进行压缩
set hive.exec.compress.output=true;
# MapReduce Job的结果输出是否使用压缩
set mapreduce.output.fileoutputformat.compress=true;减少reduce数量
#reduce 的个数决定了输出的文件的个数,所以可以调整reduce的个数控制hive表的文件数量,
#hive中的分区函数 distribute by 正好是控制MR中partition分区的,
#然后通过设置reduce的数量,结合分区函数让数据均衡的进入每个reduce即可。
#设置reduce的数量有两种方式,第一种是直接设置reduce个数
set mapreduce.job.reduces=10;
#第二种是设置每个reduce的大小,Hive会根据数据总大小猜测确定一个reduce个数
set hive.exec.reducers.bytes.per.reducer=5120000000; -- 默认是1G,设置为5G
#执行以下语句,将数据均衡的分配到reduce中
set mapreduce.job.reduces=10;
insert overwrite table A partition(dt)
select * from B
distribute by rand();
解释:如设置reduce数量为10,则使用 rand(), 随机生成一个数 x % 10 ,
这样数据就会随机进入 reduce 中,防止出现有的文件过大或过小使用hadoop的archive将小文件归档
#用来控制归档是否可用
set hive.archive.enabled=true;
#通知Hive在创建归档时是否可以设置父目录
set hive.archive.har.parentdir.settable=true;
#控制需要归档文件的大小
set har.partfile.size=1099511627776;
#使用以下命令进行归档
ALTER TABLE A ARCHIVE PARTITION(dt='2022-02-24', hr='12');
#对已归档的分区恢复为原文件
ALTER TABLE A UNARCHIVE PARTITION(dt='2022-02-24', hr='12');设置广播表大小
hive.mapjoin.smalltable.filesize=25000000;三、strict模式
开启严格模式对分区表进行查询,在where子句中没有加分区过滤的话,将禁止提交任务(默认:nonstrict)
set hive.mapred.mode=strict 开启严格模式
注:使用严格模式可以禁止以下三种类型的查询:
1. 对分区表的查询必须使用到分区相关的字段
分区表的数据量通常都比较大,对分区表的查询必须使用到分区相关的字段,不允许扫描所有分区,想想也是如果扫描所有分区的话那么对表进行分区还有什么意义呢。
当然某些特殊情况可能还是需要扫描所有分区,这个时候就需要记得确保严格模式被关闭。
2. order by必须带limit
因为要保证全局有序需要将所有的数据拉到一个Reducer上,当数据集比较大时速度会很慢。个人猜测可能是设置了limit N之后就会有一个很简单的优化算法:每个Reducer排序取N然后再合并排序取N即可,可大大减少数据传输量。
3. 禁止笛卡尔积查询(join必须有on连接条件)
Hive不会对where中的连接条件优化为on,所以join必须带有on连接条件,不允许两个表直接相乘。
四、并行执行优化
Hive会将一个查询转化成一个或者多个阶段。这样的阶段可以是MapReduce阶段、抽样阶段、合并阶段、limit阶段。或者Hive执行过程中可能需要的其他阶段。默认情况下,Hive一次只会执行一个阶段。不过,某个特定的job可能包含众多的阶段,而这些阶段可能并非完全互相依赖的,也就是说有些阶段是可以并行执行的,这样可能使得整个job的执行时间缩短。如果有更多的阶段可以并行执行,那么job可能就越快完成。
通过设置参数hive.exec.parallel值为true,就可以开启并发执行。在共享集群中,需要注意下,如果job中并行阶段增多,那么集群利用率就会增加。
set hive.exec.parallel=true; //打开任务并行执行
set hive.exec.parallel.thread.number=16; //同一个sql允许最大并行度,默认为8。五、推测执行优化
在分布式集群环境下,因为程序bug(包括Hadoop本身的bug),负载不均衡或者资源分布不均等原因,会造成同一个作业的多个任务之间运行速度不一致,有些任务的运行速度可能明显慢于其他任务(比如一个作业的某个任务进度只有50%,而其他所有任务已经运行完毕),则这些任务会拖慢作业的整体执行进度。为了避免这种情况发生,Hadoop采用了推测执行(Speculative Execution)机制,它根据一定的法则推测出“拖后腿”的任务,并为这样的任务启动一个备份任务,让该任务与原始任务同时处理同一份数据,并最终选用最先成功运行完成任务的计算结果作为最终结果。
设置开启推测执行参数:Hadoop的mapred-site.xml文件中进行配置:
<property>
<name>mapreduce.map.speculative</name>
<value>true</value>
<description>If true, then multiple instances of some map tasks
may be executed in parallel.</description>
</property>
<property>
<name>mapreduce.reduce.speculative</name>
<value>true</value>
<description>If true, then multiple instances of some reduce tasks
may be executed in parallel.</description>
</property>任务级别:set hive.mapred.reduce.tasks.speculative.execution=true
六、数据倾斜优化
set hive.map.aggr=true;
set hive.groupby.skewindata = ture;当选项设定为true时,生成的查询计划有两个MapReduce任务。
在第一个MapReduce中,map的输出结果集合会随机分布到reduce中,每个reduce做部分聚合操作,并输出结果。
这样处理的结果是,相同的Group By Key有可能分发到不同的reduce中,从而达到负载均衡的目的;
第二个MapReduce任务再根据预处理的数据结果按照Group By Key分布到reduce中(这个过程可以保证相同的Group By Key分布到同一个reduce中),最后完成最终的聚合操作。
但是这个处理方案对于我们来说是个黑盒,无法把控。
那么在日常需求的情况下如何处理这种数据倾斜的情况呢;
sample采样,获取哪些集中的key;
将集中的key按照一定规则添加随机数;
进行join,由于打散了,所以数据倾斜避免了;
在处理结果中对之前的添加的随机数进行切分,变成原始的数据。
七、小文件过多优化例子
7.1 有个表由于上游为kafka小时抽到hdfs,然后hive加分区。一天数据量233.6 G
导致有很多小文件6000+,每个文件大小不一致,6mb ~ 50m之间
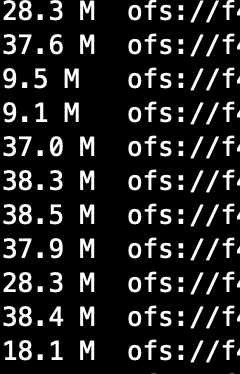
7.2 方式1,设置合并为1G。产出后文件大小为1G左右,原文件个数6000+ 小文件合并后输出文件为245个
--1G一个文件
set hive.exec.reducers.bytes.per.reducer=1024000000;
select * from dw.temp_wang
where dt = '20220713'
--rand(1)防止stage失败导致数据增多或变少。均匀分发
distribute by cast(rand(1)*1000 as int) 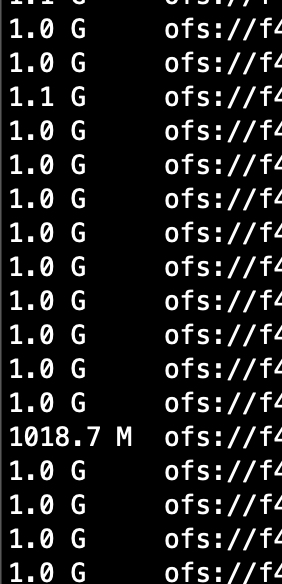
7.3 把set参数去除后尝试,看是否分发为1000个文件
--set hive.exec.reducers.bytes.per.reducer=1024000000;
只使用:distribute by cast(rand(1)*1000 as int)
实际创建980个文件,因为一天文件总量为233.6 G,设置为1000个文件达不到。
使用默认值256m*1000=256GB 大于 一天数据量233.6 G
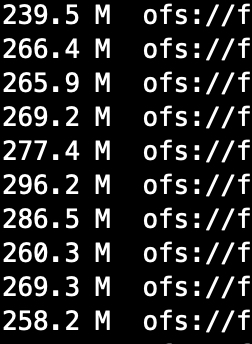
7.4 把set参数去除后尝试,因为上面一步达不到1000个文件,调整为500个
--set hive.exec.reducers.bytes.per.reducer=1024000000;
只使用:distribute by cast(rand(1)*500 as int)一天数据量233.6 G / 500 约为每个文件478MB,然而实际文件个数为980个文件。
可以看到创建了一些500mb左右的文件,还有些空文件。不了解原因
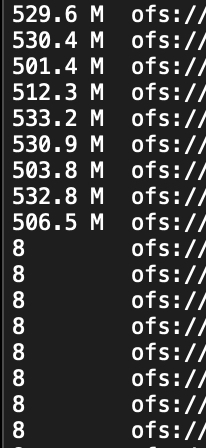
7.5 增加set参数,设置文件大小1G,目标500个文件。尝试下空文件是否还有
set hive.exec.reducers.bytes.per.reducer=1024000000;
distribute by cast(rand(1)*500 as int)空文件没了,文件大小也变成1G左右,文件个数245,比设置的500个要小。
下面准备考虑下文件大小设置为150mb,这样设置的500个文件预计75G放不下,看看处理效果如何

7.6改文件大小为150mb,500个文件,看看效果如何
set hive.exec.reducers.bytes.per.reducer=150000000;
distribute by cast(rand(1)*500 as int)实际生成文件个数1009, 设置的两个参数未生效,存在500mb文件和空文件
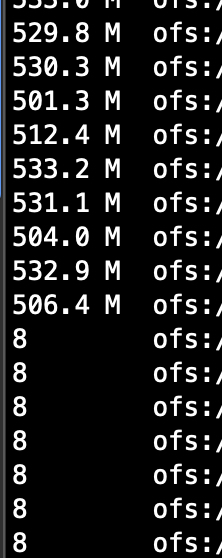
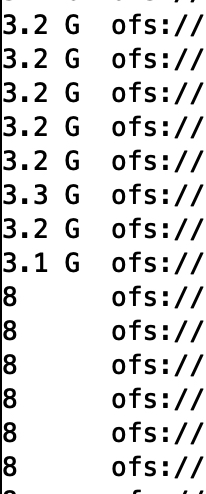
7.7 改文件大小为2048mb,80个文件,看看效果如何
set hive.exec.reducers.bytes.per.reducer=2048000000;
distribute by cast(rand(1)*80 as int)实际3.2g左右一个文件,存在一些空文件。总计123个文件,80个大文件,43个空文件。
设置的80不生效
八、Join优化
hive.auto.convert.join : 是否自动转换为mapjoin
hive.mapjoin.smalltable.filesize : 小表的最大文件大小,默认为25000000,即25M
hive.auto.convert.join.noconditionaltask : 是否将多个mapjoin合并为一个
hive.auto.convert.join.noconditionaltask.size : 多个mapjoin转换为1个时,所有小表的文件大小总和的最大值。
例:一个大表顺序关联3个小表a(10M), b(8M),c(12M),如果hive.auto.convert.join.noconditionaltask.size的值:
小于18M,则无法合并mapjoin,必须执行3个mapjoin;
大于18M小于30M,则可以合并a和b表的mapjoin,所以只需要执行2个mapjoin;
大于30M,则可以将3个mapjoin都合并为1个。
合并mapjoin有啥好处呢?因为每个mapjoin都要执行一次map,需要读写一次数据,所以多个mapjoin就要做多次的数据读写,合并mapjoin后只用读写一次,自然能大大加快速度。但是执行map是内存大小是有限制的,在一次map里对多个小表做mapjoin就必须把多个小表都加入内存,为了防止内存溢出,所以加了hive.auto.convert.join.noconditionaltask.size参数来做限制。不过,这个值只是限制输入的表文件的大小,并不代表实际mapjoin时hashtable的大小。
我们可以通过explain查看执行计划,来看看mapjoin是否生效。
hive.mapjoin.localtask.max.memory.usage : 将小表转成hashtable的本地任务的最大内存使用率,默认0.9
hive.mapjoin.followby.gby.localtask.max.memory.usage : 如果mapjoin后面紧跟着一个group by任务,这种情况下 本地任务的最大内存使用率,默认是0.55
hive.mapjoin.check.memory.rows : localtask每处理完多少行,就执行内存检查。默认为100000
使用mapjoin时还要注意,用作join的关联字段的字段类型最好要一致。
我就碰到一个诡异的问题,执行mapjoin 的local task时一直卡住,40万行的小表处理了好几个小时,正常情况下应该几秒钟就完成了。查了好久原因,结果原来是做join的关联字段的类型不一致,一边是int, 一边是string,hive解释计划里显示它们都会被转成double再来join
八、查询数据优化
1、Fetch抓取
Hive中对某些情况的查询可以不必使用MapReduce计算,例如:select * from score 。这种情况下,Hive可以直接度去score对应的存储目录下的文件,然后输出查询结果到控制台,通过设置hive.fetch.task.conversion参数,可以控制查询语句是否走MapReduce。设置成more不会走mapreduce计算,直接拿文件输出
set hive.fetch.task.conversion=more;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号