

Flink 部署和整体架构
一、Flink运行部署模式和流程
部署模式:
1、Local 本地部署,直接启动进程,适合调试使用
2、Standalone Cluster集群部署,flink自带集群模式
3、On Yarn 计算资源统一由Hadoop YARN管理资源进行调度,按需使用提高集群的资源利用率,生产环境
运行流程
1、用户提交Flink程序到JobClient,
2、JobClient的 解析、优化任务,然后提交任务到JobManager
3、TaskManager运行task, 并上报信息给JobManager
JobManager 包工头
TaskManager 任务组长
Task solt 工人 (并行去做事情)
二、架构和组件
2.1 任务流程图
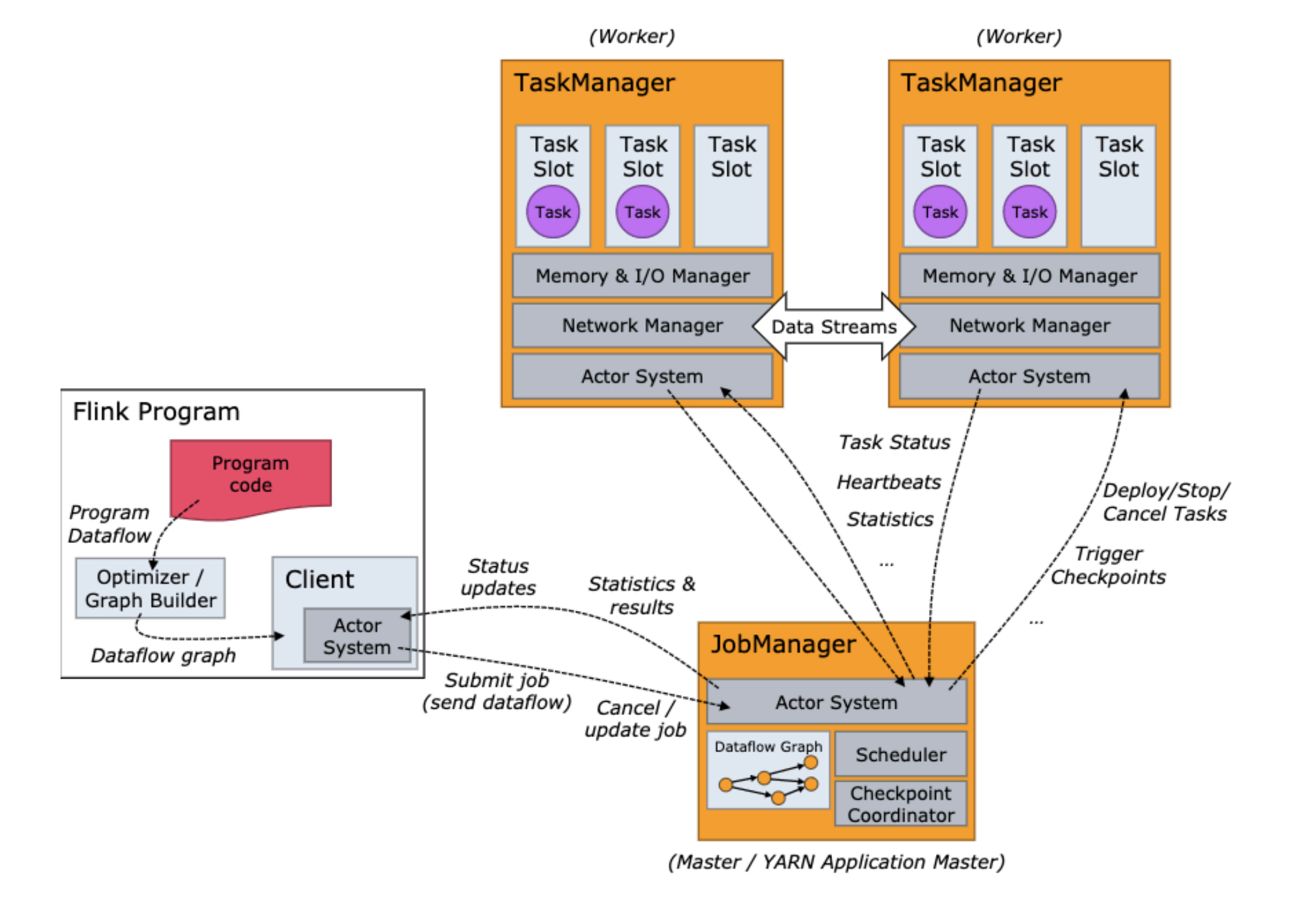
2.2 JobManager 介绍
2.2.1 JobManager功能
协调 Flink 应⽤程序的分布式执⾏
它决定何时调度下⼀个 task
对完成的 task 或执⾏失败做出反应
协调 checkpoint,并且协调从失败中恢复等等
2.2.2 JobManager组成
ResourceManager:负责 Flink 集群中的资源提供、回收、分配,它管理task slots
Dispatcher:提供了⼀个 REST 接⼝,⽤来提交 Flink 应⽤程序执⾏
运⾏ Flink WebUI ⽤来提供作业执⾏信息
运⾏ Flink WebUI ⽤来提供作业执⾏信息
为每个提交的作业启动⼀个新的 JobMaster
JobMaster:负责管理单个JobGraph的执⾏,Flink 集群中可以同时运⾏多个作业,每个作业都有⾃⼰的 JobMaster
⾄少有⼀个 JobManager,⾼可⽤(HA)设置中可能有多个 JobManager,其中⼀个始终是 leader,其他的则是 standby
⾄少有⼀个 JobManager,⾼可⽤(HA)设置中可能有多个 JobManager,其中⼀个始终是 leader,其他的则是 standby
2.3 TaskManager (任务组⻓,搬砖的⼈)
2.3.1 简介
负责计算的worker节点,还有上报节点内存、任务运⾏情况给JobManager等工作
⾄少有⼀个 TaskManager,也称为 worker 执⾏作业流的task,并且缓存和交换数据流
在 TaskManager 中资源调度的最⼩单位是 Task Slot
2.3.2 进阶概念
2.3.2.1 TaskManager中 task slot 的数量表示并发处理 task 的数量
2.3.2.2 ⼀个 task slot 中可以执⾏多个算⼦,⾥⾯多个线程
2.3.2.3 算⼦类型opetator、source、transformation、sink
2.3.2.3 算⼦类型opetator、source、transformation、sink
2.3.2.4 对于分布式执⾏,Flink 将算⼦的 subtasks 链接成 tasks,每个 task 由⼀个线程执⾏
2.3.2.5 图中source和map算⼦组成⼀个算⼦链,作为⼀个task运⾏在⼀个线程上
2.3.2.5 图中source和map算⼦组成⼀个算⼦链,作为⼀个task运⾏在⼀个线程上
2.3.2.6 将算⼦链接成 task 是个有⽤的优化:它减少线程间切换、缓冲的开销,并且减少延迟的同时增加整体吞吐量
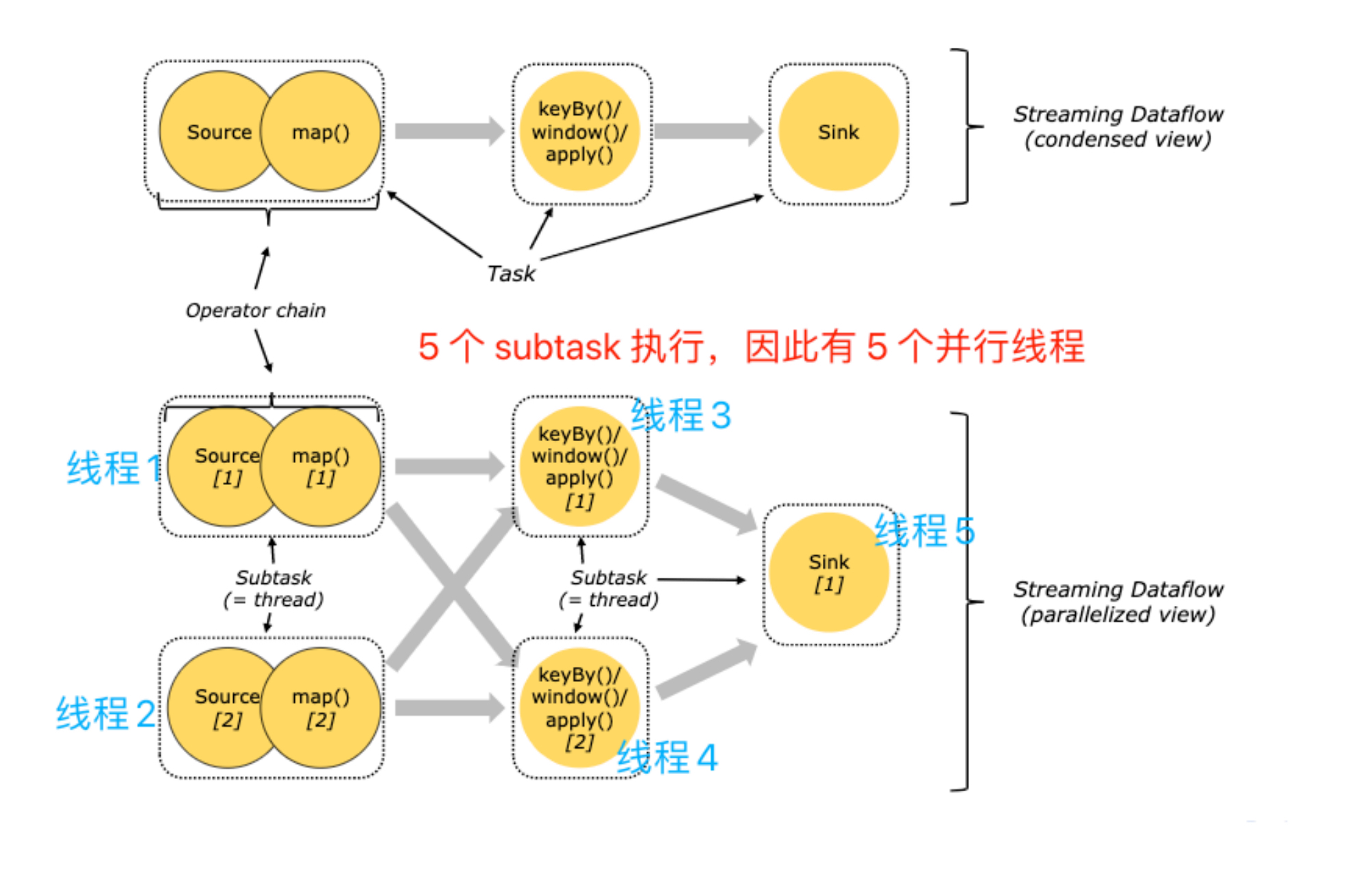
2.4 Task Slots 任务槽
2.4.1 Task Slot是Flink中的任务执⾏器,每个Task Slot可以运⾏多个subtask ,每个subtask会以单独的线程来运⾏
2.4.2 每个 worker(TaskManager)是⼀个 JVM 进程,可以在单独的线程中执⾏⼀个(1个solt)或多个 subtask
2.4.3 为了控制⼀个 TaskManager 中接受多少个 task,就有了task slots概念(⾄少⼀个)
2.4.4 每个 task slot 代表 TaskManager 中资源的固定⼦集
2.4.5 Task 正好封装了⼀个 Operator 或者 Operator Chain 的parallel instance。
2.4.6 Flink 算⼦之间可以通过【⼀对⼀】模式或【重新分发】模式传输数据
注意点:
所有Task Slot平均分配TaskManger的内存, TaskSolt 没有CPU 隔离
当前 TaskSolt 独占内存空间,作业间互不影响
⼀个TaskManager进程⾥有多少个taskSolt就意味着多少个并发
Task Solt数量建议是cpu的核数,独占内存,共享CPU
三、并行度
3.1 Flink是分布式计算流式框架
程序在多节点并⾏执⾏,所以就有并⾏度 Parallelism概念
DataStream 就像是有向⽆环图(DAG),每⼀个 数据流(DataStream) 以⼀个或多个 source 开始,以⼀个或多个sink 结束
3.2 流程
⼀个数据流( stream) 包含⼀个或多个分区,在不同的线程/物理机⾥并⾏执⾏
每⼀个算⼦( operator) 包含⼀个或多个⼦任务( subtask),⼦任务在不同的线程/物理机⾥并⾏执⾏
⼀个算⼦的⼦任务subtask 的个数就是并⾏度( parallelism)
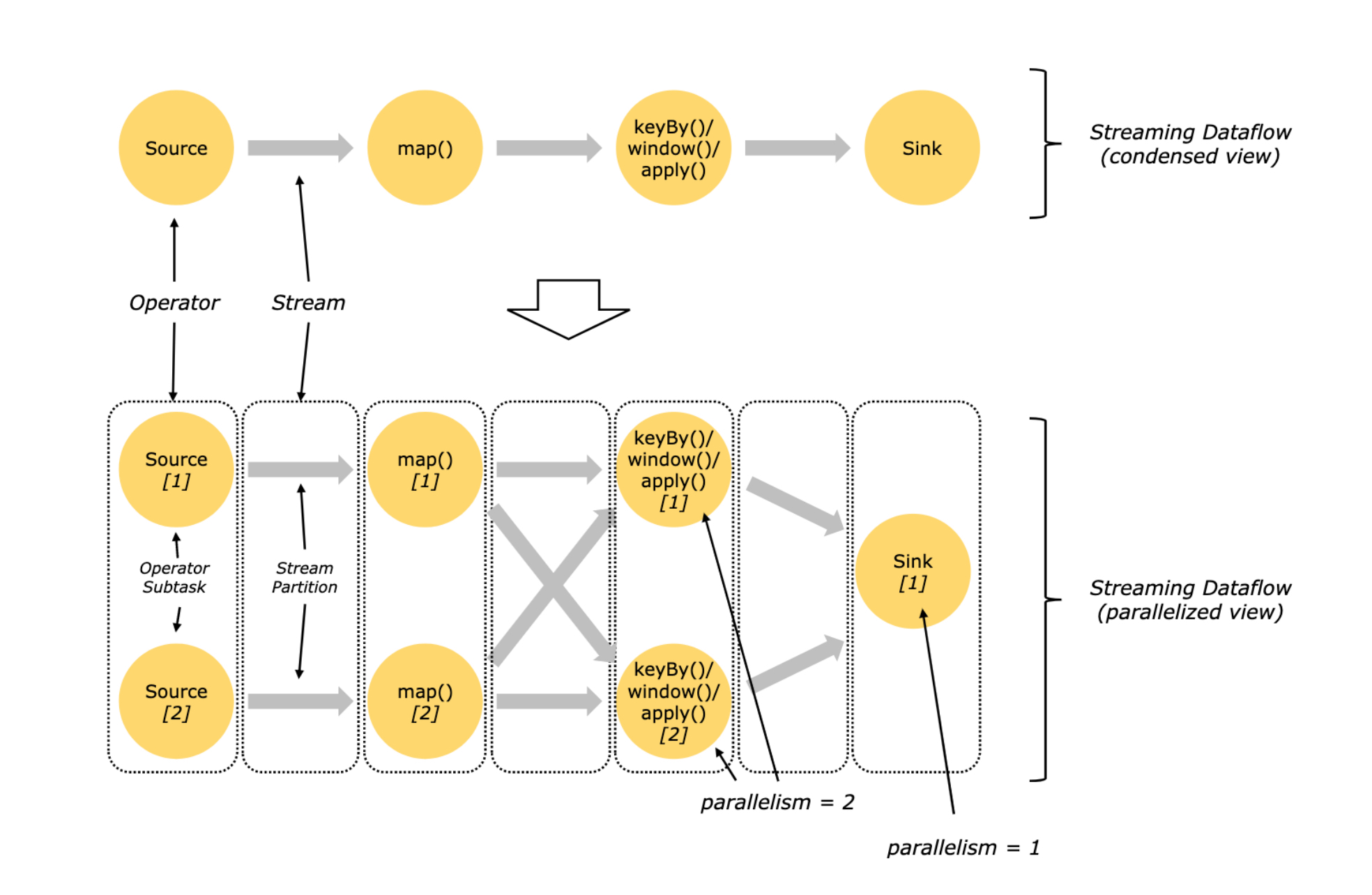
3.3 并行度的设置
Flink流程序中不同的算⼦可能具有不同的并⾏度,可以在多个地⽅配置,有不同的优先级。
某些算⼦⽆法设置并⾏度,本地IDEA运⾏ 并⾏度默认为cpu核数
优先级从高到低依次如下
3.3.1 算子
map( xxx ).setParallelism(2)
3.3.2 全局env
env.setParallelism(2)
3.3.3 客户端cli(推荐走客户端方式,不走全局env方式)
./bin/flink run -p 2 xxx.jar
3.3.4 Flink配置⽂件
/conf/flink-conf.yaml 的 parallelism.defaul 默认值
3.4 TaskSolt和parallelism并行度,定义区分
task slot是静态的概念,是指taskmanager具有的并发执⾏能⼒;
parallelism是动态的概念,是指 程序运⾏时实际使⽤的并发能⼒
前者是具有的能⼒⽐如可以100个,后者是实际使⽤的并发,⽐如只要20个并发就⾏。
parallelism是动态的概念,是指 程序运⾏时实际使⽤的并发能⼒
前者是具有的能⼒⽐如可以100个,后者是实际使⽤的并发,⽐如只要20个并发就⾏。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号